一种基于深度学习的极化码SSCL算法译码器的制作方法
本发明属于通信信道编码的译码技术领域,涉及一种与深度学习结合的极化码译码器,特别是一种相比于传统的sscl算法的译码器具有更少的计算次数,达到利用深度学习来降低译码延迟效果的极化码译码器。
背景技术:
自信道编码理论建立之后,信道编码技术已经经历了几十年的发展和革新。极化码作为近十年来提出的一种编码技术,它具备了像代数编码那样特定的编译码结构,同时也采用了信道极化的方式来建立编译码的理论基础。极化码通过信道联合和信道分裂两种操作得到了若干分裂信道,它们的容量呈现出两极分化的趋势,即随着码长的增加或者趋向于完全噪声信道,或者趋向于完全无噪声信道,并以此为基础证明了极化码可以达到任意二进制输入离散无记忆信道的对称容量。极化码所采用的信道极化的编码思想和之前已经出现的编码技术完全不同,因此引起了人们的广泛关注。
seyyeda.h.等人提出了sscl译码的算法,这个算法为了降低scl解码的时间复杂度,也提出了基于rate-1、rate-0和rep节点的路径度量计算方法,这些节点的计算是源于原始的scl算法。简化的路径度量依赖于由各自节点标识的根节点的llr值。因此,可以不需要遍历所有节点来正确计算它们的llr值。对于这三种节点,他们证明了所提出的计算与原始scl中所提出的计算完全等价。而且还提出了一种硬件友好的rate-1节点的路径度量计算方法,并证明它与遍历解码树的方法是等价的。
虽然sscl相对于scl具有更好的译码时延,但是对于这几种节点之外的情况仍使用原始scl的计算方法,这样还会产生较高的译码延迟。本发明是对sscl算法的进一步优化。
技术实现要素:
本发明为了解决sscl对于特殊节点以外的节点有较高延迟的问题,提供了一种结合深度学习神经网络的sscl译码算法的译码器,主要包含5个计算模块,正常scl计算模块、rate-0计算模块、rep计算模块、rate-1计算模块和普通节点的dnn计算模块。对于一般节点也能减少译码延迟;同时用深度神经网络(dnn)进行极化码译码,其性能能够达到最大后验概率,这样相比于传统的译码会有一定的性能提升。
本发明的基本构思:针对sscl无法应对的其他类型节点,采用一种深度神经网络的译码模块进行译码。但由于深度神经网络应用于极化码的译码有着一定的限制,因为在训练深度神经网络时,所采用的训练集要包含所用的译码可能,这样才能训练一个拟合较好的网络。当在译码过程中遇到上述提到的三种特殊节点以外的节点时,采用深度神经网络来进行译码。然后根据译码出的结果计算更新后的路径度量值,再继续进行译码。这种与深度神经网络结合的sscl译码器除了保留原有的rate-0、rate-1和rep节点的低译码延迟特性外,还用深度神经网络对普通节点译码来降低译码时延,最后达到一个降低整体译码延时效果。
基于以上的设计构思,本发明所采用的设计方案为:译码器的译码原理结构主要分为三个部分,在遇到不同节点之前的scl树型译码部分、使用三种特殊节点的译码部分和使用深度神经网络译码的部分。对于第一部分,也就是在遇到不同节点之前的scl树型译码部分,由于scl译码算法相当于有l条路径的sc译码,所以在这一部分也采用sc译码的树型译码方式,这种方式就是用二叉树图来表示scl译码的过程。对于第s层,节点v(s,k)表示第s层的第k个节点,该节点包含了对数似然比(llr)信息
αr[i]=αv[i](1-2βl[i])+αv[i+2s-1](2)
其中,0≤i≤2l-1,βl为节点vl的回传信息。对于节点v,
得出βv的唯一途径是由其左右子节点的βl和βr根据式(3)计算得来。当这个计算过程计算到最下面一层,就要计算对应路径的路径度量值(pm),通过公式(4)来进行计算得到,
这其中,l是路径的索引,代表的是第l条路径,
通过第一部分计算后,向下传递的llr值会根据节点类型的不同使用不同的计算方法。这就进入第二部分或者第三部分,若接下来的节点是属于第二部分内的那三种节点,就会使用对应特殊节点的计算方式。对于rate-1节点,能够在nv个时间步长中译码极化码部分码字,避免了完整的树搜索,而scl译码则需要3nv-2步。最后计算路径度量值如公式(5)所示。
对于rate-0节点来说,其对应的叶子节点全是冻结位,所以这种节点的计算最多可以在log2nv个时间步长内完成,因为简化后的rate-0节点最多只需要将nv个数字相加即可。
对于rep节点,译码最多可以在1+log2nv的时间步长中完成,而不是在3nv-2步长中完成,因为简化的rep节点只需要将最多nv个数字相加,并从得到的2l个候选中选择最好的l个。其计算路径度量值如公式(7)所示。
若从第一部分传递下来的llr值遇到的是普通节点,就进入到译码器的第三部分,在这一部分里将使用深度神经网络进行译码。在此之前有人得出用深度神经网络模拟sc译码的过程,一个节点所消耗的时间步长为网络层数加1,这里假设深度神经网络的层数为n,则译码所需的时间步长为n+1,然后再进行路径度量值的计算,这里所消耗的总时间步长为n+1+nv。这相比于没有使用dnn来计算普通节点有着很大的译码时延的降低。最后把所有译码信息处理后作为译码输出。
本发明相对现有技术具有的优点和有益效果为:
1)本发明相比于原先的sscl译码器降低了一定的译码时延,且在性能上没有损耗。
2)本发明所涉及到的dnn网络只会在译码器设计时需要大量的计算,但在之后的生产和使用中只是固定参数的矩阵,不再需要训练网络所带来的资源消耗。
3)本发明针对于非特殊节点来说,只需要一个dnn网络的参数矩阵即可,所以在生产的时候不会占用太多的存储资源。
附图说明
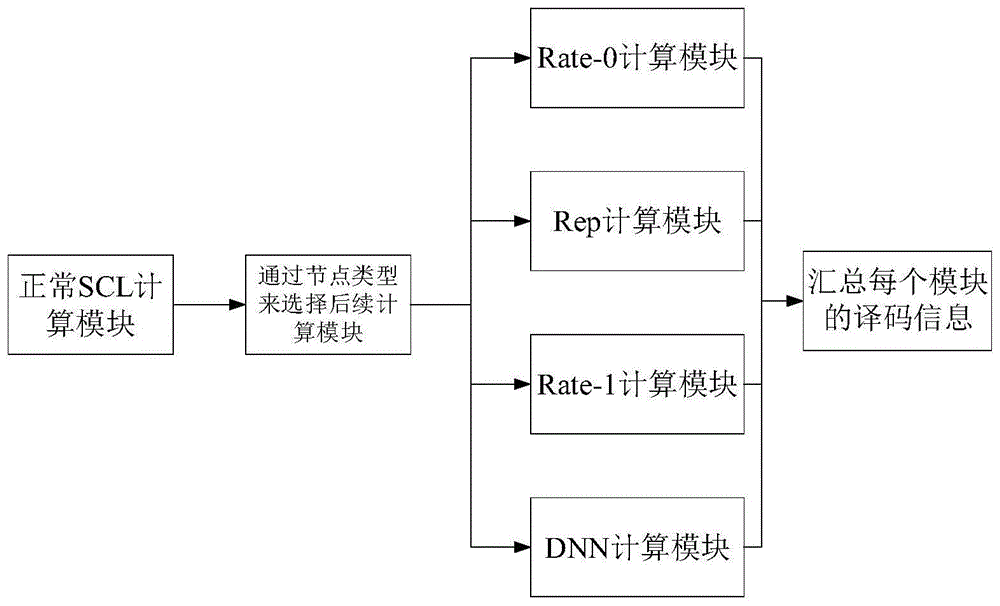
图1为本发明译码器功能结构图;
图2为本发明译码算法结构图;
图3为极化码的64码长的译码树形图;
图4为本发明数据集获取流程图;
具体实施方式
下面结合附图对本发明作进一步详细描述,以下实施例有助于对本发明的理解,是比较好的应用实例,但不应看作是对本发明的限制。
如图1所示,本发明包含5个计算模块,正常scl计算模块、rate-0计算模块、rep计算模块、rate-1计算模块和普通节点的dnn计算模块,在scl译码过程中使用树型译码方式,从根节点到中间某层使用正常scl计算,再在该层对码字进行分类,引入了4种计算,达到提前译出码字,停止剩下的树搜索的目的。
如图2所示,在这里为了方便说明,采用码长为64比特,码率为0.5,对节点的分类是采取八个一组进行分类。令图中s=1的那层的节点序号从上到下依次为1,2,…,8,其中,黑色圆环节点为rate-0节点,灰色节点为rep节点,黑色节点为rate-1节点,白色节点为普通节点。在scl译码树型译码中,每个节点须计算与l条相对应的α与β值,并由当前节点的α值与左子节点的βl值来计算右子节点的αr值,也就是llr值。本译码器的具体译码过程如下:
1)信道传递过来的信息到s=4层进入树型译码的根节点,这时译码器进入正常scl计算模块,在此模块中以递归的方式向下计算α值,也就是llr值。
2)当译码译到s=1的那层的第一个节点时,此时判定该节点为rate-0节点,就进入rate-0计算模块,直接获得最后一层的判决结果并输出相应的硬判决值β1,再更新路径度量值,并结合β1与s=2那层的第一个节点的α值计算s=1层的第二个节点的α2值,由于该节点为rep节点,就进入rep计算模块,故可直接获得最终硬判决结果β2和相应的路径度量值。然后计算这一层的第三个节点,由于它是rep节点,所以计算方式与前一个节点一样。
3)由于第4到第7节点为普通节点,当译码器计算这些节点时,进入dnn计算模块,获取最终的判决值,然后再计算对应的路径度量值。
4)最后一个节点为rate-1,这样就进入rate-1计算模块,故直接计算获得β8,然后再计算路径度量值。最后选取路径度量值最大的一条路径的β1-8,即为最终的译码输出值。
如图3所示,这是一个64码长的译码树形图,在此将使用此例来说明本发明改进后的性能提升。对于scl,需要2n-2+k个时间步长来完成译码计算,其中k是代码中的信息位的数量。在sscl中,rate-0节点最多可以在log2nv时间步长内完成计算,这里的nv代表当前节点的所有叶子节点,rep节点最多可以在1+log2nv时间步长内完成计算,rate-1节点能够在nv个时间步长内完成计算。而在本发明的译码器中,其他节点的计算时间步长和sscl一样,但在对于普通节点的dnn计算模块来说,只需要在网络层数加一个时间步长就可以完成计算。本实施例提出的译码器与其他译码方式的时间步长比较,如表1所示。
表1不同极化码译码方式的时间步长消耗的比较
如图4所示,dnn译码器的训练集是成对生成的,训练集中的llr值为训练时网络的输入,而包含冻结位和原始信息的信息作为训练的对比集,对网络进行有监督的训练。本发明中网络的输入采用所需层的普通节点的llr值作为训练时输入的llr值,并以最后一层的译码值作为训练的对比集。由该训练集训练得出的网络就可以适用于普通节点,本发明中的dnn所学习的是一个n=16的scl译码树结构。
本实例采用大小为256-128-64的三隐藏层dnn网络,制作了1000000个样本作为数据集,训练时的并行度设置为8,epoch为212,并以随机梯度下降法的改进算法adadelta作为该dnn网络的参数优化算法对网络进行训练。
结合实验结果与表1得出,当码长为64、码率为1/2时,本发明的译码延迟比sscl的译码延迟降低约27%。
上述实施例不以任何形式限制本发明,凡采用本发明的相似结构、方法及其相似变化方式所获得的技术方案,均在本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!