视频数据的解码方法与流程
技术领域
本发明涉及一种对视频数据解码的方法,具体而言,涉及一种通过利用空间合并候选区块和时间合并候选区块建构出合并候选区块列表,以此在合并模式下导出运动信息,并且利用所述运动信息来生成预测区块的方法。
背景技术:
用于对视频数据进行压缩的方法包括MPEG-2、MPEG-4以及H.264/MPEG-4AVC。在这些方法中,一副图片被分成若干个宏块以对图像进行编码,其中各个宏块的编码是利用帧内预测或帧间预测来产生预测区块而进行的。原始区块与预测区块之间的差异经过变换形成变换后的区块,生成的变换后的区块然后加以量化,量化过程中利用了一个量化参数以及多个预定的量化矩阵中的一个矩阵。用预定的扫描方式对量化后的区块的量化系数进行扫描,然后进行熵编码。对每个宏块执行量化参数的调整,并利用先前的量化参数进行编码。
在H.264/MPEG-4AVC方法中,利用运动估计来消除连续图片之间的时间冗余。为检测时间冗余,利用一个或多个参考图片来估计当前区块的运动,并利用运动信息执行运动补偿来产生预测区块。运动信息包括一个或多个参考图片索引以及一个或多个运动向量。
在H.264/MPEG-4AVC方法中,只有运动向量的预测和编码用到相邻的运动向量,而参考图片索引的编码并不使用相邻的参考图片索引。另外,因为预测区块的内插使用的是长抽头滤波器,所以用于产生预测区块的计算复杂度高。
然而,如果帧间预测使用了各种大小,那么当前区块的运动信息与一个或多个相邻区块的运动信息之间的关联性增加。如果图像几乎不发生运动或运动缓慢,那么随着图片不断变大,当前区块的运动向量与参考图片内相邻区块的运动向量之间的关联性增加。因此,在图片大小大于高清晰度图片的大小,并且在运动估计和运动补偿中可以使用各种大小的情况下,上述传统的压缩方法对运动信息的压缩效率便会降低。
技术实现要素:
[技术问题]
本发明涉及一种对视频数据解码的方法:通过利用空间合并候选区块和时间合并候选区块构建合并候选区块来以此导出运动信息,利用由所述运动向量确定的滤波器生成预测区块。
[技术解决方案]
本发明的一个方面提供一种对视频数据解码的方法,包括:导出当前预测单元的参考图片索引和运动向量;利用所述参考图片索引与所述运动向量生成所述当前预测单元的预测区块;通过对量化系数分量执行反扫描生成量化后的区块;利用量化参数对所述量化后的区块执行反量化生成变换后的区块;通过对所述变换后的区块执行反变换生成残余区块;以及利用所述预测区块和所述残余区块生成重建的像素。利用根据所述运动向量所选择的内插滤波器来生成所述预测区块的预测像素。
[有利效果]
根据本发明的方法包括:导出当前预测单元的参考图片索引和运动向量;利用所述参考图片索引与所述运动向量生成所述当前预测单元的预测区块;通过反扫描、反量化以及反变换生成残余区块;以及利用所述预测区块和所述残余区块生成重建的像素。利用根据所述运动向量所选择的内插滤波器来生成所述预测区块的预测像素。相应地,通过将各种合并候选区块包括进来而提高运动信息的编码效率。另外,根据所述运动向量所确定的这些预测像素的位置来选择不同的滤波器,以此减小编码器和解码器的计算复杂度。
附图说明
图1是根据本发明的图像编码装置的方框图。
图2是示出了根据本发明的以帧间预测模式对视频数据编码的方法的流程图。
图3是示出了根据本发明的由运动向量表示像素位置的概念图。
图4是示出了根据本发明的以合并模式对运动信息编码的方法的流程图。
图5是示出了根据本发明的空间合并候选区块的位置的概念图。
图6是示出了根据本发明的按不对称分割模式的空间合并候选区块的位置的概念图。
图7是示出了根据本发明的按再一种不对称分割模式的空间合并候选区块的位置的概念图。
图8是示出了根据本发明的按另一种不对称分割模式的空间合并候选区块的位置的概念图。
图9是示出了根据本发明的按又一种不对称分割模式的空间合并候选区块的位置的概念图。
图10是示出了根据本发明的时间合并候选区块的位置的概念图。
图11是示出了根据本发明的存储运动信息的方法的概念图。
图12是根据本发明的图像解码装置200的方框图。
图13是示出了根据本发明的以帧间预测模式对图像解码的方法的流程图。
图14是示出了以合并模式导出运动信息的方法的流程图。
图15是示出了根据本发明的以帧间预测模式生成残余区块的过程的流程图。
具体实施方式
下文中,结合附图详细描述本发明的各实施例。然而,本发明不限于下文所述的示范性实施例,而是可以按各种方式实施。因此,可以对本发明进行许多其他的修改和更改,并且应了解,在所公开的概念的范围内,本发明可以按不同于所具体描述的其他方式加以实践。
根据本发明的图像编码装置以及图像解码装置可以是用户终端,例如个人计算机、个人移动终端、移动多媒体播放器、智能电话或无线通信终端。所述图像编码装置以及图像解码装置可以包括用于与各种设备通信的通信单元、用于存储在图像编码和解码中所用到的各种程序和数据的存储器。
图1是根据本发明的图像编码装置100的方框图。
参看图1,根据本发明的图像编码装置100包括图片分割单元110、帧内预测单元120、帧间预测单元130、变换单元140、量化单元150、扫描单元160、熵编码单元170、反量化/变换单元180、后处理单元190以及图片存储单元195。
图片分割单元110将一幅图片或切片(slice)分割成若干个最大编码单元(LCU),然后将每个LCU分割成一个或多个编码单元。LCU的大小可以是32x32、64x64或128x128。图片分割单元110用于确定每个编码单元的预测模式和分割模式。
一个LCU包括一个或多个编码单元。该LCU采用递归四叉树结构,以此规定LCU的分割结构。用于规定编码单元大小的最大值和最小值的各个参数包括在一个序列参数集中。分割结构用一个或多个分开的编码单元标记(split_cu_flag)来规定。编码单元的大小是2Nx2N。如果LCU的大小是64x64,最小编码单元(SCU)的大小是8x8,那么编码单元的大小可以是64x64、32x32、16x16或8x8。
一个编码单元包括一个或多个预测单元。在帧内预测中,预测单元的大小是2Nx2N或NxN。在帧间预测中,预测单元的大小由分割模式决定。如果编码单元是对称分割的,那么分割模式采用2Nx2N、2NxN、Nx2N与NxN其中之一。如果编码单元是不对称分割的,那么分割模式采用2NxnU、2NxnD、nLx2N与nRx2N其中之一。分割模式可以根据编码单元的大小而定以减小硬件复杂度。如果编码单元的大小是最小值,那么不可以采用不对称分割。同样,如果编码单元的大小是最小值,那么不可以采用NxN分割模式。
一个编码单元包括一个或多个变换单元。变换单元采用递归四叉树结构,以此规定编码单元的分割结构。分割结构用一个或多个分开的变换单元标记(split_tu_flag)来规定。用于规定变换单元大小的最大值和最小值的各个参数包括在一个序列参数集中。
帧内预测单元120用于确定当前预测单元的帧内预测模式,并利用这个帧内预测模式产生预测区块。
帧间预测单元130利用存储在图片存储单元195中的一个或多个参考图片来确定当前预测单元的运动信息,并生成所述预测单元的预测区块。其中运动信息包括一个或多个参考图片索引以及一个或多个运动向量。
变换单元140用于变换残余区块,以生成变换后的区块。残余区块的大小与变换单元相同。如果预测单元大于变换单元,那么当前区块与预测区块之间的残余信号被分成多个残余区块。
量化单元150用于确定变换后的区块的量化中使用的量化参数。量化参数是一个量化步长。量化参数根据每个量化单元来确定。量化单元的大小可以变化,并且可以是编码单元所允许的大小中的一个。如果编码单元的大小等于或大于量化单元大小的最小值,那么编码单元成为量化单元。最小的量化单元中可以包括多个编码单元。根据每个图片确定量化单元大小的最小值,用于规定量化单元大小的最小值的参数被包括在图片参数集之中。
量化单元150产生一个量化参数预测值,然后将这个量化参数预测值从量化参数中减去,生成一个差值量化参数。对差值量化参数进行熵编码。
量化参数预测值是利用相邻编码单元的量化参数以及先前编码单元的量化参数生成的,如下所述。
依次获取左量化参数、上量化参数以及先前的量化参数。当有两个或两个以上的量化参数可用时,将以此次序获取的前两个可用的量化参数的平均值设置为所述量化参数预测值;当仅有一个量化参数可用时,将这个可用的量化参数设置为量化参数预测值。也就是,如果左量化参数和上量化参数可用,那么将左量化参数和上量化参数的平均值设置为所述量化参数预测值。如果左量化参数与上量化参数中只有一个可用,那么将这个可用的量化参数与先前的量化参数的平均值设置为所述量化参数预测值。如果左量化参数和上量化参数都不可用,那么将先前的量化参数设置为所述量化参数预测值。平均值采取四舍五入法。
通过二进制化处理,将差值量化参数转换成用于表示所述差值量化参数的绝对值的二进制序列与一个用于表示所述差值量化参数的正负号的二进制位,然后对这个二进制序列进行算术编码。如果差值量化参数的绝对值是0,那么这个表示正负号的二进制位可以省略。绝对值的二进制化使用截断一元码。
量化单元150利用量化矩阵和量化参数对变换后的区块进行量化以生成量化后的区块。将量化后的区块提供给反量化/变换单元180和扫描单元160。
由扫描单元160确定对量化后的区块应用扫描模式。
在帧间预测中,如果熵编码使用的是CABAC,那么扫描模式采用的是对角线扫描。量化后的区块的量化系数被分解成系数分量。这些系数分量为有效标记(significant flag)、系数正负号以及系数级。对每一个系数分量应用对角线扫描。有效标记表示的是对应的量化系数是否为零。系数正负号表示非零的量化系数的正负号,系数级表示非零的量化系数的绝对值。
当变换单元的大小大于预定大小时,量化后的区块被分割成多个子集并且对每个子集应用对角线扫描。每个子集的有效标记、系数正负号以及系数级都分别按对角线扫描模式进行扫描。预定大小是4x4。子集是含有16个变换系数的4x4区块。
扫描子集的扫描模式与扫描系数分量的扫描模式相同。对每个子集的有效标记、系数正负号以及系数级的扫描按反方向进行。这些子集的扫描也按反方向进行。
对表示最后一个非零系数位置的参数编码并将其传输到解码侧。表示最后一个非零系数位置的参数指示了量化后的区块中最后一个非零量化系数的位置。为除第一子集和最后子集以外的其他每个子集定义一个非零子集标记并将其传输到解码侧。第一子集含有一个DC系数。最后子集含有最后的非零系数。非零子集标记用来表示子集是否含有非零系数。
熵编码单元170对被扫描单元160扫描后的分量、从帧内预测单元120接收到的帧内预测信息、从帧间预测单元130接收到的运动信息等进行熵编码。
反量化/变换单元180对量化后的区块的量化系数进行反量化,对反量化后的区块进行反变换,以生成残余信号。
后处理单元190执行去块滤波处理,以去除图片重建中产生的块效应。
图片存储单元195从后处理单元190接收后处理后的图像并将图像存储到图片单元中。图片可以是帧或场(field)。
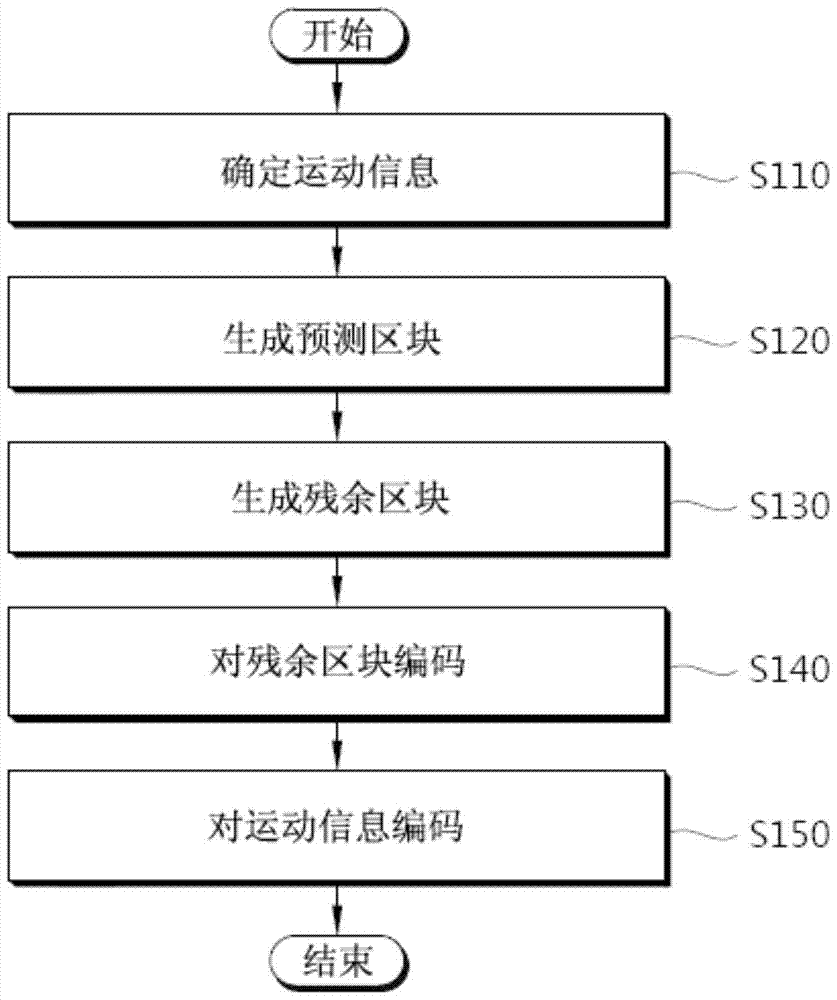
图2是示出了根据本发明的以帧间预测模式对视频数据编码的方法的流程图。
确定当前区块的运动信息(S110)。当前区块是预测单元。当前区块的大小由编码单元的大小和分割模式进行确定。
运动信息随预测类型而变。如果预测类型是单向预测,那么运动信息包括用于指定参考列表0的图片的参考索引和一个运动向量。如果预测类型是双向预测,那么运动信息包括用来指定参考列表0的图片和参考列表1的图片的两个参考索引,以及列表0运动向量和列表1运动向量。
利用这些运动信息生成当前区块的预测区块(S120)。
如果运动向量表示整数型像素位置,那么拷贝运动向量所指定的参考图片的区块来生成预测区块。如果运动向量指示子像素位置,那么对参考图片的像素执行内插来生成预测区块。运动向量采用的是四分之一像素单位。
图3是示出了根据本发明的由运动向量表示像素位置的概念图。
在图3中,标记为L0、R0、R1、L1、A0和B0的像素是参考图片的整数型位置像素,子像素位置处标记为aL0到rL0的像素是要通过内插滤波器进行内插的小数像素,内插滤波器基于运动向量来选择。
如果要执行内插的像素位于子像素位置aL0、bL0或cL0处,那么通过对水平方向上最接近的整数型位置像素应用内插滤波器来生成标记为aL0、bL0或cL0的像素。如果要执行内插的像素位于子像素位置dL0、hL0或nL0处,那么通过对垂直方向上最接近的整数型位置像素应用内插滤波器来生成标记为dL0、hL0或nL0的像素。如果要执行内插的像素位于子像素位置eL0、iL0或pL0处,那么通过对垂直方向上最接近的内插所得的像素(其中每一个的标记中包括字符“a”)应用内插滤波器来生成标记为eL0、iL0或pL0的像素。如果要执行内插的像素位于子像素位置gL0、kL0或rL0处,那么通过对垂直方向上最接近的内插所得的像素(其中每一个的标记中包括字符“c”)应用内插滤波器来生成标记为gL0、kL0或rL0的像素。如果要执行内插的像素位于子像素位置fL0、jL0或qL0处,那么通过对垂直方向上相邻的内插所得的像素(其中每一个的标记中包括字符“c”)应用内插滤波器来生成标记为fL0、jL0或qL0的像素。
根据要执行内插的像素的子像素位置确定内插滤波器,也可以根据预测模式与要执行内插的像素的子像素位置来确定。
表1显示了示范性的滤波器。子像素位置H表示内插方向上的半像素位置。例如,位置bL0、hL0、iL0、jL0和kL0对应于子像素位置H。子像素位置FL和FR表示内插方向上的四分之一像素位置。例如,位置aL0、dL0、eL0、fL0和gL0对应于子像素位置FL,位置cL0、nL0、pL0、qL0和rL0对应于子像素位置FR。
表1
如表1所示,在单向预测中,可以使用6-抽头对称滤波器对半像素位置H的像素执行内插,可以使用5抽头不对称抽头滤波器对四分之一像素位置FL或FR的像素执行内插。在双向预测中,半像素位置H可以使用8抽头对称滤波器,四分之一像素位置FL和FR可以使用8抽头不对称滤波器。
或者,可以完全由要执行内插的像素的子像素位置来确定滤波器。在单向预测中,可以使用8抽头对称滤波器来对半像素位置的像素执行内插,可以使用7抽头不对称滤波器或6抽头不对称滤波器来对四分之一像素位置的像素执行内插。在双向预测中,可以使用抽头数量更少的相同或不同滤波器来对子像素位置的像素执行内插。
利用当前区块和预测区块生成残余区块(S130)。残余区块的大小与变换单元相同。如果预测单元大于变换单元,那么当前区块与预测区块之间的残余信号被分成多个残余区块。
对残余区块编码(S140)。由图1的变换单元140、量化单元150、扫描单元160以及熵编码单元170对残余区块编码。
对运动信息编码(S150)。可以利用当前区块的空间候选区块和时间候选区块对运动信息进行预测性编码。运动信息的编码可以采用跳跃模式、合并模式或AMVP模式。在跳跃模式中,预测单元具有编码单元的大小,运动信息的编码方法与合并模式的相同。在合并模式中,当前预测单元的运动信息等同于一个候选区块的运动信息。在AMVP模式中,利用一个或多个运动向量候选区块对运动信息的运动向量进行预测性编码。
图4是示出了根据本发明的以合并模式对运动信息编码的方法的流程图。
导出空间合并候选区块(S210)。图5是示出了根据本发明的空间合并候选区块的位置的概念图。
如图5所示,合并候选区块是当前区块的左区块(区块A)、上区块(区块B)、右上区块(区块C)、左下区块(区块D)或左上区块(区块E)。这些区块是预测区块。当区块A、B、C和D中有一个或多个不可用时,将左上区块(区块E)设置为合并候选区块。将可用的合并候选区块N的运动信息设置为空间合并候选区块N。N是A、B、C、D或E。
可以根据当前区块的形状以及当前区块的位置,将空间合并候选区块设置为不可用。例如,如果利用不对称分割将这个编码单元分成两个预测单元(区块P0和区块P1),那么区块P0的运动信息很可能就不等同于区块P1的运动信息。因此,如果当前区块是不对称区块P1,那么区块P0被设置为不可用的候选区块,如图6到图9所示。
图6是示出了根据本发明的按不对称分割模式的空间合并候选区块的位置的概念图。
如图6所示,一个编码单元被分割成两个不对称预测区块P0和P1,分割模式是nLx2N模式。区块P0的大小是hNx2N,区块P1的大小是(2-h)Nx2N。h的值是1/2。当前区块是区块P1。区块A、B、C、D和E是空间合并候选区块。区块P0是空间合并候选区块A。
在本发明中,将空间合并候选区块A设置为不可用,不会列到合并候选区块列表上。同样,空间合并候选区块B、C、D或E具有与空间合并候选区块A相同的运动信息,被设置成不可用。
图7是示出了根据本发明的按不对称分割模式的空间合并候选区块的位置的概念图。
如图7所示,一个编码单元被分割成两个不对称预测区块P0和P1,分割模式是nRx2N模式。区块P0的大小是(2-h)Nx2N,区块P1的大小是hNx2N。h的值是1/2。当前区块是区块P1。区块A、B、C、D和E是空间合并候选区块。区块P0是空间合并候选区块A。
在本发明中,将空间合并候选区块A设置为不可用,不会列到合并候选区块列表上。同样,空间合并候选区块B、C、D或E具有与空间合并候选区块A相同的运动信息,被设置成不可用。
图8是示出了根据本发明的按另一种不对称分割模式的空间合并候选区块的位置的概念图。
如图8所示,一个编码单元被分割成两个不对称预测区块P0和P1,分割模式是2NxnU模式。区块P0的大小是2NxhN,区块P1的大小是2Nx(2-h)N。h的值是1/2。当前区块是区块P1。区块A、B、C、D和E是空间合并候选区块。区块P0是空间合并候选区块B。
在本发明中,将空间合并候选区块B设置为不可用,不会列到合并候选区块列表上。同样,空间合并候选区块C、D或E具有与空间合并候选区块B相同的运动信息,被设置成不可用。
图9是示出了根据本发明的按又一种不对称分割模式的空间合并候选区块的位置的概念图。
如图9所示,一个编码单元被分割成两个不对称预测区块P0和P1,分割模式是2NxnD模式。区块P0的大小是2Nx(2-h)N,区块P1的大小是2NxhN。h的值是1/2。当前区块是区块P1。区块A、B、C、D和E是空间合并候选区块。区块P0是空间合并候选区块B。
在本发明中,将空间合并候选区块B设置为不可用,不会列到合并候选区块列表上。同样,空间合并候选区块C、D或E具有与空间合并候选区块B相同的运动信息,被设置成不可用。
也可以根据合并区域来将空间合并候选区块设置为不可用。如果当前区块和空间合并候选区块属于同一个合并区域,那么将此空间合并候选区块设置为不可用。所述合并区域是一个执行运动估计的单位区域,并且指定所述合并区域的信息被包括在一个比特流中。
导出时间合并候选区块(S220)。时间合并候选区块包括时间合并候选区块的参考图片索引以及运动向量。
时间合并候选区块的参考图片索引可以利用相邻区块的一个或多个参考图片索引来导出。例如,左相邻区块的参考图片索引、上相邻区块的参考图片索引以及拐角相邻区块的参考图片索引其中之一被设置为所述时间合并候选区块的参考图片索引。所述拐角相邻区块是右上相邻区块、左下相邻区块以及左上相邻区块其中之一。或者,所述时间合并候选区块的参考图片索引可以设置为零,以减小复杂度。
可以按照下述方法导出所述时间合并候选区块的运动向量。
首先,确定时间合并候选图片。所述时间合并候选图片包括时间合并候选区块。在一个切片中使用一个时间合并候选图片。所述时间合并候选图片的参考图片索引可以设置为零。
如果当前切片是P切片,那么将参考图片列表0的参考图片其中之一设置为所述时间合并候选图片。如果当前切片是B切片,那么将参考图片列表0和1的参考图片其中之一设置为所述时间合并候选图片。如果当前切片是B切片,那么将用于指示所述时间合并候选图片是属于参考图片列表0还是属于参考图片列表1的列表指示符包括在一个切片片头中。用于指定所述时间合并候选图片的参考图片索引可以被包括在这个切片片头中。
接着,确定所述时间合并候选区块。图10是示出了根据本发明的时间合并候选区块的位置的概念图。如图10所示,第一候选区块可以是区块C的右下角区块(区块H)。区块C的大小和位置与当前区块的相同,其位于所述时间合并候选图片内。第二候选区块是覆盖区块C的中心的左上像素的一个区块。
所述时间合并候选区块可以是第一候选区块也可以是第二候选区块。如果第一候选区块可用,那么将所述第一候选区块设置为所述时间合并候选区块。如果第一候选区块不可用,那么将第二候选区块设置为所述时间合并候选区块。如果第二候选区块也不可用,那么便将所述时间合并候选区块设置为不可用。
所述时间合并候选区块根据当前区块的位置来确定。例如,如果当前区块与一个下部的LCU相邻(也就是,如果第一候选区块属于一个下部的LCU),那么可以让所述第一候选区块改变成当前LCU中的一个区块或将其设置为不可用。
同样,第一候选区块和第二候选区块可以根据候选区块各自在运动向量存储单元中的位置而变成另一个区块。运动向量存储单元是一个存储参考图片的运动信息的基本单元。
图11是示出了根据本发明的存储运动信息的方法的概念图。如图11所示,运动存储单元可以是一个16x16的区块。这个运动向量存储单元可以被分割成十六个4x4的区块。如果所述运动向量存储单元是一个16x16区块,那么按每个运动向量存储单元存储运动信息。如果运动向量存储单元包括参考图片的多个预测单元,那么将所述多个预测单元的一个预定预测单元的运动信息存储在存储器中以减少要存储到存储器中的运动信息的量。所述预定预测单元可以是覆盖这十六个4x4区块其中之一的一个区块。所述预定预测单元可以是覆盖区块C3、区块BR的一个区块。或者所述预定预测单元可以是覆盖区块UL的一个区块。
因此,如果候选区块不包括所述预定区块,那么将这个候选区块变成包括所述预定区块的区块。
如果所述时间合并候选区块已被确定,那么将所述时间合并候选区块的运动向量设置为时间合并候选区块的运动向量。
构建合并候选区块列表(S230)。以预定次序列出可用的空间候选区块和可用的时间候选区块。空间合并候选区块按照A、B、C、D和E的次序列出了四个。时间合并候选区块可以列在B与C之间或者列在空间候选区块的后面。
确定是否生成一个或多个合并候选区块(S240)。确定操作的执行方法是,将列在合并候选区块列表中的合并候选区块的数量与合并候选区块的预定数量进行比较。这个预定数量可以按每图片或每切片来加以确定。
如果列在合并候选区块列表中的合并候选区块的数量小于合并候选区块的预定数量,那么生成一个或多个合并候选区块(S250)。将所生成的合并候选区块列在最后一个可用合并候选区块的后面。
如果可用合并候选区块的数量等于或大于2,那么两个可用合并候选区块中的一个具有列表0运动信息而另一个具有列表1运动信息,将列表0运动信息与列表1运动信息组合可以生成合并候选区块。如果存在多种组合,那么可以生成多个合并候选区块。
可以在列表中添加一个或多个零合并候选区块。如果切片类型是P,那么零合并候选区块只具有列表0运动信息。如果切片类型是B,那么零合并候选区块具有列表0运动信息与列表1运动信息。
在合并区块列表的合并候选区块中选择一个合并预测区块,并对用于指定这个合并预测区块的合并索引进行编码(S260)。
图12是根据本发明的图像解码装置200的方框图。
根据本发明的图像解码装置200包括熵解码单元210、反扫描单元220、反量化单元230、反变换单元240、帧内预测单元250、帧间预测单元260、后处理单元270、图片存储单元280以及加法器290。
熵解码单元210利用上下文自适应二进制算术解码方法从一个接收到的比特流提取帧内预测信息、帧间预测信息以及量化系数分量。
反扫描单元220对量化系数分量应用反扫描模式以生成量化后的区块。在帧间预测中,反扫描模式是对角线扫描。量化系数分量包括有效标记、系数正负号以及系数级。
当变换单元的大小大于预定大小时,利用对角线扫描按子集单位对有效标记、系数正负号以及系数级执行反扫描以生成子集,并且利用对角线扫描对这些子集进行反扫描以生成量化后的区块。所述预定大小等于子集大小。子集是包括16个变换系数的4x4区块。对有效标记、系数正负号以及系数级的反扫描按反方向进行。这些子集的反扫描也按反方向进行。
从所述比特流提取表示最后一个非零系数位置的参数以及非零子集标记。根据指示了最后一个非零系数位置的这个参数来确定经编码的子集的数量。利用所述非零子集标记来确定对应的子集是否具有至少一个非零系数。如果所述非零子集标记等于1,那么利用对角线扫描产生该子集。利用反扫描模式生成第一子集和最后子集。
反量化单元230从熵解码单元210接收差值量化参数并且产生量化参数预测值以生成编码单元的量化参数。产生量化参数预测值的操作与图1的量化单元150的操作相同。接着,将所述差值量化参数与量化参数预测值相加生成当前编码单元的量化参数。如果没有从编码侧传输当前编码单元的差值量化参数,那么将差值量化参数设置为零。
反量化单元230对量化后的区块执行反量化。
反变换单元240对反量化后的区块执行反变换以生成残余区块。反变换矩阵根据预测模式以及变换单元的大小以自适应方式加以确定。所述反变换矩阵是基于DCT的整数型变换矩阵或者是基于DST的整数型变换矩阵。在帧间预测中,利用基于DCT的整数型变换。
帧内预测单元250利用接收到的帧内预测信息导出当前预测单元的帧内预测模式,并根据所导出的帧内预测模式生成预测区块。
帧间预测单元260利用接收到的帧间预测信息导出当前预测单元的运动信息,并利用所述运动信息生成预测区块。
后处理单元270的操作与图1的后处理单元180的相同。
图片存储单元280从后处理单元270接收后处理后的图像并将图像存储到图片单元中。图片可以是帧或场(field)。
加法器290将经过恢复的残余区块与预测区块相加以生成重建的区块。
图13是示出了根据本发明的以帧间预测模式对图像解码的方法的流程图。
导出当前区块的运动信息(S310)。当前区块是预测单元。当前区块的大小由编码单元的大小和分割模式加以确定。
运动信息随预测类型而变。如果预测类型是单向预测,那么运动信息包括用于指定参考列表0的图片的参考索引和一个运动向量。如果预测类型是双向预测,那么运动信息包括用来指定参考列表0的图片的参考索引、用来指定参考列表1的图片的参考索引,以及列表0运动向量和列表1运动向量。
根据运动信息的编码模式以自适应方式解码所述运动信息。运动信息的编码模式通过跳跃标记(skip flag)和合并标记来确定。如果跳跃标记等于1,那么合并标记不存在,编码模式是跳跃模式。如果跳跃标记等于0,合并标记等于1,那么编码模式是合并模式。如果跳跃标记和合并标记都等于0,那么编码模式是AMVP模式。
利用这些运动信息生成当前区块的预测区块(S320)。
如果运动向量指示整数型像素位置,那么拷贝运动向量所指定的参考图片的区块来生成预测区块。如果运动向量指示子像素位置,那么对参考图片的像素执行内插来生成预测区块。运动向量采用的是四分之一像素单位。
如图3中所示,标记为L0、R0、R1、L1、A0和B0的像素是参考图片的整数型位置像素,子像素位置处标记为aL0到rL0的像素是要通过内插滤波器来内插的小数像素,内插滤波器基于运动向量来选择。
如果要执行内插的像素位于子像素位置aL0、bL0或cL0处,那么通过对水平方向上最接近的整数型位置像素应用内插滤波器来生成标记为aL0、bL0或cL0的像素。如果要执行内插的像素位于子像素位置dL0、hL0或nL0处,那么通过对垂直方向上最接近的整数型位置像素应用内插滤波器来生成标记为dL0、hL0或nL0的像素。如果要执行内插的像素位于子像素位置eL0、iL0或pL0处,那么通过对垂直方向上最接近的内插所得的像素(其中每一个的标记中包括字符“a”)应用内插滤波器来生成标记为eL0、iL0或pL0的像素。如果要执行内插的像素位于子像素位置gL0、kL0或rL0处,那么通过对垂直方向上最接近的内插所得的像素(其中每一个的标记中包括字符“c”)应用内插滤波器来生成标记为gL0、kL0或rL0的像素。如果要执行内插的像素位于子像素位置fL0、jL0或qL0处,那么通过对垂直方向上相邻的内插所得的像素中(其中每一个的标记中包括字符“c”)应用内插滤波器来生成标记为fL0、jL0或qL0的像素。
根据要执行内插的像素的子像素位置确定内插滤波器,也可以根据预测模式与要执行内插的像素的子像素位置来确定。
如表1所示,在单向预测中,可以使用6-抽头对称滤波器来内插半像素位置H的像素,可以使用5抽头不对称抽头滤波器来内插四分之一像素位置FL或FR的像素。在双向预测中,半像素位置H可以使用8抽头对称滤波器,四分之一像素位置FL和FR可以使用8抽头不对称滤波器。
或者,可以完全由要执行内插的像素的子像素位置来确定滤波器。在单向预测中,可以使用8抽头对称滤波器来内插半像素位置的像素,可以使用7抽头不对称滤波器或6抽头不对称滤波器来内插四分之一像素位置的像素。在双向预测中,可以使用抽头数量更少的相同或不同滤波器来内插子像素位置的像素。
生成残余区块(S330)。所述残余区块由图12的熵解码单元210、反扫描单元220、反量化单元230以及反变换单元240生成。
利用预测区块和残余区块生成重建的区块(S340)。
预测区块的大小与预测单元相同,残余区块的大小与变换单元相同。因此,相同大小的残余信号与预测信号相加生成了重建的信号。
图14是示出了以合并模式导出运动信息的方法的流程图。
从比特流提取合并索引(S410)。如果所述合并索引不存在,那么将合并候选区块的数量设置为1。
导出空间合并候选区块(S420)。可用的空间合并候选区块与图4的S210所述相同。
导出时间合并候选区块(S430)。时间合并候选区块包括该时间合并候选区块的参考图片索引以及运动向量。该时间合并候选区块的参考索引以及运动向量与图4的S220所述的相同。
构建合并候选区块列表(S440)。所述合并列表与图4的S230所述相同。
确定是否产生了一个或多个合并候选区块(S450)。确定操作的执行方法是,将列在合并候选区块列表中的合并候选区块的数量与合并候选区块的预定数量进行比较。该预定数量可以按每图片或每切片来加以确定。
如果列在合并候选区块列表中的合并候选区块的数量小于合并候选区块的预定数量,那么生成一个或多个合并候选区块(S460)。将所生成的合并候选区块列在最后的可用合并候选区块后面。生成所述合并候选区块的方法与图4的S250所述相同。
将合并索引所指定的合并候选区块设置为当前区块的运动信息(S470)。
图15是示出了根据本发明的以帧间预测模式生成残余区块的过程的流程图。
由熵解码单元生成量化系数分量(S510)。
根据对角线扫描对量化系数分量执行反扫描来生成一个量化后的区块(S520)。量化系数分量包括有效标记、系数正负号以及系数级。
当变换单元的大小大于预定大小时,利用对角线扫描按子集单位对有效标记、系数正负号以及系数级执行反扫描以生成子集,并且利用对角线扫描对这些子集进行反扫描以生成量化后的区块。所述预定大小等于子集大小。子集是含有16个变换系数的4x4区块。对有效标记、系数正负号以及系数级的反扫描按反方向进行。这些子集的反扫描也按反方向进行。
从所述比特流提取表示最后一个非零系数位置的参数以及非零子集标记。根据指示了最后一个非零系数位置的参数来确定经编码的子集的数量。利用所述非零子集标记来确定该子集是否具有至少一个非零系数。如果所述非零子集标记等于1,那么利用对角线扫描生成该子集。利用反扫描模式生成第一子集和最后子集。
利用反量化矩阵以及量化参数对所述量化后的区块执行反量化(S530)。
确定量化单元大小的最小值。从一个比特流中提取指示该最小值的参数cu_qp_delta_enabled_info,并且用以下等式来确定所述量化单元的该最小值。
Log2(MinQUSize)=Log2(MaxCUSize)–cu_qp_delta_enabled_info
MinQUSize表示所述量化单元大小的最小值,MaxCUSize表示LCU的大小。参数cu_qp_delta_enabled_info是从一个图片参数集提取的。
导出当前编码单元的差值量化参数。所述差值量化参数被包括在每个量化单元中。因此,如果当前编码单元的大小等于或大于量化单元大小的最小值,那么当前编码单元的差值量化参数被恢复。如果所述差值量化参数不存在,那么将所述差值量化参数设置为零。如果有多个编码单元属于一个量化单元,那么含有按解码次序的至少一个非零系数的第一编码单元包含该差值量化单元。
对经编码的差值量化参数执行算术解码以生成指示差值量化参数的绝对值的二进制位串,以及一个指示差值量化参数的正负号的二进制位。该二进制位串可以是截断一元码。如果差值量化参数的绝对值是零,那么所述表示正负号的二进制位不存在。利用所述指示绝对值的二进制位串以及所述指示正负号的二进制位来导出所述差值量化参数。
导出当前编码单元的量化参数预测值。量化参数预测值是利用相邻编码单元的量化参数以及先前编码单元的量化参数生成的,如下所述。
依次获取左量化参数、上量化参数以及先前的量化参数。当有两个或两个以上的量化参数可用时,将以此次序获取的前两个可用的量化参数的平均值设置为量化参数预测值;当仅有一个量化参数可用时,将这个可用的量化参数设置为量化参数预测值。也就是,如果左量化参数和上量化参数可用,那么将左量化参数和上量化参数的平均值设置为量化参数预测值。如果左量化参数与上量化参数中只有一个可用,那么将这个可用的量化参数与先前的量化参数的平均值设置为所述量化参数预测值。如果左量化参数和上量化参数均不可用,那么将先前的量化参数设置为所述量化参数预测值。
如果有多个编码单元属于一个最小的量化单元,那么导出按解码次序的第一编码单元的量化参数预测值并将其用于其他编码单元。
利用所述差值量化参数与量化参数预测值生成当前编码单元的量化参数。
通过对反量化后的区块执行反变换来生成残余区块(S540)。使用的是基于一维水平和垂直的反DCT的变换。
尽管已经参考特定的示范性实施例显示和描述了本发明,但是本领域技术人员应了解,可以在不脱离由随附权利要求书所界定的本发明精神与范围的情况下,进行各种形式和细节的变化。
- 还没有人留言评论。精彩留言会获得点赞!