声场的辅助增大的制作方法
本申请要求于2014年7月3日提交的美国临时专利申请No.62/020,702的优先权权益,其通过全文引用被结合于此。
技术领域
本发明涉及音频声场处理领域,并且更具体而言涉及利用多个其它空间分离的音频馈送对声场的增大。
背景技术:
贯穿整个说明书中对背景技术的任何讨论都不应当以任何方式被认为是承认这种技术广泛已知或构成本领域众所周知常识的一部分。
长期以来一直使用多个麦克风来捕获声场景。虽然它们常常被认为是独立的音频流,但是还存在利用多个麦克风捕获声场的概念。特别地,声场捕获通常是目地在于各向同性地捕获声场景的麦克风布置。
常常在捕获音频环境时也可以捕获多个辅助音频流(例如,佩戴式麦克风、桌面麦克风、其它安装的麦克风等)。这些辅助源常常被认为是分开的。
遗憾的是,声场捕获设置的特殊性质本身不适用于附属辅助麦克风源的简单集成而同时管理这种声场的貌似真实和感知上连续的后续体验。具有用于将辅助麦克风集成到声场捕获中的方法将是有利的。
技术实现要素:
根据本发明的第一方面,提供了一种用于更改在音频环境的多声道声场表示中的感兴趣音频信号的方法,该方法包括以下步骤:(a)从声场表示提取主要由感兴趣信号组成的第一分量;(b)确定残差声场信号;(c)输入与该感兴趣信号相关联的另一相关联的音频信号;(d)将相关联的音频信号变换为与残差声场兼容的对应的相关联的声场信号;及(e)将残差声场信号与相关联的声场信号组合以产生输出声场信号。
在一些实施例中,该方法还包括在组合步骤(e)之前相对于相关联的声场信号延迟残差声场信号的步骤。在一些实施例中,步骤(a)还优选地可以包括通过利用使感兴趣信号中感知到的残差声场存在最小化的自适应滤波器来隔离感兴趣信号中的任何残差声场信号的分量。
在一些实施例中,步骤(b)还优选地可以包括利用使残差声场信号中感知到的感兴趣信号存在最小化的自适应滤波器来隔离残差声场中感兴趣信号的分量。在一些实施例中,步骤(d)还可以包括对相关联的音频信号应用空间变换。感兴趣信号的音频成分可以与相关联的音频信号基本相同。步骤(d)还可以包括对相关联的音频信号应用增益或均衡。
音频环境的多声道声场表示可以从外部环境获取,并且相关联的音频信号可以从外部环境基本上同时获取。声场可以包括一阶水平B格式表示。
在一些实施例中,步骤(a)可以包括从声场表示中的预定角度提取感兴趣信号,并且步骤(d)还可以包括平移相关联的音频信号使得其可以被感知为从新的角度到达。
根据本发明的另一方面,提供了一种用于更改在多声道声场表示中的感兴趣音频信号的音频处理系统,该系统包括:第一输入单元,用于接收音频环境的多声道声场表示;音频提取单元,用于从多声道声场表示中提取感兴趣信号并提供残差声场信号;第二输入单元,用于接收至少一个相关联的音频信号以结合到多声道声场表示中;变换单元,用于将相关联的音频信号变换为对应的相关联的声场信号;组合单元,用于组合相关联的声场信号与残差声场信号以产生输出声场信号。
该系统还可以包括延迟单元,用于在由组合单元组合之前相对于相关联的声场信号延迟残差声场信号。
在一些实施例中,系统包括用于隔离残差声场信号中的任何感兴趣信号的自适应滤波器。变换单元还可以包括用于旋转相关联的声场信号的相关联的音频信号旋转单元。在一些实施例中,系统还可以包括用于向相关联的音频信号添加增益或均衡的增益单元。
附图说明
参考附图,现在将仅作为例子描述本发明的实施例,其中:
图1示意性地示出了示例声场记录环境;
图2示出了用于声场处理的初始布置;
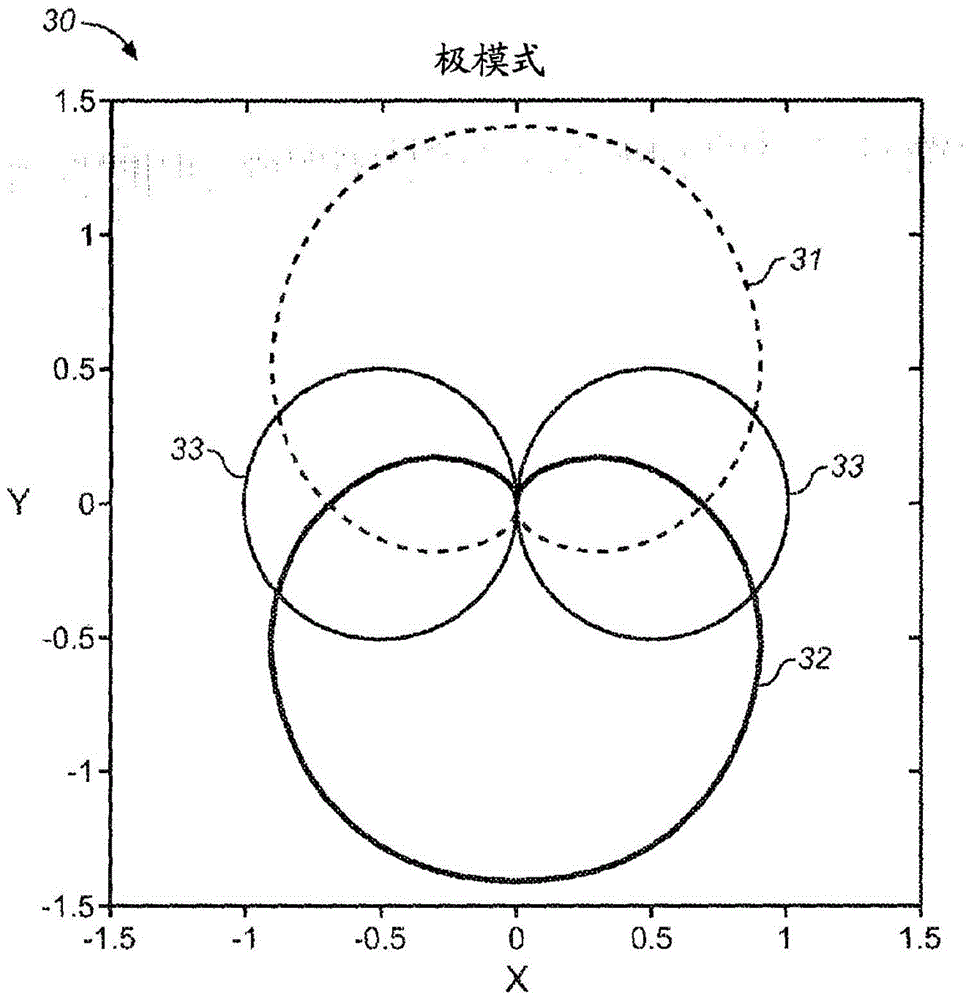
图3示出了主分量和残差分量的极(polar)响应的图;
图4示出了用于声场处理的替代布置;
图5示出了用于声场处理的另一替代布置;及
图6示出了在图5布置的一个实施例中使用的主波束和残差波束的示例方向性模式。
具体实施方式
本发明的实施例处理多声道声场处理。在这种处理中,声场利用麦克风阵列捕获,并且被记录或电信系统存储、发送或以其它方式使用。在这种系统中,将辅助麦克风源集成到来自演示者的佩戴式麦克风、来自房间中的卫星麦克风或来自足球场上的附加点麦克风的声场中将常常是有用的。辅助信号的集成可以提供改善的清晰度并且将某些对象和事件包括到目标声场所期望的单个音频场景中。实施例提供用于在最低程度地影响来自其它源的声音并适当地保持所捕获的环境的声学特性和存在的同时结合这些和其它相关联的音频流的装置。因此,实施例提供了将辅助麦克风集成到声场中的声场处理系统。
在这种系统中,能够操纵声场以移动特定声源(通常是人类说话者)常常是有用的。作为替代,隔离来自特定讲话者的语音并用另一信号(例如,来自同一讲话者的佩戴式麦克风馈送)来替换它可能是有用的。说明性例子提供了用于在最低程度地影响来自其它源的声音并适当地保持所捕获的房间的声学特性和存在的同时执行这些和其它相关联的任务的装置。
实施例使用波束成形类型做法来从声场隔离从特定角度或角度范围入射的感兴趣信号,以产生那个信号被部分或全部去除的残差声场,添加或处理音频以创建相关的感兴趣信号,然后利用适当的优先延迟将相关的感兴趣信号与残差重新组合以产生输出声场。与现有技术的重要区别在于,实施例给出去除和操纵足够量的信号以便创建期望的感知效果的方法的程度,而没有否则的话一般会引入不自然的失真的过多处理。与关于(本领域技术人员已知的)盲源分离和独立分量分析的工作相反,实施例利用信号变换、自适应滤波和/或感知引导的信号重组的平衡来实现合适的貌似合理的声场。
令人惊奇地发现,在这种处理中避免非预期或不自然的失真比实现一定程度的数字或完全信号分离具有更高的优先级。以这种方式,本发明与集中于改进的信号分离的目标的许多现有技术无关。
图1示意性地示出了实施例的操作上下文。在这个例子中,声场麦克风2捕获声场格式信号并将其转发到多声道声场处理器3。声场信号由已经变换为各向同性正交紧凑声场格式S的麦克风阵列输入组成。来自麦克风A1至An(4,5)的一系列辅助麦克风信号也被转发到多声道声场处理器,用于集成到声场S中,以创建用于与S具有相同格式的输出6的修改的声场S′。
本发明的目标是分解声场S,使得辅助麦克风A1至An可以被混入S中,以形成结合辅助麦克风的特性的修改的声场,同时保持原始声场S的感知完整性。同时还有一个目标是确保与可能已经在原始声场S中的与A1或An相关的信号分量被适当地管理,以避免造成冲突或不期望的感知线索。
现在转向图2,示出了多声道声场处理器3的一种形式,其包括用于处理输入音频流的多个子单元。阶段或子单元包括声场信号分解10、混合引擎11、主分量处理12、残差处理13和重建14。
1.信号分解10
信号分解单元10通过确定主分量M和残差分量R来确定对声场S的适当分解。M描述声场中的感兴趣信号,诸如主要讲话者,而R包含残差声场,其可以包含房间的混响特性或背景讲话者。这些分量的提取可以由任何合适的处理组成,包括线性波束成形、自适应波束成形和/或频谱相减。用于信号提取的许多技术是本领域技术人员众所周知的。主提取器的示例目标是提取与期望对象相关并从一窄角度范围入射的所有声音。主分量M被转发到混合引擎11,其中残差R进入残差处理单元13。
2.混合引擎11
主分量M和每个辅助分量An在混合引擎中被组合,其目标是确定何时混合以及如何将信号混合在一起。一直混合具有增大系统的固有噪声的负面影响,因而能够确定混合信号的适当时间的智能系统是必要的。此外,An应当被混合的比例要求对声场的特性的感知理解。例如,如果声场S高度混响,而辅助麦克风An较少混响,则在与R重新组合时用辅助麦克风An代替主分量M将听起来感觉上不协调。混合引擎11确定何时混合这些信号,以及如何将它们混合在一起。它们是如何混合的涉及考虑电平和表观本底噪声以最大化声场的感知协调性。
3.主分量处理12
然后,来自混合引擎11的结果M′被馈送到应用均衡、混响抑制或其它信号处理的附加主处理单元12中。
4.残差分量处理13
残差分量R还可以以在感知上增强M的方式被进一步处理,并且仍然保留完整声场的感知完整性。常常期望从R中去除尽可能多的感兴趣信号,并且这可以通过使用广义旁瓣消除器和残差波瓣消除器来辅助。例如,参见信号选择和阻塞的技术,如在IEEE Transactions on Signal Processing,第47卷,第10期2677-2684页Hoshuyama,O.;Sugiyama.A.;Hirano.A.的开创性著作“A robust adaptive beam former for microphone arrays with a blocking matrix using constrained adaptive filters”中所阐述的。
此外,为了改善主分量M的感知,可以结合各种心理声学效应以进一步感知上抑制残差的感知影响。一种这样的效应是表示为“优先延迟”的Hass效应(Haas,H.“The Influence of a Single Echo on the Audibility of Speech”,JAES第20卷,第2期146-159页;1972年3月)。
当相同的声音信号从两个不同的方向被重放到收听者并且其中一个源具有短的延迟时,Haas表明首先在耳朵处接收到的源支配收听者感知的到达方向。具体而言,Haas教导,即使延迟1-30ms范围内的短时间的播放相同内容的源B比A响10dB,源A也将被感知为具有主导入射角。优先延迟延迟声场的残差分量。这确保主分量在残差分量之前被呈现给收听者,其目标是收听者凭借优先效应感知主信号为来自期望的位置。优先延迟可以被集成到信号分解(10)中。可以引入优先延迟,以延迟(13)中的残差处理来创建R′。更广泛地说,应当管理信号处理路径中延迟的管理,使得M″的引入和渲染的版本在输出声场S′中基本发生在残差路径R′中所发生的任何关联或相关信号之前(1-30ms)。
虽然残差分量可能以与S相同的格式表示,但是残差声场分量可以可选地被构造为包含比输入声场更少的信息(因为感兴趣信号已经被去除或抑制)。对残差分量使用不同表示的一个动机是,当它具有比S更少的声道时,将优先延迟应用于R可能更低成本。
5.重建14
一旦确定了M″和R′,就可以重建修改的声场。声场的重建可以包括其它附加操作,诸如主分量M″的平移或声场的旋转。
具体实施例
在本发明的一个实施例中,用于S的格式是一阶水平B格式声场信号(W,X,Y),并产生修改的信号(W′,X′,Y′)作为输出。
该实施例目的在于将一个或多个辅助麦克风An集成到声场S中,其中An相对于S以角度定位,并且An的方向性模式是心形。
1.信号分解10
声场信号S=[W X Y]T可以以各种方式被分解成主分量M和残差分量,包括正交线性矩阵或一组自适应滤波器(例如,广义旁瓣消除器)。在这个实施例中,可以使用正交线性矩阵:
其中
其中是辅助麦克风An相对于S的位置角度。这产生了多个分量,如图3中所示,在的方向具有心形方向性模式的主分量M 31,2个残差分量R1 32(离M心形180度)和R2 33(在的方向具有空指向的8字模式图)。
在其中角度相对于S是固定的最简单情况下,很容易确定,但如果不是这种情况,则可以利用对象的统计建模在实时系统中在线计算在一个实施例中:
作为替代,可以采用角度的圆形平均值:
其中θ是声场景中音频对象的角度,并且p是其在辅助麦克风An处的瞬时SNR大于在S处的瞬时SNR的所有音频对象的集合。
在这种系统中,推断和估计的部件可以操作,以便监视在设备的一些最近历史中已经观察到的声音对象的活动和近似角度。来自传感器阵列的源的到达方向的识别在本领域中是众所周知的。对象和/或目标跟踪的统计学推断和维护也是众所周知的。作为这种分析的一部分,活动的历史信息可被用来推断对给定对象的角度估计。
在多个对象的集合可被认为与辅助或提取的信号更相关联的情况下,可以选择到该组对象的某个中心或平均角度作为混合信号M′的合适的感知渲染位置。上面的表达式被解释为采取与对象意在被放到目标声场S′中何处相关的一组角度的某个加权平均值的意图。通常情况下,这种与对象相关的角度是从初始声场S中对象角度的估计导出的,其中这种估计是利用声场S的历史信息和统计性推断来获得的。
以上操作对每个辅助输入或音频源重复。
2.混合引擎11
混合引擎11努力实现两个功能:确定何时在辅助麦克风中混合;以及确定如何将辅助麦克风混到声场中。
2.a.辅助麦克风选择
知道何时混入An对于确保辅助麦克风不会对声场增加过多噪声是重要的。因此,选择何时将它们添加到声场S对于最小化系统的噪声是关键的。
选择开启辅助麦克风An可以通过比较An的瞬时SNR与S的瞬时SNR来确定。瞬时SNR被定义为在特定时刻麦克风的语音水平对噪声本底水平。如果瞬时SNR表示为I,则当时我们选择An,其中α被允许依赖在r>tr时看到的观察数量而波动,并且其中tr是选择性的阈值。参数α随着观察的增加而减小,由此对An的选择性准则增加滞后。
2.b.辅助麦克风混合
一旦An已被选择要混合到S中,它应当被混入的比例就可以再次由瞬时SNR I控制。在一个实施例中,可以迫使r更慢地衰减(利用一阶平滑滤波器),以模拟房间的混响尾部,然后混合函数可以由下式给出
M′=f(b)An+(1-f(b))M
其中b是混合参数,f(b)是混合函数(例如,线性、对数)。混合函数还将限制最小和最大允许的混合,以保持声场的感知协调性。混合函数f(b)被用来控制交替信号M和An之间的混合过渡的特性。一般要求是.f(b)具有[0..1]的域并且范围是单调的。在一个实施例中有用的这种函数的简单例子是f(b)=0.9*b。
对于这种函数,应当指出,优选的辅助输入An的滤波后的感测,b,被映射到从0(消除)至接近1的增益范围,同时信号M以不小于-20dB的增益被混合。在一些实施例中,用于声场中原始信号分量的残差量对于连续性是有用的。
更一般而言,信号M′可以由一对混合函数构造
M′=f(b)An+g(b)M
因为可能期望控制用于两个信号An和M的最大和最小增益及映射函数。
替代实施例还可以利用标准噪声抑制方法将An和M预处理成被适当地调平并具有匹配的噪声基底。这将有助于最大化混合信号之间的感知协调。
3.主分量处理12
主分量M′可被进一步处理,以实现音频的期望的修改或增强。有许多本领域技术人员已知的可应用于音频信号的修改的技术,尤其是对于感兴趣对象是语音或类似语音的信号的应用。在这个阶段的信号处理的具体例子可以包括但不限于:均衡,其中应用依赖频率的滤波来校正或赋予某种音色,以增强或补偿距离或其它声学效果;动态范围压缩,其中应用时变增益来在一个或多个频带上改变信号的电平和/或动态范围;信号增强,诸如语音增强,其中时变滤波器被用来增强期望信号的可理解度和/或突出方面;噪声抑制,其中信号的分量,诸如稳定噪声,通过频谱相减来识别和抑制;混响抑制,其中信号的时间包络可以被校正,以减少期望信号包络的混响散布和扩散的影响;以及活动检测,其中一组滤波器、特征提取和或分类被用来检测感兴趣信号的活动的阈值或连续水平,并更改一个或多个信号处理参数。对于指示性例子,参考标准文本,诸如:Speech Enhancement:Theory And Practice,Philipos C.Loizou的[精装]第二版。
4.残差分量处理13
在信号分解(10)之后,可选的一组自适应滤波器可被用来最小化存在于主分量中的残差信号的量。在一个实施例中,可以使用脉冲响应长度为2至20ms的常规规格化最小均方(NLMS)自适应有限脉冲响应(FIR)滤波器。这种滤波器适于表征主波束与残差波束之间的声学路径,包括房间混响,由此最小化在主信号中也被听到的残差信号的感知量。类似的自适应滤波器可被用来最小化残差分量中主信号的量。
为了利用所谓的Haas效应或优先,向残差分量添加一些延迟是有用的。这种延迟可以被表示为优先延迟。这种延迟可以在系统中影响残差分量但不影响主分量的任何地方添加。这确保在输出声场中呈现给收听者的任何声音的第一次开始来自主分量的方向,并且最大化收听者感知来自预期方向的声音的可能性。
5.重建14
然后,声场的重建涉及主分量和残差分量在它们相关联的处理之后的重组。重建遵循分解的逆,使得
其中D-1是D的逆。
由于主分量和残差分量被合理地分离,因此可选处理可以包括将主分量平移旋转到声场中的不同位置。优先延迟和其它残差处理的添加确保主分量的定位在感知上被最大化。
替代实施例
在替代布置中,如果系统输入是从麦克风阵列捕获的,则它在被呈现给系统进行处理之前必须首先变换成格式S。类似地,输出声场可能需要从格式S变换到另一表示以便通过耳机或扬声器重放。
表示为R的残差分量表示在内部被使用。格式R可以与格式S完全相同或者可以包含更少信息-特别地,R可以具有比S更大或更小数量的声道,并且确定性地但不一定是线性地从S导出。
这个实施例从输入声场中提取感兴趣信号(表示为M)或主信号,并且产生其中感兴趣信号被感知为已被移动、更改或替换的输出声场,但是其中声场的剩余部分被认为是未修改的。
图4示出了多声道声场处理器(图1的3)的替代布置40。在这个布置中,声场输入信号41以格式S被输入,作为从声场源(例如,声场麦克风阵列)导出的信号。主信号提取器42从传入的声场提取感兴趣信号(M)。主信号处理器43利用感兴趣信号(M)和一个或多个辅助信号中的一个或两者作为输入来产生相关联的信号(MA)。辅助信号输入、一个或多个辅助信号(例如,点麦克风信号)在这里被注入。空间修改器45作用于相关联的信号(MA),以将其变换为具有空间修改特性的格式S的声场信号。
关于主信号,主信号抑制器46用于抑制传入声场中的感兴趣信号(M),从而产生格式R的残差分量。优先处理单元47用于相对于信号MA延迟残差分量。残差变换器48将延迟的残差分量变换回声场格式S。然后,混合器49将修改的相关联声场与残差声场组合,以产生输出50,它是格式S的声场输出信号。
对输入声场(41)执行的第一处理步骤是提取感兴趣信号(42)。提取可以包括任何合适的处理,包括线性波束成形、自适应波束成形和/或频谱相减。主提取器的目标是提取与期望对象相关并从一窄角度范围入射的所有声音。
同样是对输入声场操作,主信号抑制器(46)意在产生声场的残差分量表示,其以最大可能的程度描述去除了感兴趣信号的声场的剩余部分。虽然残差分量有可能类似于输入声场以格式S表示,但是残差声场分量可以可选地被构造为包含比输入声场少的信息(因为感兴趣信号已经被去除或抑制)。对残差分量使用不同表示的一个动机是,当其具有比格式S更少的声道时,可以需要更少的处理对格式R应用延迟(47)。
主提取器和抑制器可以以如图4中的虚线连接51、52部分示出的各种拓扑被配置。示例拓扑包括:主抑制器使用感兴趣信号(M)51作为参考输入。主抑制器使用相关联的信号(MA)52作为参考输入。主提取器使用残差分量作为参考输入。主抑制器和提取器是相互关联的并且共享彼此的状态。
不管主提取器相对于主抑制器的拓扑如何,对于这些部件来说共享状态和共用处理元件都会是有用的。例如,当主提取器和主抑制器都执行线性波束成形作为其处理的一部分时,线性波束成形可被合并成单个操作。在下面描述的优选实施例中给出了其例子。
主信号处理器(43)负责基于感兴趣信号和/或辅助输入产生相关联的信号(MA)。由主信号处理器执行的可能功能的例子包括:用合适的处理后的辅助信号代替结果声场中的感兴趣信号,对感兴趣信号应用增益和或均衡,组合经适当处理的感兴趣信号和经适当处理的辅助信号。
空间修改器(45)产生相关联的信号的声场表示。举例来说,可以采用目标入射角,相关联的信号应当感知地从该目标入射角出现以到达输出声场。这种参数将是有用的,例如,在试图将输入声场中从某个角度入射的所有声音作为感兴趣信号隔离并且使其看起来转而从新角度出现的实施例中是有用的。下面描述这种实施例。给出这个例而不失一般性,因为该结构可被用来移动(shift)所捕获的声场中感兴趣信号的其它感知属性,诸如距离、方位角和仰角、扩散率、宽度和运动(多普勒频移)。
当相同的声音信号从两个不同的方向向收听者重放并且其中一个源具有短延迟时,Haas表明在耳朵处首先被接收的源支配收听者感知的到达方向。具体而言,Haas教导,即使延迟1-30ms范围内的短时间的播放相同内容的源B比A响10dB,源A也将被感知为具有主导入射角。优先延迟单元(47)延迟声场的残差分量。这确保相关联的声场在残差声场之前被呈现给收听者,其目标是收听者凭借优先效应将相关联的信号感知为来自由空间修改器(45)确定的新角度或位置。优先延迟(47)也可以被集成到主抑制器(46)中。应当指出,对照Haas参考文献,具有被感知修改的属性的插入的经处理或组合的感兴趣信号的比率在其第一到达点被实现或控制为高于在残差路径中不被抑制的与感兴趣信号相关的任何残差信号成分(例如,在所捕获空间中的后期混响)6-10dB。这个约束一般而言是可实现的,尤其是在如优选实施例中所阐述的修改感兴趣信号的角度的情况下。
由于残差声场分量是以格式R表示的,因此可能需要变换部件(48)将格式R变换回格式S,以供输出。如果在特定实施例中选择格式R和S完全相同,则可以省略变换部件。应当清楚的是,在不失一般性的情况下,任何变换、下混或上混处理可以先于或跟随,如在某些应用中为实现所有可用麦克风和输出声道的兼容性和合适使用所需的。一般而言,系统将利用如在处理时可用的那样多的信息并因此输入麦克风声道。照此,可以提供封装该布置的中央框架但具有不同输入和输出格式的变体。
声场混合器(49)将残差和相关联的声场组合在一起,以产生最终的输出声场(50)。
声源重定位系统的一种形式在图5中示为55并且使用一阶水平B格式声场信号(W,X,Y)56作为格式S并产生修改后的信号(W′,X′,Y′)57作为输出。虽然该系统被设计为处理B格式信号,但是应当理解,它不限于此并且将扩展到空间波场的其它一阶水平各向同性基础表示,即,受波动方程和空气对声波在典型声强度下的线性响应约束的在所捕获的点周围的体积中表示的压力随空间和时间的变化。另外,这种表示可被扩展到更高阶,并且在一阶中,B格式、模态和泰勒级数展开的表示是线性等效的。
该实施例目的在于隔离从角度θ58入射的所有声音并产生其中那个声音看起来似乎来自角度γ60的输出声场。该系统目的在于使从所有其它角度入射的声音保持不变。在所呈现的声场具有多于两个维度的情况下,角度θ和γ应当用合适的多维朝向表示方法来代替,诸如欧拉角(方位角、高度等等)或四元数。
布置55包括:波束成形/阻塞矩阵61,其将输入声场线性分解为主波束M和残差R1、R2;广义旁瓣消除器(GSC)62,其自适应地从主波束去除残差混响;优先延迟单元63,其确保来自新方向γ的直达声音在来自方向θ的任何残差之前被听到;残差波束消除器(RLC)64,其自适应地从残差波束去除主混响;逆矩阵65,其将残差变换回原始声场基底;增益/均衡器66,其补偿由GSC和RLC引起的总能量的损失;平移器67,其以新角度γ将主波束平移到声场中;以及混合器68,其将平移的主波束与残差声场组合。
图5的布置中的第一部件是波束成形/阻塞矩阵B 61。这个方框应用正交线性矩阵变换,使得主波束M是从指向θ58的声场提取的。变换还产生多个残差信号R1...RN,这些信号与M正交以及相互正交(回想B是正交的)。这些残差信号对应于格式R。格式R可以具有比格式S更少的声道。
在实施例55中,输入声场(W,X,Y)通过下式被变换为(M,R1,R2):
在这个方程中,α描述主波束的方向性模式。例如,在时,主波束将具有心形极化响应。在α=1时,主波束将具有偶极(8字图)响应。
在这个优选实施例中使用的矩阵B的公式要求两个残差波束具有方向性模式β(具有与α相同的含义)并且从主波束偏移角度图6示出了用于该实施例的主波束模式和残差波束模式的一个例子。给定B正交的约束,即,BBT=I,求解β和给出以下封闭解。
返回图5,在波束成形/阻塞矩阵之后,可选的一组自适应滤波器(62)可被用来最小化在主信号中存在的残差信号的量。可以使用脉冲响应长度为2至20ms的常规规格化最小均方(NLMS)自适应有限脉冲响应(FIR)滤波器。这种滤波器适于表征主波束和残差波束之间的声学路径,包括房间混响,由此最小化在主信号中也听到的残差信号的感知量。
为了在本发明中使用所谓的Haas效应或优先效应,向残差信号添加某个延迟63是有用的。这种延迟可以在系统中影响残差声场但不影响主波束的任何地方添加。这确保在输出声场中呈现给收听者的任何声音的第一次开始经由平移器67来自方向γ,并且最大化收听者感知原本来自方向θ而不是来自方向γ的声音的可能性。
布置55还包括自适应滤波器64,其被设计为最小化残差中存在的主信号的量。具有脉冲响应长度2至20ms的NLMS自适应FIR滤波器是这种滤波器的良好选择。通过选择在20ms以下的脉冲响应长度,其效果是基本上除去存在于包含方向性信息的残差中的主信号的任何早期回波。这种技术可以表示为残差波瓣消除(RLC)。如果RLC滤波器成功地去除所有方向性回波,则仅剩余后期混响。这种后期混响应当在很大程度上是全向的并且如果主信号实际上源自方向γ则将是类似的。因此,结果得到的声场保持有用。
在图5中,优先延迟63在RLC 64之前示出。这具有在波阵面通过残差声道在主声道之前到达时鼓励RLC中更好的数值性能的优点,这对于某些麦克风阵列、源几何形状和源频率成分可以是可能的。但是,这种放置有效地减少了RLC滤波器的有用长度。因此,优先延迟也可以被放在RLC滤波器之后或者被分成两条延迟线,RLC之前的短延迟和之后的较长延迟。
在处理之后,残差信号必须通过应用反向波束成形/阻塞矩阵B-1被变换回原始声场基底65。回想B需要是正交的,这意味着B-1=BT。这种变换是通过下面的方程针对图5的声场基底描述的,其中显然可以省略BT的第一列,以避免一些与零相乘。
由于单元61相互从残差R去除主信号M并从主信号去除残差,因此这可能已经从声场中去除了净能量。因此包括增益均衡方框66,以补偿这种损失的能量。
在处理之后,主信号必须经由平移器67被变换回原始声场基底,使得看起来从新方向γ到达。平移器对基底信号实现以下变换:
产生输出声场的最后一步是由于主信号和残差信号而重组声场分量。混合器68根据以下方程执行这种操作。
因此,布置55按以下方式实现图4的声场修改:GSC滤波器(62)和波束成形/阻塞矩阵(61)一起实现图4的主提取器(42)。RLC滤波器(64)和波束成形/阻塞矩阵(61)一起实现图4的主抑制器(46)。在这种布置中,出于效率的原因,波束成形/阻塞矩阵在主提取器和主抑制器之间共享。EQ/增益方框(66)实现图4的主处理器(43)。平移器(67)实现图4的空间修改器(45)。优先延迟(63)实现图4的延迟(47)。逆矩阵(65)实现图4的残差变换器(48)。混合器(68)实现图4的混合器(49)。
因此图5的布置提供了阻塞矩阵的具体参数化、设计和同一性关系,以便以水平B格式操作;残差波瓣消除器(RLC)的具体目的和构造;RLC和GSC的组合网络和稳定化;使用由Haas原理指导的延迟来强调感兴趣信号的修改的空间属性,同时在声场中保持与感兴趣信号相关的的残差(例如,一些结构性声学反射和混响);EQ、增益和空间滤波或渲染的使用,以创建具有与从原始声场被抑制的感兴趣信号不同的感知属性的修改的感兴趣信号;使用与感兴趣信号相关的辅助信号以实现期望效果的选项,尤其是将附近的麦克风带入貌似合理的声场中;根据需要将以上想法的具体应用和现有技术的整合,以便为电话会议应用实现声场修改的结果。
说明
贯穿本说明书对“一个实施例”、“一些实施例”或“实施例”的引用意味着结合实施例描述的特定特征、结构或特性包括在本发明的至少一个实施例中。因此,短语“在一个实施例中”、“在一些实施例中”或“在实施例中”贯穿本说明书在各个地方的出现不一定全部指代相同的实施例,而是可以指代同一实施例。此外,在一个或多个实施例中,特定特征、结构或特性可以以任何合适的方式组合,如根据本公开内容对本领域普通技术人员将清楚的。
如本文所使用的,除非另有说明,否则用于描述公共对象的序数形容词“第一”、“第二”、“第三”等的使用仅仅指示正在被参考的相似对象的不同实例,而不意在暗示如此描述的对象必须在时间上、空间上、排名上或以任何其它方式处于给定的序列。
在下面的权利要求和本文的描述中,“包括”、“由...组成”当中任何一个术语都是开放术语,意味着包括至少随后的元素/特征,但不排除其它元素/特征。因此,当在权利要求中使用时,术语“包括”不应当被解释为限制于其后面列出的装置或元件或步骤。例如,表述“包括A和B的设备”的范围不应当限于仅由元件A和B组成的设备。如本文所使用的,术语“包含”也是开放术语,也意味着包含至少该术语之后的元素/特征,但不排除其它元素/特征。因此,“包含”与“包括”同义。
如本文所使用的,术语“示例性”在提供例子的意义上使用的,与指示质量相反。即,“示例性实施例”是作为例子提供的实施例,而不一定是示例性质量的实施例。
应当明白,在本发明的示例性实施例的以上描述中,本发明的各种特征有时在单个实施例、图或其描述中被分组在一起,以简化本公开内容并有助于理解各个发明性方面中的一个或多个。但是,本公开内容的这种方法不应当被解释为反映所要求保护的发明需要比每个权利要求中明确记载的特征更多的特征的意图。相反,如以下权利要求所反映的,发明性方面在于少于单个前述公开的实施例的所有特征。因此,具体实施方式之后的权利要求被明确地结合到本具体实施方式中,其中每项权利要求自身作为本发明的单独实施例。
此外,虽然本文所述的一些实施例包括其它实施例中包括的一些但不包括其它特征,但是不同实施例的特征的组合意在本发明的范围内,并形成不同的实施例,如本领域技术人员将理解的。例如,在以下权利要求中,任何要求保护的实施例都可以以任何组合使用。
此外,本文中将一些实施例描述为可由计算机系统的处理器或者由执行该功能的其它装置实现的方法或方法的元素的组合。因此,具有用于执行这种方法或方法元素的必要指令的处理器构成用于执行所述方法或方法元素的装置。此外,本文描述的装置实施例的元件是用于为了执行本发明而执行由元件执行的功能的装置的例子。
在本文提供的描述中,阐述了众多具体细节。但是,应当理解,本发明的实施例可以在没有这些具体细节的情况下实践。在其它情况下,未详细示出众所周知的方法、结构和技术,以便不模糊对本描述的理解。
类似地,应当注意,当在权利要求中使用时,术语“耦合”不应当被解释为仅限于直接连接。可以使用术语“耦合”和“连接”以及它们的派生词。应当理解,这些术语不意在作为彼此的同义词。因此,表述“耦合到设备B的设备A”的范围不应当限于其中设备A的输出直接连接到设备B的输入的设备或系统。这意味着在A的输出和B的输入之间存在路径,该路径可以是包括其它设备或装置的路径。“耦合”可以指两个或更多个元件或者直接物理或者电接触,或者两个或更多个元件彼此不直接接触但是仍然彼此协作或交互。
因此,虽然已经描述了被认为是本发明优选实施例的实施例,但是本领域技术人员将认识到,在不背离本发明的精神的情况下可以对其进行其它和进一步的修改,并且意在要求所有这样的改变和修改都落入本发明的范围内。例如,上面给出的任何方程仅仅代表可被使用的过程。功能可以添加到框图或从框图中删除,并且操作可以在功能方框之间互换。可以向在本发明范围内描述的方法添加或删除步骤。
- 还没有人留言评论。精彩留言会获得点赞!