错误检测和分类匹配方法及系统与流程
本发明的实施例涉及半导体领域,并且更具体地涉及错误检测和分类匹配方法及系统。
背景技术:
在半导体制造中,利用各种处理工具来执行包括蚀刻、沉积、注入和退火的各种工艺。例如,设计溅射工具以执行溅射沉积。此外,通常单独设计具有相同类型的各种处理工具以执行对应的工艺,注入溅射沉积。通常,处理工具配置为使得处理工具之间的处理偏差在特定容限范围内。
在传统上,通过用户常识来识别不同工具之间的错误检测和分类(FDC)匹配。例如,用户依据经验和常识而不是依据标准规范来确定FDC图表上的异常情况。
技术实现要素:
本发明的实施例提供了一种错误检测和分类匹配方法,包括:从多个腔室接收原始数据;基于接收的所述腔室的原始数据,检测所述腔室的操作中是否存在错误,其中,所述检测包括以下中的至少一个:基于所述接收的所述腔室的原始数据,生成与所述腔室对应的多个第一西格玛值;在与所述第一西格玛值对应的西格玛比率小于阈值的情况下,通过对所述腔室执行平均匹配工艺,生成与所述腔室对应的多个第一平均离群值指数;以及识别所述腔室中的具有所述第一平均离群值指数的最差的第一平均离群值指数的一个腔室以作为具有错误操作的目标腔室。
本发明的实施例还提供了一种错误检测和分类匹配方法,包括:基于从第一腔室和第二腔室接收的原始数据,检测所述第一腔室和所述第二腔室的操作中是否存在错误,其中,所述检测包括以下中的至少一个:将所述第一腔室配置为多个虚拟腔室,其中,所述虚拟腔室中的每一个都包括所述第一腔室的原始数据的一部分;基于所述第一腔室和所述第二腔室的原始数据,生成与所述第一腔室和所述第二腔室分别对应的第一西格玛值和第二西格玛值;在与所述第一西格玛值和所述第二西格玛值对应的西格玛比率小于阈值的情况下,通过对所述第一腔室、所述第二腔室和所述虚拟腔室执行平均匹配工艺,生成与所述第一腔室、所述第二腔室和所述虚拟腔室分别对应的多个第一平均离群值指数;以及当在所述第一腔室、所述第二腔室和所述虚拟腔室中,所述虚拟腔室和所述第一腔室中的一个具有所述第一平均离群值指数的最差的第一平均离群值指数时,识别所述第一腔室为具有错误操作的目标腔室。
本发明的实施例还提供了一种错误检测和分类匹配系统,包括:多个腔室;以及主器件,配置为:从所述腔室接收原始数据;和基于接收的原始数据,通过以下中的至少一个确定目标错误腔室:生成与所述多个腔室对应的多个第一西格玛值;基于与所述多个第一西格玛值对应的西格玛比率,生成与所述多个腔室对应的多个第一平均离群值指数;以及基于所述多个第一平均离群值指数,识别具有错误操作的目标腔室以作为所述目标错误腔室。
附图说明
当结合附图进行阅读时,根据下面详细的描述可以最佳地理解本发明的实施例。应该注意,根据工业中的标准实践,各种部件没有被按比例绘制。实际上,为了清楚的讨论,各种部件的尺寸可以被任意增加或减少。
图1是根据本发明的各个实施例的错误检测和分类系统的示意图;
图2A和图2B中的每一个都是根据本发明的各个实施例的与图1中的系统相关联的错误检测和分类方法的流程图;以及
图3是根据本发明的各个实施例的示出了西格玛(sigma)值和平均值的箱线图(box-and-whisker plot),其对应于五个腔室(chamber)的原始数据并且与图2A和图2B中的方法相关。
具体实施方式
以下公开内容提供了许多不同实施例或实例,用于实现所提供主题的不同特征。以下将描述组件和布置的具体实例以简化本发明。当然,这些仅是实例并且不意欲限制本发明。例如,在以下描述中,在第二部件上方或上形成第一部件可以包括第一部件和第二部件直接接触的实施例,也可以包括形成在第一部件和第二部件之间的附加部件使得第一部件和第二部件不直接接触的实施例。而且,本发明在各个实例中可以重复参考数字和/或字母。这种重复仅是为了简明和清楚,其自身并不表示所论述的各个实施例和/或配置之间的关系。
本说明书中使用的术语通常具有其在本领域中以及在使用每一个术语的具体的内容中的普通含义。本说明书中使用的实例,包括本文所讨论的任何术语的实例,仅是示例性的,并且绝不是限制本发明的或任何示例性术语的范围和意义。同样,本发明不限于本说明书中给出的各个实施例。
尽管本文可以使用术语“第一”、“第二”等以描述各个元件,但是这些元件不应被这些术语限制。这些术语用于将一个元件与另一个元件区别开。例如,在不背离本发明的范围的情况下,可以将第一元件叫做第二元件,并且类似地,可以将第二元件叫做第一元件。如本文所使用的,术语“和/或”包括一个或多个所列的相关联项目的任何以及所有的组合。
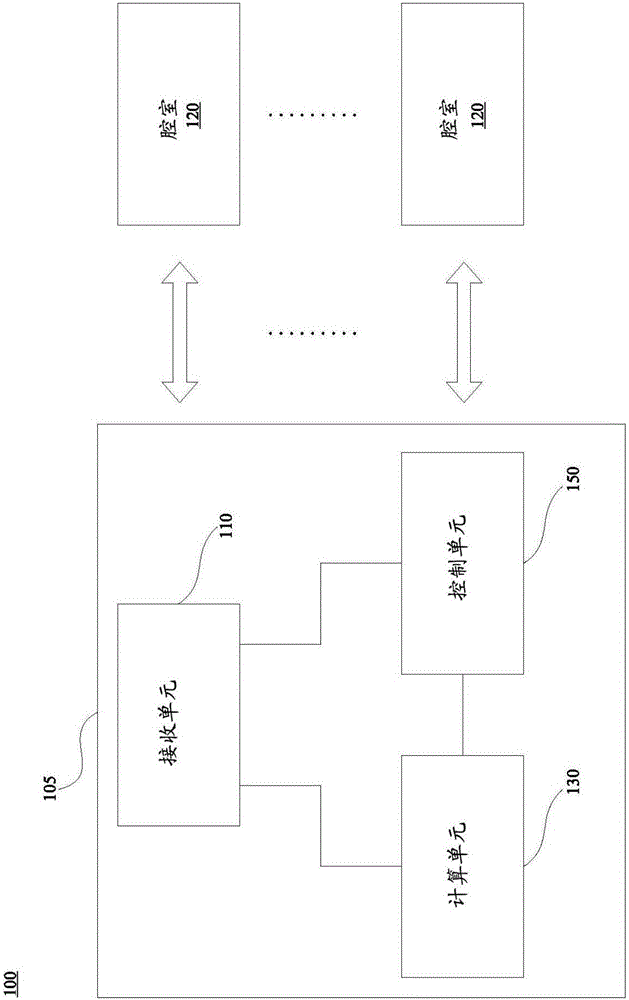
图1是根据本发明的各个实施例的错误检测和分类(FDC)系统100的示意图。在错误检测和分类系统100中,主器件105配置为分析来自腔室120的原始数据。原始数据包括参数,例如,参数包括温度、空气压力、空气类型(air type)等。此外,主器件105配置为根据分析结果在腔室120中识别目标腔室。在一些实施例中,目标腔室是具有错误操作的腔室。为了说明,目标腔室具有FDC误匹配参数,例如,FDC误匹配参数包括不正确的压力、温度、工艺时间等,这将在下文中进行解释。
在一些实施例中,在半导体制造环境中实施错误检测和分类系统100,以处理相对大量的实时数据和延时数据。在半导体制造环境中,错误检测和分类系统100是半导体制造FDC系统,并且主器件105分析来自半导体制造腔室的原始数据。
如图1示例性地示出,主器件105配置为从腔室120接收原始数据(如,温度、空气压力等),并且基于接收的腔室120的原始数据来检测腔室120的操作中是否存在错误。在一些实施例中,例如,通过包括中央处理单元、控制单元、微处理器或等同物的计算机来实施主器件105。在一些其他的实施例中,错误检测和分类系统100支持自动错误检测和分类。在又一实施例中,主器件105配置为自动实施纠正以修正目标腔室中检测到的错误。
在一些实施例中,主器件105包括接收单元110、计算单元130和控制单元150。接收单元110配置为接收腔室120中的每一个的原始数据(如,温度、空气压力等)。
计算单元130配置为执行数学算法。在一些实施例中,计算单元130配置为计算腔室120中的每一个的原始数据的标准差,以生成与腔室120对应的多个西格玛值。在一些其他的实施例中,计算单元130配置为计算腔室120中的每一个的原始数据的平均值。
控制单元150配置为通过分析腔室120的原始数据之间的差异和关联性来在腔室120中识别目标腔室。在一些实施例中,控制单元150配置为通过确定腔室120的数量、检查与腔室120的西格玛值对应的西格玛比率、对腔室120的原始数据执行西格玛匹配工艺和平均匹配(mean matching)工艺来识别目标腔室。下文参考图2A和图2B描述详细的操作。在一些实施例中,主器件105执行图2A和图2B中示出的操作。
参考图1、图2A和图2B。图2A和图2B中的每一个都是根据本发明的各个实施例的与图1中的系统100相关联的错误检测和分类方法的流程图。
在一些实施例中,接收单元110、计算单元130和控制单元150采用存储在非易失性计算机可读存储介质上的计算机程序产品的形式,其中非易失性计算机可读存储介质具有嵌入在介质中的计算机可读指令。在一些其他的实施例中,错误检测和分类方法200采用存储在非易失性计算机可读存储介质上的计算机程序产品的形式,其中非易失性计算机可读存储介质具有嵌入在介质中的计算机可读指令。可以使用任何合适的非易失性存储介质,并且包括:非易失性存储器,诸如只读存储器(ROM)、可编程只读存储器(PROM)、可擦除可编程只读存储器(EPROM)、以及电可擦除可编程只读存储器(EEPROM)器件;易失性存储器,诸如静态随机存取存储器(SRAM)、动态随机存取存储器(DRAM)以及双数据速率随机存取存储器(DDR-RAM);光学存储器件,诸如光盘只读存储器(CD-ROM)和数字多功能光盘只读存储器(DVD-ROM);以及磁性存储器件,诸如硬盘驱动器(HDD)和软盘驱动器。
在一些实施例中,图1中的主器件105执行图2A和图2B中示出的操作。为了说明,主器件105执行包括操作S201的操作,以从腔室120接收原始数据。然后,主器件105执行包括操作S203至S237的操作,以基于接收的腔室120的原始数据来检测腔室120的操作中是否存在错误。下文参考图1、图2A和图2B描述详细的操作。
如图1和图2A示例性地示出,在操作S201中,由接收单元110接收腔室120的原始数据。在操作S203中,通过控制单元150来确定腔室120的数量。在腔室120的数量比预定数量大的情况下,执行操作S205至S219。另一方面,在腔室120的数量等于或小于预定数量的情况下,执行图2B中示出的操作S221至S237。在腔室120的数量等于或小于预定数量的情况下,腔室120中的一个能够被有效地选择并且配置为用于进一步操作的虚拟(virtual)腔室,例如,进一步的操作包括操作S221至S237。在一些实施例中,预定数量配置为二。然而,为了说明的目的给出以上讨论的预定数量。各个预定数量都在本发明的预期范围内。
如以上在操作S203中描述的,如果腔室120的数量比预定数量大,则执行操作S205至S219。参考图3描述操作S205至S219。图3是根据本发明的各个实施例的示出了西格玛(sigma)值和平均值的箱线图(box-and-whisker plot),其对应于五个腔室CH1至CH5的原始数据并且与图2A和图2B中的方法相关。在图3中,为了说明,西格玛值σ1至σ5分别表示与腔室CH1至CH5的原始数据对应的标准差。为了简明,图3中示出了五个腔室CH1至CH5,但是不在这方面对本发明进行限制。或者说,与图3中示出的西格玛值和平均值有关的各个数量的腔室(大于预定数量)都在本发明的预期范围内。
参考图1、图2A和图3,在操作S205中,基于腔室CH1至CH5的原始数据,由计算单元130生成与腔室CH1至CH5分别对应的西格玛值σ1至σ5。在一些实施例中,计算单元130计算腔室CH1至CH5中的每一个的原始数据的标准差,以生成与腔室CH1至CH5分别对应的西格玛值σ1至σ5。为了说明,西格玛值σ1表示腔室CH1的原始数据的分布,西格玛值σ2表示腔室CH2的原始数据的分布,以此类推。
在操作S207中,由控制单元150做出确定,以确定与西格玛值σ1至σ5对应的西格玛比率是否小于阈值。在一些实施例中,西格玛比率是西格玛值σ1至σ5中的最大西格玛值的平方与西格玛值σ1至σ5中的最小西格玛值的平方的比率。在图3中,为了说明,腔室CH3的西格玛值σ3大于西格玛值σ1至σ2和σ4至σ5,并且腔室CH4的西格玛值σ4小于西格玛值σ1至σ3和σ5。因此,控制单元150生成西格玛值σ3的平方与西格玛值σ4的平方的比率以作为西格玛比率。
在一些实施例中,将西格玛值的平方限定为合并方差(pooled variance)。或者说,在一些实施例中,西格玛比率还被定义为腔室的合并方差中的最大合并方差与最小合并方差的比率。
在一些实施例中,西格玛比率小于阈值的情况表示原始数据的波动小。在这种情况下,腔室中的每一个的原始数据中几乎不存在噪声。因此,在西格玛比率小于阈值的情况下,跳过对于识别腔室的原始数据的波动所使用的西格玛匹配工艺。
在西格玛比率小于阈值的情况下,执行操作S209。在操作S209中,通过对腔室CH1至CH5执行平均匹配工艺,由控制单元150生成与腔室CH1至CH5分别对应的多个平均离群值指数(mean outlier indexes)OImean11至OImean15。在一些实施例中,“离群值指数(outlier indexes)”指示测量结果,其中数据点偏离于数据流的剩余部分的表现。
在一些实施例中,平均匹配工艺包括以下概述的操作。由计算单元130计算腔室CH1至CH5中的每一个的原始数据的平均值。接下来,由控制单元150比较腔室的每一个平均值与其他平均值,以生成与腔室CH1至CH5分别对应的平均离群值指数OImean11至OImean15。
在图3中,为了说明,计算与腔室CH1至CH5的原始数据对应的平均值M1至M5。参考图1和图3,控制单元150比较腔室CH1的平均值M1与腔室CH2至CH5的平均值M2至M5,以生成腔室CH1的平均离群值指数OImean11。控制单元150比较腔室CH2的平均值M2与腔室CH1和CH3至CH5的平均值M1和M3至M5,以生成腔室CH2的平均离群值指数OImean12。以与以上所讨论的类似的方式生成其他平均离群值指数,并且本文不再具体描述。
在一些实施例中,平均离群值指数(如,OImean11)是一个平均值(如,M1)和其他平均值(如,M2至M5)之间的差值的绝对值的和。为了说明,平均离群值指数OImean11是平均值M1和M2之间的差值的绝对值、平均值M1和M3之间的差值的绝对值、平均值M1和M4之间的差值的绝对值以及平均值M1和M5之间的差值的绝对值的和。
在一些实施例中,使用平均匹配工艺以用于识别腔室的原始数据的偏移。或者说,腔室的平均离群值指数表示腔室的原始数据与其他腔室的原始数据相比较的偏移。因此,控制单元150根据腔室的平均离群值指数来确定腔室是否为目标腔室。
在操作S211中,根据平均离群值指数OImean11至OImean15,由控制单元150识别具有错误操作的目标腔室,其中,目标腔室为腔室CH1至CH5中的具有最差平均离群值指数的腔室。在一些实施例中,控制单元150在平均离群值指数OImean11至OImean15中识别最大的平均离群值指数以作为最差平均离群值指数。因此,控制单元150识别具有最大平均离群值指数的腔室以作为目标腔室。
在一些实施例中,主器件105在主器件105的显示器上显示与目标腔室相关的错误检测通知。在一些其他的实施例中,主器件105基于错误检测结果来控制目标腔室。在各个实施例中,主器件105基于错误检测结果向目标腔室发送更新的配置数据,以更正目标腔室的操作。
在一些其他的实施例中,控制单元150在平均离群值指数OImean11至OImean15中识别比预定标准大的平均离群值指数以作为最差平均离群值指数。或者说,控制单元150识别具有比预定标准大的平均离群值指数的腔室以作为目标腔室。为了说明的目的给出识别目标腔室的前述方法。识别目标腔室的各种方法都在本发明的预期范围内。
另一方面,在西格玛比率大于或等于阈值的情况下,执行操作S213。在操作S213中,由控制单元150对腔室CH1至CH5中的每一个的原始数据执行噪声滤除工艺。在一些实施例中,西格玛比率表示腔室之间的波动。因此,西格玛比率大于或等于阈值的情况表示腔室之间的波动大。
在一些实施例中,噪声滤除工艺包括以下概述的操作。由控制单元150确定腔室CH1至CH5中的每一个中的至少一种噪声,其中,噪声指示具有比边界值大的值的原始数据。接下来,从腔室CH1至CH5中的每一个的原始数据中滤除噪声(如果存在的话)。
为了说明,在所有原始数据中,一些原始数据具有比边界值大的值,并且大部分原始数据具有比边界值小的值。控制单元150确定具有比边界值大的值的原始数据为噪声。然后,控制单元150从腔室的原始数据滤除具有比边界值大的值的原始数据。
在执行噪声滤除工艺之后,执行操作S215。在操作S215中,通过对腔室CH1至CH5执行西格玛匹配工艺,由控制单元150生成与腔室CH1至CH5分别对应的多个西格玛离群值指数(sigma outlier indexes)OIsigma11-OIsigma15。
在一些实施例中,西格玛匹配工艺包括以下概述的操作。由计算单元130生成已经执行了噪声滤除工艺的腔室CH1至CH5中的每一个的原始数据的西格玛值。为了说明,计算单元130计算原始数据的标准差,以生成与腔室CH1至CH5分别对应的西格玛值σ1'至σ5',其中,对于腔室CH1至CH5中的每一个已经滤除了噪声(如果存在的话)。接下来,由控制单元150比较西格玛值σ1'至σ5'中的每一个与其他西格玛值,以生成与腔室CH1至CH5分别对应的西格玛离群值指数OIsigma11-OIsigma15。
类似地,为了说明,控制单元150比较腔室CH1的西格玛值σ1'与腔室CH2至CH5的西格玛值σ2'至σ5',以生成西格玛离群值指数OIsigma11,比较腔室CH2的西格玛值σ2'与腔室CH1和CH3至CH5的西格玛值σ1'和σ3'至σ5'以生成西格玛离群值指数OIsigma12,以此类推。
在一些实施例中,西格玛离群值指数(如,OIsigma11)是一个西格玛值(如,σ1')和其他西格玛值(如,σ2'至σ5')之间的差值的绝对值的和。为了说明,西格玛离群值指数OIsigma11是西格玛值σ1'和σ2'之间的差值的绝对值、西格玛值σ1'和σ3'之间的差值的绝对值、西格玛值σ1'和σ4'之间的差值的绝对值以及西格玛值σ1'和σ5'之间的差值的绝对值的和。
在一些实施例中,使用西格玛匹配工艺以用于识别腔室的原始数据的波动。或者说,腔室的西格玛离群值指数表示腔室的原始数据与其他腔室的原始数据相比较的波动。因此,控制单元150根据腔室的西格玛离群值指数来确定腔室是否为目标腔室。
在操作S217中,通过对腔室CH1至CH5执行平均匹配工艺,由控制单元150生成与腔室CH1至CH5分别对应的多个平均离群值指数OImean21至OImean25。类似地,在一些实施例中,平均匹配工艺包括以下概述的操作。由计算单元130生成已经执行了噪声滤除工艺的腔室CH1至CH5中的每一个的原始数据的平均值。为了说明,计算单元130计算原始数据的平均值,以生成与腔室CH1至CH5分别对应的平均值M1'至M5',其中,对于腔室CH1至CH5中的每一个已经滤除了噪声(如果存在的话)。接下来,由控制单元150比较平均值M1'至M5'中的每一个与其他平均值,以生成与腔室CH1至CH5分别对应的平均离群值指数OImean21至OImean25。操作S217与操作S209类似,并且因此本文不再具体描述。
在操作S219中,根据集成离群值指数(integrated outlier index)OIin1至OIin5,由控制单元150识别目标腔室,其中,目标腔室为腔室CH1至CH5中的具有最差集成离群值指数的腔室。在一些实施例中,集成离群值指数(如,OIin1)为平均离群值指数(如,OImean21)与西格玛离群值指数(如,OIsigma21)的和。在一些实施例中,控制单元150识别最大的集成离群值指数(即,平均离群值指数和西格玛离群值指数的最大的和)以作为最差集成离群值指数。或者说,控制单元150识别具有最大集成离群值指数的腔室以作为目标腔室。在一些实施例中,控制单元150识别比预定标准大的集成离群值指数以作为最差集成离群值指数。或者说,控制单元150识别具有比预定标准大的集成离群值指数的腔室以作为目标腔室。
在一些实施例中,在西格玛比率大于或等于阈值的情况下,考虑西格玛匹配和平均匹配两者。或者说,使用腔室的原始数据的偏移和波动以用于识别目标腔室。此外,在对于腔室的原始数据执行西格玛匹配工艺和平均匹配工艺之前,确定腔室的原始数据中的噪声,并且如果存在噪声,则滤除噪声。因此,增加了确定目标腔室的精确度并且减小误差。
在操作S203中,在腔室的数量等于或小于预定数量(如,在一些实施例中为2)的情况下,执行图2B中示出的操作S221至S237。为了说明操作S221至S237,描述腔室CH6和CH7以及虚拟腔室CH8和CH9以具体解释。
在操作S221中,通过控制单元150将腔室CH6和CH7中的一个配置为虚拟腔室CH8和CH9。为了说明,腔室CH6配置为虚拟腔室CH8和CH9,其中,虚拟腔室CH8和CH9中的每一个都包括腔室CH6的原始数据的一部分。
在一些实施例中,配置腔室的操作基于对于晶圆数量的采样大小。例如,如果腔室具有70晶圆数量并且采样大小为30,则腔室配置为三个虚拟腔室,其中,两个虚拟腔室都具有30晶圆数量,并且另一个虚拟腔室具有10晶圆数量。在一些实施例中,将腔室配置为虚拟腔室的操作基于采样周期。例如,接收腔室的原始数据的总周期为一小时,并且采样周期为40分钟。在这种实例中,通过控制单元150将腔室配置为两个虚拟腔室,其中,一个虚拟腔室包括腔室的原始数据的前40分钟内的原始数据,而另一个包括后20分钟内的原始数据。
在操作S223中,基于腔室CH6至CH7和虚拟腔室CH8至CH9的每一个的原始数据,由计算单元130生成与腔室CH6至CH7和虚拟腔室CH8至CH9分别对应的西格玛值σ6至σ9。在一些实施例中,计算单元130计算腔室CH6至CH7和虚拟腔室CH8至CH9中的每一个的原始数据的标准差,以生成与腔室CH6至CH7和虚拟腔室CH8至CH9分别对应的西格玛值σ6至σ9。
在操作S225中,由控制单元150做出确定,以确定与西格玛值σ6至σ7对应的西格玛比率是否小于阈值。在一些实施例中,西格玛比率为腔室CH6和CH7的西格玛值σ6至σ7中的最大西格玛值的平方与最小西格玛值的平方的比率。
在西格玛比率小于阈值的情况下,执行操作S227。在操作S227中,通过对腔室CH6至CH7和虚拟腔室CH8至CH9执行平均匹配工艺,由控制单元150生成与腔室CH6至CH7和虚拟腔室CH8至CH9分别对应的平均离群值指数OImean16至OImean19。操作S227与操作S209类似,并且因此本文不再具体描述。
在操作S229中,根据平均离群值指数OImean16至OImean19,由控制单元150识别目标腔室,其中,目标腔室为腔室CH6至CH7和虚拟腔室CH8至CH9中的具有最差平均离群值指数的腔室。具体地,当在腔室CH6至CH7和虚拟腔室CH8至CH9中,虚拟腔室CH8至CH9和腔室CH6中的一个具有最差平均离群值指数时,控制单元150识别腔室CH6为目标腔室,或者当在腔室CH6至CH7和虚拟腔室CH8至CH9中,腔室CH7具有最差平均离群值指数时,识别腔室CH7为目标腔室。
在一些实施例中,控制单元150在平均离群值指数OImean16至OImean19中识别最大的平均离群值指数以作为最差平均离群值指数。或者说,控制单元150识别具有最大平均离群值指数的腔室以作为目标腔室。在一些其他的实施例中,控制单元150在平均离群值指数中识别比预定标准大的平均离群值指数以作为最差平均离群值指数。或者说,控制单元150识别具有比预定标准大的平均离群值指数的腔室以作为目标腔室。
另一方面,在西格玛比率大于或等于阈值的情况下,执行操作S231。在操作S231中,由控制单元150对腔室CH6至CH7和虚拟腔室CH8至CH9中的每一个的原始数据执行噪声滤除工艺。在一些实施例中,西格玛比率表示腔室的原始数据的波动。因此,西格玛比率大于或等于阈值的情况表示腔室之间的波动大。操作S231的进一步的细节与操作S213类似,并且因此本文不再具体描述。
在执行噪声滤除工艺之后,执行操作S233。在操作S233中,通过对腔室CH6至CH7和虚拟腔室CH8至CH9执行西格玛匹配工艺,由控制单元150生成与腔室CH6至CH7和虚拟腔室CH8至CH9分别对应的西格玛离群值指数OIsigma16至OIsigma19。操作S233的进一步的细节与操作S215类似,并且因此本文不再具体描述。
在一些实施例中,使用西格玛匹配工艺以用于识别腔室的原始数据的波动。或者说,腔室的西格玛离群值指数表示腔室的原始数据与其他腔室的原始数据相比较的波动。因此,控制单元150根据腔室的西格玛离群值指数来确定腔室是否为目标腔室。
在操作S235中,通过对腔室CH6至CH7和虚拟腔室CH8至CH9执行平均匹配工艺,由控制单元150生成与腔室CH6至CH7和虚拟腔室CH8至CH9分别对应的平均离群值指数OImean26至OImean29。操作S235的进一步的细节与操作S217类似,并且因此本文不再具体描述。
在操作S237中,根据集成离群值指数OIin6至OIin9,由控制单元150识别目标腔室,其中,目标腔室为腔室CH6至CH7和虚拟腔室CH8至CH9中的具有最差集成离群值指数的腔室。在一些实施例中,集成离群值指数(如,OIin6)为平均离群值指数(如,OImean26)与西格玛离群值指数(如,OIsigma16)的和。操作S237的进一步的细节与操作S219和S229类似,并且因此本文不再具体描述。
如以上所讨论的,在腔室的数量等于或小于预定数量的情况下,将腔室中的一个的原始数据虚拟地配置为虚拟腔室。因此,对于腔室和虚拟腔室的原始数据,仍能执行西格玛匹配工艺和平均匹配工艺。结果,利用错误检测和分类方法200仍具有良好的分析结果和精确的确定。
在一些方法中,通过用户常识和经验来实现错误检测和分类(FDC)匹配,以找到在异常情况下操作和/或具有FDC误匹配参数的目标腔室。这种方法缺少指数以证明具有处理工具的腔室存在的参数差异的意义。
与前述方法相比较,以上讨论的错误检测和分类系统100和/或方法200能够通过使用指数和标准来检测错误操作是否存在于腔室的操作中。错误检测和分类系统100和/或方法200还能够基于指数和标准来识别具有错误操作的目标腔室。
在一些实施例中,使用腔室的原始数据的偏移和波动以用于识别并且确定目标腔室。此外,在对腔室的原始数据执行西格玛匹配工艺和平均匹配工艺之前,确定并且滤除腔室的原始数据中的噪声。因此,增加了确定目标腔室的精确度并且减小误差。此外,本发明中提供的错误检测和分类系统100和错误检测和分类方法200不在腔室的数量上进行限制。
以上所示包括示例性操作,但是没有必要以所示出的顺序执行该操作。根据本发明的各个实施例的精神和范围,可以视情况添加、替换、重排和/或消除操作。
在一些实施例中,公开了包括以下概述的操作的方法。从多个腔室接收原始数据。基于接收的腔室的原始数据,检测腔室的操作中是否存在错误。检测包括以下概述的至少一个操作。基于腔室的原始数据,生成与腔室分别对应的多个西格玛值。做出确定以确定与西格玛值对应的西格玛比率是否小于阈值。在西格玛比率小于阈值的情况下,通过对腔室执行平均匹配工艺,生成与腔室分别对应的多个平均离群值指数。识别腔室中的具有第一平均离群值指数的最差的第一离群值指数的一个以作为具有错误操作的目标腔室。
还公开了一种方法,方法包括以下列出的操作。从第一腔室和第二腔室接收原始数据。基于接收的腔室的原始数据,检测第一腔室和第二腔室的操作中是否存在错误。检测包括以下概述的至少一个操作。第一腔室配置为多个虚拟腔室,其中,每一个虚拟腔室都包括第一腔室的原始数据的一部分。基于第一腔室和第二腔室的原始数据,生成与第一腔室和第二腔室分别对应的第一西格玛值和第二西格玛值。做出确定以确定与第一西格玛值和第二西格玛值对应的西格玛比率是否小于阈值。在西格玛比率小于阈值的情况下,通过对第一腔室、第二腔室和虚拟腔室执行平均匹配工艺,生成与第一腔室、第二腔室和虚拟腔室分别对应的多个平均离群值指数。当在第一腔室、第二腔室和虚拟腔室中,虚拟腔室和第一腔室中的一个具有第一平均离群值指数的最差平均离群值指数时,第一腔室被识别为具有错误操作的目标腔室,并且当在第一腔室、第二腔室和虚拟腔室中,第二腔室具有第一平均离群值指数的最差平均离群值指数时,第二腔室被识别为目标腔室。
还公开了包括多个腔室和主器件的系统。主器件配置为从腔室接收原始数据,并且基于接收的原始数据,通过以下中的至少一个来确定目标错误腔室:生成与多个腔室对应的多个第一西格玛值;基于与多个第一西格玛值对应的西格玛比率,生成与多个腔室对应的多个第一平均离群值指数;以及基于多个第一平均离群值指数,识别具有错误操作的目标腔室以作为目标错误腔室。
本发明的实施例提供了一种错误检测和分类匹配方法,包括:从多个腔室接收原始数据;基于接收的所述腔室的原始数据,检测所述腔室的操作中是否存在错误,其中,所述检测包括以下中的至少一个:基于所述接收的所述腔室的原始数据,生成与所述腔室对应的多个第一西格玛值;在与所述第一西格玛值对应的西格玛比率小于阈值的情况下,通过对所述腔室执行平均匹配工艺,生成与所述腔室对应的多个第一平均离群值指数;以及识别所述腔室中的具有所述第一平均离群值指数的最差的第一平均离群值指数的一个腔室以作为具有错误操作的目标腔室。
根据本发明的一个实施例,其中,生成所述第一西格玛值包括:计算所述腔室的原始数据的标准差。
根据本发明的一个实施例,其中,所述西格玛比率为所述西格玛值中的最大西格玛值的平方与最小西格玛值的平方的比率。
根据本发明的一个实施例,其中,所述平均匹配工艺包括:计算所述腔室中的每一个的原始数据的平均值;以及比较所述腔室的每一个平均值与其他的平均值,以生成与所述腔室对应的所述第一平均离群值指数。
根据本发明的一个实施例,其中,所述检测还包括以下中的至少一个:在所述西格玛比率大于或等于所述阈值的情况下,对所述腔室的原始数据执行噪声滤除工艺;执行所述噪声滤除工艺之后,通过对所述腔室执行西格玛匹配工艺,生成与所述腔室对应的多个西格玛离群值指数;执行所述噪声滤除工艺之后,通过对所述腔室执行所述平均匹配工艺,生成与所述腔室对应的多个第二平均离群值指数;以及识别所述腔室中的具有所述西格玛离群值指数和所述第二平均离群值指数的最差的和的一个腔室以作为所述目标腔室。
根据本发明的一个实施例,其中,所述噪声滤除工艺包括:确定所述腔室中的每一个的比边界值大的原始数据为噪声;以及从所述腔室中的每一个的原始数据中滤除所述噪声。
根据本发明的一个实施例,其中,所述西格玛匹配工艺包括:计算所述腔室的原始数据的标准差,以生成与所述腔室对应的多个第二西格玛值;以及比较所述第二西格玛值中的每一个与所述第二西格玛值中的其他西格玛值,以生成与所述腔室对应的所述西格玛离群值指数。
根据本发明的一个实施例,其中,所述平均匹配工艺包括:计算所述腔室中的每一个的原始数据的平均值;以及比较所述腔室的每一个平均值与其他的平均值,以生成与所述腔室对应的所述第二离群值指数。
本发明的实施例还提供了一种错误检测和分类匹配方法,包括:基于从第一腔室和第二腔室接收的原始数据,检测所述第一腔室和所述第二腔室的操作中是否存在错误,其中,所述检测包括以下中的至少一个:将所述第一腔室配置为多个虚拟腔室,其中,所述虚拟腔室中的每一个都包括所述第一腔室的原始数据的一部分;基于所述第一腔室和所述第二腔室的原始数据,生成与所述第一腔室和所述第二腔室分别对应的第一西格玛值和第二西格玛值;在与所述第一西格玛值和所述第二西格玛值对应的西格玛比率小于阈值的情况下,通过对所述第一腔室、所述第二腔室和所述虚拟腔室执行平均匹配工艺,生成与所述第一腔室、所述第二腔室和所述虚拟腔室分别对应的多个第一平均离群值指数;以及当在所述第一腔室、所述第二腔室和所述虚拟腔室中,所述虚拟腔室和所述第一腔室中的一个具有所述第一平均离群值指数的最差的第一平均离群值指数时,识别所述第一腔室为具有错误操作的目标腔室。
根据本发明的一个实施例,其中,生成所述第一西格玛值和所述第二西格玛值包括:计算所述第一腔室和所述第二腔室的原始数据的标准差,以生成所述第一西格玛值和所述第二西格玛值。
根据本发明的一个实施例,其中,所述西格玛比率为所述第一西格玛值和所述第二西格玛值中的最大西格玛值的平方与最小西格玛值的平方的比率。
根据本发明的一个实施例,其中,所述平均匹配工艺包括:计算所述第一腔室、所述第二腔室和所述虚拟腔室中的每一个的原始数据的平均值;以及比较所述第一腔室、所述第二腔室和所述虚拟腔室的每一个平均值与其他的平均值,以生成与所述第一腔室、所述第二腔室和所述虚拟腔室分别对应的所述第一平均离群值指数。
根据本发明的一个实施例,其中,所述检测还包括以下中的至少一个:在所述西格玛比率大于或等于所述阈值的情况下,对所述第一腔室、所述第二腔室和所述虚拟腔室中的每一个的原始数据执行噪声滤除工艺;执行所述噪声滤除工艺之后,通过对所述第一腔室、所述第二腔室和所述虚拟腔室执行西格玛匹配工艺,生成与所述第一腔室、所述第二腔室和所述虚拟腔室分别对应的多个西格玛离群值指数;执行所述噪声滤除工艺之后,通过对所述第一腔室、所述第二腔室和所述虚拟腔室执行所述平均匹配工艺,生成与所述第一腔室、所述第二腔室和所述虚拟腔室分别对应的多个第二平均离群值指数;以及当在所述第一腔室、所述第二腔室和所述虚拟腔室中,所述虚拟腔室和所述第一腔室中的一个具有所述西格玛离群值指数和所述第二平均离群值指数的最差的和时,识别所述第一腔室为所述目标腔室,并且当在所述第一腔室、所述第二腔室和所述虚拟腔室中,所述第二腔室具有所述西格玛离群值指数和所述第二平均离群值指数的最差的和时,识别所述第二腔室为所述目标腔室。
根据本发明的一个实施例,其中,所述噪声滤除工艺包括:确定所述第一腔室、所述第二腔室和所述虚拟腔室中的每一个的比边界值大的原始数据为噪声;以及从所述第一腔室、所述第二腔室和所述虚拟腔室中的每一个的原始数据中滤除所述噪声。
根据本发明的一个实施例,其中,所述西格玛匹配工艺包括:计算所述第一腔室、所述第二腔室和所述虚拟腔室的中的每一个的原始数据的标准差,以生成与所述第一腔室、所述第二腔室和所述虚拟腔室分别对应的多个第三西格玛值;以及比较所述第三西格玛值中的每一个与其他的第三西格玛值,以生成与所述第一腔室、所述第二腔室和所述虚拟腔室分别对应的所述西格玛离群值指数。
根据本发明的一个实施例,其中,所述平均匹配工艺包括:计算所述第一腔室、所述第二腔室和所述虚拟腔室中的每一个的原始数据的平均值;以及比较所述第一腔室、所述第二腔室和所述虚拟腔室的每一个平均值与其他的平均值,以生成与所述第一腔室、所述第二腔室和所述虚拟腔室分别对应的所述第二平均离群值指数。
本发明的实施例提供了一种错误检测和分类匹配系统,包括:多个腔室;以及主器件,配置为:从所述腔室接收原始数据;和基于接收的原始数据,通过以下中的至少一个确定目标错误腔室:生成与所述多个腔室对应的多个第一西格玛值;基于与所述多个第一西格玛值对应的西格玛比率,生成与所述多个腔室对应的多个第一平均离群值指数;以及基于所述多个第一平均离群值指数,识别具有错误操作的目标腔室以作为所述目标错误腔室。
根据本发明的一个实施例,其中,所述西格玛比率为所述第一西格玛值中的最大的第一西格玛值的平方与最小的第一西格玛值的平方的比率。
根据本发明的一个实施例,其中,在所述西格玛比率大于或等于所述阈值的情况下,所述主器件配置为对所述腔室的原始数据执行噪声滤除工艺。
根据本发明的一个实施例,其中,所述主器件配置为还通过以下中的至少一个来确定目标错误腔室:执行所述噪声滤除工艺之后,生成与所述多个腔室对应的多个西格玛离群值指数;基于与所述原始数据对应的第二平均值,生成与所述多个腔室对应的多个第二平均离群值指数;以及基于所述多个西格玛离群值指数和所述多个第二平均离群值指数,识别具有错误操作的目标腔室以作为所述目标错误腔室。
以上论述了若干实施例的部件,使得本领域的技术人员可以更好地理解本发明的各个方面。本领域技术人员应该理解,可以很容易地使用本发明作为基础来设计或更改其他的处理和结构以用于达到与本发明所介绍实施例相同的目的和/或实现相同优点。本领域技术人员也应该意识到,这些等效结构并不背离本发明的精神和范围,并且在不背离本发明的精神和范围的情况下,可以进行多种变化、替换以及改变。
- 还没有人留言评论。精彩留言会获得点赞!