一种基于社交数据的区域高速路网车流状态分析方法与流程
本发明涉及交通领域。具体而言涉及一种基于社交网络的区域高速路网车流状态分析方法。
背景技术:
随着基于地理位置的社交网络(Location-based Social Network,LBSN)服务的快速发展和使用人数的迅速增长,基于LBSN的用户行为挖掘分析日益成为研究的热点。结合GPS、移动终端分享技术和Web2.0,用户可以实时记录个人动态并分享所在位置。常见的LBSN如微波、微信朋友圈、Facebook、Twitter等,包含了地理网络层、社交网络层、信息内容层和时间轴的多层框架。由于LBSN包含了用户现实生活行为多方面的信息,因而能更真实地反映用户的现实生活行为,为分析用户群体行为提供了庞大而丰富的数据。
由于LBSN能够提供用户地理位置及信息内容,因此利用LBSN进行节假日期间的区域路网的车流状态分析是可行且富有创新性的。目前的车流状态分析大部分是基于传统的交通信息收集技术,如浮动车技术,存在渗透率低,设备成本较高的问题。相较于传统的交通信息数据收集系统,基于LBSN的用户渗透率更高。以新浪微博为例,日活跃用户超过五千万,日均发布约1.2亿条微博(2012年)。对某一用户或多个用户的带有时间信息,地理位置信息及文字内容信息的微博进行聚类分析,能够绿色高效地获得用户的出行OD点(起终点),再结合用户发布信息的挖掘分析,能够提取出与区域路网车流状态的相关信息,从而可以进行车流的状态分析作为路网状态分析的补充手段。这种方法充分发挥了交通大数据技术的优势,提高了社交网络海量数据的价值。
技术实现要素:
本发明旨在利用基于地理位置的社交网络(LBSN)所发布的带有地理位置信息、时间标签等信息的文字消息,分析区域路网的车流运行状态,为相关部门在车流高峰期间的交通管控提供数据支持,并为人们的日常出行提供指导。它主要是用采集到的社交平台的信息,对这些信息进行挖掘和聚类,得到用户的出行的OD点。经过统计得到节假日期间不同OD点间的车流运行状态。
本发明是一种基于社交网络的区域高速路网车流状态分析方法,主要通过以下步骤实现:
步骤一:采集基于地理位置的社交网络(LBSN)发布的信息,得到地理位置、时间信息、文字信息等内容;
步骤二:将采集到的信息进行清洗和挖掘,剔除无效和错误数据,并通过聚类方法得到用户节假日和非节假日的出行OD点。
步骤三:通过统计方法,得到节假日期间不同OD点间的车流运行状态,也即节假日期间某区域路网的路段车流分配。
所述步骤一中,为得到大量有效信息,以国内用户量较多、发布信息内容较多的社交平台——新浪微博为例进行说明,且该平台具有丰富的API接口,可以得到用户的好友列表,读取用户的位置动态,获取用户发布的微博内容等功能。需要指出的是,本发明专利不局限于新浪微博,其他社交平台也能应用。
所述步骤二中,运用聚类算法获得用户的居住地信息与可能出行地的信息,用到K-means聚类算法,其过程为:
(1)采集到的第i个数据定义为向量。
其中,其中x_i1表示第i个点的经度,x_i2表示第i个点的纬度,x_i3表示第i个点的时间,x_i4表示第i个点所对应的微博内容。
(2)聚类得到用户的OD点。定义某一个节假日集的第k个地点聚类中心为:
其中,n表示点的总数;分配系数
然后定义第i个点xi与第k个聚类中心μk之间的距离为:
Dik=(xi-μk)T(xi-μk)
计算步骤包括:先随机初始化聚类均值μ1、μ2、μ3;对每个点xi都找到使Dik最小的k,将i点聚到该中心,并设置该分配系数zik=1;如果所有的zik与上一次迭代没有变化,则停止聚类,输出μ1、μ2、μ3;否则按照①式更新μ1、μ2、μ3;
并用同样的方法得到非节假日集的一个聚类中心ρ1。
(3)当μ1、μ2、μ3、ρ1属于不同地方,认为该用户在节假日期间存在出行行为,将其确定为下一步研究对象。
(4)对该对象的微博内容进行挖掘,将高速公路出行相关的语句字典中内容作为关键字,判断用户是否选择高速公路作为出行路径,若是,则将其确定为研究的目标用户;并统计得到目标用户的总数N;
步骤三:通过统计方法,预测得到节假日期间高速公路的车流量;
所述步骤三中,根据上步确定的目标用户的用户居住地和预测的目的地,定义表示节假日期间第i个城市到第j个城市之间的车流量,表示节假日期间第j个城市到第i个城市之间的车流量。并根据步骤二统计出的目标用户的总数N,定义节假日高速公路微博用户出行率矩阵:
当某区域在节假日期间的高速公路总车流量为W时,则该区域高速路网各路段在节假日期间的车流量为
与现有的技术相比,本发明有益效果在于:
(1)LBSN用户量庞大,相比于其他技术,其渗透率更高,成本低廉,数据量丰富且庞大,更适宜数据挖掘的相关工作。
(2)LBSN的信息来源于人们的日常生活,记录日常生活中人们的真实行为,因而能更贴切的反应人们出行动机和出行行为。
(3)基于K-means的聚类算法易于理解、容易实现,且时间复杂度低,可以客观反映用户OD点的相关性关系。
附图说明
图1为本发明具体实施方式中一种基于社交网络的区域高速路网车流状态分析方法的原理图;
图2为本发明所述的基于社交网络的区域高速路网车流状态分析方法的流程图。
具体实施方式
下面结合附图对本专利的具体实施方式进行详细说明。需要指出的是,该具体实施方式仅仅是对本专利优选技术方案的举例。并不能理解为对本专利保护范围的限制。其目的在于对本发明做进一步的详细说明,以令本领域技术人员参照说明书能够据以实施。
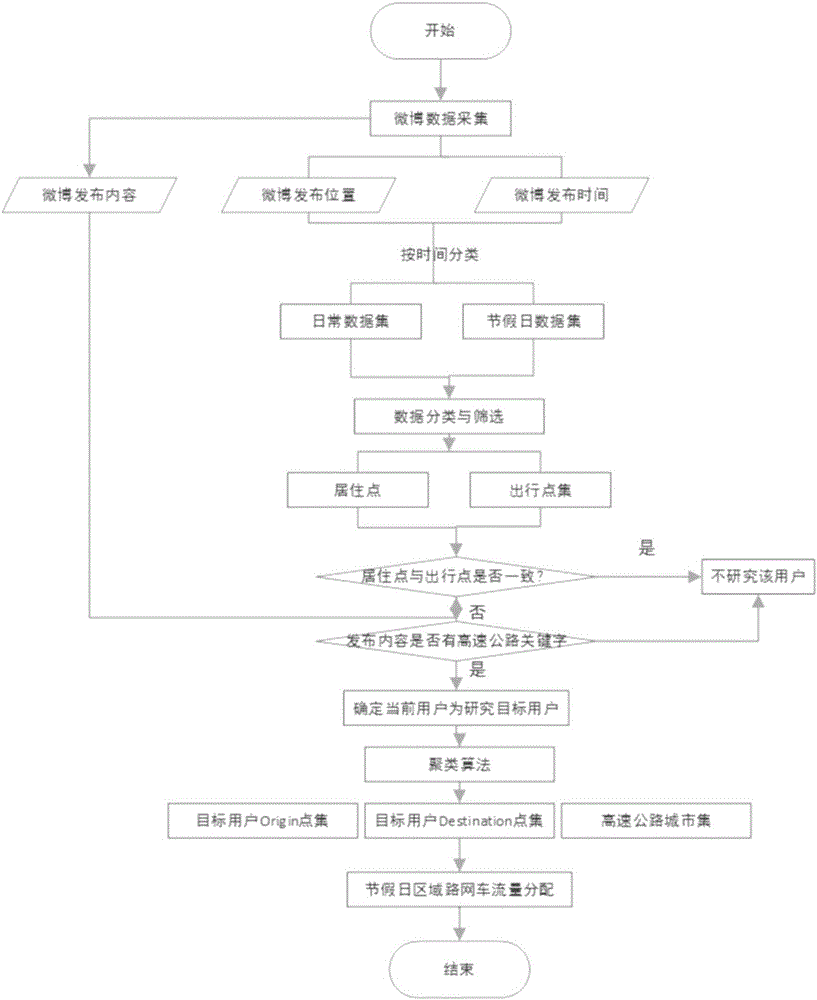
如图1、图2所示。本具体实施方式提供了一种基于社交网络的区域高速路网车流状态分析方法,所述方法包括如下步骤:
步骤一,社交软件数据采集步骤,所述社交软件数据采集包括获取社交软件的信息数据,并从中采集到微博内容、地理位置、时间等信息。
在本步骤中,以微博数据为例,可以利用微博提供的开放接口抓取发布的微博中的相关信息数据。可以通过设置抓取条件的方式来获取上述数据,所述条件包括微博内容、地理位置信息、时间信息、朋友关联关系等。
比如,在地理位置信息中,可以设置北京;抓取的数据的时间信息中,抓取的数据量至少为一个月,并可以不断地实时抓取并更新。
步骤二、对所述数据采集步骤采集到的数据进行挖掘,得到节假日与非节假日期间用户出行的OD点。
在本步骤中,首先将用户数据按照日期切分为非节假日集与节假日集(如:将10月1日至10月7日的用户数据划归至节假日集中),然后利用K-means聚类算法分别对非节假日集与节假日集进行聚类以获得用户的居住地信息与可能出行地的信息。
所述K-means聚类算法包括:K-means算法是很典型的基于距离的聚类算法,采用距离作为相似性的评价指标,即认为两个对象的距离越近,其相似度就越大。该算法认为簇是由距离靠近的对象组成的,因此把得到紧凑且独立的簇作为最终目标。
k个初始类聚类中心点的选取对聚类结果具有较大的影响,因为在该算法第一步中是随机的选取任意k个对象作为初始聚类的中心,初始地代表一个簇。该算法在每次迭代中对数据集中剩余的每个对象,根据其与各个簇中心的距离将每个对象重新赋给最近的簇。当考察完所有数据对象后,一次迭代运算完成,新的聚类中心被计算出来。如果在一次迭代前后,距离的值没有发生变化,说明算法已经收敛。
在本例中,采集到的第i个数据可以定义为向量:(粗体字母代表向量,下同),其中表示第i个点的经度,表示第i个点的纬度,表示第i个点的时间,表示第i个点所对应的微博内容。在计算地点聚类中心之前可以先利用时间进行分类,根据即微博的发布时间将数据集分割为节假日集与非节假日集。例如,可以设定将用户于春节、五一劳动节、端午节、中秋节、国庆节等发布的内容划归到节假日集(每一个假期的数据属于单独的一个节假日集)中,其余时间段发布的内容划归到非节假日集中。这一步实现了初步的数据过滤与分类,有利于后续步骤的聚类。
接下来进行地点聚类,在非节假日集和节假日集中分别选出1个点和3个点作为备选点,即确定聚类中心数k=1和k=3。如此取值的原因是:用户一般有固定的居住地,即会集中居住在某一个城市,而旅游时往往会有几个目的地。先定义某一个节假日集的第k个地点聚类中心为:
其中,分配系数该公式的意义是将参与了该节假日集第k个地点聚类的点的经纬度计算平均值,计算出的经纬度作为第k个聚类中心的坐标。
然后定义第i个点xi与第k个聚类中心μk之间的距离为:
Dik=(xi-μk)T(xi-μk)
(1)先随机初始化聚类均值μ1、μ2、μ3;
(2)对每个点xi都找到使Dik最小的k,将i点聚到该中心,并设置该分配系数zik=1;
(3)如果所有的zik与上一次迭代没有变化,则停止聚类,输出μ1、μ2、μ3;
(4)否则按照①式更新μ1、μ2、μ3;
用同样的办法可以得到非节假日集的一个聚类中心ρ1。
然后结合地图数据判断出μ1、μ2、μ3、ρ1分别属于哪几个城市(精确到地级行政区),例如μ1∈(青岛)、μ2∈(秦皇岛)、μ3∈(烟台)、ρ1∈(北京),那么可以知道该用户居住地在北京,在某一个假期去了青岛、秦皇岛和烟台三个地方游玩,这说明了在该假期期间,北京与青岛、秦皇岛、烟台三个地方之间存在一定客运量。如果μ1、μ2、μ3、ρ1属于不同地方,那么认为该用户在节假日期间存在出行行为,统计所有具有出行行为的用户,设总数为N。如果μ1、μ2、μ3、ρ1属于同一个地方,那么认为该用户在节假日期间没有出行,不将该用户作为研究的目标用户。
然后对该用户的微博数据进行挖掘,如果在节假日期间,该用户发布的内容中包含了“公路”、“高速公路”、“堵”、“拥堵”等与高速公路相关的关键字,那么判断该用户在节假日的出行采取了高速公路的出行方式,从而将该用户设为目标用户进行下一步的研究。统计所有以高速公路出行的微博用户的数量,记为N。
用上述k-means聚类算法既可以实现数据筛选的功能,也可以实现数据聚类的功能,有利于挖掘出用户真正的居住地点(O点)与旅游地点(D点)。
步骤三、统计得到节假日期间不同OD点间的车流运行状态,也即节假日期间某区域路网的路段车流分配。
经过第二步的聚类,得到了单个用户的居住地信息与节假日期间可能的旅游地信息,用同样的方法挖掘出每一个用户的居住地信息与节假日期间可能的旅游地信息。定义节假日高速公路微博用户出行矩阵Q如下:
其中Qij表示第i个城市到第j个城市之间的客运量,Qji表示第j个城市到第i个城市之间的客运量,Qij≠Qji。当i=j时,Qij=0,表示同城不产生高速公路客运量。截至2016年9月30日,我国共有334个地级行政区,所以可取n=334。统计步骤二中目标用户OD点数据,如果客户在节假日期间在城市i与城市j之间存在出行行为,那么Qij加1;如果客户在节假日期间在城市j与城市i之间存在出行行为,那么Qji加1,用这种方式遍历所有目标用户,生成上述OD点矩阵Q。在步骤二中已经统计出所有具有出行行为的用户总数N,所以可以定义节假日高速公路微博用户出行率矩阵η如下:
下面说明社交网络与区域路网车流的统计关系。研究表明,某区域的总人口与该区域高速路网总车流存在一定的关系。而某区域不是所有人都使用微博,因此可以将该区域的微博用户看成是总人口的一个抽样,那么这个抽样的规律能够在一定程度上反映出该区域高速路网车流的规律。假设节假日某区域高速路网中的微博用户总数N中,从城市i到城市j的微博用户数为Qij,那么我们认为,其比率约等于城市i到城市j的高速公路车流占整个区域高速路网的总车流的比率。
假设利用某区域收费站的数据得到其高速路网总车流量为W,那么可以计算出分配到高速公路路段上的车流量为:
- 还没有人留言评论。精彩留言会获得点赞!