一种基于深度学习的极化码翻转译码方法及系统与流程
本发明涉及无线通信技术领域,更具体地说,涉及一种基于深度学习的极化码翻转译码方法及系统。
背景技术:
迄今,信道编码已发展了70余年。作为第一个可实现对称二进制或非二进制输入离散无记忆通道(binary-inputornonbinary-input,discrete,memorylesschannels,b-dmc)信道容量的码字,极化码吸引了越来越多的关注。在5g标准化进程中,极化码因其较大的性能提升效果,被选为5g增强信道场景(enhancedmobilebroadband,embb)控制信道的前向纠错(forwarderrorcorrection,fec)代码。为了满足5g的低延迟和高速要求,研究令人满意的具有高并行度及低复杂度的高效极化码译码器是十分迫切且有必要的。
目前来说,应用最广的极化码译码算法包括连续消除(successivecancellation,sc)译码算法及置信传播(beliefpropagation,bp)译码算法。作为极化码较好的译码算法,sc译码算法虽然在复杂度方面可显示出其优势,但受到逐位译码策略的限制,无法获得令人满意的有限长度纠错性能。通过在译码过程中进行更多次尝试,连续消除列表(successivecancellationlist,scl)译码算法和连续消除堆栈(successivecancellationstack,scs)译码算法被提出作为sc译码算法的改进。仿真结果表明这两种基于sc的改良译码器均可实现接近最大似然(maximumlikelihood,ml)译码器的性能。
与sc译码算法相比,bp译码器更适合于低延迟和高吞吐量应用,因为其能够并行处理接收到码字的对数似然比(log-likelihoodratios,llrs)。但是,与传统sc译码相似,bp译码的性能需要被提升。受sc比特翻转(scbit-flipping,scf)译码算法的启发,基于临界集的bp比特翻转(bpbit-flipping,bpf)译码算法被提出,以识别可能的错误比特并执行翻转操作。现有的bp算法存在下述问题:现有基于bpf的工作有效地识别了不可靠的比特,但是与传统的bp译码器相比,译码延迟更长,因此能够以较少的bp译码翻转尝试次数来准确地识别不可靠比特的最佳翻转策略仍然是一个悬而未决的问题。
近年来,深度学习(deeplearning,dl)因其强大的解决复杂任务的能力而被用于许多领域以实现性能提升,同样应用于极化码译码领域。传统基于深度学习的译码器通过学习大量码字,直接用神经网络对译码算法进行拟合来取得接近最优的误码率(biterrorratio,ber)性能。但是,因其在训练时指数增长的复杂度,所提出的译码器仅适用于较短的码字。因此,较高的训练复杂度和较为困难的长码拟合是阻碍应用深度学习作为极化码译码性能提升方案的两个主要障碍。
中国专利申请一种基于比特翻转的极化码置信传播译码方法,申请号cn201811423884.6,公开日2019年6月4日,公开了一种基于比特翻转的极化码置信传播译码方法,涉及无线通信中的信道编码技术领域,本发明中基于比特翻转的极化码置信传播译码方法,使用的码字是循环冗余校验码和极化码形成的级联码。本发明中提出的ω阶关键集合,是在现有的关键集合的概念上进行变换得到的,避免了现有的基于cs的译码方法存在的试探性译码数量呈指数增长的问题。本发明中的方法在传统bp译码器的译码结果未通过crc校验的情况下,通过构造cs-ω,对极化码中位于cs-ω内的信息比特进行翻转(本发明中的比特翻转指的是将被翻转比特的先验对数似然比设置为无穷大),能够纠正传统bp译码器中的错误,从而提高bp译码器的误组率性能。该发明的关键集合基于码树的码率1结点,只利用了极化码的性质,而非bp译码器的输出信息,特别是在低信噪比时性能不够理想。
基于以上的分析可知,现有的极化码译码方法不足以很好地满足实际应用的需求。
技术实现要素:
1.要解决的技术问题
针对现有技术中存在的现有的bpf译码方法计算复杂度较高的不足问题,本发明提供了一种基于深度学习的极化码翻转译码方法及系统,可以在提高系统的译码性能的同时,降低译码复杂度,更好地满足通信系统应用的需求。
2.技术方案
本发明的目的通过以下技术方案实现。
本发明的一种基于深度学习的极化码翻转译码方法,先构建神经网络单元并进行训练,再将译码单元输出的软信息输入至训练好的神经网络单元中得到可能的译码错误位置;而后将可能的译码错误位置反馈至译码单元,译码单元将译码错误位置的译码结果进行翻转,根据翻转位的信息重新开始译码,直至得到译码结果。
更进一步地,包括如下步骤:
步骤一、构建神经网络单元,
构建一个神经网络单元并进行训练,所述神经网络单元包括输入层、隐藏层和输出层;
步骤二、译码单元初始化,
将译码过程中所需的两类对数似然比信息
步骤三、译码,
译码单元执行译码操作,对数似然比信息在迭代过程中不断更新,直至达到最大迭代次数,译码结束,将译码后的软信息传递给译码单元中的校验单元进行校验,若无法通过校验则激活神经网络单元预测可能出错的比特位置;
步骤四、预测,
将译码后的软信息llri输入至神经网络单元得到可能出错的比特位置zi,再将可能出错的比特位置zi输入至译码单元;其中,i∈(1,...,q),q为出错比特位置集合的最大数目;
步骤五、翻转译码,
根据可能出错的比特位置zi,译码单元中的翻转单元依次将zi对应的r值翻转为正无穷或负无穷,继续进行译码,直到通过校验,若将z对应的比特翻转完毕仍未通过校验,则重复步骤四及步骤五,直到达到最大翻转位数w。
更进一步的,步骤二中译码单元初始化公式如下:
其余的软信息置为0。
更进一步的,步骤三中对数似然比信息
其中g执行的是box-plus运算,box-plus运算也称为
更进一步地,步骤四中可能出错的比特位置zi根据以下公式计算:
其中,wij为权重,bj为偏置,xj为每层对应的输入值。
更进一步地,神经网络单元输入层的结点数等于信息位长度k,输入向量为译码后的软信息llri,隐藏层结点数为2*n,n为码长,输出层结点数为k。
更进一步地,利用tensorflow平台对神经网络进行训练,其中,最大迭代次数tepoch为100。
一种基于深度学习的极化码翻转译码系统,使用所述的一种基于深度学习的极化码翻转译码方法,系统包括神经网络单元和译码单元,所述神经网络单元和译码单元连接;神经网络单元用于计算可能出错的比特位置,译码单元用于对待输入译码路径信息进行译码及执行比特翻转操作。
更进一步地,所述译码单元包括置信传播单元、校验单元和翻转单元;置信传播单元连接校验单元和翻转单元,神经网络单元数据发送给译码单元中的翻转单元,数据通过翻转单元处理后传输至置信传播单元,置信传播单元将数据发送至校验单元校验,数据通过置信传播单元发送至神经网络单元。
更进一步的,所述神经网络单元包括输入层、隐藏层和输出层。
本发明实现了一种基于深度学习的极化码翻转译码方法,先构建神经网络单元并进行训练,再将译码单元输出的软信息输入至神经网络单元得到可能的译码错误位置,而后将可能的译码错误反馈至译码单元,译码单元根据译码错误位置将译码结果翻转,重新开始译码直至得到译码结果。本发明解决了现有技术中传统的翻转译码算法复杂度较高,性能不够理想的不足,降低译码复杂度,满足通信系统不同的信道环境及配置要求。
3.有益效果
相比于现有技术,本发明的优点在于:
(1)本发明实现了一种基于深度学习的极化码翻转译码方法,通过神经网络获得可能出错的比特位置,对译码错误位进行翻转,本发明所以译码方法适用于各种信噪比场景,适用性强;
(2)本发明所实现的基于深度学习的极化码翻转译码方法,基于bp译码器的输出通过神经网络预测出错位置,因神经网络训练的准确率较高,较传统的bp翻转算法待翻转比特集合较小,从而减少了每次译码的翻转次数,进而降低了译码器的时间和空间复杂度;
(3)本发明实现了一种基于深度学习的极化码翻转译码系统,通过配置神经网络单元和译码单元,从而将深度学习与传统极化码置信传播译码器结合在一起,通过预测出错的译码位来执行翻转策略,因此提升译码性能,同时,错误路径的早中断使译码复杂度有所降低。
综上所述,本发明可以有效地提高系统的通信性能、数据处理能力并降低译码复杂度,有着良好的实际应用价值。
附图说明
图1为本发明译码系统的结构示意图;
图2为本发明一实施例译码系统的结构示意图;
图3为本发明一实施例译码系统与传统sc和scl的性能对比示意图。
具体实施方式
下面结合说明书附图和具体的实施例,对本发明作详细描述。
实施例1
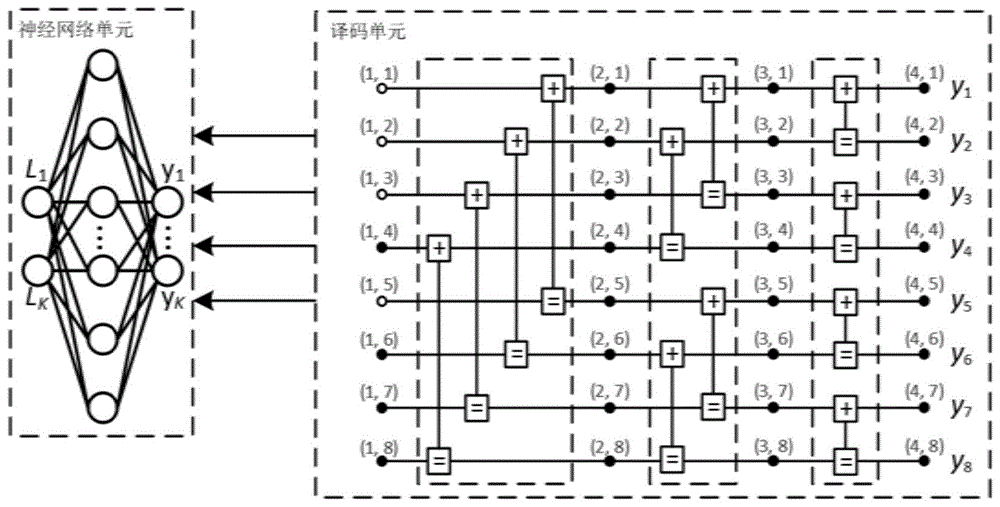
如图2所示,一种基于深度学习的极化码翻转译码系统,所述系统包括译码单元和神经网络单元,译码单元和神经网络单元连接,其中,神经网络单元用于预测译码过程中的出错位置索引,译码单元用于对待译码路径信息进行译码并在发生译码错误时执行位翻转操作;具体地,神经网络单元根据接收到的译码后的软信息计算译码过程中的出错位置索引。
系统所述的神经网络单元包括输入层、隐藏层和输出层;输入层的结点数等于码长k,且输入向量为译码单元输出的软信息,即左端的对数似然比llri;隐藏层结点数为2*k,输出层结点数为k–2。如图2所示,译码单元包括置信传播单元、校验单元和翻转单元,置信传播单元连接校验单元和翻转单元,神经网络单元数据发送给译码单元中的翻转单元,数据通过翻转单元处理后传输至置信传播单元,置信传播单元将数据发送至校验单元校验,数据通过置信传播单元发送至神经网络单元。
在译码单元中,置信传播单元用于读取待译码信息,且对待译码路径并行进行传播并计算相应的对数似然比,而后将计算得到的软信息输入至校验;校验单元将软信息通过硬判决转换为译码后的码字,并进行crc校验,若校验无法通过则将软信息传给神经网络单元;翻转单元接收神经网络单元输出的出错位置索引集合,并执行比特翻转操作,将翻转后的r信息传给置信传播单元以继续译码。本发明的一种基于深度学习的极化码翻转译码系统,通过预测出错的译码位来执行翻转策略,因此提升译码性能,同时,错误路径的早中断使译码复杂度有所降低。
本发明的一种基于深度学习的极化码翻转译码方法,先构建神经网络并进行训练,再将译码器输出的软信息输入至训练好的神经网络中得到可能的译码错误位置,训练好的神经网络适用于各种信噪比场景,提高了本方法的适用性。系统将可能的译码错误位置反馈至译码器,译码器将译码错误位置的译码结果进行翻转,根据翻转位的信息重新开始译码,和传统bp翻转算法相比较小的待翻转比特集合减少了每次译码的翻转次数,进而降低了译码器的时间和空间复杂度。在译码过程中如果通过校验则译码停止输出译码结果,否则继续进行翻转知道达到最大翻转次数。
需要说明的是,本发明中接收到的信息为yi,其长度为n,信息位个数为k,信息位组成的集合为a,译码过程中传输的两类对数似然比信息为
i∈(1,...,n+1),i∈(1,...,n),n=log2n,t表示译码器迭代次数,译码器输出的软信息为llri。
所述译码方法具体的步骤如下:
步骤一、构建神经网络,
构建一个神经网络并进行训练,所述神经网络单元包括输入层、隐藏层和输出层;输入层的结点数等于信息位长度k,且输入向量为译码器输出的软信息llri,隐藏层结点数为2*k,输出层结点数为k-2;本实施例利用tensorflow平台对神经网络进行训练,在进行神经网络单元训练时,训练集由240000组在不同信噪比下产生的码字组成,每120个为一批,学习率设定为0.001,最大迭代次数tepoch为100。
步骤二、译码单元初始化,
将译码过程中所需的两类对数似然比信息
i∈(1,...,n+1),i∈(1,...,n),n=log2n,n表示码长,t表示译码单元迭代次数。
具体初始化方式如下:
其余的软信息置为0。
步骤三、译码,
译码单元执行译码操作,对数似然比信息在迭代过程中不断更新,直至达到最大迭代次数tmax,译码结束,将译码后的软信息llri传递给校验单元进行crc校验,若无法通过crc校验则激活神经网络单元预测可能出错的比特位置。
其中对数似然比信息
其中g执行的是box-plus运算,也称为
步骤四、预测,
译码后的软信息llri输入至神经网络单元得到可能出错的比特位置zi,再将可能出错的比特位置zi输入至译码单元;其中,i∈(1,...,q),q为出错比特位置集合的最大数目。可能出错的比特位置索引根据以下公式计算得出:
其中,wij为权重,bj为偏置,xj为每层对应的输入值,σ为激活函数sigmoid,
步骤五、翻转译码,
根据可能出错的比特位置zi,译码器中的翻转单元依次将zi对应的r值翻转为正无穷或负无穷,继续进行译码,直到通过校验,若将z对应的比特翻转完毕仍未通过校验,则重复步骤四及步骤五,直到达到最大翻转位数w;和传统bp翻转算法相比较小的待翻转比特集合减少了每次译码的翻转次数,进而降低了译码器的时间和空间复杂度;而神经网络良好的近似性能保证了译码性能。
本发明的一种基于深度学习的极化码翻转译码方法,通过在译码前训练神经网络过程中修改神经网络的层数、输入输出结点个数及输入向量可以预测在不同码长及码率下的出错位置信息,可以满足通信系统不同的信道环境及配置要求,具有丰富的灵活度,且具有可配置性;本发明可以有效地提高系统的通信性能和数据处理能力,并且可以降低译码复杂度。
结合图2所示译码系统的结构图,图1为一种码长n为8,信息位个数k为4的译码系统,左端黑色结点为信息位,即本系统神经网络单元所访问结点。本实施例的神经网络单元的输入向量为长度为4的接收到的对数似然比,输出为长度为4的各比特错误概率,并传输至译码单元。假定错误集的大小为q,共翻转w位,则在译码单元中,当q=2,即每次最大翻转个数为2个,w=2即共翻转2位时,执行两次神经网络预测,每次预测结束后根据错误集中的索引进行翻转,即共进行四次译码,每次将神经网络单元输出选取错误概率最大的两位进行翻转。
图3为码长n=128,信息位个数k=19时不同基于bp的译码算法的性能比较,横坐标表示信噪比eb/n0=1.0-4.0db,纵坐标表示误帧率(frameerrorrate,fer)。本发明选择了计算复杂度相同的翻转1位6次(w=1,q=6)和翻转2位3次(w=2,q=3)的bpf进行比较,由图可得,在各种信噪比下,本发明的译码系统性能优于传统的bp译码器,且在高信噪比下,本发明的译码系统性能与scl,列表长度为8的译码器接近,其中列表长度为现有scl译码器的每层扩展路径个数,本发明的译码系统具有优异的性能。此外,和传统bpf译码算法相比,本发明的译码系统在翻转次数较少的情况下可达到较好的性能,本发明的译码系统在复杂度降低方面具有一定优势。
综上所述,本发明的一种基于深度学习的极化码翻转译码方法及系统,将深度学习与传统极化码bp译码器结合在一起,通过预测出错的译码位来执行翻转策略,因此提升译码性能,同时,错误路径的早中断使译码复杂度有所降低。本实施例在复杂度和性能上均展现了其优势,其高硬件适配性也显示了对于实际应用的巨大潜力。
以上示意性地对本发明创造及其实施方式进行了描述,该描述没有限制性,在不背离本发明的精神或者基本特征的情况下,能够以其他的具体形式实现本发明。附图中所示的也只是本发明创造的实施方式之一,实际的结构并不局限于此,权利要求中的任何附图标记不应限制所涉及的权利要求。所以,如果本领域的普通技术人员受其启示,在不脱离本创造宗旨的情况下,不经创造性的设计出与该技术方案相似的结构方式及实施例,均应属于本专利的保护范围。此外,“包括”一词不排除其他元件或步骤,在元件前的“一个”一词不排除包括“多个”该元件。产品权利要求中陈述的多个元件也可以由一个元件通过软件或者硬件来实现。第一,第二等词语用来表示名称,而并不表示任何特定的顺序。
- 还没有人留言评论。精彩留言会获得点赞!