一种图像重建的方法和系统与流程
1.本发明涉及图像处理,特别地,本发明涉及一种图像重建的方法、系统和计算机程序产品。
背景技术:
2.图像重建可以基于一个场景的多个现有视角的图像建立该场景的三维模型。在图像重建的基础上,本领域技术人员可以基于建立的三维模型生成新视角的图像,该新视角不属于现有的多个视角。图像重建技术以及生成新视角的图像技术可用于智能工厂、智慧城市、vr、ar、网络购物中的商品三维重建等。
3.现有技术有多种图像重建方法,例如nerf、nv、llff等基于神经网络的方法,以及colmap、sfm、orbslam等传统方法。基于神经网络的方法以其生成质量高的优点,现在正在被广泛使用。但是现有的基于神经网络的方法由于其使用了均匀采样和由粗到细的采样及基于频率的位置编码方法导致其训练速度慢,通常生成一个三维模型训练时间要花费8-12个小时,这也限制了其广泛的使用。
技术实现要素:
4.根据本发明的一个方面,公开了一种图像重建的方法,包括:获取一个场景的多个现有视角的图像;将所述多个现有视角的图像作为训练样本,训练一个神经辐射场模型,其中在训练过程中所述神经辐射场模型的输入为训练样本的视角以及存储在哈希表中的特征,所述存储在哈希表中的特征是通过对采样点的位置进行哈希编码,并根据编码值索引存储在哈希表中的特征来获得的;以及显示训练的神经辐射场模型对应的所述场景的三维模型。
5.根据本发明的另一个方面,公开了一种图像重建的系统,包括:获取模块,被配置为获取一个场景的多个现有视角的图像;训练模块,被配置为将所述获取模块获取的所述多个现有视角的图像作为训练样本,训练一个神经辐射场模型,其中所述神经辐射场模型的输入为训练样本的视角以及存储在哈希表中的特征,所述存储在哈希表中的特征是通过所述训练模块包括的位置编码模块获得的,所述位置编码模块被配置为对采样点的位置进行哈希编码,并根据编码值索引存储在哈希表中的特征;以及显示模块,被配置为显示所述训练模块训练的神经辐射场模型对应的所述场景的三维模型。
6.根据本发明的又一个方面,公开了一种计算机程序产品,包括计算机可读存储介质,具有随其体现的计算机可读程序代码,所述计算机可读程序代码可由一个或多个计算机处理器执行,以执行上述方法。
7.本发明公开的技术方案较现有技术方案重建模型精度更高,训练速度更快。本发明可以应用在物体重建、场景重建、新视角生成、渲染等领域,从而应用在智能工厂、智慧城市、vr、ar、网络购物中的商品三维重建等。
附图说明
8.图1示出了根据一个场景的多个现有视角的图像建立该场景的三维模型的示意图;
9.图2示出了基于图1中建立的三维模型生成的新视角的图像的示意图;
10.图3示出了根据本发明实施例的一种图像重建的系统的结构框图;
11.图4示出了根据本发明实施例的训练模块的流程图;
12.图5示出了根据本发明实施例的图1对应的场景的三维模型的密度体素网格的示意图;
13.图6示出了根据本发明实施例的如何对密度体素网格进行采样的示意图;
14.图7示出了根据本发明实施例的针对一条视线上的密度体素网格采样模块的采样流程图;
15.图8示出了根据本发明实施例的像素颜色计算模块进行体渲染的示意图;
16.图9示出了根据本发明实施例的位置编码模块的流程图;以及
17.图10示出了使用本发明的图像重建方法与现有方法得到的不同新视角图像的结果对比。
具体实施方式
18.以下描述包括体现本发明技术的示例性方法、系统、和存储介质。然而,应该理解,在一个或多个方面,可以在没有这些具体细节的情况下实践所描述的发明。在其他情况下,没有详细示出公知的协议、结构和技术,以免模糊本发明。本领域普通技术人员将理解,所描述的技术和机制可以应用于利用图像说明训练目标检测模型的系统、方法、以及计算机可读存储介质。
19.下面参照附图来说明本发明的实施例。在下面的说明中,阐述了许多具体细节以便更全面地了解本发明。但是,对于本技术领域内的技术人员明显的是,本发明的实现可不具有这些具体细节中的一些。此外,应当理解的是,本发明并不限于所介绍的特定实施例。相反,可以考虑用下面的特征和要素的任意组合来实施本发明,而无论它们是否涉及不同的实施例。因此,下面的方面、特征、实施例和优点仅作说明之用而不应被看作是所附权利要求的要素或限定,除非权利要求中明确提出。
20.如技术背景所述,图像重建可以基于根据一个场景的多个现有视角的图像建立该场景的三维模型。在图像重建的基础上,本领域技术人员可以基于建立的三维模型生成新视角的图像,该新视角不属于现有的多个视角。图1示出了根据一个场景的多个现有视角的图像建立该场景的三维模型的示意图。根据图1,3个图像110为一个场景的3个现有视角的图像,三维模型120为根据图像110重建的该场景三维模型。图1中仅仅示出了一个场景的3个现有视角的图像,本领域技术人员可以知道,可以使用更多的现有视角图像建立相关场景的三维模型。现有技术有多种图像重建方法,例如nerf、nv、llff等基于神经网络的方法,以及colmap、sfm、orbslam等传统方法。基于神经网络的方法以其生成质量高的优点,现在正在被广泛使用。但是现有的基于神经网络的方法由于其使用了均匀采样和由粗到细的采样及基于频率的位置编码方法导致其训练速度慢,通常生成一个三维模型训练时间要花费8-12个小时,这也限制了其广泛的使用。
21.图2示出了基于图1中建立的三维模型生成的新视角的图像的示意图,其中图2a中示出了针对图1中建立的三维模型的现有视角210和220,以及针对图1中建立的三维模型的新视角230,可见,新视角230是不同于现有视角210和220的。图2b为针对新视角230生成的图像。
22.在现有的图像重建技术方案中,首先要将一个场景的多个现有视角的图像作为训练样本,其神经辐射场模型的输入仅仅为训练样本的视角。在训练过程中,现有技术对训练样本进行采样是从相机到某一训练样本图像像素的视线上采样若干采样点。再将采样点进行位置编码得到采样点对应的特征向量,再将特征向量输入多层感知机神经网络得到每个采样点的密度和颜色;神经辐射场模型将密度和颜色积分得到图像像素的输出颜色作为神经辐射场模型的输出。通过对比训练样本图像像素的输出颜色和训练样本图像像素的真实颜色计算损失函数,再通过损失函数和优化器迭代优化模型参数。
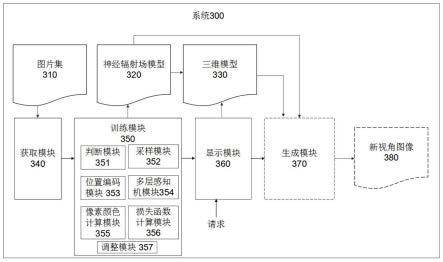
23.现有的图像重建技术方案中,采样方法是通过设置场景到相机的最近距离和最远距离。在一条视线上的最近距离到最近距离位置之间进行均匀采样,得到均匀粗采样点。将粗采样点通过现有的位置编码、多层感知机模型(multilayer perceptron,mlp)、积分,得出每个采样点的密度,然后在密度高的地方密集采样,得到细采样点。粗采样点和细采样点合并即为现有方法的总采样点。该方法由于没有场景的大致几何结构,只能通过均匀采样大致确定场景密度高的位置,而均匀采样就会导致很多采样点是无意义的。这些无意义的采样点也要经过位置编码、mlp、积分等等的计算,会带来额外的时间损耗。
24.在现有的图像重建中,位置编码采用频率编码的方法。具体方法是,对于采样点坐标(x,y,z),分别通过公式:
25.γ(p)=(sin(20πp),(os(20πp),
···
,sin(2
l-1
πp),cos(2
l-1
πp)).转换为频域特征。该方法对场景中细致部分表征能力有限,并且对于训练更难收敛,造成训练时间过长。因此现有的神经辐射场训练时间大约为8-12小时,导致其无法用于需要极短时间的场景重建。
26.本发明提出了一种图像重建的方法,该方法在训练过程中所述神经辐射场模型的输入为训练样本的视角以及存储在哈希表中的特征,存储在哈希表中的特征是通过(对采样点的位置进行哈希编码(称为基于哈希编码的位置编码),并根据编码值索引存储在哈希表中的特征来获得的。该位置编码方式相比于现有技术的基于频率的位置编码方法有更强的表达能力,从而加速训练。本发明还进一步采用了基于密度体素网格的采样方法,该方法相比于现有技术的基于均匀采样的采样方法,能够在训练过程中迭代地恢复场景的粗略体素网格,并根据粗略体素网格模型进行更准确的采样,从而减少采样点数、增加采样准确性,进而提升训练速度。神经辐射场模型已经广泛应用于图像重建,本文采用的神经辐射场模型的数据结构与现有技术基本相同,因此本文将不再详细描述神经辐射场模型的具体数据结构。
27.图3示出了根据本发明实施例的一种图像重建的系统300的结构框图。如图3所示,系统300包括获取模块340,训练模块350,以及显示模块360。获取模块340被配置为获取一个场景的多个现有视角的图像310。训练模块350被配置为将获取模块340获取的多个现有视角的图像310作为训练样本,训练一个神经辐射场模型320,其中所述训练模块350包括位置编码模块353,所述位置编码模块被配置为对采样点的位置进行哈希编码,并根据编码值
索引存储在哈希表中的特征,训练模块350输出完成训练的神经辐射场模型320。显示模块360被配置为显示训练模块350训练的神经辐射场模型320对应的所述场景的三维模型330。在优选的实施方式中,系统300还包括生成模块370,该生成模块370被配置为响应于从显示模块360接收到显示所述场景的所述三维模型330的一个新视角的图像380的请求,根据训练模块350训练的神经辐射场模型320,输出所述场景的所述三维模型330的新视角的图像380。该生成模块370可以使用现有技术方法生成新视角的图像。
28.参考图3,获取模块340获得的一个场景的多个现有视角的图像310包括多个图像310的每个图像的视角(拍摄视角),以及多个图像310的每个图像的像素(包括像素位置、像素值(rgb))。
29.训练模块350被配置为将获取模块340获取的多个现有视角的图像310作为训练样本,训练一个神经辐射场模型320。该神经辐射场模型的输入为训练样本的视角以及存储在哈希表中的特征。训练模块350包括判断模块351、采样模块352、位置编码模块353、多层感知机模块354、像素颜色计算模块355、损失函数计算模块356以及调整模块357。
30.图4示出了根据本发明实施例的训练模块350的流程图400。如图4所述,在步骤401,判断模块351判断模型中的参数达到预定要求或训练次数达到预定次数,如果达到预定要求或训练次数达到预定次数则在步骤409输出训练完成的神经辐射场模型然后结束,否则进行(继续)训练。预定要求可以有多种不同的实施方式,例如损失函数达到阈值、损失函数达到极小值等等。
31.在步骤402,采样模块352通过密度体素网格采样获得所述多个训练样本上多个像素对应的多条视线上的多个采样点。关于采样以及采样模块352的具体描述及实现过程在图5-7中详细描述,这里不再赘述。
32.在步骤403,位置编码模块353对采样点的位置进行哈希编码。
33.在步骤404,位置编码模块353根据编码值索引存储在哈希表中的特征。位置编码模块353的具体实现过程在图9中详细描述,这里不再赘述。
34.在步骤405,多层感知机模块354基于所述多个训练样本的视角和所述存储在哈希表的特征,计算所述采样模块的所述多个采样点的颜色和密度。在一个实施例中,先将特征输入使用有2层隐藏层神经元个数为64的全连接层,再通过分别通过输出维度为3和1的全连接层分别输出颜色和密度。本领域技术人员可以知道上述的隐藏层层数、神经元个数可以采用任何其他层数或个数。
35.在步骤406,像素颜色计算模块355利用体渲染将所述采样模块的所述多个采样点通过密度积分计算所述多个像素的颜色,作为所述神经辐射场模型的输出的多个像素的颜色。像素颜色计算模块355可以使用现有的体渲染方法或者使用本领域技术人员已知的任何其他密度积分计算方法。像素颜色计算模块355的具体计算过程在以下图8中给出示例,这里不再赘述。
36.在步骤407,损失函数计算模块356通过将所述神经辐射场模型的输出的所述多个像素的颜色和训练样本的相同位置的所述多个像素的真实颜色进行比较计算损失函数。一种实施方式是,通过huber loss函数计算损失函数。另一种实施方式中,也可以通过mseloss函数计算损失函数。在又一种实施方式中,也可以通过l1loss函数计算损失函数。本领域技术人员也可以使用现有的其他函数或将来开发的函数计算损失函数。
37.在步骤408,调整模块357利用所述损失函数计算模块计算的损失函数调整所述哈希表中存储的特征和所述神经辐射场模型中的其他参数。在一种实施方式中,优化器采用adam优化器,学习率使用0.01作为初始值进行训练。在另一种实施方式中,优化器采用sgd优化器,学习率使用0.05作为初始值进行训练。在又一种实施方式中,优化器采用rmsprop优化器,学习率使用0.1作为初始值进行训练。本领域技术人员也可以使用现有的其他优化器或将来开发的优化器并且学习率也可以采用其他数值作为初始值进行训练。在调整模块357调整了哈希表中存储的特征和所述神经网络模型存储的其他参数后,判断模块351继续在步骤401中进行判断。
38.在一个实施例中,采样模块352是通过密度体素网格采样获得采样点的。图5示出了根据本发明实施例的图1对应的场景的三维模型的密度体素网格的示意图。图5a示出了根据本发明实施例的图1对应的场景的三维模型的图像重建空间中真实场景的示意图。图5b示出了将图5a的图像重建空间均匀划分为密度体素网格的示意图。密度体素网格是将图像重建空间划分为多个单位立方体。图5c示出了利用密度体素网格表示图5a的三维模型的图像重建空间的几何结构,其中每个密度体素网格的值表示该密度体素网格内是否存在物体,例如1表示存在物体,0表示不存在物体。本领域技术人员知道也可以使用其他的值表示密度体素网格内是否存在物体。图5c为密度体素网格的值为1所有密度体素网格的示意图。使用密度体素网格,只需要针对值为1的密度体素网格进行采样,从而减少计算量。
39.图6示出了根据本发明实施例的如何对密度体素网格进行采样的示意图。图6a示出了采样的示意图,其中610为相机到某一训练样本的一图像像素的对应视线,620为该视线上的3个采样点。图6b示出了密度体素网格采样的示意图,其中视线630穿过的值为1的密度体素网格640,则在密度体素网格640内视线630的方向上进行采样。如果视线630穿过的密度体素网格的值都为0,那么就不进行采样。
40.图7示出了根据本发明实施例的针对一条视线上的密度体素网格采样模块的采样流程图700。如图7所示,在步骤701,遍历该视线穿过的密度体素网格。在一种实施方式中,先求出视线与整个密度体素网格的交点,以离相机最近的交点作为初始点,每次向视线方向前进一定距离,以到达下一个密度体素网格,重复上述步骤以遍历视线穿过的密度体素网格。
41.在步骤702判断是否完成遍历,如果完成遍历则进行步骤705,即汇集所有采样点并输出,针对一条视线上的密度体素网格采样结束。否则进行步骤703。
42.在步骤703,判断当前密度体素网格的值是否为1,即当前密度体素网格内部是否存在物体,如果值不为1则进行步骤701,即继续遍历密度体素网格,否则进行步骤704。
43.在步骤704,在存在物体的密度体素网格内沿视线方向进行采样。在一种实施方式中,将视线与当前密度体素网格求交点,在两个交点间进行固定数量(如10个采样点)的均匀采样。本领域技术人员知道,也可以采用其他的非均匀采样方法。
44.在一种实施方式中,每一轮训练都要进行采样,需要判断是否训练的迭代次数达到一定间隔,如果达到一定间隔,通过所述三维模型的图像重建空间的密度,对所述三维模型的图像重建空间的对应位置的密度体素网络进行更新。例如,每10轮训练就更新一次密度体素网格的值。具体如何更新密度体素网格,可以在每个密度体素网格内随机采样,然后计算采样点密度,通过密度体素网格内采样点密度更新密度体素网格的值。本领域技术人
员知道,也可以采用其他的方法进行密度体素网格的更新。该方法相比于现有技术的基于均匀采样的采样方法,能够在训练过程中迭代地恢复场景的粗略体素网格,并根据粗略体素网格模型进行更准确的采样,从而减少采样点数、增加采样准确性,进而提升训练速度。
45.在一种实施方式中,像素颜色计算模块355通过体渲染将视线上的采样点通过密度积分计算出的像素颜色。像素颜色计算模块355可以使用现有的体渲染方法或者使用本领域技术人员已知的任何其他密度积分计算方法。图8示出了根据本发明实施例的像素颜色计算模块355进行体渲染的示意图。根据图8,在视线方向810,计算出了颜色和密度的采样点820,将采样点820的颜色及密度信息通过密度积分可以计算出视线810对应像素830的渲染颜色。
46.图9示出了根据本发明实施例的位置编码模块353的流程图900。如图9所述,在步骤901,将三维模型的图像重建空间表示为多个离散体素的组合。离散体素的组合不同于上述密度体素网格,但其基本概念类似,也是把图像重建空间表示为多个单位立方体,但是仅仅是一个空间的划分,并不考虑空间中是否存在物体。
47.在步骤902,获得图像重建空间的位置坐标对应的离散体素的位置。
48.在步骤903,对离散体素的位置进行哈希编码。一种实施方式是,假设对于离散体素的位置是(x,y,z),则通过不连续哈希函数h(x,y,z)=(x*p1+y*p2+z*p3)%m进行哈希编码,其中p1、p2、p3为3个不同质数,m为哈希表大小。哈希函数h的哈希编码值为0~m-1之间的整数。
49.在步骤904,根据哈希编码获取哈希表的下标。
50.在步骤905,根据哈希编码的下标获得哈希表中存储的特征,然后结束。哈希表中存储的特征在训练初始时就被初始化为随机数,训练过程中被调整模块357根据损失函数更新,其表征了图像重建空间中位置坐标对应位置的相关信息。哈希表中存储的特征会作为多层感知机模块354的输入。可见,哈希表中存储的特征是作为训练神经辐射场模型的输入的,哈希表中存储的特征是基于本发明的位置编码获得的,该位置编码方式相比于现有技术的基于频率的位置编码方法有更强的表达能力,从而使得模型的训练收敛的速度更快。
51.图10示出了使用本发明的图像重建方法与现有方法得到的不同新视角图像的结果对比。在图10的对比中,采用乐高场景200张不同视角图像作为训练数据,另外200张不同视角图像作为测试数据,进行实验。现有方法训练5秒显示的三维模型图像的新视角图像如图10a所示,现有方法训练8小时显示的三维模型图像的新视角图像如10b所示。本方法训练5秒显示的三维模型图像的新视角图像如图10c所示,真实场景的三维模型图像的新视角图像为图10d。本发明的方法能够在5秒时间重建,效果远好于现有方法5秒重建的效果,并且和现有方法8小时的重建效果相当。通过该方法进行重建效率能较现有神经辐射场重建方法提升近一万倍,在几秒就能完成高质量重建。
52.在一种实施方式中,将获得的离散体素的位置进行哈希编码中使用多分辨率哈希表示方法,该多分辨率哈希表示方法将空间表示为不同分辨率的离散体素,使用或训练神经辐射场模型时将不同分辨率哈希表中的特征拼接为一个向量,再进行后续计算。例如类似于在图5b中的密度体素网格,使离散体素的组合对应的单位立方大小、个数不同,从而形成多分辨率的哈希表示。例如将分辨率为8(将离散体素的组合立方体划分为8*8*8)的特征
和分辨率为16(将离散体素的组合立方体划分为16*16*16)的特征拼接,形成一个更长的特征,通过这个更长的特征进行训练效果更好。
53.在一种实施方式中,将获得的离散体素的位置进行哈希编码中使用连续或局部连续哈希表示方法,所述连续或局部连续哈希表示方法通过连续或局部连续哈希函数进行哈希映射。例如,可以采用连续哈希函数h(x)=(x+b1)%m,h(y)=(y+b2)%m,h(z)=(z+b3)%m进行哈希编码,使得哈希表的映射具有连续性,从而让哈希表能通过卷积等操作进行进一步优化,进而让神经辐射场模型更有范化性,能够适用于多种不同场景。
54.在一种实施方式中,哈希表是采用生成对抗网络(gan)或者扩散生成模型(diffusion models)方法生成的。把现有的生成对抗网络和扩散生成模型生成2d图像的技术,通过修改其内部的2d卷积算子为3d卷积算子,从而生成哈希表,进而可以减少所需的训练样本数量,加速训练收敛。
55.在一种实施方式中,将获得的离散体素的位置进行哈希编码中使用可微哈希函数,该可微哈希函数使哈希函数的参数或函数定义是可微的,从而通过反向传播优化所述哈希函数。例如,可以将哈希函数h(x,y,z)=(x*p1+y*p2+z*p3)%m、h(x)=(x+b1)%m,h(y)=(y+b2)%m,h(z)=(z+b3)%m中固定的参数p1、p2、p3、b1、b2、b3通过可微方式进行训练,增强哈希函数表达能力,从而能表征更复杂的场景,重建效果更好。
56.以上所述仅是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明技术原理的前提下,还可以做出若干改进和替换,这些改进和替换也应视为本发明的保护范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1