图像处理方法、计算机设备及可读存储介质与流程
1.本发明涉及计算机技术领域。更具体地,涉及一种图像处理方法、计算机设备及可读存储介质。
背景技术:
2.在例如远程视频会议等场景中,通常在一方屏幕上显示的是另一方的摄像头采集的整个会场的图像,但通常来说,这种方式不是最佳的。例如,图像包含的范围较大,而会场中只有少数区域存在参会者,那么覆盖了整个会场的图像就会含有大量的冗余信息,信息接收方体验不佳。目前,解决此问题的通常方式为通过调节摄像头采集视场来限定图像仅包含参会人区域,但这种方式存在一些问题,例如操作不便,再例如无法根据参会者移动位置、会议过程中临时增加参会者等变化而自动调整。
技术实现要素:
3.本发明的目的在于提供一种图像处理方法、计算机设备及可读存储介质,以解决现有技术存在的问题中的至少一个。
4.为达到上述目的,本发明采用下述技术方案:
5.本发明第一方面提供了一种图像处理方法,包括:
6.获取图像采集设备采集的图像,作为原始图像;
7.对所述原始图像进行人形检测,得到人物检测框;以及
8.对人物检测框进行超分辨率处理,生成与原始图像分辨率相同的处理后图像。
9.可选地,所述对人物检测框进行超分辨率处理,生成与原始图像分辨率相同的处理后图像包括:
10.确定所述原始图像中覆盖所有人物检测框的最小覆盖矩形区域;
11.将原始图像横向分辨率与最小覆盖矩形区域横向分辨率的第一比值和原始图像纵向分辨率与最小覆盖矩形区域纵向分辨率的第二比值中的最小值作为放大倍数;
12.对所述最小覆盖矩形区域进行超分辨率处理,以使所述最小覆盖矩形区域的横向分辨率和纵向分辨率分别根据所述放大倍数进行放大,得到放大后的最小覆盖矩形区域;以及
13.判断放大后的最小覆盖矩形区域分辨率与原始图像分辨率是否相同:
14.若是,则将包含放大后的最小覆盖矩形区域的图像作为处理后图像;
15.若否,则对最小覆盖矩形区域进行边缘扩展,得到与原始图像分辨率相同的包含放大后的最小覆盖矩形区域和边缘扩展区域的处理后图像。
16.可选地,所述对最小覆盖矩形区域进行边缘扩展,得到与原始图像分辨率相同的包含放大后的最小覆盖矩形区域和边缘扩展区域的处理后图像,还包括:
17.对放大后的最小覆盖矩形区域进行背景虚化处理。
18.可选地,在对最小覆盖矩形区域进行边缘扩展的情况下,所述方法还包括:在边缘
扩展区域填充原始图像相关信息。
19.可选地,在对最小覆盖矩形区域进行边缘扩展的情况下,所述放大后的最小覆盖矩形区域设置于所述处理后图像的居中位置。
20.可选地,在所述对所述原始图像进行人形检测之后且在所述对人物检测框进行超分辨率处理之前,所述方法还包括:
21.对所述原始图像进行说话人检测,筛除所述人形检测得到的人物检测框中的非说话人的人物检测框。
22.可选地,所述对人物检测框进行超分辨率处理,生成与原始图像分辨率相同的处理后图像包括:
23.计算人物检测框的横向分辨率均值和纵向横向分辨率均值n为人物检测框数量,wn为第n个人物检测框的横向分辨率,hn为第n个人物检测框的纵向分辨率,n为正整数,n为小于或等于n的正整数;
24.计算原始图像横向分辨率w与人物检测框的横向分辨率均值w
mean
的比值ω=w/w
mean
,并计算原始图像纵向分辨率h与人物检测框的纵向分辨率均值h
mean
的比值η=h/h
mean
;
25.对于[n,2n-1]区间中每一个自然数t,进行因子分解t=a*b,得到该自然数t的所有因子分解结果(ak,bk);
[0026]
对于[n,2n-1]区间中的每一自然数t,计算该自然数t的每一因子分解结果对应的调节值θk=min(ω/ak,η/bk),并将该自然数t的每一因子分解结果对应的调节值θk中的最大值作为该自然数t对应的调节值θ
t
,θ
t
=max(θk);
[0027]
将[n,2n-1]区间中的各自然数t对应的调节值中的最大值作为超分辨率调节值θ
#
,θ
#
=max(θ
t
),并确定超分辨率调节值θ
#
对应的自然数t及因子分解结果(a
#
,b
#
);
[0028]
生成与原始图像分辨率相同的空白图像,并将所述空白图像划分为b
#
*a
#
排列的子图像区域;以及
[0029]
对各人物检测框分别进行超分辨率处理以使各人物检测框的横向分辨率为θ
#
*w
mean
且纵向分辨率为θ
#
*h
mean
,并将超分辨率处理后的各人物检测框分别填充至一个子图像区域,得到与原始图像分辨率相同的处理后图像。
[0030]
可选地,所述将超分辨率处理后的各人物检测框分别填充至一个子图像区域包括:
[0031]
计算各人物检测框在原始图像中的中心坐标,根据各人物检测框在原始图像中的中心坐标确定超分辨率处理后的各人物检测框对应的子图像区域。
[0032]
可选地,所述将超分辨率处理后的各人物检测框分别填充至一个子图像区域,得到与原始图像分辨率相同的处理后图像还包括:
[0033]
对填充有超分辨率处理后的人物检测框的子图像区域进行背景虚化处理。
[0034]
可选地,在所述将超分辨率处理后的各人物检测框分别填充至一个子图像区域之后,在存在未对应人物检测框的剩余子图像区域的情况下,所述方法还包括:在所述剩余子图像区域填充原始图像相关信息。
[0035]
本发明第二方面提供了一种计算机设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述程序时实现如本发明第一方面提
供的图像处理方法。
[0036]
本发明第三方面提供了一种计算机可读存储介质,其上存储有计算机程序,该程序被处理器执行时实现如本发明第一方面提供的图像处理方法。
[0037]
本发明的有益效果如下:
[0038]
本发明所述技术方案通过放大例如视频会议图像、行为监测图像等图像中的高价值人物区域的信息,可实现图像有效信息的最大化,提升信息接收方的用户体验。
附图说明
[0039]
下面结合附图对本发明的具体实施方式作进一步详细的说明。
[0040]
图1示出本发明实施例提供的图像处理方法的流程图。
[0041]
图2示出采用第一模式的超分辨率处理步骤的示意图。
[0042]
图3示出采用第二模式的超分辨处理步骤的示意图。
[0043]
图4示出实现本发明实施例提供的服务器的计算机系统的结构示意图。
具体实施方式
[0044]
为了更清楚地说明本发明,下面结合实施例和附图对本发明做进一步的说明。附图中相似的部件以相同的附图标记进行表示。本领域技术人员应当理解,下面所具体描述的内容是说明性的而非限制性的,不应以此限制本发明的保护范围。
[0045]
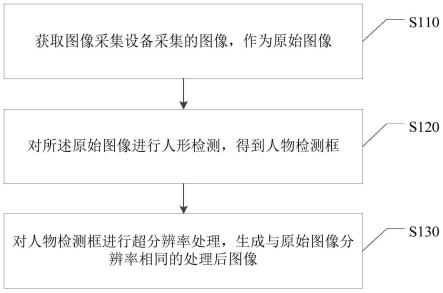
本发明实施例提供了一种图像处理方法,包括如下步骤:
[0046]
获取图像采集设备采集的图像,作为原始图像;
[0047]
对所述原始图像进行人形检测,得到人物检测框;以及
[0048]
对人物检测框进行超分辨率处理,生成与原始图像分辨率相同的处理后图像。
[0049]
本发明实施例提供的图像处理方法,通过放大例如视频会议图像、行为监测图像等图像中的高价值人物区域的信息,可实现图像有效信息的最大化,提升信息接收方的用户体验。其中,通过人形检测来确定人物区域的方式,可实现自动检测,并可随人物移动位置、图像中人物的增减等变化而自动调整。
[0050]
本实施例提供的图像处理方法可以通过具有数据可通处理能力的计算机设备来实现,具体的,该计算机设备可以为具有数据处理能力的计算机,包括个人计算机(pc,personal computer)、小型机或者大型机,也可以是具有数据处理能力的服务器或者服务器集群等,本实施例对此不做限定。
[0051]
接下来,从具有数据处理能力的处理设备的角度,以应用于远程视频会议等场景为例,对本实施例提供的一种图像处理方法进行说明。
[0052]
本发明的一个实施例提供了一种图像处理方法,如图1所示,包括如下步骤:
[0053]
s110、获取图像采集设备采集的图像,作为原始图像。
[0054]
在远程视频会议等场景中,图像采集设备例如为会议室上方设置的用于采集会场图像的摄像头,执行图像处理方法的计算机设备与摄像头连接,可实时获取摄像头采集的视频会议图像(通常为整个会场图像),原始图像为视频会议图像。
[0055]
s120、对所述原始图像进行人形检测,得到人物检测框。
[0056]
步骤s120采用的人形检测,相比于人脸检测、头部检测等,检测范围更宽泛,只要
是图像中出现人物,不管是什么姿势,是否低头或者背对例如会议室上方摄像头的图像采集装置,都可以进行检测。例如,人形检测可以采用yolo(you only look once)v5等深度学习模型实现,也可以采用基于hog和svm等机器学习模型实现。
[0057]
在一个具体示例中,步骤s120的人形检测采用yolov5模型实现,例如,利用已训练的yolov5模型对原始图像(视频会议图像)进行人形检测,得到人物检测框(参会人检测框){pi|i=1,..,n},n为原始图像中的人物(参会人)数量。
[0058]
yolo(you only look once)模型,是一种基于深度神经网络的对象识别和定位模型。yolov5模型识别效果较好,且推理速度很快,有利于上线部署。同时,yolov5在模型网络结构和锚点框设计上考虑到目标多尺度情况,能很好解决尺寸较小的目标(人物)的识别问题。在对yolov5模型进行训练时,yolov5模型会通过数据加载器传递并增强每一批训练数据(数据加载器进行三种数据增强:缩放,色彩空间调整和马赛克增强),这种处理对训练数据进行了充分的增广,极大提高了模型的泛化能力。例如,yolov5模型包括骨干(backbone)网络、融合网络以及边框预测层,其中,骨干网络可以是卷积神经网络,用于对图像进行多个层次上采样处理得到不同细粒度(分辨率)的图像,每个层次对应的上采样特征图的细粒度大于上一层次,并提取每个上采样特征图的图像特征。融合网络包括一系列混合和组合图像特征的网络层,融合网络可以是特征融合金字塔(fpn,feature pyramid networks)或者路径聚合网络(panet,path aggregation network),用于将图像特征融合,并将融合图像特征传递到边框预测层。边框预测层用于生成待识别目标对应的边界框,并基于边界框将待识别目标从待识别图像中分割出来,得到待识别目标,即人物检测框。
[0059]
s130、对人物检测框进行超分辨率处理,生成与原始图像分辨率相同的处理后图像。
[0060]
在远程视频会议等场景中,在本地处理后图像之后,可传输至视频会议的另一方进行显示,由此,可实现视频会议图像中有效信息的最大化,提升视频会议的另一方,即信息接收方的用户体验。
[0061]
在一种可能的实现方式中,在步骤s120之后且在步骤s130之前,本实施例提供的图像处理方法还包括:
[0062]
对所述原始图像进行说话人检测,筛除所述人形检测得到的人物检测框中的非说话人的人物检测框。
[0063]
在远程视频会议等场景中,本实现方式,在人形检测的基础之上,判断参会人中正在发言的说话人,仅采用说话人的人物检测框行后续的超分辨率处理流程,而无需采用非说话人的人物检测框执行后续的超分辨率处理流程,例如进行说话人检测后在双方视频会议中,一方的参会者中仅有一个说话人,那么仅对这个说话人的人物检测框进行超分辨率处理,仅将超分辨率处理后的包含该说话人的画面展示给另一方,如果后续说话人变化,则根据实时检测结果将超分辨率处理后的包含新的说话人的画面展示给另一方。本实现方式中,可以采用resnet、densenet等卷积神经网络实现说话人检测,例如通过提取人物的唇部特征信息进行识别检测。
[0064]
下面继续介绍步骤s130,步骤s130为超分辨率处理步骤,对于步骤s130,本实施例在下述可能实现方式中提供了两种模式,例如,用户可通过执行图像处理方法的计算机设备的例如鼠标、键盘、触控屏等输入装置进行模式选择。
[0065]
下面对s130的超分辨率处理步骤的两种模式分别说明进行。
[0066]
第一模式
[0067]
在第一模式中,步骤s130进一步包括子步骤s1311-s1314:
[0068]
s1311、确定所述原始图像中覆盖所有人物检测框的最小覆盖矩形区域。
[0069]
在一个具体示例中,在已得到人物检测框(参会人检测框){pi|i=1,..,n},n为原始图像中的人物(参会人)数量的情况下,确定能够覆盖所有人物检测框{pi|i=1,..,n}的矩形中最小的,作为最小覆盖矩形区域r。确定最小覆盖矩形区域r的方法例如:确定所有人物检测框{pi|i=1,..,n}的横坐标最大值和最小值分别记为x
max
和x
min
,并确定所有人物检测框{pi|i=1,..,n}的纵坐标最大值和最小值分别记为y
max
和y
min
,确定最小覆盖矩形区域r的4个顶点坐标分别为(x
min
,y
max
)、(x
max
,y
max
)、(x
min
,y
min
)和(x
max
,y
min
),或者说,最小覆盖矩形区域r为以(x
min
,y
min
)与(x
max
,y
max
)的连线为对角线的矩形区域。
[0070]
s1312、将原始图像横向分辨率与最小覆盖矩形区域横向分辨率的第一比值和原始图像纵向分辨率与最小覆盖矩形区域纵向分辨率的第二比值中的最小值作为放大倍数。
[0071]
在一个具体示例中,设原始图像横向分辨率(原始图像宽度)为w,原始图像纵向分辨率(原始图像高度)为h,最小覆盖矩形区域r横向分辨率(最小覆盖矩形区域r宽度)为wr,最小覆盖矩形区域r纵向分辨率(最小覆盖矩形区域r高度)为hr,则放大倍数为s=min(w/wr,h/hr)。
[0072]
s1313、对所述最小覆盖矩形区域进行超分辨率处理,以使所述最小覆盖矩形区域的横向分辨率和纵向分辨率分别根据所述放大倍数进行放大,得到放大后的最小覆盖矩形区域。
[0073]
在一个具体示例中,利用超分辨率处理将最小覆盖矩形区域r放大s倍,得到放大后的最小覆盖矩形区域r1,其中,原始图像中的第i个人物检测框放大为pi`。
[0074]
在一个具体示例中,超分辨率处理可采用基于插值、基于重建和基于学习的方法,例如,采用双线性插值方法。
[0075]
s1314、判断放大后的最小覆盖矩形区域分辨率与原始图像分辨率是否相同:
[0076]
若是,则将包含放大后的最小覆盖矩形区域的图像作为处理后图像,其中,可理解的是,在原始图像横向分辨率w与最小覆盖矩形区域r横向分辨率wr的第一比值w/wr和原始图像纵向分辨率h与最小覆盖矩形区域r纵向分辨率hr的第二比值h/hr相同的情况下,放大后的最小覆盖矩形区域r分辨率与原始图像分辨率相同,在第一比值w/wr和第二比值h/hr不同的情况下,放大后的最小覆盖矩形区域r的横向分辨率会小于原始图像横向分辨率w或者放大后的最小覆盖矩形区域r的纵向分辨率会小于原始图像纵向分辨率h;
[0077]
若否,则对最小覆盖矩形区域进行边缘扩展,得到与原始图像分辨率相同的包含放大后的最小覆盖矩形区域和边缘扩展区域的处理后图像。
[0078]
在一种可能的实现方式中,子步骤s1314中,所述对最小覆盖矩形区域进行边缘扩展,得到与原始图像分辨率相同的包含放大后的最小覆盖矩形区域和边缘扩展区域的处理后图像,还包括:
[0079]
对放大后的最小覆盖矩形区域进行背景虚化处理。
[0080]
这样,结合背景虚化处理,可进一步压缩低价值区域信息,从而进一步提升高信息价值区域的显著性。
[0081]
在一个具体示例中,可通过对放大后的最小覆盖矩形区域中的除了放大后的人物检测框之外的背景区域进行高斯滤波进行模糊化,实现背景虚化。
[0082]
在一种可能的实现方式中,在对最小覆盖矩形区域进行边缘扩展的情况下,子步骤s1314还包括:在边缘扩展区域填充原始图像相关信息。例如,在远程视频会议场景下,原始图像相关信息包括会议名称信息、时间信息、会议室信息、注意事项信息等。
[0083]
在一种可能的实现方式中,子步骤s1314中,在对最小覆盖矩形区域进行边缘扩展的情况下,所述放大后的最小覆盖矩形区域设置于所述处理后图像的居中位置。
[0084]
如果直接将最小覆盖矩形区域超分辨率到原始图像分辨率,很有可能由于长宽比变化会造成人脸的扭曲,影响用户体验。而采用上述第一模式,可在保证人物不变形的前提下,尽量突出人物并显示更多细节,且保证每个人脸区域放大比例一致。另外,第一模式可简单快速实现,适用于人物检测框数量n≥1的情形。
[0085]
在一个具体示例中,采用第一模式的步骤s130中,原始图像、最小覆盖矩形区域和处理后图像如图2所示,图2上方为原始图像,中间为最小覆盖矩形区域,下方为处理后图像。可见,第一模式可有效实现放大例如视频会议图像中的高价值人物区域的信息,从而实现图像有效信息的最大化。
[0086]
第二模式
[0087]
第二模式可称为自适应模式,第二模式中,步骤s130进一步包括子步骤s1321-s1327:
[0088]
s1321、计算人物检测框的横向分辨率均值和纵向横向分辨率均值n为原始图像中的人物检测框数量,wn为第n个人物检测框的横向分辨率(宽度),hn为第n个人物检测框的纵向分辨率(高度),n为正整数,n为小于或等于n的正整数。
[0089]
s1322、计算原始图像横向分辨率w与人物检测框的横向分辨率均值w
mean
的比值ω=w/w
mean
,并计算原始图像纵向分辨率h与人物检测框的纵向分辨率均值h
mean
的比值η=h/h
mean
。
[0090]
s1323、对于[n,2n-1]区间中每一个自然数t,进行因子分解t=a*b,得到该自然数t的所有因子分解结果(ak,bk)。
[0091]
其中,对于不同的自然数t,其因子分解结果的个数可能不同,例如,人物检测框数量n=5,则自然数t的取值为t=5,6,7,8,9。对于t=5,其因子分解结果的集合ф为{(1,5),(5,1)},即对于t=5,k=2。对于t=6,其因子分解结果的集合ф为{(1,6),(2,3),(3,2),(6,1)},即对于t=6,k=4。
[0092]
s1324、对于[n,2n-1]区间中的每一自然数t,计算该自然数t的每一因子分解结果对应的调节值θk=min(ω/ak,η/bk),例如,在一个具体示例中,假如ω=8且η=6,人物检测框数量n=5,则对于t=5的两个因子分解结果(1,5)和(5,1),第1个因子分解结果(1,5)对应的调节值θ1=min(8/1,6/5)=1.2,第2个因子分解结果(5,1)对应的调节值θ2=min(8/5,6/1)=1.6,同理,对于t=6的四个因子分解结果(1,6)、(2,3)、(3,2)和(6,1)对应的调节值分别为1、2、2.67和1.33,对于t=7的两个因子分解结果(1,7)和(7,1)对应的调节值分别为0.86和1.14,对于t=8的四个因子分解结果(1,8)、(2,4)、(4,2)和(8,1)对应的调节值分别
为0.75、1.5、2和1,对于t=9的三个因子分解结果(1,9)、(3,3)和(9,1)对应的调节值分别为0.67、2和0.89。并将该自然数t的每一因子分解结果对应的调节值θk中的最大值作为该自然数t对应的调节值θ
t
,θ
t
=max(θk),例如接续上述示例,t=5对应的调节值θ
t
=max(1.2,1.6)=1.6,同理,t=6对应的调节值θ
t
=2.67,t=7对应的调节值θ
t
=1.14,t=8对应的调节值θ
t
=2,t=9对应的调节值θ
t
=2。
[0093]
s1325、将[n,2n-1]区间中的各自然数t对应的调节值中的最大值作为超分辨率调节值θ
#
,θ
#
=max(θ
t
),并确定超分辨率调节值θ
#
对应的自然数t及因子分解结果(a
#
,b
#
)。接续前述示例,超分辨率调节值θ
#
=2.67,超分辨率调节值θ
#
=2.67对应自然数t=6且对应的因子分解结果为(3,2)。
[0094]
s1326、生成与原始图像分辨率相同的空白图像,并将所述空白图像划分为b
#
*a
#
排列的子图像区域。接续前述示例,将所述空白图像划分为2*3排列子图像区域,即两行三列排列的子图像区域。
[0095]
s1327、对各人物检测框分别进行超分辨率处理以使各人物检测框的横向分辨率为θ
#
*w
mean
且纵向分辨率为θ
#
*h
mean
,接续前述示例,对各人物检测框分别进行超分辨率处理以使各人物检测框的横向分辨率为2.67*w
mean
且纵向分辨率为2.67*h
mean
。并将超分辨率处理后的各人物检测框分别填充至一个子图像区域,得到与原始图像分辨率相同的处理后图像。
[0096]
在一个具体示例中,超分辨率处理可采用基于插值、基于重建和基于学习的方法,例如,采用双线性插值方法。
[0097]
对于步骤s1327,可理解的是,在原始图像中存在多个人物检测框的情况下,极少情况会出现一个或一些人物检测框比其他人物检测框的尺寸大很多的情况,因此,基本上步骤s1327对所有人物检测框都是进行放大。而即使在极端情况下,原始图像存在一个人物检测框比其他人物检测框的尺寸大很多的情况,整体上,步骤s1327对于人物检测框也是进行放大。
[0098]
在一种可能的实现方式中,子步骤s1327中,所述将超分辨率处理后的各人物检测框分别填充至一个子图像区域包括:
[0099]
计算各人物检测框在原始图像中的中心坐标,根据各人物检测框在原始图像中的中心坐标确定超分辨率处理后的各人物检测框对应的子图像区域。
[0100]
在一个具体示例中,可先按纵坐标由上至下排序,再按横坐标由左至右排序,以使得处理后图像中的各超分辨率处理后的人物检测框的相对位置关系尽量贴近原始图像中的各人物检测框的相对位置关系。具体而言,接续前述示例,先确定计算每个人物检测框在原始图像中的中心坐标,将人物检测框中心的纵坐标从上到下排序(当2个或多个人物检测框的纵坐标相同时,内部可采用顺序随机排列),第1到a
#
个对应在第1行子图像区域,第a
#
+1到第2a
#
个对应在第2行子图像区域,以此类推,最后一排放第(b
#-1)*a
#
+1到第n个(可能不满a
#
个)对应在第最后一行子图像区域。然后,在同一行子图像区域之中,将人物检测框中心的横坐标从左到右排序(当2个或多个人物检测框的横坐标相同时,内部可采用顺序随机排列),按此顺序依次居中填入对应的子图像区域。
[0101]
在一种可能的实现方式中,子步骤s1327中,所述将超分辨率处理后的各人物检测框分别填充至一个子图像区域,得到与原始图像分辨率相同的处理后图像还包括:
[0102]
对填充有超分辨率处理后的人物检测框的子图像区域进行背景虚化处理。
[0103]
在一个具体示例中,子图像区域的尺寸可能大于超分辨率处理后的人物检测框,可通过对子图像区域中的除了超分辨率处理后的人物检测框之外的背景区域填充人脸检测框边缘区域的像素值后进行高斯滤波进行模糊化,实现背景虚化。
[0104]
在一种可能的实现方式中,在所述将超分辨率处理后的各人物检测框分别填充至一个子图像区域之后,在存在未对应人物检测框的剩余子图像区域的情况下,子步骤s1327还包括:在所述剩余子图像区域填充原始图像相关信息。
[0105]
例如,在远程视频会议场景下,原始图像相关信息包括会议名称信息、时间信息、会议室信息、注意事项信息等。
[0106]
接续前述示例,采用第二模式的步骤s130中,原始图像和处理后图像如图3所示,图3上方为原始图像,下方为处理后图像。可见,第二模式可有效实现放大例如视频会议图像中的高价值人物区域的信息,从而实现图像有效信息的最大化。
[0107]
可理解的是,第二模式适用于人物检测框数量n≥1的情形,其中用于n>1的情形更加合适。
[0108]
本发明的另一个实施例提供了一种服务器,包括:
[0109]
获取模块,用于获取图像采集设备采集的图像,作为原始图像;
[0110]
检测模块,用于对所述原始图像进行人形检测,得到人物检测框;以及
[0111]
超分模块,用于对人物检测框进行超分辨率处理,生成与原始图像分辨率相同的处理后图像。
[0112]
需要说明的是,本实施例提供的服务器的原理及工作流程与上述图像处理方法相似,相关之处可以参照上述说明,在此不再赘述。
[0113]
如图4所示,适于用来实现上述实施例提供的服务器的计算机系统,包括中央处理模块(cpu),其可以根据存储在只读存储器(rom)中的程序或者从存储部分加载到随机访问存储器(ram)中的程序而执行各种适当的动作和处理。在ram中,还存储有计算机系统操作所需的各种程序和数据。cpu、rom以及ram通过总线被此相连。输入/输入(i/o)接口也连接至总线。
[0114]
以下部件连接至i/o接口:包括键盘、鼠标等的输入部分;包括诸如液晶显示器(lcd)等以及扬声器等的输出部分;包括硬盘等的存储部分;以及包括诸如lan卡、调制解调器等的网络接口卡的通信部分。通信部分经由诸如因特网的网络执行通信处理。驱动器也根据需要连接至i/o接口。可拆卸介质,诸如磁盘、光盘、磁光盘、半导体存储器等等,根据需要安装在驱动器上,以便于从其上读出的计算机程序根据需要被安装入存储部分。
[0115]
特别地,根据本实施例,上文流程图描述的过程可以被实现为计算机软件程序。例如,本实施例包括一种计算机程序产品,其包括有形地包含在计算机可读介质上的计算机程序,上述计算机程序包含用于执行流程图所示的方法的程序代码。在这样的实施例中,该计算机程序可以通过通信部分从网络上被下载和安装,和/或从可拆卸介质被安装。
[0116]
附图中的流程图和示意图,图示了本实施例的系统、方法和计算机程序产品的可能实现的体系架构、功能和操作。在这点上,流程图或示意图中的每个方框可以代表一个模块、程序段或代码的一部分,上述模块、程序段或代码的一部分包含一个或多个用于实现规定的逻辑功能的可执行指令。也应当注意,在有些作为替换的实现中,方框中所标注的功能
也可以以不同于附图中所标注的顺序发生。例如,两个接连地表示的方框实际上可以基本并行地执行,它们有时也可以按相反的顺序执行,这依所涉及的功能而定。也要注意的是,示意图和/或流程图中的每个方框、以及示意和/或流程图中的方框的组合,可以用执行规定的功能或操作的专用的基于硬件的系统来实现,或者可以用专用硬件与计算机指令的组合来实现。
[0117]
描述于本实施例中所涉及到的模块可以通过软件的方式实现,也可以通过硬件的方式来实现。所描述的模块也可以设置在处理器中,例如,可以描述为:一种处理器,包括获取模块、检测模块和超分模块。其中,这些模块的名称在某种情况下并不构成对该模块本身的限定。例如,超分模块还可以被描述为“超分辨率模块”。
[0118]
作为另一方面,本实施例还提供了一种非易失性计算机存储介质,该非易失性计算机存储介质可以是上述实施例中上述装置中所包含的非易失性计算机存储介质,也可以是单独存在,未装配入终端中的非易失性计算机存储介质。上述非易失性计算机存储介质存储有一个或者多个程序,当上述一个或者多个程序被一个设备执行时,使得上述设备:获取图像采集设备采集的图像,作为原始图像;对所述原始图像进行人形检测,得到人物检测框;对人物检测框进行超分辨率处理,生成与原始图像分辨率相同的处理后图像。
[0119]
在本发明的描述中,需要说明的是,术语“上”、“下”等指示的方位或位置关系为基于附图所示的方位或位置关系,仅是为了便于描述本发明和简化描述,而不是指示或暗示所指的装置或元件必须具有特定的方位、以特定的方位构造和操作,因此不能理解为对本发明的限制。除非另有明确的规定和限定,术语“安装”、“相连”、“连接”应做广义理解,例如,可以是固定连接,也可以是可拆卸连接,或一体地连接;可以是机械连接,也可以是电连接;可以是直接相连,也可以通过中间媒介间接相连,可以是两个元件内部的连通。对于本领域的普通技术人员而言,可以根据具体情况理解上述术语在本发明中的具体含义。
[0120]
还需要说明的是,在本发明的描述中,诸如第一和第二等之类的关系术语仅仅用来将一个实体或者操作与另一个实体或操作区分开来,而不一定要求或者暗示这些实体或操作之间存在任何这种实际的关系或者顺序。而且,术语“包括”、“包含”或者其任何其他变体意在涵盖非排他性的包含,从而使得包括一系列要素的过程、方法、物品或者设备不仅包括那些要素,而且还包括没有明确列出的其他要素,或者是还包括为这种过程、方法、物品或者设备所固有的要素。在没有更多限制的情况下,由语句“包括一个
……”
限定的要素,并不排除在包括所述要素的过程、方法、物品或者设备中还存在另外的相同要素。
[0121]
显然,本发明的上述实施例仅仅是为清楚地说明本发明所作的举例,而并非是对本发明的实施方式的限定,对于本领域的普通技术人员来说,在上述说明的基础上还可以做出其它不同形式的变化或变动,这里无法对所有的实施方式予以穷举,凡是属于本发明的技术方案所引伸出的显而易见的变化或变动仍处于本发明的保护范围之列。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1