一种用于通信的基于图形处理器的BCH码并行译码方法与流程
本发明涉及一种用于通信的基于图形处理器的bch码并行译码方法,属于数字信号处理技术领域。
背景技术:
bch码是一类纠多个错误的线性分组码,经常作为外码与ldpc码和turbo码级联,用来消除内码的误码平台。这种级联编码可以提供优良的纠错性能,所以被广泛的应用于各种无线通信标准中。例如中国的数字电视地面传输标准和欧洲的dvb-s2、dvb-s2x、dvb-t2等。
经典bch码串行译码算法由文献(h.o.burton,"inversionlessdecodingofbinarybchcodes,"(inenglish),ieeetransactionsoninformationtheory,vol.17,no.4,pp.464-+,1971.)给出。
图形处理器(gpu)是近年得到快速发展的具备大规模并行处理能力的单指令流多线程流(simt)架构通用运算处理器。目前市场主流图形处理器nvidiagtx1080ti包含3584个运算核心,单精度浮点运算能力高达10tflop。与现有采用单指令流多数据流(simd)架构的cpu、arm、dsp相比具有更高的运算能力。
computeunifieddevicearchitecture(cuda)是用于gpu计算的开发环境,它是一个全新的软硬件架构,可以将gpu视为一个并行数据计算的设备,对所进行的计算进行分配和管理。在cuda的架构中,这些计算不再像过去所谓的gpgpu架构那样必须将计算映射到图形api(opengl和direct3d)中,因此对于开发者来说,cuda的开发门槛大大降低了。与fpga和asic硬件相比配置更加灵活、开发难度更小,更适用于通信系统。
经对现有技术的文献检索发现,专利申请号201810478181.7的中国专利,专利名称为“一种bch译码器”公开了一种基于电路实现的bch译码,用于存储器信息校验。该译码器采用电路实现要考虑时序排列和资源分配等问题,复杂度较高,不利于开发人员编程实现;通用性和可重构性不高。
技术实现要素:
本发明的目的是一种用于通信的基于图形处理器的bch码并行译码方法,在图形处理器上实现了通用的bch码并行译码方法,利用查表等算法提高译码效率;在一个码字内进行并行译码,充分发挥图形处理器多核的运算能力,提高了译码吞吐率,减少了译码时延。
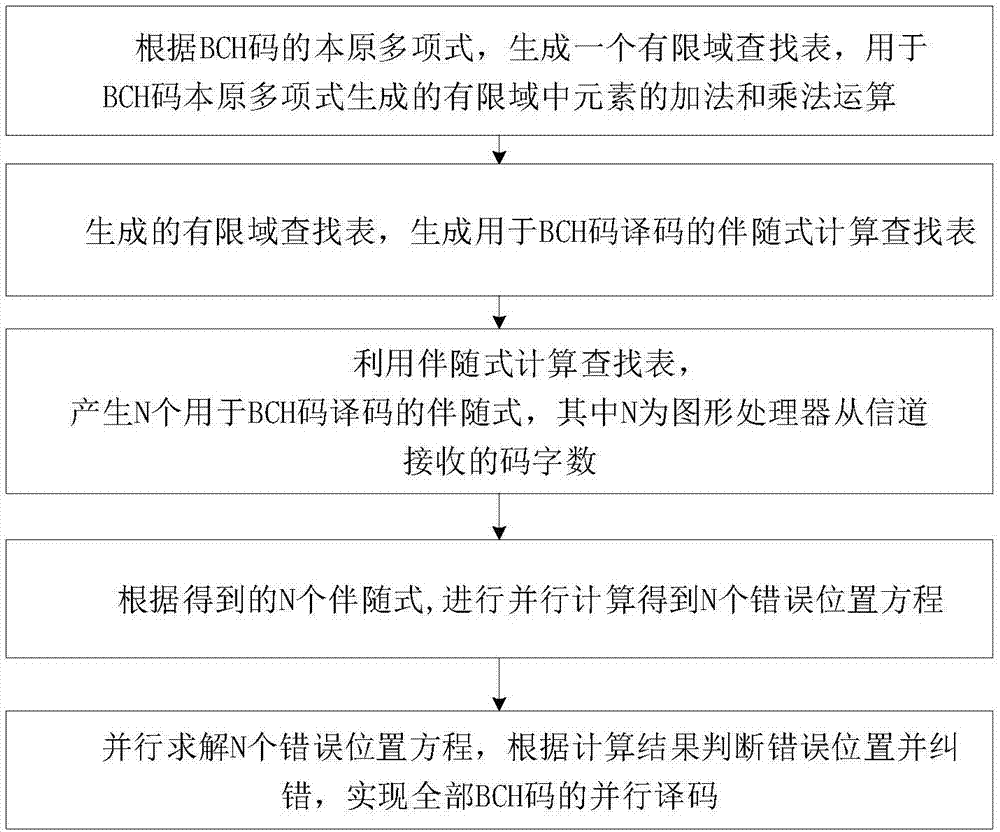
本发明提出的用于通信的基于图形处理器的bch码并行译码方法,包括以下步骤:
(1)根据bch码的本原多项式,生成一个有限域查找表log(β)和exp(e),生成过程如下:
(1-1)从bch码本原多项式产生的有限域gf(2q)中获取一个非零元素β,β=αe,其中,e为非零元素β的序号,0≤e≤2q-2,α为bch码本原多项式的一个根,q为本原多项式的次数;
(1-2)在图形处理器的全局内存中,以非零元素β为地址存储非零元素序号e,以非零元素序号e为地址存储非零元素β;
(1-3)遍历bch码本原多项式产生的有限域gf(2q)中的所有非零元素,重复步骤(1-1)和步骤(1-2),得到非零元素β与非零元素序号e之间的映射表,记为有限域查找表log(β)和exp(e);
(2)利用步骤(1)生成的有限域查找表log(β)和exp(e),生成用于bch码译码的伴随式计算查找表
(2-1)初始化伴随式序号j=0;
(2-2)初始化计算参数
(2-3)计算计算参数
(2-4)利用步骤(1)得到的有限域查找表log(β)和exp(e),计算得到
(2-5)在图形处理器的全局内存中,以
(2-6)对
(2-7)对j进行判断,若j<2t-1,则使j=j+1,返回步骤(2-2),若j=2t-1,,得到伴随式计算查找表
(3)利用以下方法,产生n个用于bch码译码的伴随式sg(x),
(3-1)根据图形处理器从信道中接收的码字数n、bch码的最大纠错个数t和码字长度n,将图形处理器中的运算资源分配为
(3-2)对步骤(3-1)图形处理器中的每个线程块分配32个子线程,字线程的序号为v,32m≤v≤32m-1,共得到
(3-3)在步骤(3-1)的线程块内进行如下并行计算,得到第一临时变量bg(v,j):
其中,v为子线程的序号,
(3-4)利用归约算法,在每个线程块内对步骤(3-3)的临时变量bg(v,j)进行bch码本原多项式产生的有限域gf(2q)中的求和计算,得到第二临时变量
具体并行计算步骤为:
其中
(3-5)利用原子按位异或操作,在每个线程块间对步骤(3-4)的第二临时变量cg(m,j)进行有限域gf(2q)中的求和运算,得到
(4)根据步骤(3)的n个伴随式,利用以下方法,并行计算得到n个错误位置方程,其中bch码本原多项式产生的有限域gf(2q)中的加法和乘法由步骤(1)中得到的有限域查找表log(β)和exp(e)获得,包括以下步骤:
(4-1)初始化时,使k=0,
(4-2)设定一个第四临时变量
(4-3)根据用于bch码译码的公式
(4-4)根据用于bch码译码的公式
计算得到第一临时多项式
(4-5)根据用于bch码译码公式的
(4-6)对迭代次数进行判断,若k<t-1,则使k=k+1,返回执行步骤(4-2),若k≥t-1,则得到n个错误位置方程
(5)并行求解步骤(4)中n个错误位置方程σg(x),具体方法为:
(5-1)根据码字数量n,重新将图形处理器中的运算资源分配为n个线程块,根据码字长度n,为每个线程块分配n个子线程,将线程块序号记为g,0≤g≤n-1,将子线程序号记为i,一个子线程对应码字的一个比特,0≤i≤n-1;
(5-2)在每个线程块内,将αi代入步骤(4)中得到的错误位置方程,得到σg(αi),其中α为bch码本原多项式的一个根,其中bch码本原多项式产生的有限域gf(2q)中的加法和乘法由步骤(1)中得到的有限域查找表log(β)和exp(e)获得;
(5-3)对上述计算结果σg(αi)进行判断,若计算结果为非零元素,则判定从信道中接收的第g个码字的第i个比特无错误,若计算结果为零元素,则判定第g个码字的第i个比特出现错误,并对第g个码字的第i个比特进行纠错,使
本发明提出的用于通信的基于图形处理器的bch码并行译码方法,其优点是:
本发明实现的bch码译码方法,提出了一种新颖bch码并行译码方法,可以在一个码字内实现bch码并行译码,充分利用图形处理器强大运算能力,具有吞吐率高,时延低等优点;同时采用全新的软硬件架构computeunifieddevicearchitecture(cuda)作为bch码译码方法的软硬件架构,可以将图形处理器视为一个并行数据计算设备,对所进行计算进行分配和管理,bch码译码方法的最大纠错个数、本原多项式、码长等译码参数可以灵活配置,与基于fpga和asic的bch码译码方法相比,配置更加灵活、通用性和可重构性更高、更便于开发人员编程实现。
附图说明
图1为本发明提出用于通信的基于图形处理器的bch码并行译码方法流程框图。
图2为本发明方法实施例中涉及的bch码的生成多项式,其中g1为本原多项式。
具体实施方式
本发明提出的用于通信的基于图形处理器的bch码并行译码方法,其流程框图如图所示,包括以下步骤:
(1)根据bch码的本原多项式,生成一个有限域查找表log(β)和exp(e),生成过程如下:
(1-1)从bch码本原多项式产生的有限域gf(2q)中获取一个非零元素β,β=αe,其中,e为非零元素β的序号,0≤e≤2q-2,α为bch码本原多项式的一个根,q为本原多项式的次数;
(1-2)在图形处理器的全局内存中,以非零元素β为地址存储非零元素序号e,以非零元素序号e为地址存储非零元素β;
(1-3)遍历bch码本原多项式产生的有限域gf(2q)中的所有非零元素,重复步骤(1-1)和步骤(1-2),得到非零元素β与非零元素序号e之间的映射表,记为有限域查找表log(β)和exp(e);
在本发明方法中,根据上述获得的查找表log(β)和exp(e),有限域上gf(2q)上的两个非零元素x和y相乘,由公式xy=exp(mod(log(x)+log(y),2q-1))计算,两个非零元素x和y相除,由公式x/y=exp(mod(log(x)-log(y),2q-1))计算,其中mod(log(x)+log(y),2q-1),表示log(x)+log(y)除以2q-1的余数;
有限域上gf(2q)上的两个元素x和y相加,由公式
有限域上gf(2q)上的非零元素x的u次幂,由公式xu=exp(mod(log(x)×u,2q-1))计算;
为了叙述方便下文中所有涉及bch码本原多项式产生的有限域gf(2q)中的运算,默认省略取模运算mod(.);
(2)利用步骤(1)生成的有限域查找表log(β)和exp(e),生成用于bch码译码的伴随式计算查找表
(2-1)初始化伴随式序号j=0;
(2-2)初始化计算参数
(2-3)计算计算参数
(2-4)利用步骤(1)得到的有限域查找表log(β)和exp(e),计算得到
(2-5)在图形处理器的全局内存中,以
(2-6)对
(2-7)对j进行判断,若j<2t-1,则使j=j+1,返回步骤(2-2),若j=2t-1,,得到伴随式计算查找表
(3)利用以下方法,产生n个用于bch码译码的伴随式sg(x),
(3-1)根据图形处理器从信道中接收的码字数n、bch码的最大纠错个数t和码字长度n,将图形处理器中的流处理器、共享内存、寄存器等运算资源分配为
(3-2)对步骤(3-1)图形处理器中的每个线程块分配32个子线程,字线程的序号为v,32m≤v≤32m-1,共得到
(3-3)在步骤(3-1)的线程块内进行如下并行计算,得到第一临时变量bg(v,j):
其中,v为子线程的序号,
(3-4)利用归约算法,在每个线程块内对步骤(3-3)的临时变量bg(v,j)进行bch码本原多项式产生的有限域gf(2q)中的求和计算,得到第二临时变量
具体并行计算步骤为:
最后子线程序号为32m中的bg(v,j),即为第二临时变量cg(m,j);
(3-5)利用原子按位异或操作,在每个线程块间对步骤(3-4)的第二临时变量cg(m,j)进行有限域gf(2q)中的求和运算,得到
由于图形处理器线程块间不能使用归约求和,本发明方法采用原子按位异或操作,对cg(m,j)进行有限域gf(2q)中的求和运算,得到
(4)根据步骤(3)的n个伴随式,利用以下方法,并行计算得到n个错误位置方程,其中bch码本原多项式产生的有限域gf(2q)中的加法和乘法由步骤(1)中得到的有限域查找表log(β)和exp(e)获得,包括以下步骤:
(4-1)初始化时,使k=0,
(4-2)设定一个第四临时变量
(4-3)根据用于bch码译码的公式
(4-4)根据用于bch码译码的公式
计算得到第一临时多项式
(4-5)根据用于bch码译码公式的
(4-6)对迭代次数进行判断,若k<t-1,则使k=k+1,返回执行步骤(4-2),若k≥t-1,则得到n个错误位置方程
(5)并行求解步骤(4)中n个错误位置方程σg(x),具体方法为:
(5-1)根据码字数量n,重新将图形处理器中的流处理器、共享内存、寄存器等运算资源分配为n个线程块,根据码字长度n,为每个线程块分配n个子线程,将线程块序号记为g,0≤g≤n-1,将子线程序号记为i,一个子线程对应码字的一个比特,0≤i≤n-1;
(5-2)在每个线程块内,将αi代入步骤(4)中得到的错误位置方程,得到σg(αi),其中α为bch码本原多项式的一个根,其中bch码本原多项式产生的有限域gf(2q)中的加法和乘法由步骤(1)中得到的有限域查找表logβ)和exp(e)获得;
(5-3)对上述计算结果σg(αi)进行判断,若计算结果为非零元素,则判定从信道中接收的第g个码字的第i个比特无错误,若计算结果为零元素,则判定第g个码字的第i个比特出现错误,并对第g个码字的第i个比特进行纠错,使
以下介绍本发明方法的一个实施例:
以dvb-s2中n=58320,t=8的bch码为例,该码信息长度为58192比特,生成的多项式如图2所示。
本实施例采用的gpu为nvidiagtx1080ti,包含3584个流处理器,单精度浮点运算能力为10tflop。
(1)根据bch码的本原多项式,生成一个有限域查找表log(β)和exp(e),生成过程如下:
(1-1)从bch码本原多项式产生的有限域gf(2q)中获取一个非零元素β,β=αe,其中,e为非零元素β的序号,0≤e≤2q-2,α为bch码本原多项式的一个根,q为本原多项式的次数,本原多项式的次数q=16,所以有限域查找表log(β)和exp(i)的大小为216×4=218字节;
(1-2)在图形处理器的全局内存中,以非零元素β为地址存储非零元素序号e,以非零元素序号e为地址存储非零元素β;
(1-3)遍历bch码本原多项式产生的有限域gf(2q)中的所有非零元素,重复步骤(1-1)和步骤(1-2),得到非零元素β与非零元素序号e之间的映射表,记为有限域查找表log(β)和exp(e);
(2)利用步骤(1)生成的有限域查找表log(β)和exp(e),生成用于bch码译码的伴随式计算查找表
(2-1)初始化伴随式序号j=0;
(2-2)初始化计算参数
(2-3)计算计算参数
(2-4)利用步骤(1)得到的有限域查找表log(β)和exp(e),计算得到
(2-5)在图形处理器的全局内存中,以
(2-6)对
(2-7)对j进行判断,若j<2t-1,则使j=j+1,返回步骤(2-2),若j=2t-1,,得到伴随式计算查找表
(3)利用以下方法,产生n个用于bch码译码的伴随式sg(x),sg(x)=1+
(3-1)根据图形处理器从信道中接收的码字数n、bch码的最大纠错个数t=8和码字长度n=58320,将图形处理器中的流处理器、共享内存、寄存器等运算资源分配为n×16×456个线程块,将线程块的三维索引记为(g,j,m),其中g为码字序号,0≤g≤n-1,j为bch码的伴随式系数序号,0≤j≤15,将长度为n的码字分为
(3-2)对步骤(3-1)图形处理器中的每个线程块分配32个子线程,字线程的序号为v,32m≤v≤32m-1,共得到n×16×456×32个子线程,如果每次只对一个码字进行译码,即n=1,需要分配线程233472个,远大于流处理器个数3584,可以充分利用gpu的运算资源,提高译码吞吐率、降低译码延迟;
(3-3)在步骤(3-1)的线程块内进行如下并行计算,得到第一临时变量bg(v,j):
其中,v为子线程的序号,
(3-4)利用归约算法,在每个线程块内对步骤(3-3)的临时变量bg(v,j)进行bch码本原多项式产生的有限域gf(2q)中的求和计算,得到第二临时变量
具体并行计算步骤为:
其中
(3-5)利用原子按位异或操作,在每个线程块间对步骤(3-4)的第二临时变量cg(m,j)进行有限域gf(2q)中的求和运算,得到
(4)根据步骤(3)的n个伴随式,利用以下方法,并行计算得到n个错误位置方程,其中bch码本原多项式产生的有限域gf(2q)中的加法和乘法由步骤(1)中得到的有限域查找表log(β)和exp(e)获得,包括以下步骤:
(4-1)初始化时,使k=0,
(4-2)设定一个第四临时变量
(4-3)根据用于bch码译码的公式
(4-4)根据用于bch码译码的公式
计算得到第一临时多项式
(4-5)根据用于bch码译码公式的
(4-6)对迭代次数进行判断,若k<t-1,则使k=k+1,返回执行步骤(4-2),若k≥t-1,则得到n个错误位置方程
(5)并行求解步骤(4)中n个错误位置方程σg(x),具体方法为:
(5-1)根据码字数量n,重新将图形处理器中的运算资源分配为n个线程块,根据码字长度n=58320,为每个线程块分配n个子线程,将线程块序号记为g,0≤g≤n-1,将子线程序号记为i,一个子线程对应码字的一个比特,0≤i≤58319,每个码字分配58320个线程,远大于流处理器个数3584,可以充分利用gpu的运算资源,降低译码延迟;
(5-2)在每个线程块内,将αi代入步骤(4)中得到的错误位置方程,得到σg(αi),其中α为bch码本原多项式的一个根,其中bch码本原多项式产生的有限域gf(2q)中的加法和乘法由步骤(1)中得到的有限域查找表log(β)和exp(e)获得;
(5-3)对上述计算结果σg(αi)进行判断,若计算结果为非零元素,则判定从信道中接收的第g个码字的第i个比特无错误,若计算结果为零元素,则判定第g个码字的第i个比特出现错误,并对第g个码字的第i个比特进行纠错,使
- 还没有人留言评论。精彩留言会获得点赞!