一种无线通讯系统用户优先级的判别方法及装置与流程
本发明涉及通信领域,特别涉及一种无线通讯系统用户优先级的判别方法及装置。
背景技术:
随着移动通信技术的发展,移动通信业务种类越来越多,对通讯资源的需求也迅速增长,然而当前可用的无线通讯资源有限,在多用户多业务的条件下如何合理调配资源,提高无线资源的利用效率,是目前移动通信领域研究的热点和难点,而在无线资源调度过程中的一个关键问题就是确定用户优先级。
用户优先级别的确定是一个多目标求解的问题,需要同时综合考虑用户使用资源的公平性、无线资源使用效率、系统吞吐量、服务质量等多个目标的约束。目前对用户优先级的判别方法,或只考虑技术上的需求,或只考虑业务上的需求,没有全面考虑用户优先级别的影响因素,导致用户优先级的确定具有片面性。
技术实现要素:
本发明提供了一种无线通讯系统用户优先级的判别方法及装置,其目的是为了解决动态资源分配过程中用户优先级别判别的问题。
为了达到上述目的,本发明的实施例提供了一种无线通讯系统用户优先级的判别方法,包括:
获取无线通讯系统数据库中影响用户优先级的多个指标数据,构成第一级指标数据集;
对所述第一级指标数据集中的多个所述指标数据进行分析处理,构成第二级指标数据集;
根据所述第二级指标数据集,判别用户的优先级别。
其中,所述影响用户优先级的多个指标数据包括:信道质量指示、用户最大传输速率、用户历史平均传输速率、用户丢包率、用户时延、用户要求的传输速率、服务质量参数标识、系统可分配资源总量、系统历史平均吞吐量、用户计费总额、用户当前业务类型、用户当前时刻所需的资源量和/或当前业务完成进度。
其中,所述对所述第一级指标数据集中的多个所述指标数据进行分析处理,构成第二级指标数据集的具体步骤:
对所述第一级指标数据集中的多个所述指标数据进行归一化处理,使多个所述指标数据保持统一量纲;
计算所述第一指标数据集中进行归一化处理后的每一指标数据与用户优先级的相关关系显著性水平,提取与用户优先级的相关关系显著性水平小于预设数值的指标数据,建立第一初步筛选指标数据集;
对所述第一初步筛选指标数据集中的多个指标数据进行因子分析,筛除多个指标数据之间达到预定条件、除第一指标数据外的其他指标数据,建立第二初步筛选指标数据集;
对所述第二初步筛选指标数据集中的多个指标数据进行离散化处理,得到所述第二级指示数据集。
其中,所述对所述第一级指标数据集中的多个所述指标数据进行归一化处理,得到第一指标数据集的具体步骤包括:
通过公式
其中,v′ij为进行归一化处理后的指标数据,vij为需处理的第i指标数据,
其中,所述根据所述第二级指标数据集,判别用户的优先级别的具体步骤:
根据所述第二级指标数据集,将用户优先级别按优先级由高到低进行分类;
估算出每类用户优先级别出现的概率;
根据所述每类用户优先级别出现的概率判断出用户的优先级别。
其中,所述估算出每类用户优先级别出现的概率的具体步骤包括:
通过公式
其中,p(upi)为用户优先级别出现的概率;p(x)为给定事件x的概率;p(upi|x)为优先级别为upi的条件下给定事件x的概率。
其中,所述根据所述每类用户优先级别出现的概率判断出用户的优先级别的步骤为:
根据所述每类用户优先级别出现的概率,选择概率值最大的为用户的优先级别。
本发明的实施例还提供了一种无线通讯系统用户优先级的判别装置,包括:
获取模块,用于获取无线通讯系统数据库中影响用户优先级的多个指标数据,构成第一级指标数据集;
分析处理模块,用于对所述第一级指标数据集中的多个所述指标数据进行分析处理,构成第二级指标数据集;
分析判别模块,用于根据所述第二级指标数据集,判别用户的优先级别。
其中,所述分析处理模块包括:
第一处理模块,用于对所述第一级指标数据集中的多个所述指标数据进行归一化处理,使多个所述指标数据保持统一量纲;
第一计算模块,用于计算所述第一指标数据集中进行归一化处理后的每一指标数据与用户优先级的相关关系显著性水平,提取与用户优先级的相关关系显著性水平小于预设数值的指标数据,建立第一初步筛选指标数据集;
分析模块,用于对所述第一初步筛选指标数据集中的多个指标数据进行因子分析,筛除多个指标数据之间达到预定条件、除第一指标数据外的其他指标数据,建立第二初步筛选指标数据集;
第二处理模块,用于对所述第二初步筛选指标数据集中的多个指标数据进行离散化处理,得到所述第二级指示数据集。
其中,所述分析判别模块包括:
分类模块,用于根据所述第二级指标数据集,将用户优先级别按优先级由高到低进行分类;
估算模块,用于估算出每类用户优先级别出现的概率;
判定模块,用于根据所述每类用户优先级别出现的概率判断出用户的优先级别。
本发明的上述方案的有益效果如下:
本发明所提供的无线通讯系统用户优先级的判别方法及装置以海量移动通信领域数据为基础,以数据挖掘技术为手段,充分发挥海量数据的优势,综合考虑多方面的影响因素,合理确定用户优先级,以实现提高无线资源的使用效率和系统吞吐量的目的。
附图说明
图1为本发明所述方法的流程示意图;
图2为本发明所述方法的第二步骤的具体步骤的流程示意图;
图3为本发明所述方法的第三步骤的具体步骤的流程示意图;
图4为本发明所述装置的结构示意图。
具体实施方式
为使本发明要解决的技术问题、技术方案和优点更加清楚,下面将结合附图及具体实施例进行详细描述。
本发明针对现有的问题,提供了一种无线通讯系统用户优先级的判别方法及装置。
如图1所示,本发明的实施例提供了一种无线通讯系统用户优先级的判别方法,包括:
步骤1,获取无线通讯系统数据库中影响用户优先级的多个指标数据,构成第一级指标数据集;
步骤2,对所述第一级指标数据集中的多个所述指标数据进行分析处理,构成第二级指标数据集;
步骤3,根据所述第二级指标数据集,判别用户的优先级别。
本发明的上述实施例所述的方法首先从技术和业务两方面选择可能影响用户优先级的指标数据,确定后续工作的对象;然后对所述指标数据进行数据预处理,为后续工作提供完整、可靠的数据资源;最后利用朴素贝叶斯分类算 法实现用户优先级的判别,目的在于以海量移动通信领域数据为基础,以数据挖掘技术为手段,充分发挥海量数据的优势,综合考虑多方面的影响因素,合理确定用户优先级,以实现提高无线资源的使用效率和系统吞吐量的目的。
其中,所述影响用户优先级的多个指标数据包括:信道质量指示、用户最大传输速率、用户历史平均传输速率、用户丢包率、用户时延、用户要求的传输速率、服务质量参数标识、系统可分配资源总量、系统历史平均吞吐量、用户计费总额、用户当前业务类型、用户当前时刻所需的资源量和/或当前业务完成进度。
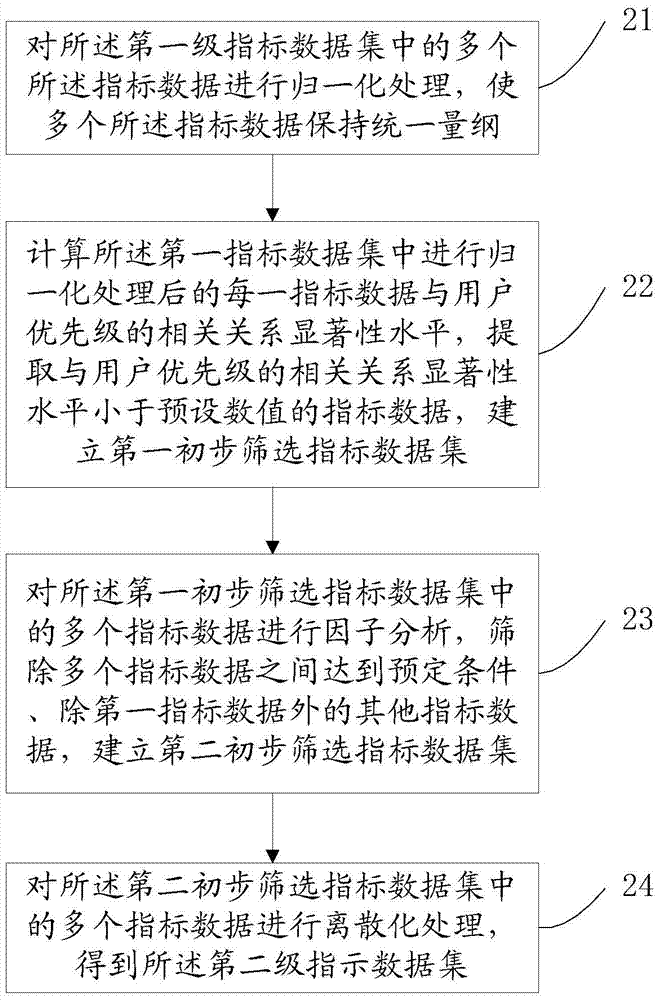
如图2所示,所述对所述第一级指标数据集中的多个所述指标数据进行分析处理,构成第二级指标数据集的具体步骤:
步骤21,对所述第一级指标数据集中的多个所述指标数据进行归一化处理,使多个所述指标数据保持统一量纲;
步骤22,计算所述第一指标数据集中进行归一化处理后的每一指标数据与用户优先级的相关关系显著性水平,提取与用户优先级的相关关系显著性水平小于预设数值的指标数据,建立第一初步筛选指标数据集;
步骤23,对所述第一初步筛选指标数据集中的多个指标数据进行因子分析,筛除多个指标数据之间达到预定条件、除第一指标数据外的其他指标数据,建立第二初步筛选指标数据集;
步骤24,对所述第二初步筛选指标数据集中的多个指标数据进行离散化处理,得到所述第二级指示数据集。
本发明的上述实施例所述的方法为后续工作提供完整、可靠的数据资源,该部分除了常规的数据处理,如数据清洗、装载、转换之外,还应包括数据规范化处理,将所有指标数据统一到相同的量纲;相关分析,挑选出与用户优先级具有显著相关关系的指标数据;线性降维,用更少的、互不相关的指标数据代替原来的多个指标数据;聚类分析,将降维后得到的因子的取值离散化处理得到第二级指示数据集。
其中,所述对所述第一级指标数据集中的多个所述指标数据进行归一化处理,得到第一指标数据集的具体步骤包括:
通过公式
其中,v′ij为进行归一化处理后的指标数据,vij为需处理的第i指标数据,
本发明的上述实施例所述方法的具体实施例为利用相关分析方法(如pearson相关分析)分析每一指标数据与用户优先级(用up表示)的相关关系,挑选出与up具有显著相关关系的指标数据,计算相关关系显著性水平,分别用pi表示(其中i=1,2,…,n);若pi<0.05,说明该指标与up之间具有显著的相关关系,则保留该指标数据;否则说明该指标与up之间没有显著的相关关系,删除该指标数据;设经相关分析之后保留下来的有m个指标(2≤m≤n,不考虑m≤1的情况),利用因子分析法可以得到k个新指标(1≤k<m),分别用表示f1,f2,…,fk表示;由于经线性降维处理后得到的fk为连续数据类型,为了减少后续的工作量,方便后续工作中进行情景组合以计算其历史概率,本发明利用k-均值聚类的方法分别将f1,f2,…,fk的取值进行离散化处理,得到f’1,f’2,…,f’k。
如图3所示,所述根据所述第二级指标数据集,判别用户的优先级别的具体步骤:
步骤31,根据所述第二级指标数据集,将用户优先级别按优先级由高到低进行分类;
步骤32,估算出每类用户优先级别出现的概率;
步骤33,根据所述每类用户优先级别出现的概率判断出用户的优先级别。
本发明的上述实施例所述的方法利用朴素贝叶斯分类算法实现用户优先级的判别,先进行用户优先级分类,将用户优先级分类排序;然后以海量数据为基础统计各优先级的先验概率及特定情境的概率;最后利用数据挖掘中的分类方法确定用户优先级类别,以实现提高无线资源的使用效率和系统吞吐量的目的。
其中,所述估算出每类用户优先级别出现的概率的具体步骤包括:
通过公式
其中,p(upi)为用户优先级别出现的概率;p(x)为给定事件x的概率;p(upi|x)为优先级别为upi的条件下给定事件x的概率。
其中,所述根据所述每类用户优先级别出现的概率判断出用户的优先级别的步骤为:根据所述每类用户优先级别出现的概率,选择概率值最大的为用户的优先级别。
本发明的上述实施例所述方法的具体实施例为首先将用户优先级别分成9类,一类为一个用户优先等级,且第一类优先级最高,第9类优先级最低,分别用up1,up2,…,up9表示;以上述得到的k个指标f’1,f’2,…,f’k作为分类属性,利用海量历史数据估计p(upi),p(x)和p(x|upi),其中i=1,2,…,9;p(upi)为先验概率,即出现优先级别为upi的概率;p(x)和p(x|upi)分别为给定事件x的概率以及在优先级别为upi的条件下给定事件x的概率;利用朴素贝叶斯算法计算用户所属的类,所对应类的顺序即为该用户可分配的优先级别;分别计算出优先级别为upi的概率p(upi|x),对于给定优先级别upi,若有p(upi|x)>p(upi|x)1≤j≤9,i≠j,则此时对应的upi即为用户所得到的优先级。
为使本发明的内容和步骤更加清晰明确,在此对以上各步骤进行详细举例说明:
选择无线通讯系统中可能影响用户优先级的指标,如表1所示。
以过去长期(如1年)的数据为基础,分别计算出每个指标的均值和标准 差,再进行规范化处理。如信道质量指示cqi的均值为4.5,标准差为5.0,第j条数据的cqi值为2,则规范化结果为
同理可以对每一条数据的每个指标属性进行规范化处理。
以规范化处理后的数据作为输入,利用pearson相关分析可以得到各指标与用户优先级up的相关关系显著性水平,如表2所示。
由以上相关分析结果可知,信道质量指示cqi(v1)、用户最大传输速率(v4)、用户历史平均传输速率(v5)、业务类型(v6)和用户计费总额(v9)这5个因素对于的p值均小于0.05,说明这些指标与up具有显著的相关关系。
以上述5个指标的数据作为输入,利用因子分析法对这5个指标进行因子分析,根据因子的累积方差贡献率超过85%可以抽取出3互不相关的因子(f1,f2,f3)替代原来的5个指标:
在降维的基础上利用k-均值聚类的方法将f1,f2,f3的取值进行离散化处理。如:
以上述3个因子f1,f2,f3作为分类属性,利用朴素贝叶斯分类方法对判别用户所属的优先级(类别),即求出p(upi|x)最大时对应的upi,而求p(upi|x)最大值即求p(x|upi)*p(upi)的最大值,因此,需要求出p(x|upi)和p(upi)的值。根据大量历史数据可以估算得到p(upi),如
p(up1)=0.042,p(up2)=0.089,p(up3)=0.120,
p(up4)=0.186,p(up5)=0.125,p(up6)=0.076,
p(up7)=0.142,p(up8)=0.104,p(up9)=0.112;
然后计算出在给定用户优先级为upi时出现事件x(如f1=1,f2=1,f3=2)时p(x|upi)的概率,如
p((f1=1,f2=1,f3=2)|up1)=0.056
p((f1=1,f2=1,f3=2)|up2)=0.047
p((f1=1,f2=1,f3=2)|up3)=0.850
p((f1=1,f2=1,f3=2)|up4)=0.001
p((f1=1,f2=1,f3=2)|up5)=0.010
p((f1=1,f2=1,f3=2)|up6)=0.026
p((f1=1,f2=1,f3=2)|up7)=0.036
p((f1=1,f2=1,f3=2)|up8)=0.406
p((f1=1,f2=1,f3=2)|up9)=0.056
进一步,计算出p(x|upi)*p(upi)的值,
p((f1=1,f2=1,f3=2)|up1)*p(up1)=0.003
p((f1=1,f2=1,f3=2)|up2)*p(up2)=0.004
p((f1=1,f2=1,f3=2)|up3)*p(up3)=0.102
p((f1=1,f2=1,f3=2)|up4)*p(up4)=0.001
p((f1=1,f2=1,f3=2)|up5)*p(up5)=0.001
p((f1=1,f2=1,f3=2)|up6)*p(up6)=0.002
p((f1=1,f2=1,f3=2)|up7)*p(up7)=0.005
p((f1=1,f2=1,f3=2)|up8)*p(up8)=0.042
p((f1=1,f2=1,f3=2)|up9)*p(up9)=0.006
可以看出,当用户级别up为3时,p(x|upi)*p(upi)的值最大,因此,该用户的优先级别为3。
如图4所示,本发明的实施例还提供了一种无线通讯系统用户优先级的判别装置,包括:获取模块,用于获取无线通讯系统数据库中影响用户优先级的多个指标数据,构成第一级指标数据集;分析处理模块,用于对所述第一级指标数据集中的多个所述指标数据进行分析处理,构成第二级指标数据集;分析判别模块,用于根据所述第二级指标数据集,判别用户的优先级别。
本发明所提供的无线通讯系统用户优先级的判别方法及装置以海量移动通信领域数据为基础,以数据挖掘技术为手段,充分发挥海量数据的优势,综合考虑多方面的影响因素,合理确定用户优先级,以实现提高无线资源的使用效率和系统吞吐量的目的。
其中,所述分析处理模块包括:第一处理模块,用于对所述第一级指标数据集中的多个所述指标数据进行归一化处理,使多个所述指标数据保持统一量纲;第一计算模块,用于计算所述第一指标数据集中进行归一化处理后的每一指标数据与用户优先级的相关关系显著性水平,提取与用户优先级的相关关系显著性水平小于预设数值的指标数据,建立第一初步筛选指标数据集;分析模块,用于对所述第一初步筛选指标数据集中的多个指标数据进行因子分析,筛除多个指标数据之间达到预定条件、除第一指标数据外的其他指标数据,建立第二初步筛选指标数据集;第二处理模块,用于对所述第二初步筛选指标数据集中的多个指标数据进行离散化处理,得到所述第二级指示数据集。
其中,所述分析判别模块包括:分类模块,用于根据所述第二级指标数据集,将用户优先级别按优先级由高到低进行分类;估算模块,用于估算出每类用户优先级别出现的概率;判定模块,用于根据所述每类用户优先级别出现的概率判断出用户的优先级别。
本发明的上述实施例所述的装置包括在后台服务器,包括了历史数据库、 数据仓库、数据挖掘算法库以及专用挖掘库等,历史数据库广泛收集用户业务信息、无线资源动态分配信息以及其他信息;利用数据集成整理模块从历史数据库抽取出有效的数据存于数据仓库;进一步,经过相关分析、因子分析、聚类分析等步骤,将数据仓库中的数据转换为可以直接用于后续用户优先级判别的数据并存于专用挖掘库中;专用挖掘库同时存储了直接从历史数据中统计出来的知识,如各种无线资源分配情景的先验概率等;而数据挖掘算法库则存储了已实现的算法工具,以供各功能模块调用。
在基站侧,主要包括用户优先级判别模块和动态资源分配模块。其中用户优先级判别模块以来自用户设备的用户实时需求信息和来自专用挖掘库中的历史统计信息作为输入,以朴素贝叶斯算法作为处理方法,经计算可输出用户优先级;而动态资源分配模块则可根据用户优先级判别结果对动态资源进行实时分配调度,从而实现了无线通讯系统中动态资源的有效分配,提高系统吞吐量和无线资源使用效率。
以上所述是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明所述原理的前提下,还可以作出若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!