基于类名引导的弱监督文本分类系统及其方法与流程
1.本发明涉及一种基于类名引导的弱监督文本分类系统及其方法。
背景技术:
2.目前,文本分类任务是自然语言处理中最基础的任务,从情感分析到意图识别,再到信息抽取都可以见到其身影。近年来,循环神经网络、卷积神经网络以及bert预训练模型都在文本分类任务上取得了十分优异的成绩,这些文本分类模型正越来越受到学界的欢迎,要训练一个有监督分类模型,至少需要消耗数十万的标注文档。然而想要收集这种规模的训练文档常常需要大量标注人员和文档专家的协同配合,缺乏训练数据是监督分类模型难以大规模落地的重要原因。
3.弱监督文本分类的主要技术方法分为:基于类名的方法、基于种子词的方法等,基于类名的方法多采用将标签和文档嵌入语义空间,计算文档和潜在标签之间的语义相似度为主要手段,利用逻辑回归模型进行分类;基于种子词的方法多使用由对语料库特别熟悉的专家提供的种子词作为监督源,使用语境化技术进行文本分类,例如:bert模型,elmo模型等等。现有的弱监督文本分类技术存在较多的局限性。
技术实现要素:
4.本发明的目的是克服现有技术存在的不足,提供一种基于类名引导的弱监督文本分类系统及其方法。
5.本发明的目的通过以下技术方案来实现:
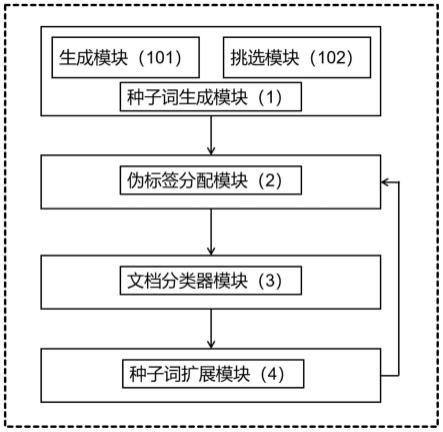
6.基于类名引导的弱监督文本分类系统,特点是:包含种子词生成模块、伪标签分配模块、文档分类器模块以及种子词扩展模块;
7.所述种子词生成模块,对语料库中语料学习向量表示、建模关系、生成种子词;
8.所述伪标签分配模块,给语料库中的文档分配预测的伪标签;
9.所述文档分类器模块,根据已分配伪标签的文档进行预训练,在未标注文档上泛化训练;
10.所述种子词扩展模块,在一次分类完成后,通过对分类结果以及生成种子词时产生的排名分数进行综合考虑,以此扩展种子词。
11.进一步地,上述的基于类名引导的弱监督文本分类系统,其中,所述种子词生成模块包含生成模块和挑选模块,所述生成模块,用于学习向量表示、建模关系,将类名与语料库中的文档进行建模,通过相似度计算,得到一系列语义相关的单词;所述挑选模块,用于生成种子词,将得到的语义相关单词联合考虑语义特异性,得出单词排名分数,以便生成高质量的种子词。
12.进一步地,上述的基于类名引导的弱监督文本分类系统,其中,所述伪标签分配模块,统计种子词生成模块生成的高质量种子词在文档中出现的频率,并结合种子词生成模块得出的单词排名分数,给未标注的文档分配伪标签。
13.进一步地,上述的基于类名引导的弱监督文本分类系统,其中,所述文档分类器模块,采用层次注意力模型作为分类器,先关注文档中的句子,找到文档中的重要句子,然后关注句子中的单词,识别句子中的重要单词;接着采用伪标签分配模块生成的伪标签在未标记的文档数据上训练一个han模型。
14.进一步地,上述的基于类名引导的弱监督文本分类系统,其中,所述种子词扩展模块,通过将文档分类器模块所得到的对文档的预测概率与种子词在预测的文档中的出现频率进行综合考虑,计算出扩展分数;种子词扩展模块扩充种子词生成模块的种子词集,通过伪标签分配模块再次分配伪标签,然后训练文档分类器模块,直至收敛。
15.本发明基于类名引导的弱监督文本分类方法,其中,包括以下步骤:
16.首先,将类名与语料库进行种子词生成;
17.然后,迭代地将种子词生成之后的种子词运用于伪标签分配,使用分配了伪标签的文档训练文档分类器,通过预测的结果扩展种子词;
18.最后,等到迭代次数结束,输出分类结果。
19.更进一步地,上述的基于类名引导的弱监督文本分类方法,其中,由种子词生成模块,对语料库中语料学习向量表示、建模关系、生成种子词;由伪标签分配模块,给语料库中的文档分配预测的伪标签;由文档分类器模块,根据已分配伪标签的文档进行预训练,接着在未标注文档上泛化训练;由种子词扩展模块,在一次分类完成后,通过对分类结果以及生成种子词时产生的排名分数进行综合考虑,以此扩展种子词。
20.更进一步地,上述的基于类名引导的弱监督文本分类方法,其中,由种子词生成模块的生成模块将类名与语料库中的文档进行建模,通过相似度计算,得到一系列语义相关的单词;由种子词生成模块的挑选模块,将得到的语义相关单词联合考虑语义特异性,得出单词排名分数,以便生成高质量的种子词;
21.种子词生成模块中的生成模块采用冯米塞尔分布,对类名与语料库进行建模,并使用相似度计算获得一组单词,计算如下:
22.冯米塞尔分布,xw是语料库中单词的m维向量,是阶的第一类修正贝塞尔函数;冯米塞尔分布有平均方向和集中参数两个参数,标签名向量u
l
被作为平均方向,其他单词在标签名附近的集中程度k
l
被作为集中参数,分布表达式:
[0023][0024]
相似度计算,余弦相似度可提取单词间的语义相关性,从而获得一系列与类名相关的单词,通过向量余弦相似度获取一组与标签名l高度语义相关的单词wk:
[0025][0026][0027]
冯米塞尔分布是一个球形分布,与中心词语义相关的会聚集在中心词四周,通过
相似度计算,可获得一系列与类名相关的单词;
[0028]
种子词生成模块的挑选模块,使用语义特异性,并联合相似度计算,来获取最终的种子词,计算如下:
[0029]
语义特异性,如果单词v的含义包含另一个单词w含义,那么单词v的所有上下文特征会在单词w中出现;使用标量sc
w,l
将单词w与标签名l关联,sc
w,l
越大时,表明单词w的语义较标签名l而言更具体且排他;将单词的sc
w,l
值进行归一化操作,以此得到语义特异性分数:
[0030][0031]
由伪标签分配模块,给语料库中的文档分配预测的伪标签;
[0032]
由文档分类器模块,根据已分配伪标签的文档进行预训练,接着在未标注文档上泛化训练;
[0033]
由种子词扩展模块,在一次分类完成后,通过对分类结果以及生成种子词时产生的排名分数进行综合考虑,以此扩展种子词;
[0034]
种子词扩展模块扩充种子词生成模块的种子词集,通过伪标签分配模块再次分配伪标签,然后训练文档分类器模块,直至收敛;迭代的训练框架赋予其更强的泛化能力和有效性。
[0035]
本发明与现有技术相比具有显著的优点和有益效果,具体体现在以下方面:
[0036]
①
本发明基于类名引导的弱监督文本分类系统及方法,对语料库中语料学习向量表示、建模关系、生成种子词,通过种子词生成模块,生成与类名相关的种子词,有效减少高质量标注语料库的依赖,解决了缓解文本分类领域的数据稀缺问题;
[0037]
②
使用类名和种子词结合的方法,取代传统的单纯基于类名和单纯基于种子词方法;本发明创新性的解决了文本分类的数据稀缺问题,相比于现有技术在通用数据集上有更高的分类准确率;
[0038]
③
针对具有极高应用价值的文本分类方法开展实际研究,具有开拓性,显著提高分类成功的准确率。
[0039]
本发明的其他特征和优点将在随后的说明书阐述,并且,部分地从说明书中变得显而易见,或者通过实施本发明具体实施方式了解。本发明的目的和其他优点可通过在所写的说明书以及附图中所特别指出的结构来实现和获得。
附图说明
[0040]
为了更清楚地说明本发明实施例的技术方案,下面将对实施例中所需要使用的附图作简单地介绍,应当理解,以下附图仅示出了本发明的某些实施例,因此不应被看作是对范围的限定,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他相关的附图。
[0041]
图1:本发明系统的架构原理示意图;
[0042]
图2:本发明的流程示意图;
[0043]
图3:种子词生成模块的架构原理示意图;
[0044]
图4:伪标签分配模块的架构原理示意图;
[0045]
图5:文档分类器模块的架构示意图;
[0046]
图6:种子词扩展模块的架构原理示意图;
[0047]
图7:生成效果展示图。
具体实施方式
[0048]
下面将结合本发明实施例中附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。通常在此处附图中描述和示出的本发明实施例的组件可以以各种不同的配置来布置和设计。因此,以下对在附图中提供的本发明的实施例的详细描述并非旨在限制要求保护的本发明的范围,而是仅仅表示本发明的选定实施例。基于本发明的实施例,本领域技术人员在没有做出创造性劳动的前提下所获得的所有其他实施例,都属于本发明保护的范围。
[0049]
应注意到:相似的标号和字母在下面的附图中表示类似项,因此,一旦某一项在一个附图中被定义,则在随后的附图中不需要对其进行进一步定义和解释。同时,在本发明的描述中,方位术语和次序术语等仅用于区分描述,而不能理解为指示或暗示相对重要性。
[0050]
如图1所示,基于类名引导的弱监督文本分类系统,包含种子词生成模块1、伪标签分配模块2、文档分类器模块3以及种子词扩展模块4;
[0051]
种子词生成模块1,对语料库中语料学习向量表示、建模关系、生成种子词;
[0052]
伪标签分配模块2,给语料库中的文档分配预测的伪标签;
[0053]
文档分类器模块3,根据已分配伪标签的文档进行预训练,在未标注文档上泛化训练;
[0054]
种子词扩展模块4,在一次分类完成后,通过对分类结果以及生成种子词时产生的排名分数进行综合考虑,以此扩展种子词。
[0055]
如图3,种子词生成模块1包含生成模块101、挑选模块102,所述生成模块101,用于学习向量表示、建模关系,将类名与语料库中的文档进行建模,通过相似度计算,得到一系列语义相关的单词;所述挑选模块102,用于生成种子词,将得到的语义相关单词联合考虑语义特异性,得出单词排名分数,以便生成高质量的种子词。
[0056]
如图4,伪标签分配模块2,统计种子词生成模块1生成的高质量种子词在文档中出现的频率,并结合种子词生成模块1得出的单词排名分数,给未标注的文档分配伪标签。
[0057]
如图5,文档分类器模块3,采用层次注意力模型作为分类器,首先关注文档中的句子,找到文档中的重要句子;然后关注句子中的单词,识别句子中的重要单词。接着使用伪标签分配模块2生成的伪标签在未标记的文档数据上训练一个han模型。
[0058]
如图6,种子词扩展模块4,通过将文档分类器模块3所得到的对文档的预测概率与种子词在预测的文档中的出现频率进行综合考虑,计算出扩展分数,以便更好地扩展种子词。
[0059]
本发明基于类名引导的弱监督文本分类方法及系统,包括以下步骤:
[0060]
首先,将类名与语料库进行种子词生成;
[0061]
然后,迭代地将种子词生成之后的种子词运用于伪标签分配,使用分配了伪标签的文档训练文档分类器,通过预测的结果扩展种子词;
[0062]
最后,等到迭代次数结束,输出分类结果。
[0063]
如图2,由种子词扩展模块1,对语料库中语料学习向量表示、建模关系、生成种子词;伪标签分配模块2,给语料库中的文档分配预测的伪标签;文档分类器模块3,根据已分配伪标签的文档进行预训练,接着在未标注文档上泛化训练;种子词扩展模块4,在一次分类完成后,通过对分类结果以及生成种子词时产生的排名分数进行综合考虑,以此扩展种子词。
[0064]
由种子词生成模块1的生成模块101将类名与语料库中的文档进行建模,通过相似度计算,得到一系列语义相关的单词;种子词生成模块1的挑选模块102,将得到的语义相关单词联合考虑语义特异性,得出单词排名分数,以便生成高质量的种子词;
[0065]
种子词生成模块1中的生成模块101采用冯米塞尔分布,对类名与语料库进行建模,并使用相似度计算获得一组单词,计算如下:
[0066]
冯米塞尔分布,xw是语料库中单词的m维向量,是阶的第一类修正贝塞尔函数;冯米塞尔分布有平均方向和集中参数两个参数,标签名向量u
l
被作为平均方向,其他单词在标签名附近的集中程度k
l
被作为集中参数,分布表达式:
[0067][0068]
相似度计算,余弦相似度可提取单词间的语义相关性,从而获得一系列与类名相关的单词,通过向量余弦相似度获取一组与标签名l高度语义相关的单词wk:
[0069][0070][0071]
冯米塞尔分布是一个球形分布,与中心词语义相关的会聚集在中心词四周,通过相似度计算,可获得一系列与类名相关的单词;
[0072]
种子词生成模块1的挑选模块102,使用语义特异性,并联合相似度计算,来获取最终的种子词,计算如下:
[0073]
语义特异性,如果单词v的含义包含另一个单词w含义,那么单词v的所有上下文特征会在单词w中出现;使用标量sc
w,l
将单词w与标签名l关联,sc
w,l
越大时,表明单词w的语义较标签名l而言更具体且排他;将单词的sc
w,l
值进行归一化操作,以此得到语义特异性分数:
[0074][0075]
由伪标签分配模块2,给语料库中的文档分配预测的伪标签;
[0076]
由文档分类器模块3,根据已分配伪标签的文档进行预训练,接着在未标注文档上泛化训练;
[0077]
由种子词扩展模块4,在一次分类完成后,通过对分类结果以及生成种子词时产生
的排名分数进行综合考虑,以此扩展种子词;
[0078]
种子词扩展模块4扩充种子词生成模块的种子词集,通过伪标签分配模块2再次分配伪标签,然后训练文档分类器模块3,直至收敛;迭代的训练框架赋予其更强的泛化能力和有效性。
[0079]
如图7所示,例如样例:“under the terms of the deal,shareholders will receive$54.20in cash for each share of twitter stock they own,matching musk's original offer and marking a 38%premium over the stock price the day before musk revealed his stake in the company.”,未被打标签,但是应属于business类,采用本发明基于类名引导的弱监督文本分类系统,可以一步步从文本数据中提取有效信息,最终输出正确结果。
[0080]
由用户提供类名,将类名与语料库进行建模,进行种子词生成操作;然后,将生成的种子词运用于伪标签分配,使用分配了伪标签的文档训练文档分类器,通过预测的结果扩展种子词;将扩展的种子词再次运用于伪标签分配,之后训练文档分类器;最后,等到方法效果收敛,输出分类结果。
[0081]
综上所述,基于类名引导的弱监督文本分类系统及方法,对语料库中语料学习向量表示、建模关系、生成种子词,通过种子词生成模块,生成与类名相关的种子词,有效减少高质量标注语料库的依赖,解决了缓解文本分类领域的数据稀缺问题。使用类名和种子词结合的方法,取代传统的单纯基于类名和单纯基于种子词方法;本发明创新性的解决了文本分类的数据稀缺问题,相比于现有技术在通用数据集上有更高的分类准确率;针对具有极高应用价值的文本分类方法开展实际研究,具有开拓性,显著提高分类成功的准确率。
[0082]
以上所述仅为本发明的优选实施例而已,并不用于限制本发明,对于本领域的技术人员来说,本发明可以有各种更改和变化。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。应注意到:相似的标号和字母在下面的附图中表示类似项,因此,一旦某一项在一个附图中被定义,则在随后的附图中不需要对其进行进一步定义和解释。
[0083]
上述仅为本发明的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,可轻易想到变化或替换,都应涵盖在本发明的保护范围之内。
[0084]
需要说明的是,在本文中,诸如第一和第二等之类的关系术语仅仅用来将一个实体或者操作与另一个实体或操作区分开来,而不一定要求或者暗示这些实体或操作之间存在任何这种实际的关系或者顺序。而且,术语“包括”、“包含”或者其任何其他变体意在涵盖非排他性的包含,从而使得包括一系列要素的过程、方法、物品或者设备不仅包括那些要素,而且还包括没有明确列出的其他要素,或者是还包括为这种过程、方法、物品或者设备所固有的要素。在没有更多限制的情况下,由语句“包括一个
……”
限定的要素,并不排除在包括所述要素的过程、方法、物品或者设备中还存在另外的相同要素。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1