以太网无源光网络上行链路带宽分配方法和装置与流程
本发明涉及以太网无源光网络(ethernetpassiveopticalnetwork,epon)领域,尤其涉及以太网无源光网络上行链路动态带宽分配方法和装置,可以根据光网络单元(opticalnetworksunit,onu)的业务配置和流量需求,给onu进行带宽分配。
背景技术:
在epon系统中,一个光线路终端(opticallineterminal,olt)可以连接多个onu,在这种情况下,onu需要分时复用上行的带宽;在epon系统中,接收gate消息并反馈report消息的实体称为逻辑链路,逻辑链路可以用逻辑链接标志(logicallinkidentification,llid)来进行标识;llid是epon系统分配给逻辑链接的一种数字标识,每一个逻辑链接都会分配到不同的llid;在epon系统中,llid是由网管通过olt分配的.olt可以通过llid辨别帧是由哪个onu发来的。
epon系统中,数据包是不被分片的,如果带宽的尾部不足一个数据包,尾部的带宽将被浪费;如此,当onu的逻辑链路的上行流量低于olt可分配带宽的时候,逻辑链路的请求带宽小于可以分配的带宽,直接按照逻辑链路的请求带宽为逻辑链路分配带宽即可,这样可以保证带宽尾部不出现带宽浪费问题;当onu的逻辑链路的上行流量较大时,onu的逻辑链路的请求带宽可能超过olt允许分配的带宽,此时olt无法按照逻辑链路的请求带宽进行带宽分配,此时,olt只能按照自身的允许分配的带宽进行带宽分配,在采用此种带宽分配方案时,onu不能按照请求带宽上传数据包,onu实际上传的数据包的总流量通常小于所分配的带宽,会不可避免地造成带宽尾部的浪费问题;对于几 百兆带宽来说,尾部出现一定的浪费可以忽视,但是当业务带宽比较小的时候,出现尾部浪费,将会对用户的体验造成很大的影响;例如,如果用户本来仅仅购买了2m的带宽,由于帧尾带宽浪费的存在,实际用户可能只能享用70%左右的带宽。
技术实现要素:
为解决上述技术问题,本发明实施例期望提供一种以太网无源光网络上行链路动态带宽分配(dynamicbandwidthallocation,dba)方法和装置,能够使用户购买的带宽服务得到足额的保证。
本发明的技术方案是这样实现的:
本发明实施例提供了一种epon上行链路dba方法,所述方法包括:
在当前dba周期,按照预先设置的第一带宽分配策略,为每个逻辑链路分配授权带宽;
针对按照所述第一带宽分配策略分配的授权带宽大于0的逻辑链路,分配补偿带宽,所述补偿带宽为前一dba周期为对应逻辑链路分配的授权带宽减去前一dba周期通过对应逻辑链路实际上传的数据流量而得出的差值。
上述方案中,在分配补偿带宽之后,所述方法还包括:
对应逻辑链路还有剩余的允许分配的带宽时,按照预先设置的第二带宽分配策略,为对应逻辑链路分配授权带宽。
上述方案中,所述按照预先设置的第二带宽分配策略,为对应逻辑链路分配授权带宽,包括:
根据经过补偿带宽分配后对应逻辑链路剩余的允许分配的带宽的值、经过补偿带宽分配后还未满足请求带宽的所有逻辑链路的权重之和、以及预先设置的对应逻辑链路的权重,得出对应逻辑链路允许分配的授权带宽;基于所述对应逻辑链路允许分配的授权带宽,为对应逻辑链路分配授权带宽。
上述方案中,所述方法还包括:
在按照所述第一带宽分配策略为对应逻辑链路分配的授权带宽等于0,且 所述补偿带宽的值大于预先设置的补偿带宽分配阈值时,为对应逻辑链路分配补偿带宽。
上述方案中,所述按照预先设置的第一带宽分配策略,为每个逻辑链路分配授权带宽,包括:
在对应逻辑链路的请求带宽大于设定的带宽分配阈值时,为对应逻辑链路分配大小不超过带宽分配阈值的授权带宽;
在对应逻辑链路的请求带宽小于等于设定的带宽分配阈值时,按照对应逻辑链路的请求带宽为对应逻辑链路分配授权带宽。
本发明实施例还提供了一种epon动态带宽分配dba装置,所述装置包括第一分配模块和第二分配模块,其中,
第一分配模块,用于在当前dba周期,按照预先设置的第一带宽分配策略,为每个逻辑链路分配授权带宽;
第二分配模块,用于针对按照所述第一带宽分配策略分配的授权带宽大于0的逻辑链路,分配补偿带宽;所述补偿带宽为前一dba周期为对应逻辑链路分配的授权带宽减去前一dba周期通过对应逻辑链路实际上传的数据流量而得出的差值。
上述方案中,所述装置还包括第三分配模块;所述第三分配模块,用于在分配补偿带宽之后,在对应逻辑链路还有剩余的允许分配的带宽时,按照预先设置的第二带宽分配策略,为对应逻辑链路分配授权带宽。
上述方案中,,所述第三分配模块,具体用于根据经过补偿带宽分配后对应逻辑链路剩余的允许分配的带宽的值、经过补偿带宽分配后还未满足请求带宽的所有逻辑链路的权重之和、以及预先设置的对应逻辑链路的权重,得出对应逻辑链路允许分配的授权带宽;基于所述对应逻辑链路允许分配的授权带宽,为对应逻辑链路分配授权带宽。
上述方案中,,所述第二分配模块,还用于在按照所述第一带宽分配策略为对应逻辑链路分配的授权带宽等于0,且所述补偿带宽的值大于预先设置的补偿带宽分配阈值时,为对应逻辑链路分配补偿带宽。
上述方案中,所述第一分配模块,具体用于在对应逻辑链路的请求带宽大于设定的带宽分配阈值时,为对应逻辑链路分配大小不超过带宽分配阈值的授权带宽;在对应逻辑链路的请求带宽小于等于设定的带宽分配阈值时,按照对应逻辑链路的请求带宽为对应逻辑链路分配授权带宽。
本发明实施例提供了一种以太网无源光网络上行链路动态带宽分配方法和装置,在当前dba周期,按照预先设置的第一带宽分配策略,为每个逻辑链路分配授权带宽;针对按照所述第一带宽分配策略分配的授权带宽大于0的逻辑链路,分配补偿带宽,所述补偿带宽为前一dba周期为对应逻辑链路分配的授权带宽减去前一dba周期通过对应逻辑链路实际上传的数据流量而得出的差值;如此,通过在当前dba周期下发补偿带宽,使用户购买的带宽服务得到足额的保证。
附图说明
图1为本发明以太网无源光网络上行链路动态带宽分配方法的第一实施例的流程图;
图2为本发明以太网无源光网络上行链路动态带宽分配方法的第二实施例中每个动态带宽分配周期内进行的带宽分配流程的示意图;
图3为本发明以太网无源光网络上行链路动态带宽分配方法的第二实施例为任意一个逻辑链路进行保证带宽分配的流程图;
图4为本发明以太网无源光网络上行链路动态带宽分配方法的第二实施例中为任意一个逻辑链路进行补偿带宽分配的流程图;
图5为本发明以太网无源光网络上行链路动态带宽分配方法的第二实施例中为任意一个逻辑链路分配尽力而为带宽的流程图;
图6为本发明以太网无源光网络上行链路动态带宽分配方法的第三实施例中补偿带宽计算的流程图;
图7为本发明实施例epon上行链路dba装置的组成结构示意图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述。
对于现有技术存在的带宽尾部浪费的问题,本发明实施例可以根据每个逻辑链路的允许分配带宽和请求带宽,合理地为逻辑链路分配带宽,达到带宽资源的充分合理的利用;本发明实施例可以在在有限的带宽资源情况下,为用户提供更优质的服务,让用户购买的带宽体验得到保证。
这里,每个逻辑链路的允许分配带宽通常为该逻辑链路的已购买带宽,每个逻辑链路的允许分配带宽可以通过服务等级协议(service-levelagreement,sla)表配置信息获取。
第一实施例
在本发明第一实施例中,可以采用集中式的动态带宽分配策略,即,按照设定的周期进行带宽分配;设定的周期称为dba周期,在每个dba周期为各个逻辑链路进行上行流量的带宽分配,带宽分配结束后,待下一个dba周期到达时,再次进行对应dba周期的带宽分配。
这里,为各个逻辑链路进行带宽分配的过程可以在olt实现,在为每个逻辑链路分配带宽时,olt通过对应的逻辑链路将带宽的分配信息下发至对应的onu;如此,onu可以基于所获取的带宽的分配信息,将至少一个数据包通过对应的逻辑链路上传至olt。
图1为本发明以太网无源光网络上行链路动态带宽分配方法的第一实施例的流程图,如图1所示,该流程包括:
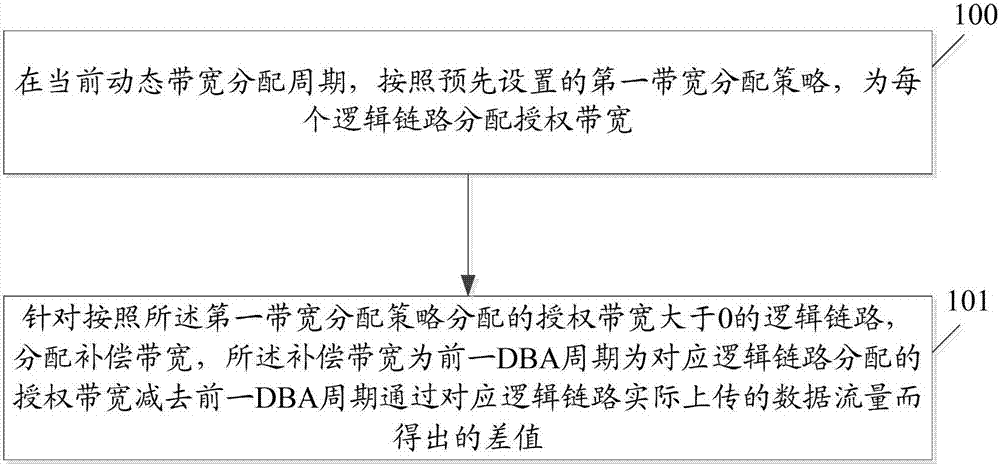
步骤100:在当前动态带宽分配周期,按照预先设置的第一带宽分配策略,为每个逻辑链路分配授权带宽;
本步骤中,为任意一个逻辑链路分配的授权带宽可以大于0,也可以等于0,显然,在为任意一个逻辑链路分配的授权带宽等于0时,可以不进行带宽的分配信息的下发。
具体地说,在对应逻辑链路的请求带宽大于设定的带宽分配阈值时,为对应逻辑链路分配大小不超过带宽分配阈值的授权带宽;在对应逻辑链路的请求带宽小于等于设定的带宽分配阈值时,按照对应逻辑链路的请求带宽为对应逻辑链路分配授权带宽。
步骤101:针对按照所述第一带宽分配策略分配的授权带宽大于0的逻辑链路,分配补偿带宽,所述补偿带宽为前一dba周期为对应逻辑链路分配的授权带宽减去前一dba周期通过对应逻辑链路实际上传的数据流量而得出的差值。
这里,前一动态带宽分配周期为对应逻辑链路分配的授权带宽为前一动态带宽分配周期为对应逻辑链路各次分配的授权带宽之和,这里,前一动态带宽分配周期为对应逻辑链路分配的授权带宽不包括前一动态带宽分配周期为对应逻辑链路分配的补偿带宽。
例如,前一动态带宽分配周期为对应逻辑链路只进行了授权带宽和补偿带宽的分配,则前一动态带宽分配周期为对应逻辑链路总共分配的带宽为前一动态带宽分配周期为对应逻辑链路分配的授权带宽;如果前一动态带宽分配周期为对应逻辑链路进行授权带宽和补偿带宽的分配之后,再次进行了授权带宽分配,则前一动态带宽分配周期为对应逻辑链路分配的授权带宽为前一动态带宽分配周期为对应逻辑链路两次分配的授权带宽之和。
可以看出,补偿带宽实际上表示了前一带宽周期内对应逻辑链路所浪费的尾部带宽;在现有技术中,由于存在所浪费的尾部带宽,用户购买的带宽服务没有得到足额的保证,而在本发明实施例中,通过在当前dba周期下发补偿带宽,使用户购买的带宽服务得到足额的保证,提高了用户体验。
需要说明的是,对于第一个动态带宽分配周期,可以不进行补偿带宽的分配,也就是说,在第一个动态带宽分配周期,按照预先设置的初始带宽分配策略,为每个逻辑链路分配带宽。
这里,对于如何设置初始带宽分配策略不进行限制,示例性地,初始带宽分配策略可以是:将大小为设定值的带宽分配至每个逻辑链路。
进一步地,在按照所述第一带宽分配策略为对应逻辑链路分配的授权带宽等于0,且所述补偿带宽的值大于预先设置的补偿带宽分配阈值时,为对应逻辑链路分配补偿带宽;在按照所述第一带宽分配策略为对应逻辑链路分配的授权带宽等于0,且所述补偿带宽的值小于等于预先设置的补偿带宽分配阈值时,不为对应逻辑链路分配补偿带宽,只为应逻辑链路分配授权带宽。
进一步地,在分配补偿带宽之后,对应逻辑链路还有剩余的允许分配的带宽时,按照预先设置的第二带宽分配策略,为对应逻辑链路分配授权带宽。
具体地,所述按照预先设置的第二带宽分配策略,为对应逻辑链路分配授权带宽,包括:根据经过补偿带宽分配后对应逻辑链路剩余的允许分配的带宽的值、经过补偿带宽分配后还未满足请求带宽的所有逻辑链路的权重之和、以及预先设置的对应逻辑链路的权重,得出对应逻辑链路允许分配的授权带宽;基于所述对应逻辑链路允许分配的授权带宽,为对应逻辑链路分配授权带宽。
在现有技术中,当onu的逻辑链路的上行流量较大时,onu的逻辑链路的请求带宽可能超过olt允许分配的带宽,此时olt无法按照逻辑链路的请求带宽进行带宽分配,此时,olt只能按照自身的允许分配的带宽进行带宽分配,在采用此种带宽分配方案时,onu不能按照请求带宽上传数据包,onu实际上传的数据包的总流量通常小于所分配的带宽,会不可避免地造成带宽尾部的浪费问题;对于几百兆带宽来说,尾部出现一定的浪费可以忽视,但是当业务带宽比较小的时候,出现尾部浪费,将会对用户的体验造成很大的影响;进一步地,上行逻辑链路的带宽利用率和onu的发包大小有很大关系,数据包越大,相应的带宽利用率越低,数据包越小,相应的带宽利用率会提高。
针对现有技术中存在的上述问题,本发明第一实施例通过在当前dba周期下发补偿带宽,使用户购买的带宽服务得到足额的保证,提高了用户体验。
第二实施例
为了能更加体现本发明的目的,在本发明第一实施例的基础上,进行进一步的举例说明。
在本发明第二实施例中,可以采用集中式的dba分配策略,即,按照设 定的周期进行带宽分配;设定的周期称为dba周期,在每个dba周期为各个逻辑链路进行上行流量的带宽分配,带宽分配结束后,待下一个dba周期到达时,再次进行对应dba周期的带宽分配。
这里,dba周期一般为几百微秒,在一个dba周期到达时,计算对应dba周期内为各个逻辑链路分配的带宽,在计算完毕后,可以根据多点控制协议(multipointmaccontrolprotocol,mpcp),将为每个逻辑链路分配的带宽通过gant_length信息搬运至gatempcp帧,之后,将gatempcp帧下发至与逻辑链路对应的onu;在所有的gatempcp帧下发完毕后,对应dba周期的带宽分配过程结束。
在本发明第二实施例中,每个dba周期内带宽分配过程可以包括依次进行的固定带宽分配步骤、保证带宽分配步骤、补偿带宽分配步骤及尽力而为带宽分配步骤;这里,每个带宽分配步骤都要轮询所有的逻辑链路,即,对于当前带宽分配步骤来说,只有在各个逻辑链路的带宽分配过程结束后,才执行下个带宽分配步骤。
在本发明第二实施例中,带宽的单位可以是m、g等单位,此时,带宽单位是站在用户使用层的角度的来设置的,在实际应用中,olt在配置硬件带宽的时候,需要把这个带宽折算成时间定量(timequanta,tq)单位,配置进sla表中。本发明第二实施例中,硬件带宽计算过程中可以按照tq单位计算带宽。
图2为本发明以太网无源光网络上行链路动态带宽分配方法的第二实施例中每个dba周期内进行的带宽分配流程的示意图,如图2所示,该流程包括:
步骤200:为各个逻辑链路进行固定带宽(fixedbandwidth)分配。
这里,固定带宽是不论有无流量需求都需要分配的带宽,固定带宽以牺牲带宽为代价,来换取快而稳定的响应时间。
本步骤中,可以预先设置为每个逻辑链路分配的固定带宽的大小,在为任意一个逻辑链路分配固定带宽时,可以在每个dba周期均进行一次固定带宽分配,也可以每隔fix_alloc_cycle个dba周期进行一次固定带宽的分配, fix_alloc_cycle为大于1的自然数。
在为任意一个逻辑链路分配固定带宽时,如果采用每隔fix_alloc_cycle个dba周期进行一次固定带宽的分配的方式,如果当前的dba周期不是可以分配固定带宽的周期,则不为对应逻辑链路进行固定带宽分配,如果当前的dba周期是可以分配固定带宽的周期,则为对应逻辑链路分配大小为fix_alloc_cycle*bw_f的固定带宽,bw_f为对应逻辑链路预先配置的第一带宽配置值,bw_f可以在sla表中进行配置。
这里,为了实现每隔fix_alloc_cycle个dba周期进行一次固定带宽的分配,可以设置计数器fix_bw_cnt,计数器fix_bw_cnt的初始计数值为0,在每个dba周期计数器fix_bw_cnt的计数值累加bw_f,当计数器fix_bw_cnt的计数值达到fix_alloc_cycle*bw_f时,为对应逻辑链路分配相应的固定带宽,并置计数器fix_bw_cnt的计数值为0。
步骤201:为各个逻辑链路进行保证带宽(assuredbandwidth)分配。
如图3所示,是本发明以太网无源光网络上行链路动态带宽分配方法的第二实施例为任意一个逻辑链路进行保证带宽分配的流程图;在为任意一个逻辑链路进行保证带宽分配时,将经过固定带宽分配后还未满足的对应逻辑链路的请求带宽的值记为req,将经过固定带宽分配后对应逻辑链路剩余的允许分配的带宽的值记为sleft,将对应逻辑链路预先配置的第二带宽配置值记为bw_a,bw_a可以在sla表中进行配置;设置对应逻辑链路的保证带宽漏桶为token_a,将为对应逻辑链路每次分配的保证带宽的最小阈值记为thre_min,将为对应逻辑链路每次分配的保证带宽的最大阈值记为thre_max,将当前dba周期为对应逻辑链路分配的保证带宽的值记为ass_pure。
这里,在当前dba周期为对应逻辑链路分配的固定带宽大于等于对应逻辑链路的请求带宽时,经过固定带宽分配后还未满足的对应逻辑链路的请求带宽为0,在当前dba周期为对应逻辑链路分配的固定带宽小于对应逻辑链路的请求带宽时,经过固定带宽分配后还未满足的对应逻辑链路的请求带宽req为当前dba周期对应逻辑链路的请求带宽减去对应逻辑链路分配的固定带宽的 差值;例如,当前dba周期为对应逻辑链路分配的固定带宽为a1,当前dba周期对应逻辑链路的请求带宽为a2,则经过固定带宽分配后还未满足的对应逻辑链路的请求带宽req为a2-a1。
token_a表示对应逻辑链路的保证带宽漏桶,token_a不能超过token_a_max,token_a_max=bw_a×num;token_a_max的大小与bw_a有关,例如,dba周期为750us时,如果bw_a为2m,则配置num=30;如果bw_a为200m,则配置num=10;token_a用来记录前一dba周期后允许分配的保证带宽,如果token_a超过token_a_max,说明最近对应逻辑链路的允许分配的保证带宽比较充足,此时,可以自动溢出,也就是说,在token_a超过限制token_a_max时,令token_a=token_a_max。
这里,设置最小阈值thre_min的目的在于防止保证带宽频繁分配造成开销浪费、以及带宽尾部浪费,这里,在每次分配保证带宽时,会造成的开销包括但不限于layer_on开销、layser_off开销、sync_time开销等;示例性地,bw_a=2m时,可以将thre_min设置为1518字节,使最大的数据包可以下发即可,在bw_a=200m时,可以设置较大的最小阈值thre_min,但不能超过thre_max。
这里,设置最大阈值thre_max,可以防止由于对应逻辑链路单次分配的保证带宽过大而出现当前dba周期其他逻辑链路的保证带宽无法分配的情况;举例来说,以dba周期750us为例,bw_a=2m时,可以设置最大阈值thre_max为1518*2字节;当bw_a=20m的时候,可以设置最大阈值thre_max=10*bw_a;当bw_a=200m时,可以设置最大阈值thre_max=3*bw_a。
参照图3,为任意一个逻辑链路进行保证带宽分配的流程包括:
步骤2011:判断req是否小于等于token_a,如果req小于等于token_a,则跳至步骤2012,否则,跳至2013。
这里,在req小于等于token_a时,说明req可以在保证带宽分配阶段得到满足,在req大于token_a时,说明req不能够在保证带宽分配阶段得到满足。
步骤2012:判断req是否大于thre_max,如果req大于thre_max,则ass_pure=thre_max,将大小为thre_max的保证带宽分配至对应的逻辑链路;如 果req小于等于thre_max,则ass_pure=req,将大小为req的保证带宽分配至对应的逻辑链路;在为对应逻辑链路分配保证带宽之后,跳至步骤2014。
本步骤中,在req大于thre_max时,为了防止由于对应逻辑链路单次分配的保证带宽过大而出现当前dba周期其他逻辑链路的保证带宽无法分配的情况,只能将大小为thre_max的保证带宽分配至对应的逻辑链路,而超过thre_max的请求带宽在当前dba周期暂时不予满足;在req小于等于thre_max时,说明req可以在保证带宽分配阶段得到满足。
步骤2013:判断token_a是否大于thre_max,如果token_a大于thre_max,则ass_pure=thre_max,将大小为thre_max的保证带宽分配至对应的逻辑链路;如果token_a不大于thre_max,则判断token_a是否大于等于thre_min,如果token_a大于等于thre_min,则ass_pure=token_a,将大小为token_a的保证带宽分配至对应的逻辑链路;如果token_a小于thre_min,则ass_pure=0,不为对应逻辑链路分配保证带宽;
之后,跳至步骤2014。
步骤2014:更新token_a。
这里,更新token_a的过程可以包括:将token_a加上bw_a后减去ass_pure,得出更新后的token_a。
进一步地,在步骤2014之后,还可以计算得出在经过固定带宽分配和保证带宽分配后为对应逻辑链路实际已经分配的带宽。
需要说明的是,在每个dba周期内带宽分配过程的四个带宽分配步骤中,固定带宽分配步骤具有最高的优先级,如果固定带宽和保证带宽要在一起进行分配,由于漏桶分配的猝发特性,可能导致固定带宽需要延迟几个dba周期才可以分配带宽,导致固定带宽无法稳定的得到响应;因而,虽然固定带宽分配步骤和保证带宽分配步骤都是必须进行的,但还是要分成两个步骤来依次执行。
可以看出,在进行保证带宽分配时,可以设置一个保证带宽漏桶token_a,每个周期漏桶进行累加。另外,保证带宽在新的report消息来的时候才分配,无 新的report过来或者从上次接收report消息开始的report_max_interval个周期未结束时,则不进行保证带宽分配,这样可以精确知道onu端新的带宽需求;当经过固定带宽分配后还未满足的对应逻辑链路的请求带宽小于等于token_a的时候,直接分配带宽满足req的需求;当经过固定带宽分配后还未满足的对应逻辑链路的请求带宽大于token_a的时候,此时无法知道onu端的buffer头部信息,会出现带宽尾部浪费的问题;此时,需要启动补偿带宽分配功能,进行带宽补偿工作;当检测到onu的带宽需求可以得到满足的时候,关闭带宽补偿工作。
这里,参照本发明第一实施例,按照第一带宽分配策略为每个逻辑链路分配的授权带宽包括依据步骤200为对应逻辑链路分配的固定带宽和依据步骤201为对应逻辑链路分配的保证带宽。
步骤202:为逻辑链路进行补偿带宽(compensationbandwidth)分配。
图4为本发明以太网无源光网络上行链路动态带宽分配方法的第二实施例中为任意一个逻辑链路进行补偿带宽分配的流程图,如图4所示,该流程包括:
步骤2021:判断在经过固定带宽分配和保证带宽分配后为对应逻辑链路实际已经分配的带宽是否大于0,如果是,则为对应的逻辑链路分配大小为bw_c的补偿带宽,如果否,则跳至步骤2022。
这里,根据本发明第一实施例,bw_c为前一动态带宽分配周期为对应逻辑链路总共分配的带宽减去前一动态分配周期通过对应逻辑链路实际上传的数据流量而得出的差值。
步骤2022:判断对应逻辑链路是否满足设定条件,如果满足,则为对应的逻辑链路分配大小为bw_c的补偿带宽,如果不满足,则跳至步骤2023。
这里,将对应逻辑链路预先配置的第三带宽配置值记为bw_b,所述设定条件为:对应逻辑链路预先配置的第一带宽配置值bw_f为0、对应逻辑链路预先配置的第二带宽配置值bw_a为0、对应逻辑链路预先配置的第三带宽配置值bw_b大于0、且bw_c大于thre_cm;thre_cm表示预先设置的补偿带宽分配阈值。
步骤2023:不为对应逻辑链路分配补偿带宽。
对于补偿带宽分配步骤,可以由补偿带宽计算装置先计算出bw_c;在当前dba周期,只有在固定带宽分配阶段或者保证带宽阶段已经分配的带宽大于0的时候,才会把补偿带宽分配下去,否则等待对应逻辑链路在某个dba周期出现固定带宽分配阶段或者保证带宽阶段已经分配的带宽大于0时,再分配补偿带宽;对于只含有满足设定条件的逻辑链路,由于尽力而为带宽分配步骤处于补偿带宽分配步骤之后,无法判断当前dba周期为对应逻辑链路总分配的带宽是否大于0,此时,需要设置一个补偿带宽分配阈值,只有当bw_c超过补偿带宽分配阈值时,才分配补偿带宽。
这里,在利用补偿带宽计算装置计算bw_c时,需要统计前一动态带宽分配周期为对应逻辑链路总共分配的带宽、以及前一动态分配周期通过对应逻辑链路实际上传的数据流量;前一动态带宽分配周期为对应逻辑链路总共分配的带宽可以是:olt接收的gate信息中的grant_length扣除以下带宽而得出的带宽:layser_on开销、layser_off开销、sync_time开销和补偿阶段得到的带宽。可以看出,利用补偿带宽计算装置计算出的bw_c为前一动态带宽分配周期带宽尾部浪费阶段浪费的带宽。
步骤203:为逻辑链路进行尽力而为带宽(besteffortbandwidth)分配,
如图5所示,是本发明以太网无源光网络上行链路动态带宽分配方法的第二实施例中为任意一个逻辑链路分配尽力而为带宽的流程图;在任意一个逻辑链路分配尽力而为带宽时,将经过补偿带宽分配后还未满足的对应逻辑链路的请求带宽的值记为req,将经过补偿带宽分配后对应逻辑链路剩余的允许分配的带宽的值记为sleft,将预先设置的对应逻辑链路的权重记为we,将经过补偿带宽分配后还未满足请求带宽的所有逻辑链路的权重之和记为total_we,设置对应逻辑链路的优先级权重漏桶为token_pw,设置对应逻辑链路的带宽限速漏桶为token_b,将对应逻辑链路每次分配的尽力而为的最小阈值记为thre_bmin,将对应逻辑链路每次分配的尽力而为带宽的最大阈值记为thre_bmax,将当前dba周期为对应逻辑链路分配的尽力而为带宽的值记为be_pure。
这里,在经过补偿带宽分配后为对应逻辑链路实际分配的带宽大于等于对应逻辑链路的请求带宽时,经过补偿带宽分配后还未满足的对应逻辑链路的请求带宽的值req为0,在经过补偿带宽分配后为对应逻辑链路实际分配的带宽小于对应逻辑链路的请求带宽时,经过补偿带宽分配后还未满足的对应逻辑链路的请求带宽的值req为对应逻辑链路的请求带宽减去经过补偿带宽分配后为对应逻辑链路实际分配的带宽的差值;例如,当前dba周期经过补偿带宽分配后为对应逻辑链路实际分配的带宽为a3,当前dba周期对应逻辑链路的请求带宽为a4,则经过补偿带宽分配后还未满足的对应逻辑链路的请求带宽的值req为a4-a3。
可以理解的是,在经过补偿带宽分配后,任意一个逻辑链路的请求带宽可能已经得到满足,也可能没有得到满足;在任意一个逻辑链路的请求带宽小于等于经过补偿带宽分配后为对应逻辑链路实际已经分配的带宽时,说明在经过补偿带宽分配后,任意一个逻辑链路的请求带宽可能已经得到满足;否则,说明在经过补偿带宽分配后,任意一个逻辑链路的请求带宽没有得到满足。
这里,可以为每个逻辑链路预先设置权重,则经过补偿带宽分配后请求带宽得到满足的各个逻辑链路的权重之和为total_we;在实际应用中,可以在sla表中设置各个逻辑链路的权重,可以按照每个逻辑链路的请求带宽来设置对应的权重,例如,逻辑链路的权重与逻辑链路的请求带宽的大小成正比。
token_pw表示对应逻辑链路的优先级权重漏桶,token_pw不能超过bw_b×num,token_pw的大小与对应逻辑链路预先配置的第三带宽配置值bw_b有关,token_pw用来记录前一dba周期后按照权重允许分配的尽力而为带宽扣除前期已经使用的带宽。如果token_pw超过bw_b×num,说明最近对应逻辑链路允许分配的尽力而为带宽比较充足,此时,可以自动溢出,也就是说,在token_pw超过bw_b×num时,令token_pw=bw_b×num;进一步地,在当前dba周期对应逻辑链路的优先级权重漏桶溢出时,在下个dba周期不为对应逻辑链路进行尽力而为带宽的分配。
token_b表示对应逻辑链路的带宽限速漏桶,token_b漏桶的最大数值大于 token_pw的最大数值,token_b用来起到限速漏桶的作用,保证为任意一个逻辑链路分配的尽力而为带宽不超过预先配置的第三带宽配置值bw_b。
这里,设置最小阈值thre_bmin的目的在于防止尽力而为带宽频繁分配,造成开销浪费、以及带宽尾部浪费,这里,在每次分配保证带宽时,会造成的开销包括但不限于layer_on开销、layser_off开销、sync_time开销;设置最大阈值thre_max,可以防止由于对应逻辑链路单次分配的尽力而为带宽过大而出现当前dba周期其他逻辑链路的尽力而为带宽无法分配的情况。
参照图5,为任意一个逻辑链路进行尽力而为带宽分配的流程包括:
步骤2031:获取对应逻辑链路允许分配的尽力而为带宽bw_pw。
具体地,根据经过补偿带宽分配后对应逻辑链路剩余的允许分配的带宽的值sleft、经过补偿带宽分配后还未满足请求带宽的所有逻辑链路的权重之和total_we、以及预先设置的对应逻辑链路的权重we,得出对应逻辑链路允许分配的尽力而为带宽bw_pw,bw_pw=(we/total_we)*sleft。
步骤2032:判断req是否小于等于token_pw,如果是,则跳至步骤2033,否则,跳至步骤2034。
这里,如果req小于等于token_pw,则说明req可以在尽力而为带宽分配阶段得到满足,如果req大于token_pw,则说明req不能够在尽力而为带宽分配阶段得到满足。
步骤2033:判断req是否大于thre_bmax,如果req大于thre_bmax,则be_pure=thre_bmax,将大小为thre_bmax的尽力而为带宽分配至对应的逻辑链路;如果req小于等于thre_bmax,则be_pure=req,将大小为req的尽力而为带宽分配至对应的逻辑链路,在为对应逻辑链路分配尽力而为带宽之后,跳至步骤2035。
这里,在req大于thre_bmax时,为了防止由于对应逻辑链路单次分配的尽力而为带宽过大而出现当前dba周期其他逻辑链路的尽力而为带宽无法分配的情况,只能满足大小为thre_bmax的带宽分配请求,超过thre_bmax的带宽分配请求在当前dba分配中暂时不予满足;如果req小于等于thre_bmax, 说明req可以在尽力而为带宽分配阶段得到满足。
步骤2034:判断token_pw是否大于thre_bmax,如果token_pw大于thre_bmax,则be_pure=thre_bmax,将大小为thre_bmax的尽力而为带宽分配至对应的逻辑链路;如果token_pw不大于thre_bmax,则判断token_pw是否大于等于thre_bmin,如果token_pw大于等于thre_bmin,则be_pure=token_pw,将大小为token_pw的尽力而为带宽分配至对应的逻辑链路;如果token_pw小于thre_bmin,则be_pure=0,不为对应逻辑链路分配尽力而为带宽。
之后,跳至步骤2035。
步骤2035:更新token_b和token_pw。
具体地,更新token_b和token_pw可以包括:将token_b加上bw_b后减去be_pure,得出更新后的token_b;之后,判断token_pw与bw_pw之和是否大于token_b,如果是,则将token_b作为更新后的token_pw;如果token_pw与bw_pw之和小于等于token_b,则将token_pw减去be_pure后加上bw_pw,得出更新后的token_pw。
进一步地,步骤2035还可以包括:得出经过固定带宽分配、保证带宽分配、补偿带宽分配和尽力而为带宽分配后为对应逻辑链路实际已经分配的带宽。
参照本发明第一实施例,按照第二带宽分配策略为每个逻辑链路分配的授权带宽为依据步骤200为对应逻辑链路分配的尽力而为带宽。
根据上述四个带宽分配步骤,可以看出,补偿带宽和尽力而为带宽并不是一定要为对应逻辑链路分配的带宽,只有对应逻辑链路满足相应的条件时,才能为对应逻辑链路分配补偿带宽和尽力而为带宽。
步骤204:判断下一个dba周期是否到达,如果没有到达,则继续等待,在下一个dba周期到达时,返回至步骤200,再次进行相应的动态动态分配。
在步骤204前,还可以得出每个逻辑链路的对应的未来上行时隙,之后,根据未来burst的预期到达时间exp_up_burst_time算出gate帧的发送时刻start_time,start_time=exp_up_burst_time-rtt,rtt为往返延时;之后,按照gate帧的发送时刻start_time生成对应逻辑链路的gate帧;在得出所有逻辑链路 的gate帧后,执行步骤204。
进一步地,在本发明第二实施例中,为了避免epon分配的带宽尾部不足一个完整的数据包导致的带宽浪费的问题,在一个dba周期开始进行带宽分配时,务必获取onubuffer头部的准确信息。onubuffer头部的准确信息主要指的是onu待上传的前若干个数据包需要的grant_length。因此,当olt通过逻辑链路收到新的report消息时,才会进行当前dba周期的带宽分配,否则不进行当前dba周期的带宽分配。
同时,当report消息出现异常丢弃的情况时,为了保证带宽可以继续分配,需要设置一个分配间隔report_max_interval,如果在截止到当前dba周期的report_max_interval个dba周期内有接收到新的report消息,则进行当前dba周期的带宽分配,否则等待从上次接收report消息开始的report_max_interval个dba周期结束后,再对相应的dba周期进行带宽分配。这样,这样,尽量避免了epon分配的带宽尾部不足一个完整的数据包导致的带宽浪费的问题,同时提高了动态带宽分配的可靠性。这里,report_max_interval不需要设置很大,只要能判断出report消息出现了异常丢弃即可。
第三实施例
为了能够更加体现本发明的目的,在本发明第二实施例的基础上,进行进一步的举例说明。
本发明第三实施例提供了一种以太网无源光网络上行链路动态带宽分配方法,本发明第三实施例与本发明第二实施例基本相同,其区别点主要在于:计算得出补偿带宽的大小的过程。
在本发明第三实施例中,计算补偿带宽数值的流程贯穿在整个dba周期的带宽分配步骤中,为了实现补偿带宽的计算,可以设置一个流量统计装置和一个流量补偿装置。
这里,流量统计装置,用于对通过每个逻辑链路实际上传的流量进行统计,对于任意一个逻辑链路,将通过其实际上传的数据流量记为up_statics,up_statics的初始值为0;在实际应用中,每通过对应逻辑链路上传一个数据包, 令up_statics的值累加pkt_len、ipg_len以及premble_len,这里,pkt_len表示上传的数据包的数据长度,ipg_len表示帧间距长度,premble_len表示与上传的数据包对应的前导长度,例如,ipg_len等于12,preamble_len等于8。
下面针对统计通过每个逻辑链路实际上传的流量的开始时刻进行说明。olt中可以设置用于计算gate帧中grant_length长度的dba模块,在计算通过对应逻辑链路实际上传的流量的开始时刻start_time时,olt可以逐步划分未来的上行时隙,对每个gate条目,会提前计算出gate帧对应的burst未来上行时间exp_up_burst_time,因此exp_up_burst_time是可以确定的;为了保证流量统计的准确性,当某个逻辑链路要进行补偿带宽分配时,需要先向对应逻辑链路的gate帧一个up_statics_clear_ind指示,当计算出gate帧对应的burst未来上行时间exp_up_burst_time后,在该未来上行时间exp_up_burst_time到达后,将通过对应逻辑链路的实际上传的数据流量清0,之后,开始统计通过每个逻辑链路实际上传的流量,这里,为对应逻辑链路的实际分配带宽也会在下一次为对应逻辑链路实际分配的带宽大于0的时刻开始统计。
流量补偿装置,用于对当前dba周期内为对应逻辑链路总共实际分配的带宽,并基于当前dba周期内为对应逻辑链路实际分配的授权带宽和通过每个逻辑链路实际上传的数据流量,得出下个dba周期补偿带宽的数值。
下面通过图6说明补偿带宽计算的流程,图6为本发明以太网无源光网络上行链路动态带宽分配方法的第三实施例中补偿带宽计算的流程图,如图6所示,该流程包括:
步骤301:在固定带宽分配步骤后,得出为对应逻辑链路实际分配的固定带宽,并设置补偿使能cm_en的值。
这里,固定带宽分配步骤得出为对应逻辑链路实际分配的固定带宽不包括开销,将固定带宽分配步骤得出为对应逻辑链路实际分配的固定带宽记为fix_pure;根据步骤200,在当前dba周期能够分配固定带宽时,fix_pure=fix_bw_cnt;在当前dba周期是不能分配固定带宽的dba周期时,fix_pure=0。
这里,补偿使能cm_en的取值为0或1,在补偿使能为0时,关闭带宽补偿功能,在步骤200后,如果req小于bw_fix_cnt+token_a+token_pw,则置cm_en=0,使带宽补偿功能处于关闭状态;反之如果req不小于bw_fix_cnt+token_a+token_pw,补偿使能cm_en保持不变。
在根据req与bw_fix_cnt+token_a+token_pw的大小关系设置补偿使能cm_en的值后,如果带宽补偿功能处于关闭状态,且在固定带宽分配步骤分配的固定带宽无法满足对应逻辑链路请求带宽req,则置cm_en=1,启动带宽补偿功能。
步骤302:在保证带宽分配步骤后,得出为对应逻辑链路实际分配的保证带宽,并更新补偿使能cm_en的值。
这里,为对应逻辑链路实际分配的保证带宽不包括开销,将当前dba周期为对应逻辑链路分配的保证带宽的值记为ass_pure,在带宽补偿功能处于关闭状态且保证带宽分配步骤后实际分配的带宽无法满足对应逻辑链路请求带宽时,置cm_en=1,启动带宽补偿功能。
具体地说,基于步骤201,在req小于等于token_a且req大于thre_max时,置cm_en=1;在req小于等于token_a且req小于等于thre_max时,令cm_en保持不变;在req大于token_a且token_a大于等于thre_min时,置cm_en=1;在req大于token_a且token_a小于thre_min时,置cm_en=0。
步骤303:为逻辑链路进行补偿带宽分配。
本步骤与步骤202的实现方式相同,这里不再重复。
步骤304:在尽力而为带宽分配步骤后,得出当前dba周期为对应逻辑链路分配的尽力而为带宽,并更新补偿使能cm_en的值。
这里,为对应逻辑链路分配的尽力而为带宽不包括开销,将当前dba周期为对应逻辑链路分配的尽力而为带宽的值记为be_pure,在带宽补偿功能处于关闭状态且尽力而为带宽分配步骤后实际分配的带宽无法满足对应逻辑链路请求带宽时,置cm_en=1,启动带宽补偿功能。
具体地说,基于步骤203,在req小于等于token_pw且req大于thre_bmax 时,置cm_en=1;在req小于等于token_pw且req小于等于thre_bmax时,cm_en保持不变;在req大于token_pw且token_pw大于等于thre_bmin时,置cm_en=1;在req大于token_pw且token_pw小于thre_bmin,cm_en保持不变。
步骤305:得出当前dba周期内为对应逻辑链路实际分配的授权带宽。
具体地,将当前dba周期内为对应逻辑链路实际分配的授权带宽的值记为bw_pure,则bw_pure=fix_pure+ass_pure+be_pure,
进一步地,将下一个周期为对应逻辑链路实际分配的授权带宽的值记为bw_pure_next,bw_pure_next=bw_pure+fix_pure+ass_pure+be_pure。
步骤306:计算得出补偿带宽的值bw_c。
具体地,得出补偿带宽漏桶token_c的值,补偿带宽漏桶token_c的初始值为intial_token_c;得出补偿带宽漏桶token_c的值的过程可以包括:如果当前时刻cm_en=1,需要置token_c_clear_flag=1,token_c=initial_token_c;如果当前cm_en=0,则在流量补偿功能的工作过程中,进行流量统计和实际下发带宽的平衡工作,此时token_c=token_c_next=token_c+bw_pure-up_statics。
在得出token_c之后,如果token_c大于intial_token_c,则补偿带宽的值bw_c为token_c减去intial_token_c得出的差值,反之,如果token_c不大于intial_token_c,则补偿带宽的值bw_c等于0。
第四实施例
基于本发明第一实施例提供的epon上行链路dba方法,本发明第四实施例提供了一种epon上行链路dba装置。
图7为本发明实施例epon上行链路dba装置的组成结构示意图,如图7所示,该装置包括:第一分配模块401和第二分配模块402,其中,
第一分配模块401,用于在当前dba周期,按照预先设置的第一带宽分配策略,为每个逻辑链路分配授权带宽;
第二分配模块402,用于针对按照所述第一带宽分配策略分配的授权带宽大于0的逻辑链路,分配补偿带宽;所述补偿带宽为前一dba周期为对应逻辑链路分配的授权带宽减去前一dba周期通过对应逻辑链路实际上传的数据 流量而得出的差值。
具体地,所述第一分配模块401,用于在对应逻辑链路的请求带宽大于设定的带宽分配阈值时,为对应逻辑链路分配大小不超过带宽分配阈值的授权带宽;在对应逻辑链路的请求带宽小于等于设定的带宽分配阈值时,按照对应逻辑链路的请求带宽为对应逻辑链路分配授权带宽。
进一步地,所述第二分配模块402,还用于在按照所述第一带宽分配策略为对应逻辑链路分配的授权带宽等于0,且所述补偿带宽的值大于预先设置的补偿带宽分配阈值时,为对应逻辑链路分配补偿带宽。
进一步地,所述装置还包括第三分配模块403;所述第三分配模块403,用于在分配补偿带宽之后,在对应逻辑链路还有剩余的允许分配的带宽时,按照预先设置的第二带宽分配策略,为对应逻辑链路分配授权带宽。
具体地,所述第三分配模块403,用于根据经过补偿带宽分配后对应逻辑链路剩余的允许分配的带宽的值、经过补偿带宽分配后还未满足请求带宽的所有逻辑链路的权重之和、以及预先设置的对应逻辑链路的权重,得出对应逻辑链路允许分配的授权带宽;基于所述对应逻辑链路允许分配的授权带宽,为对应逻辑链路分配授权带宽。
在实际应用中,所述第一分配模块401、第二分配模块402和第三分配模块403均可由位于olt中的中央处理器(centralprocessingunit,cpu)、微处理器(microprocessorunit,mpu)、数字信号处理器(digitalsignalprocessor,dsp)、或现场可编程门阵列(fieldprogrammablegatearray,fpga)等实现。
第五实施例
本发明第五实施例提供了一种olt,该olt包括本发明第四实施例中的任意一种epon上行链路dba装置。
本领域内的技术人员应明白,本发明的实施例可提供为方法、系统、或计算机程序产品。因此,本发明可采用硬件实施例、软件实施例、或结合软件和硬件方面的实施例的形式。而且,本发明可采用在一个或多个其中包含有计算机可用程序代码的计算机可用存储介质(包括但不限于磁盘存储器和光学存储 器等)上实施的计算机程序产品的形式。
本发明是参照根据本发明实施例的方法、设备(系统)、和计算机程序产品的流程图和/或方框图来描述的。应理解可由计算机程序指令实现流程图和/或方框图中的每一流程和/或方框、以及流程图和/或方框图中的流程和/或方框的结合。可提供这些计算机程序指令到通用计算机、专用计算机、嵌入式处理机或其他可编程数据处理设备的处理器以产生一个机器,使得通过计算机或其他可编程数据处理设备的处理器执行的指令产生用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的装置。
这些计算机程序指令也可存储在能引导计算机或其他可编程数据处理设备以特定方式工作的计算机可读存储器中,使得存储在该计算机可读存储器中的指令产生包括指令装置的制造品,该指令装置实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能。
这些计算机程序指令也可装载到计算机或其他可编程数据处理设备上,使得在计算机或其他可编程设备上执行一系列操作步骤以产生计算机实现的处理,从而在计算机或其他可编程设备上执行的指令提供用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的步骤。
以上所述,仅为本发明的较佳实施例而已,并非用于限定本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!