一种基于EEMD-IAGA-BP神经网络的船舶交通流预测方法与流程
本发明涉及船舶交通流预测方法
技术领域:
,尤其涉及一种基于eemd-iaga-bp神经网络的船舶交通流预测方法。
背景技术:
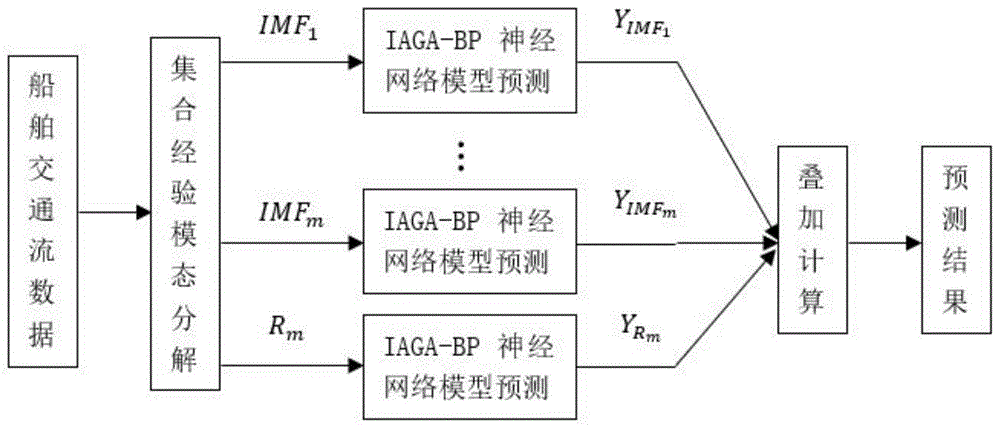
:船舶交通流预测是实现交通控制与诱导的关键,其结果对于船舶的通航安全有重要意义,尤其是在特殊航道、桥区水域等附近,对相关方面的管理者也能提供重要的决策支持,有助于管理部门制定有效的安全办法管理规定和交通组织方案。随着交通流预测领域研究的深入,涌现了很多预测方法,有学者andriusd利用神经网络建立预测模型,摆脱了要求精确模型的限制,并取得了较好效果。但传统的bp算法由于是基于梯度下降的方法,因此不同的初始权向量可能导致完全不同的结果,而且有关的参数选取只能通过实验经验确定,选择不当会导致网络振荡不能收敛,或是陷入局部极值的情况。国内李松有采用遗传算法进行优化,大大降低了bp神经网络预测模型陷入局部极值的可能,提高了模型收敛速度。但传统遗传算法中的交叉概率和变异概率均为定值,导致算法容易早熟。国外有专家srinivasm利用自适应遗传(adaptivegeneticalgorithm)算法进行改进,但在进化初期,交叉概率和变异概率几乎为零,导致进化停滞。在此基础上采用改进的自适应遗传算法,但计算公式存在一定缺陷,导致当群体最大适应度值与平均适应度值相等时进化停滞。其各种改进,均存在数据的非平稳部分会影响预测结果,预测精度低的问题。经验模态分解(empiricalmodedecomposition,emd)方法是上世纪末由huang等提出的一种常用于分析非平稳信号序列的方法,其原理是依据数据本身的时间尺度特征把复杂信号分解为有限个本征模函数(intrinsicmodefunction,imf),得到的各imf分量包含了原信号不同时间尺度的局部特征信号。然而emd方法的一个主要问题是模态混淆,即同一个本征模函数分量中出现了不同尺度或频率的信号,或者同一尺度或频率的信号被分解到多个不同的imf分量当中,同样存在预测准确度不高的问题。技术实现要素:针对现有技术中船舶交通流预测方法的预测精度低的问题,本发明提供了一种基于eemd-iaga-bp神经网络的船舶交通流预测方法,其降低了非平稳性对于预测结果的影响,提高了预测的准确度。为达到上述目的,本发明采用以下技术方案:一种基于eemd-iaga-bp神经网络的船舶交通流预测方法,包括以下步骤:利用单位根检验中的np检验法检验船舶交通流数据的非平稳性;利用集合经验模态分解算法将船舶交通流数据这个非平稳时间序列分解为平稳信号;构建改进自适应遗传算法优化的3层bp神经网络作为训练模型;得到预测结果。在一种优选实施例中,所述预测方法还包括:采用递推方式把船舶交通流数据分为训练集和预测集两部分,训练集部分用于训练上述模型,预测集部分用于测试模型准确性。在一种优选实施例中,单位根检验是指检验序列中是否存在单位根,存在单位根即为非平稳时间序列,单位根指单位根过程,所述np检验法为基于gls除趋势数据的检验单位根的统计量以改善检验的效率和势,该方法称为np检验,相应的统计量称为np检验统计量。在一种优选实施例中,所述集合经验模态分解算法,包括以下步骤:(1)在待分解信号x(t)中加入白噪声n(t)得到加噪声后的总体信号x(t)为:x(t)=x(t)+n(t)(2)对总体信号x(t)进行emd分解,得到一组imf分量cj(t)(j=1,2...m)和一个残余分量rm(t):(3)给待分解信号x(t)加入不同白噪声信号ni(t)(i=1,2...n),重复(1)(2)步骤n次,n为可人工设定的常数,得到不同的总体信号xi(t),以及imf分量cij(t)和残余分量(即rm分量)rim(t),即:(4)为消除多次添加白噪声对实际imf的干扰,对各imf分量进行整体平均计算,获得时序信号的eemd分解结果,即平均imf分量cj(t),计算公式为:在一种优选实施例中,所述3层bp神经网络的构建方法,包括如下步骤:(1)网络拓扑结构:输入层的神经元数量为3,输出层的神经元数量为1,隐藏层的神经元数量为4;(2)初始化权值阈值:在matlab中随机产生初始权值和阈值;(3)采用数据归一化方法对数据进行预处理,把所述船舶交通流数据转化为[0,1]之间的数,计算公式如下:其中,x为所述船舶交通流,xmin为船舶交通流中的最小值,xmax为船舶交通流中的最大值,为归一化后的数据。在一种优选实施例中,所述改进自适应遗传算法,包括如下步骤:(1)选择操作:采用轮盘赌的方法,个体的适应度值记为fi,先计算个体的相对适应度值根据pj(j=1,2,...,n)把圆盘分为n份,转动圆盘,若落入第j个扇形内,则选择个体j;(2)交叉操作:从种群中选择2个个体按照交叉概率及实数交叉法得到新个体如式(1)、(2)所示:其中pc1、pc2分别为交叉概率的上下限,且pc1=0.9、pc2=0.6,;fbigger为参与交叉运算的两个个体中适应度值较大的值,fav为种群的平均适应度值,fmax为种群中最大的适应度值;式中am为第m个染色体,an为第n个染色体,i代表它们在第i位交叉,b为[0,1]之间的随机数;(3)变异操作:从种群中随机选择一个个体按照变异概率计算得到新个体,变异概率算法如式(3)、(4)所示:式中pm为变异概率,pm1、pm2分别为变异概率的上下限,且pm1=0.1、pm2=0.01,pm3=0.07;f为当前进行突变的个体的适应度值,其他符号取值如式(1);式中基因amn为得到的新个体,其上界是amax,下界是amin,g为当前迭代次数,gmax为最大进化次数,r为[0,1]之间的一个随机数,r2为一个随机数。本发明的基于eemd-iaga-bp神经网络的船舶交通流预测方法,构建改进自适应遗传算法优化的3层bp神经网络作为训练模型,数据的非平稳部分对预测结果影响降低,提高了预测的准确度。附图说明构成本申请的一部分附图用来提供对本申请的进一步理解,本申请的示意性实施例及其说明用于解释本申请,并不构成对本申请的不当限定。在附图中:图1为本发明实施例的一种基于eemd-iaga-bp神经网络的船舶交通流预测方法的模型示意图;图2为船舶交通流量变化曲线图;图3为各imf分量对时间序列的曲线图;图4为rm分量随时间序列的变化曲线图;图5为船舶交通流预测结果对比曲线图。具体实施方式本发明提供一种基于eemd-iaga-bp神经网络的船舶交通流预测方法,为使本发明的目的、技术方案及效果更加清楚、明确,以下参照附图并举实例对本发明进一步详细说明。应当理解,此处所描述的具体实施例仅用以解释本发明,并不用于限定本发明。需要说明的是,本发明的说明书和权利要求书及上述附图中的术语“第一”、“第二”等是用于区别类似的对象,而不必用于描述特定的顺序或先后次序,应该理解这样使用的数据在适当情况下可以互换。此外,术语“包括”和“具有”以及它们的任何变形,意图在于覆盖不排他的包含,例如,包含了一系列单元的系统、产品或设备不必限于清楚地列出的那些单元,而是可包括没有清楚地列出的或对于这些产品或设备固有的其它单元。本实施例提供了一种基于eemd-iaga-bp神经网络的船舶交通流预测方法,如图1-4所示,包括如下步骤:s101:选取船舶交通流数据作为一个时间序列,基于eviews软件,对其进行单位根检验法的np检验法进行检验,通过检验时间序列中是否存在平方根来判断是否平稳,如果存在单位根则时间序列不平稳,不存在单位根则时间序列平稳。eviews是econometricsviews的缩写,eviews软件通常称为计量经济学软件包,是专门为大型机构开发的、用以处理时间序列数据的软件包。单位根检验是指检验序列中是否存在单位根,存在单位根即为非平稳时间序列,单位根指单位根过程。np检验法是ng和perron于2001年针对pp检验和ers检验等的不足之处,构造了4个基于gls除趋势数据的检验单位根的统计量以改善检验的效率和势,该方法称为np检验,相应的统计量称为np检验统计量。本实施例以2009年1月到2015年12月南京长江大桥大桥断面的船舶交通流为例,其船舶交通流数据变化曲线如图2所示,本实施例采用根据前三个月的船舶交通流量预测第四个月的流量,如用2009年1-3月的交通流量数据预测2009年4月。2009年至2015年用于进行预测的原始数据如表1所示。np检验法对其进行平稳性检验的结果如表2所示。表12009年1月到2015年12月南京长江大桥大桥断面的船舶交通流数据表2np检验法对船舶交通流时间序列进行平稳性检验的结果t-statisticprob.*augmenteddikey-fullerteststastic-1.3756790.5896testcriticalvalues:1%level-3.5242335%level-2.90235810level-2.588587s102:利用集合经验模态分解算法将船舶交通流数据这个非平稳时间序列分解为一系列平稳信号,包括一下子步骤:(1)在待分解信号x(t)中加入白噪声n(t)得到加噪声后的总体信号x(t)为:x(t)=x(t)+n(t);(2)对总体信号x(t)进行emd分解,得到一组imf分量cj(t)(j=1,2...m)和一个残余分量rm(t):(3)给待分解信号x(t)加入不同白噪声信号ni(t)(i=1,2...n),重复(1)(2)步骤n次,n为可人工设定的常数,得到不同的总体信号xi(t),以及imf分量cij(t)和残余分量(即rm分量)rim(t);其计算公式为:平均imf余量对时间序列的曲线图如图3所示,残余rm分量随时间序列的变化曲线图如图4所示。(4)为消除多次添加白噪声对实际imf的干扰,对各imf分量进行整体平均计算,获得时序信号的eemd分解结果,即平均imf分量cj(t),计算公式为:s103:构建3层bp神经网络模型,其构建方法包括子步骤:(1)设置模型参数,例如:bp神经网络部分学习速率为0.1,训练次数1000次,训练目标为0.001;(2)网络拓扑结构:输入层的神经元数量为3,输出层的神经元数量为1,隐藏层的神经元数量为4;(3)初始化权值阈值:在matlab中随机产生初始权值和阈值;(4)采用数据归一化方法对数据进行预处理,把所述船舶交通流数据转化为[0,1]之间的数,计算公式如下:其中,x为所述船舶交通流数据,xmin为船舶交通流数据中的最小值,xmax为船舶交通流数据中的最大值,为归一化后的数据。s104:改进自适应遗传算法,遗传算法部分进化代数设为20,设置种群规模设为10,其包括子步骤:(1)选择操作:采用轮盘赌的方法,个体的适应度值记为fi,先计算个体的相对适应度值根据pj(j=1,2,...,n)把圆盘分为n份,转动圆盘,若落入第j个扇形内,则选择个体j。实际上的实现过程是采用一个随机数,看它落入哪个区间,方法是先生成一个[0,1]之间的随机数r,若p1+p2+…+pj-1<r<p1+p2+…+pj,则选择个体j;(2)交叉操作:从种群中选择2个个体按照一定的交叉概率得到新个体,本文采用交叉概率及实数交叉法如式(1)(2)所示:式中pc为交叉概率,pc1、pc2分别为交叉概率的上下限,且pc1=0.9、pc2=0.6,;fbigger为参与交叉运算的两个个体中适应度值较大的值,fav为种群的平均适应度值,fmax为种群中最大的适应度值。式中am为第m个染色体,an为第n个染色体,i代表它们在第i位交叉,b为[0,1]之间的随机数;(3)变异操作:从种群中随机选择一个个体按照一定的变异概率得到新个体,变异概率及方法如式(3)(4)所示:式中pm为变异概率,pm1、pm2分别为变异概率的上下限,且pm1=0.1、pm2=0.01,pm3=0.07;f为当前进行突变的个体的适应度值,其他符号取值如式(1)。式中基因amn为得到的新个体,其上界是amax,下界是amin,g为当前迭代次数,gmax为最大进化次数,r为[0,1]之间的一个随机数,r2为一个随机数。s105:准确度检测:采用递推方式把船舶交通流数据分为训练集和预测集两部分,训练集部分用于训练上述模型,预测集部分用于测试模型准确性,分组情况如表3所示。在matlab2017a环境下进行仿真,数据总量为84个月份,采用递推方式把数据数据分为81组,递推方式是用前三个月的交通流量数据预测第四个月,如用2009年1-3月的交通流量数据预测2009年4月,即输入为[12617,9408,13578],输出为[12210]。通过预测值与实际船舶交通流数据的对比,可做出预测结果与实际数据的对比曲线,如图5所示。同时,通过现有技术中的其他方法如bp神经网络、ga-bp神经网络、iaga-bp神经网络的实现的预测结果与本申请获得的预测结果的对比如图5所示,由此可知,本申请的预测准确度较高。表3船舶交通流的分组情况以上对本发明的具体实施例进行了详细描述,但其只作为范例,本发明并不限制于以上描述的具体实施例。对于本领域技术人员而言,任何对该实用进行的等同修改和替代也都在本发明的范畴之中。因此,在不脱离本发明的精神和范围下所作的均等变换和修改,都应涵盖在本发明的范围内。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1