一种基于多任务深度Q网络的Q值迁移的多交叉口信号灯协同控制方法与流程
本发明属于人工智能与智能交通的交叉领域,涉及一种基于多任务深度Q 网络的Q值迁移多交叉口信号灯协同控制方法。
背景技术:
城市交通贯穿于城市公共空间的各个区域,是居民日常出行最主要、最便捷的方式,经过长期发展,城市交通已经形成较为完善的格局,提高了居民的出行效率,给居民生活带来很大便利。但随着经济的发展和城市化进程的加快,城市人口及人均汽车保有量快速增长,交通拥堵问题日趋严重,交通不畅、运输效率低下、环境污染等问题日益严峻,严重影响和谐可持续发展。为缓解交通拥堵问题,可以采取拓宽道路、修建高架桥等扩张道路基础设施的方法,但由于公共空间有限、造价昂贵、污染环境等原因,这类方法的作用有限。
现实生活中,各城市的信号灯控制多为定时控制,即根据交叉口的历史交通流数据预先计算出红绿灯配时方案,此后一直按照此方案进行信号灯相位切换,这种控制方法不能根据实时的交通流自适应地调节信号灯相位,易造成交通拥堵。因此,可以通过信号灯的自适应控制来提高已有道路的利用率,减少拥堵。信号灯的自适应控制策略将交通系统视为一个不确定的系统,根据测量到的交通流量、延误时间和队列长度等状态变量的反馈,实现信号灯的动态优化和调整,以应对交通流的随机特性。通过信号灯的自适应控制来优化区域道路网络的交通,减少拥堵,提高通行效率,并减少二氧化碳的排放。因此,对交叉口信号灯的自适应控制研究具有重要的现实意义。
20世纪80年代以后,随着机器学习和人工智能技术的发展,科研学者将其中的新方法新理论应用在信号灯的智能控制中,例如模糊逻辑、神经网络、进化算法和动态规划。模糊逻辑信号控制器通常依据专家知识建立一组规则,根据这些规则,基于交叉口的状态输入来选择适当的交通信号灯相位,具有较强的实时性且设计简单实用,然而,规则的制定过分依赖于专家知识,此外,随着交叉口数目增多,相位数目也随之增加时,很难生成一套有效的规则。对非线性系统和难以建模的系统,神经网络具有良好的逼近能力和学习能力,但神经网络模型大多采用监督学习的方式来训练,需要大量成功的学习样本,样本的质量将影响模型的训练效果。进化算法收敛到最优解需要较大的计算量,不适用于交叉口信号灯控制等在线问题。动态规划也被广泛应用于信号灯的自适应控制,但随着问题规模的扩大,动态规划需要有效的机制来解决计算量过大和难以计算操作环境转移概率的问题。
强化学习通过感知环境状态和接收环境中的不确定性信息来学习最优策略,通过与环境连续交互,寻找最优策略以使累积折扣奖赏最大化。强化学习最主要的优势是不需要先验知识,能够解决现实应用中信息不完全和环境随机变化的问题,信号灯控制正面临这两个复杂的问题,因此,很多学者采用强化学习对信号灯进行自适应控制。
对于多交叉口的信号灯控制,有研究采用集中控制的方式,通过训练一个强化学习Agent来对整个道路网络的信号灯进行控制,在每个时刻,Agent获取整个道路网络的交通状态并对整个路网的信号灯进行决策。但在集中控制模式下,随着交叉口数目的线性增加,状态空间和动作空间大小将会指数增长,导致状态空间和动作空间的维度灾难。对于此问题,研究者提出基于分布式控制的多Agent强化学习系统,将多交叉口信号灯控制问题视为多Agent问题,其中每个Agent采用RL算法控制一个单交叉口的信号灯,Agent通过单个路口的局部环境进行决策的方式易于扩展到多交叉口。
多Agent强化学习的优势在于每个Agent只观察单个交叉口的局部环境,并且只需从单交叉口的动作空间中选择一个动作执行,不会造成维度灾难,因此这种控制方式可以扩展到更多的交叉口。然而,传统的强化学习通过人工提取的交叉口特征来表示状态空间,同时为避免状态空间过大,通常都简化状态表示,往往忽略了一些重要信息。强化学习的Agent是基于对周围环境的状态观察做出决策的,如果丢失重要的信息,不能保证Agent能够做出对真实环境最优的决策。例如,采用车辆的平均延迟表示状态,只反映了历史交通数据不能满足实时的交通需求;简化道路网络为单车道的方式,虽避免了状态空间过大,但不符合现实复杂的交通场景。这些解决状态空间过大的方法都没有充分利用交叉口的有效状态信息,导致Agent所做的决策是基于部分信息的。
2015年,Mnih提出将深度学习与强化学习联合的深度Q网络(Deep Q Network,DQN)学习算法后(MnihV,KavukcuogluK,SilverD,et al.Human-level control through deep reinforcement learning[J].Nature,2015,518(7540):529-533.),科研学者开始将深度Q网络技术应用于单交叉口和多交叉口的信号灯控制中。深度强化学习主要是通过卷积神经网络(Convolutional Neural Network,CNN)、堆叠自编码器(Stacked Auto-Encoder,SAE)等深度学习模型对交叉口原始的交通状态信息进行自动特征提取,以避免繁琐的手工特征提取,并能够充分地利用交叉口的原始状态信息,以便Agent能够基于这些信息做出最优的信号灯相位选择。Li等人提出一种深度强化学习的方法来控制单交叉口的信号灯,其中采用每条道路上的车辆排队长度作为交叉口的状态输入神经网络,然后利用 SAE来估计各个动作对应的Q值(Li L,Yisheng L,Wang F Y.Traffic signal timing via deep reinforcement learning[J].ACTA AUTOMATICA SINICA,2016, 3(3):247-254.)。Genders等人提出基于卷积神经网络的深度强化学习算法来对单交叉口的信号灯进行控制,其中采用车辆的位置矩阵、速度矩阵和最近时刻的信号灯相位来表示交叉口的交通状态,用带有经验池回放的Q-learning算法训练Agent。该方法由于动作的估计Q值与目标Q值之间存在潜在的相关性,算法的稳定性较差(Genders W,Razavi S.Using a Deep Reinforcement Learning Agent for Traffic Signal Control[J].//arXiv preprint arXiv:1611.01142,2016.)。Gao 等人采用目标网络冻结技术改进了Genders方法中的不稳定问题(Gao J, ShenY,Liu J,et al.Adaptive Traffic Signal Control:DeepReinforcement Learning Algorithm with Experience Replay and TargetNetwork.//arXiv preprint arXiv:1705.02755,2017.)。Jeon等人认为以往大多数强化学习控制信号灯的研究中提出的交通参数不能充分表示实际交通状态的复杂性,文中直接采用交叉口的实时视频图像来表示交通状态(Jeon H J,Lee J and SohnK.Artificial intelligence for traffic signal controlbased solely on video images.Journal of Intelligent TransportationSystems,2018,22(5):433-445)。最近,Van der Pol等人首次将多Agent深度强化学习应用于无左转的多交叉口信号灯自适应控制 (Vander Pol E and Oliehoek F A,Coordinated deep reinforcement learnersfor traffic light control.//In NIPS’16Workshop on Learning,Inferenceand Control of Multi-Agent Systems,2016)。首先将多Agent问题划分为多个较小的子问题(文中每两个相邻交叉口定义一个Agent,称之为一个子问题,又称为“源问题”),利用深度Q网络算法在源问题上对网络进行训练,训练完成后得到联合Q函数,然后将此联合Q函数迁移至其它相似的子问题上,最后采用max-plus算法计算多交叉口信号灯控制的全局最优联合动作。然而,Max-plus在以协同图表示的协作多Agent系统中寻找最优解,但不能保证收敛到最优解。并且,在不同的子问题之间迁移Q函数,要求各子问题的状态维度和相位个数是相等的,这需要对交叉口的结构进行限制或近似。
针对多交叉口交通状态特征提取困难、多交叉口没有充分挖掘多个Agent 之间的相似性且信号灯控制缺乏有效的协同策略等问题,本发明提出了一种基于多任务深度Q网络的Q值迁移协同控制方法(Multi-Task Deep Q-Network with Q-valueTransfer,QT-MTDQN)。首先在多交叉口上训练一个适合每个交叉口信号灯控制的多任务网络,然后把它在多交叉口上学到的知识用在目标问题上(不同交通流密度的交叉口),多任务网络将比单个网络拥有更多的知识,对单个交叉口提取特征的能力更强,最后通过协同算法对目标域中各个交叉口的信号灯进行协同控制。多任务网络将比单个专家网络拥有更多的知识,对单个交叉口提取特征的能力更强,最后通过协同算法对目标域中各个交叉口的信号灯进行协同控制,这在一定程度上能够平衡各路口的交通流量,提高区域交通中道路的利用率,减少车辆的排队长度,缓解交通拥堵。该方法对交通网络具有较好的可扩展性。
技术实现要素:
针对传统的信号灯控制方法存在交通状态特征提取困难、多交叉口没有充分挖掘多个Agent之间的相似性且多交叉口信号灯之间缺乏有效的协同策略等问题,本发明提出了一种基于多任务深度Q网络的Q值迁移协同控制方法 (QT-MTDQN)用于多交叉口信号灯协同控制。该方法对交通状态的原始信息进行自动特征提取,并充分挖掘各交叉口之间进行决策的相似性、考虑相邻交叉口的影响,对多交叉口信号灯进行协同控制,提升了多交叉口的交通效率,缓解了各交叉口的拥堵。
本发明的技术方案:
一种基于多任务深度Q网络的Q值迁移的多交叉口信号灯协同控制方法,步骤如下:
步骤一、获取每个交叉口的状态;
步骤二、定义动作空间和奖赏函数;
步骤三、训练专家网络
将有N个交叉口的路网建模为多Agent系统Agent1,Agent2,…,Agenti,...,AgentN,将每个Agent上的信号灯控制视为一个源任务Si*,每个Agent都由一个DQN估计网络组成,针对每个Agent独立地训练估计网络,Agenti训练完成的估计网络即为专家网络Ei,即Ei是第i交叉口的专家网络;每个Agent新增一个与估计网络结构相同参数不同的目标网络,估计网络估计当前状态下各个动作的Q值目标网络估计目标值其中通过在一段时间内冻结目标网络的参数,使DQN算法更稳定;各Agent的损失函数定义为:
其中,m为批大小,是状态下所有动作中最优的目标Q值,θi′是第i个Agent的目标网络参数,为相应的估计网络的输出,γ表示学习率,a′表示动作空间中可选的某个动作,θi表示第i个Agent的估计网络的参数;
在训练每个估计网络时,在每个时间步t,第i个Agent将对交叉口的状态观察输入估计网络,根据网络输出的值使用ε-贪心策略选择动作并执行, Agent得到来自环境的奖赏并进入下一个状态在每个时间步t将对第i个路口的经验存入经验池Mi中,每个Agent对应一个经验池;每个经验池最多能存储max_size条经验,存满后将最早的数据舍弃继续存入最新的经验;经验池的样本需达到min_size条才能开始训练网络,训练时从经验池Mi中随机均匀采样m条经验,采用随机梯度下降算法RMSProp对参数θi进行更新;
采用的神经网络均为CNN,CNN网络包含4个隐层,第一个卷积层由16 个4×4的滤波器组成,步长为2;第二个卷积层由32个2×2的滤波器组成,步长为1;第三层和第四层是两个全连接层,分别由128和64个神经元组成;四个隐层都采用Relu非线性激活函数,然后将网络的输出值再作为最后的输出层的输入,输出层采用softmax激活函数,其中输出层的神经元个数与对应路口的动作空间大小相等;
步骤四、训练多任务网络
建立一个多任务的DQN网络MTDQN,其网络结构与专家网络相同;在时间步t,将Agenti控制的交叉口的状态分别输入专家网络Ei和多任务网络中,网络输出的Q值经过公式(3)归一化处理后,采用专家网络策略与多任务网络策略之间的交叉熵对多任务网络的参数进行更新,如式(4)所示;
其中,是Q值经过归一化操作得到的一个归一化值,τ是温度参数,s是交叉口的状态,a是动作空间中的一个动作,是第i个Agent的专家网络 Ei在状态s下执行动作a的输出Q值,是专家网络Ei的动作空间,a′是其中的某一个动作;
其中,是交叉熵损失函数,πMTDQN(a|s;θ)是多任务深度Q网络MTDQN 的策略,θ是MTDQN的参数,损失函数中用到的动作a,是依据多任务网络输出的策略进行采样的,即在训练多任务网络的过程中,每次各交叉口的信号灯动作都是根据多任务网络输出的策略进行选择的,而不是根据专家网络,每次更新多任务网络参数时,各专家网络交替地“指导”多任务网络;
步骤五、训练多任务协同网络
多任务深度Q网络MTDQN训练完成后,对于多交叉口信号灯的协同控制,先将训练好的多任务深度Q网络MTDQN迁移到各个Agent上,即将已训练的多任务深度Q网络MTDQN的参数作为各Agent估计网络的参数初始值,再采用基于Q值迁移的协同方法来协同控制多交叉口的信号灯,该算法称为基于多任务深度Q网络的Q值迁移协同控制算法QT-MTDQN;
在QT-MTDQN算法中,考虑到相邻交叉口间的交通会相互影响,将相邻 Agent最近时刻的最优Q值迁移到每个Agent的损失函数中,各Agent的损失函数定义为:
其中,公式中的角标MT表示各Agent的网络是多任务网络,是在状态下所有动作中最优的目标Q值,θ′MT,i是第i个Agent的目标网络参数,为相应的估计网络的输出;为从相邻Agent经验回放中取出的最近时刻的Q值,ω(i,j)是第j个Agent对第i个Agent影响的权重大小;
在训练QT-MTDQN模型时,在更新第i个Agent的估计网络时会将其邻居最近时刻的最优Q值迁移到当前Agent的损失函数中,相应的,从经验池Mi中随机采样后,需要从其邻居的经验池中采样对应的最近时刻的经验。
进一步地,步骤一的具体过程为:对进入交叉口的所有道路上的车辆进行离散状态编码,对于某个交叉口i,将从停车线开始长度为l的道路k划分为长度c的离散单元,将交叉口i的道路k的车辆位置和速度记录为车辆位置矩阵和车辆速度矩阵当车辆头部在某个离散单元上时,则车辆位置矩阵对应的位置值为1,否则值为0;将车辆速度与道路限制的最大速度归一化后的值作为速度矩阵对应单元格的值;对于每条进入交叉口i的车道,相应的都有一个位置矩阵和一个速度矩阵对于第i个交叉口,所有车道的和组成交叉口i的位置矩阵Pi和速度矩阵Vi;在t时刻,Agent观察到第i个交叉口的状态为其中Si表示第i个路口的状态空间。
进一步地,步骤二的具体过程为:定义第i个交叉口的动作空间Ai,即第i 个交叉口的所有可切换信号灯相位;在t时刻,Agent得到第i个交叉口的状态后,选择一个动作其中Ai表示第i个交叉口的动作空间,每次选择的动作,其相位时间是一段固定长度的时间间隔τg,当前相位时间结束后,当前时刻t随之结束,并且开始下一个时刻t+1,Agent开始观察第i个交叉口的下一个状态状态会受最近一次所执行动作的影响,对于新状态选择下一个动作并执行;
在Agent观察到第i个交叉口的状态后,选择一个动作并执行,Agent 将从环境中获得一个标量奖赏值以评价所执行动作的好坏;选择路口车辆平均排队长度的变化作为奖赏函数,和分别为t时刻和t+1时刻进入第i个交叉口所有车道上车辆的平均排队长度,奖赏如式(1)所示,奖赏值为正,表示 t时刻采取的动作对环境有一个积极的影响,使车辆平均排队长度减少,为负表示动作导致环境中车辆平均排队长度增加;
本发明的有益效果:基于多任务深度Q网络的Q值迁移的多交叉口信号灯协同控制方法充分挖掘了多个Agent之间的相似性,使得多任务网络能够充分有效地提取交叉口的特征,并能够协同地控制多交叉口的信号灯,该方法能扩展到更多的交叉口而不会造成维度灾难。
附图说明
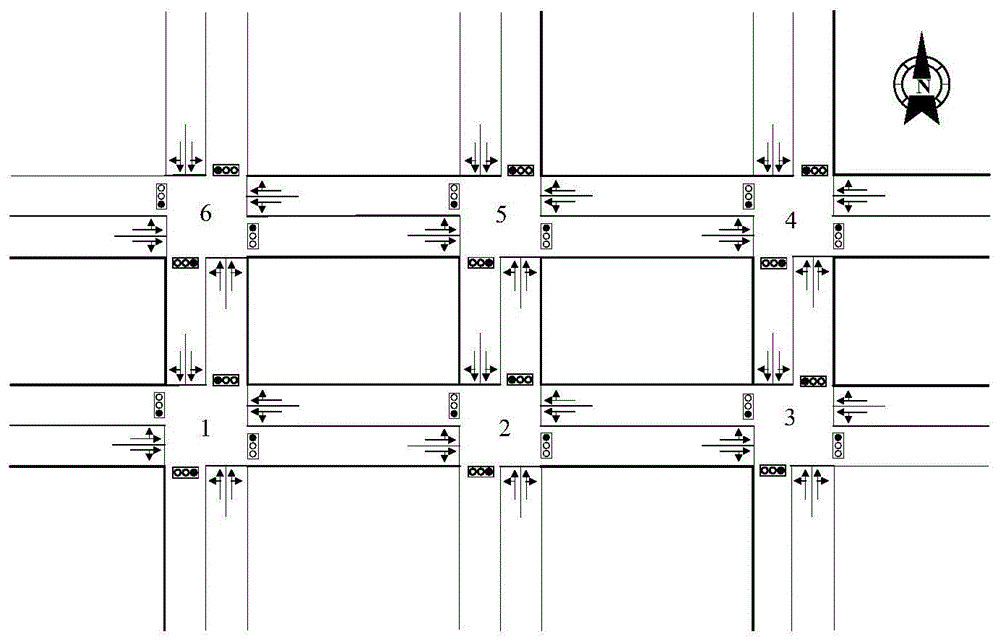
图1六交叉口示意图;
图2交通信息的离散状态编码;
图3六交叉口的动作空间;
图4训练专家网络示意图;
图5训练多任务网络及多任务协同网络示意图;
图6QT-MTDQN方法在六路口上的平均排队长度(其中,QT-MTDQN是基于多任务深度Q网络的Q值迁移协同控制,QT-CDQN为带有Q值迁移深度强化学习的协同控制方法,CDRL是基于Max-plus的协同控制方法,MADQN为无协同的DQN方法,Distributed QL为无协同的Q学习控制方法);
图7QT-MTDQN方法在六路口上的平均速度;
图8QT-MTDQN方法在六路口上的平均等待时间;
图9QT-MTDQN方法在每个交叉口的平均排队长度;
图10QT-MTDQN方法在每个交叉口的平均速度;
图11QT-MTDQN方法在每个交叉口的平均等待时间。
具体实施方式
本发明提供一种基于多任务深度Q网络的Q值迁移的多交叉口信号灯协同控制方法。所论述的具体实施例仅用于说明本发明的实现方式,而不限制本发明的范围。下面结合附图对本发明的实施方式进行详细说明,具体包括以下步骤:
1.获取交叉口的状态。以图1中的六交叉口为例说明,每条道路均有两条车道,根据交叉口的结构,左侧车道允许车辆直行或左转,右侧车道允许车辆直行或右转。对各个交叉口的交通信息进行离散状态编码,将从停车线开始长度为l的道路k划分为长度c的离散单元,其中c的取值要适中,c值过大则容易忽略个体车辆状态,过小会造成计算量太大。如图2所示,将路口i的道路k 的车辆位置和速度记录在两个矩阵:车辆位置矩阵和车辆速度矩阵如果车辆头部在某个单元格上,则矩阵对应的位置值为1,否则值为0;将车辆速度与道路限制的最大速度归一化后的值作为速度矩阵对应单元格的值。对于第i个交叉口,所有道路的车辆位置矩阵Pi和车辆速度矩阵Vi分别表示为和在t时刻,Agent观察到第i个路口的状态为其中Si表示第i个路口的状态空间。
2.定义动作空间和奖赏函数。
定义第i个交叉口的动作空间Ai,即第i个交叉口的所有可切换信号灯相位。在t时刻,Agent得到第i个交叉口的状态后,选择一个动作其中Ai表示第i个交叉口的动作空间,图3所示是每个交叉口的动作空间。每次选择的动作,其相位时间是一段固定长度的时间间隔τg(6s),当前相位时间结束后,当前时刻t随之结束,并且开始下一个时刻t+1,Agent开始观察第i个交叉口的下一个状态状态会受最近一次所执行动作的影响,对于新状态选择下一个动作并执行(此时可能选择与上一时刻相同的动作)。
奖赏函数是在与环境交互的过程中获取的奖励信号,奖赏函数反应了Agent 所面临的任务的性质,同时作为Agent修改策略的基础。在Agent观察到第i个交叉口的状态后,选择一个动作并执行,Agent将从环境中获得一个标量奖赏值以评价所执行动作的好坏。Agent追求的目标就是寻找一种状态-动作策略,使最终得到的累积奖赏值达到最大。本发明选择路口车辆平均排队长度的变化作为奖赏函数,和分别为t时刻和t+1时刻进入第i个交叉口所有车道上车辆的平均排队长度,奖赏如式(1)所示,奖赏值为正,表示t时刻采取的动作对环境有一个积极的影响,使车辆平均排队长度减少,为负表示动作导致环境中车辆平均排队长度增加。
3.训练专家网络。将有N个交叉口的路网建模为多Agent系统 Agent1,Agent2,…AgentN,将每个Agent上的信号灯控制视为一个源任务每个 Agent都由一个DQN估计网络组成,针对每个Agent独立地训练估计网络,Agenti训练完成的估计网络即为专家网络Ei,即Ei是第i交叉口的专家网络(Expert Net)。为缓解决策过程中微小的Q值变化可能导致的估计网络策略震荡问题,每个Agent新增一个与估计网络结构相同参数不同的目标网络,估计网络估计当前状态下各个动作的Q值目标网络估计目标值其中通过在一段时间内冻结目标网络的参数,使DQN算法更稳定。各Agent的损失函数定义为:
其中,m为批大小,是状态下所有动作中最优的目标Q值,θ′i是第i个Agent的目标网络参数,为相应的估计网络的输出。
在训练每个估计网络时,在每个时间步t,第i个Agent将对交叉口的状态观察输入估计网络,根据网络输出的值使用ε-贪心策略选择动作并执行,此时Agent得到来自环境的奖赏并进入下一个状态在每个时间步t将对第i个路口的经验存入经验池Mi中(每个Agent对应一个经验池)。每个经验池最多能存储max_size(2×105)条经验,存满后将最早的数据舍弃继续存入最新的经验。经验池的样本需达到min_size(5×103)条才能开始训练网络,为了更有效地训练估计网络CNNi的参数θi,训练时从经验池Mi中随机均匀采样m(32)条经验,采用随机梯度下降算法RMSProp对参数θi进行更新。训练过程的示意图如图4所示。
上述过程用采用的神经网络均为CNN,CNN网络包含4个隐层,第一个卷积层由16个4×4的滤波器组成,步长为2;第二个卷积层由32个2×2的滤波器组成,步长为1;第三层和第四层是两个全连接层,分别由128和64个神经元组成。四个隐层都采用Relu非线性激活函数,然后将网络的输出值再作为最后的输出层的输入,输出层采用softmax激活函数,其中输出层的神经元个数与对应路口的动作空间大小相等。
4.训练多任务网络。建立一个多任务的DQN网络(MTDQN),其网络结构与专家网络相同。在时间步t,将Agenti控制的交叉口的状态分别输入专家网络Ei和多任务网络中,网络输出的Q值经过式(3)归一化处理后,采用专家网络策略与多任务网络策略之间的交叉熵对多任务网络的参数进行更新,如式(4) 所示。
其中,τ是温度参数,是专家网络Ei的动作空间。
其中,πMTDQN(a|s;θ)是多任务深度Q网络(MTDQN)的策略,θ是MTDQN的参数,损失函数中用到的动作a,是依据多任务网络输出的策略进行采样的,即在训练多任务网络的过程中,每次各交叉口的信号灯动作都是根据多任务网络输出的策略进行选择的,而不是根据专家网络。每次更新多任务网络参数时,各专家网络交替地“指导”多任务网络。图5给出了该过程的训练示意图,图中已训练完成的估计网络即为专家网络,多任务网络即为多任务DQN网络。
5.训练多任务协同网络。多任务深度Q网络(MTDQN)训练完成后,在单个交叉口上,与专家网络相比,MTDQN拥有更强的状态特征提取能力和决策能力,但是多个交叉口之间无协同。因此,对于多交叉口信号灯的协同控制,需要先将训练好的多任务深度Q网络迁移到各个Agent上,即将已训练的多任务深度Q网络的参数作为各Agent估计网络的参数初始值,再采用基于Q值迁移的协同方法来协同控制多交叉口的信号灯,该算法称为基于多任务深度Q网络的Q值迁移协同控制算法(QT-MTDQN),在此过程中也用到了经验回放机制和目标网络冻结策略,QT-MTDQN算法的结构图如图5所示。
在QT-MTDQN算法中,考虑到相邻交叉口间的交通会相互影响,将相邻 Agent最近时刻的最优Q值迁移到每个Agent的损失函数中,各Agent的损失函数定义为:
其中,公式中的角标MT表示各Agent的网络是多任务网络,是在状态下所有动作中最优的目标Q值,θ′MT,i是第i个Agent的目标网络参数,为相应的估计网络的输出。为从相邻Agent经验回放中取出的最近时刻的Q值。
在训练QT-MTDQN模型时,与第三步中采样不同的是,在更新第i个Agent 的估计网络时会将其邻居最近时刻的最优Q值迁移到当前Agent的损失函数中,因此,从经验池Mi中随机采样后,需要从其邻居的经验池中采样对应的最近时刻的经验。
- 还没有人留言评论。精彩留言会获得点赞!