熵转换编码的方法以及相关装置与流程
本申请请求2015年1月4日提交的申请号为62/170,810的美国临时专利申请的优先权。相关的专利申请的全文被本申请引用。
技术领域
本发明有关于源数据(例如视频以及图像数据)的熵编码。具体来说,本发明有关于使用算术编码的熵编码数据的转换编码,来增进性能。
背景技术:
视频数据需要大量的存储空间来存储或者需要较宽的频宽来传输。随着高分辨率与高帧率的发展,如果视频数据是以未压缩形式存储或者传输,对存储以及传输频宽的需求是艰巨。因此,视频数据通常是以视频编码技术来压缩的形式来存储或者传输。使用新的视频压缩格式,例如H.264/AVC、VP8、VP9、以及新兴的高效视频编码HEVC(High Efficiency Video Coding)标准,编码效率大幅地增加。为了维持管理的复杂性,一张图片通常分为多个区块,例如宏区块(MB)或者最大编码单元/编码单元LCU/CU来应用视频编码。视频编码标准通常在区块的基础上使用帧间/帧内预测。
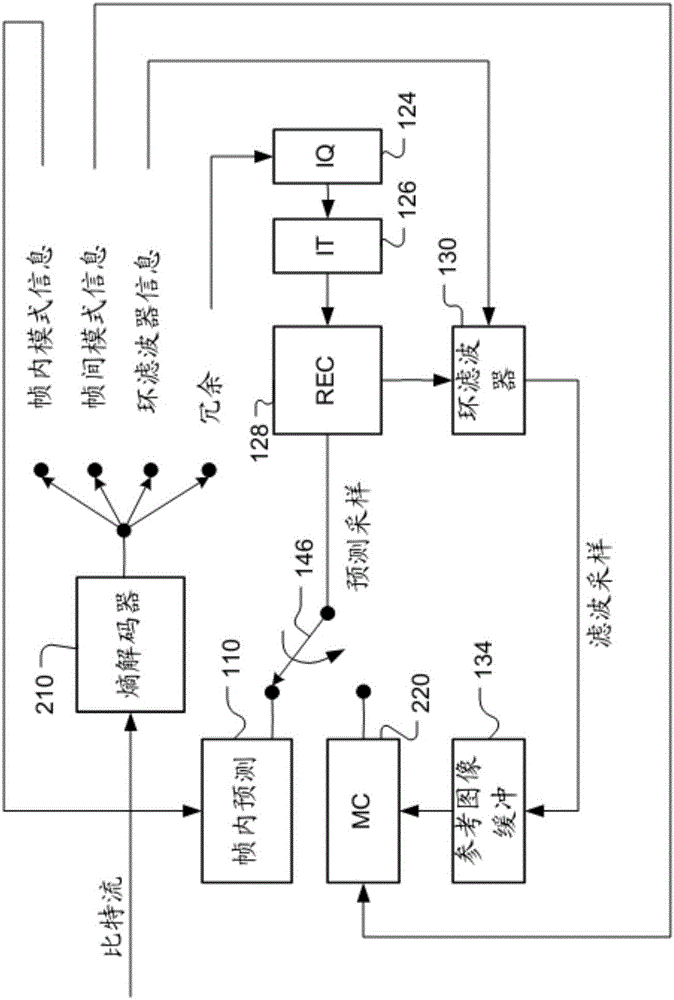
图1是具有循环处理的适应性帧间/帧内视频编码系统的举例说明。为了帧间预测,运动估计(ME)/运动补偿(MC)112用来基于来自其他图像或者图像组合的视频数据提供预测数据。开关114选择帧内预测110或者帧间预测数据,并且选择的预测数据提供给加法器116来行成预测误差,也称为冗余。预测误差接着被转换器(T)118以及后续的量化(Q)120处理。转换的以及量化的冗余被熵编码器122编码,来包含 在一个视频比特流中,该视频比特流对应压缩的视频数据。该比特流与该转换系数一同被与旁侧信息(例如运动、编码模式以及其他与图像区域有关的信息)一起打包。旁侧信息也可以通过熵编码来压缩,以减少所需的频宽。据此,如图1所示,与旁侧信息有关的数据也提供给熵编码器122。当使用帧间预测模式时,一个参考图像或者多个参考图像在编码器端重建。接着,转换的以及量化的冗余通过逆转换(IQ)124以及逆转换(IT)126来处理,以恢复冗余。该冗余接着在重建(Reconstruction,REC)128被加回至预测数据136,以重建视频数据。重建的视频数据在参考图像缓冲134中存储并用于预测其他帧。
如图1所示,输入的视频数据在编码系统中经过一系列的处理。来自REC128的重建的视频数据可能由于一系列的处理导致具有各种损伤。因此,经常在重建的视频数据存储在参考图像缓冲器134之前,应用环滤波器130来增进视频质量。举例来说,解区块滤波器(DF)以及采样自适应偏移(Sample Adaptive Offset,SAO)在HEVC标准中使用。环滤波器信息需要嵌入比特流,从而使得一个解码器能够正确地恢复所需的信息。因此,环滤波器信息被提供给熵编码器122,以嵌入至比特流中。在图1中,环滤波器130是在重建的采样存储至参考图像缓冲器134之前应用至重建视频。图1所示的系统是一个典型的视频编码器的举例说明,其可对应至HEVC系统、VP8、VP9或者H.264。
图2是图1所示的编码器系统对应的视频解码器的系统区块的举例说明。由于编码器也包含一个本地解码器来重建视频数据,一些解码器部分也已经用在了编码器中,除了熵解码器210。更进一步,仅仅运动补偿220在解码器端是需要的。开关146选择帧内预测或者帧间预测,并且所选择的预测数据提供给REC128,以与恢复的冗余结合。除了在压缩的冗余上执行熵解码,熵解码器210也用于执行旁侧信息的熵解码,并且提供旁侧信息至各个区块。举例来说,帧内模式信息提供给帧内预测110,帧间模式信息提供给运动补偿器220,环滤波器信息提供给环滤波器130,以及冗余提供给逆量化124。冗余被IQ124、 IT126以及后续的重建程序处理以重建视频数据。此外,来自REC128的重建的视频数据经过如图2所示的一系列的包含IQ124与IT126的处理并且遭受伪影。重建的视频数据进一步被环滤波器130处理。
对于熵编码而言,其具有多种形态。可变长度编码是熵编码的一种形态,其被广泛地应用于源编码。通常,可变长度编码(VLC)表被使用来进行可变长度编码以及解码。算术编码是一种新型的熵编码技术,其使用“文本(context)”来利用条件性概率。进一步来说,算术编码可容易地适应于源统计并且相较于可变长度编码提供较高的压缩效率。算术编码是一种高效率的熵编码工具,在先进的视频编码系统中被广泛地使用,同时算术编码的操作也比可变长度编码更复杂。
图3是基于文本的适应性二进制算术编码(context-based adaptive binary arithmetic coding,CABAC)程序的示例性区块示意图。由于CABAC驱动中的算术编码器仅仅可以编码二进制符号值,CABAC程序需要使用二值化计算310(binarizer)转换语法元素的值为二进制值。转换过程通常称为二值化。在编码程序中,针对不同的文本,概率模型从编码的符号逐步建立。文本模型化320作为模型,并且使用解码输出数据来进行模型更新。据此,提供了一条从常规编码引擎330的输出至文本模型化320的路径335。在常规基于文本编码的过程中,使用常规编码引擎330,其对应一个二进制算术编码器。用于编码下一二进制符号的模型文本的选择可通过编码的信息决定。符号也可不经过模型阶段来编码,并且假设一个相同的概率分布,通常作为旁通模型(bypass mode),来减少复杂性。对于旁通模型,使用旁通编码引擎340。如图3所示,开关(S1、S2与S3)用来指示在常规CABCA模式以及旁通模式之间的数据流。当选择常规的CABAC模式时,开关翻转至较上连接。当选择旁通模式时,开关翻转至较下连接。
由于高压缩效率,需要利用算术编码的长处来增进熵编码视频数据的性能。
技术实现要素:
本发明之一实施例提供一种压缩比特流的转换编码的方法。该系统接收第一压缩比特流,该第一压缩比特流是通过应用第一熵编码至一组标记产生的;使用对应该第一熵编码的第一熵解码来解码该第一压缩比特流为该组标记;使用第二熵编码来编码该组标记为第二压缩比特流,其中该第二熵编码以及该第一熵编码使用不同的统计、或者不同的初始状态、或者两者都不同。该系统进一步包含决定一个或者多个改进的或者最优的与该组标记有关的概率模型,其中该第二熵编码是基于该改进的或者最优的概率模型。
在本发明的一实施例中,该改进的或者最优的概率模型是基于从视频编码器接收到的文本统计来决定的,并且该文本统计是与从源编码程序产生的多个标记相关,该源编码程序包含运动估计、运动补偿、转换、量化、逆量化以及/或者逆转换。举例来说,该视频编码器对应VP9或者VP8视频编码器,该第一熵编码对应VP9或者VP8算术编码器。对于VP9系统,对于每一帧使用后向适应来更新该一个或者多个改进的或者最优的概率模型,针对具有N个帧的该第一压缩比特流,基于第(N-1)帧的该一个或者多个改进的或者最优的概率模型被该第一熵解码使用,并且基于第N帧的该一个或者多个改进的或者最优的概率模型被该第二熵编码使用,其中N是正整数。对于VP8系统,对于每一帧更新该一个或者多个改进的或者最优的概率模型,针对具有N个帧的该第一压缩比特流,基于第N帧的该一个或者多个改进的或者最优的概率模型被该第二熵解码使用,其中N是正整数。
该方法进一步包含从第一压缩的比特流获得文本统计。其中该文本统计与从源编码程序产生的多个标记相关,该源编码程序包含运动估计、运动补偿、转换、量化、逆量化以及/或者逆转换,并且该改进 的或者最优的概率模型是基于所获得文本统计。
在另一个举例说明中,第一压缩比特流是通过视频编码器获得,第二熵编码与第一熵编码对应算术编码,并且第二熵编码与第一熵编码使用不同的初始状态。视频编码器对应H.264或者HEVC算术编码器。对于H.264视频编码器,针对第二熵编码由cabac_init_idc指示的一个或者多个非预置初始状态被评估,并且该一个或者多个非预置初始状态与一个预置初始状态中的一个达到最佳性能的最优初始状态被选择来进行第二熵编码。对于HEVC视频编码器,对于该第二熵编码由cabac_init_flag指示的所有初始状态被评估,并且达到最优编码性能的一个初始状态被选择来进行该第二熵编码。
本发明的另一实施例提供一种压缩的比特流的熵转换编码的装置。该装置包含第一熵解码单元,使用对应第一熵编码的第一熵解码来解码第一压缩比特流为一组标记;以及第二熵编码单元,使用第二熵编码来编码该组标记为第二压缩比特流,其中该第二熵编码与该第一熵编码使用不同的统计、或不同的初始状态或者两者都不同。该装置进一步包含概率分析单元来决定与该组标记相关的一个或者多个改进的或者最优的概率模型,其中该第二熵编码是基于该改进的护着最优的概率模型。第二熵编码是基于改进的或者最优的概率模型。更进一步,该装置也包含概率分析单元来决定一个或者多个改进的或者最优的与该组标记相关的概率模型,其中该第二熵编码是基于一个或者多个改进的或者最优的概率模型。
附图说明
图1是包含转换、量化以及循环处理的适应性帧间/帧内视频编码系统的举例说明。
图2是包含转换、量化以及循环处理的适应性帧间/帧内视频解码 系统的举例说明。
图3是基于文本的适应性二进制算数编码程序的方块示意图。
图4是依据本发明的使用熵转换编码的示例性情境。
图5是依据本发明的一实施例的包含熵编码的编码系统的实施例行流程图。
图6是2级编码程序的举例说明,其中第一级产生对应编码元素的标记/语法元素,并且第二级应用熵编码至产生的标记/语法元素。
图7是依据本发明的实施例的针对VP9编码的比特流的熵转换编码设计的举例说明。
图8是依据本发明的实施例的针对VP8编码的比特流的熵转换编码设计的举例说明。
图9是依据本发明的实施例的针对H.264编码的比特流的熵转换编码设计的举例说明。
图10是依据本发明的实施例的针对HEVC编码的比特流的熵转换编码设计的举例说明。
图11是依据本发明的实施例的针对VP9编码的比特流的不需要存取编码器内部信息的熵转换编码设计的举例说明。
图12是依据本发明的实施例的针对VP8编码的比特流的不需要存取编码器内部信息的熵转换编码设计的举例说明。
图13是依据本发明的实施例的使用熵转换编码来增强编码性能的视频编码系统的流程图。
具体实施方式
如下所述的说明是实施本发明的最佳模式之一的举例说明。以下描述仅仅用来举例说明本发明的精神,而并非是本发明的限制。本发明的范围参考权利要求来确定。
如上所述,算术编码是一种高效率的熵编码工具。每一符号可以是使用文本的熵编码的,从而利用具有已知的文本的当前符号的一些 条件性概率。更进一步,算术编码可使用文本模型更新程序来适应性地适用于源符号的下层统计。在算术编码程序的开始,下层源符号的统计可能并不知道。因此,使用一个初始的文本模型,并且希望文本更新程序可以逐步地收敛至真实的统计。
算术编码具有逐步适用于真实统计的能力,压缩效率可被初始文本模型所影响。对于已经进行熵编码数据(包含算术编码数据)的算术编码,具有一些增强性能的空间。本发明提供一种熵转换编码方法来增强熵编码数据的性能。图4是依据本发明的一实施例的情境的使用熵转换编码的举例说明。熵转换编码器420可接收来自视频编码器410的输入比特流,其中视频编码器使用算术编码来压缩至少一部分编码符号或者编码参数。熵转换编码器420使用改进的或者最优的概率模型来重新编码先前已编码的编码符号或者编码参数,以达到增强编码效率的目的。熵转换编码可与附加的数据存取以及计算协同使用,其将导致较高的数据频宽以及较高的计算成本。然而,频宽与计算成本的增加可被编码效率的增加所补偿。此外,用于存储整个帧文本的外部存储器可减少。
图4所示的视频编码器410可以是任何的使用算术编码的视频编码器。举例来说,视频编码器可对应AVC/H.264、HEVC/H.265、VP8或者VP9视频编码器。图4所示的熵转换编码器420可基于软件(例如高级程序代码或者数字信号处理(DSP)代码)或者基于硬件(例如应用特定集成电路(ASIC))。更进一步,熵转换编码的使用可适应性地使能(enable)或者失能(disable)。举例来说,一旦功率消耗过高或者处理器/系统资源紧张,熵转换编码可被失能,而不导致任何的系统错误。在这种情况下,系统将仅仅后退至初始的来自视频编码器410的比特流。
图5是依据本发明的实施例的编码系统结合熵转换编码的流程图。流程的输入是一个经过熵编码的比特流。系统在步骤510获得一个标记/语法,并且在步骤520决定是否该标记/语法是算术编码的。 如果该标记/语法是算术编码的(即“是”的路径),则执行步骤530与540。如果该标记/语法不是算术编码的(即“否”的路径),则执行步骤550与560。在步骤530中,算术编码的标记/语法将依据原始的编码器使用的原始的概率模型来解码。如上所述,原始的算术编码的编码效率可能由于多种原因而不如所需的效果好。本发明的系统将使用一个具有更准确概率模型以及/或者更佳的概率模型的算术编码来重新编码该标记/语法,如步骤540所示。如果处理的标记/语法不是算术编码的,该标记/语法可被编码,其可能是使用可变长度未压缩或者压缩的。未压缩的标记/语法被提取,举例来说,在步骤550中被恢复。如果该标记/语法是可变长度编码的,其要使用可变长度解码器来解码。在步骤560中,该标记/语法将使用熵编码来重新编码。算术编码也将应用于该分支的标记/语法,以进一步提高编码效率。然而,原始的VLC或者改进的VLC也可用于该分支的标记/语法。在步骤570中,系统检查该标记/语法是否是输入中的最后一个。如果结果为“是”,程序将结束。如果结果为“否”,如步骤580所示,该程序获取下一标记/语法,并且在步骤520开始重复上述流程。该标记/语法元素在一些文献中也称为编码元素。
对于VP8与VP9,编码器使用如图6所示的2级编码流程600,其中编码器应用第一级编码流程610来产生标记/语法。第一级编码流程610包含运动估计/补偿(ME/MC)、转换(T)、量化(Q)、逆量化(IQ)、逆转换(IT)、重新构建(REC)以及过滤。一个图像单元(例如一个帧)产生的标记/语法元素在存储整个帧文本的外部存储器640中缓冲。在一个帧的标记/语法元素累计之后,概率模型与该标记/语法的文本将使用概率分析620而产生。概率分析620产生的概率模型提供给熵编码630来编码外部存储器640中存储的标记/语法。
由于概率模型是从实际产生的标记/语法元素而获得的,2级编码器能够实现更有效率的熵编码。然而,2级编码器需要一个额外的缓冲器来缓冲编码的帧的标记/语法元素。此外,将产生的标记/语法元 素写出以及读回需要消耗附加的频宽。概率模型化以及熵重新编码也将消耗更多的功率。
为了节省频宽与缓冲器,1级编码器在VP8与VP9被使用。1级编码器结合所有的后续流程,包含一个基于宏区块编码循环的运动估计、运动补偿、转换、量化、逆量化、逆转换以及熵编码。由于在熵编码的过程中帧的统计不可得,使用的来产生比特流的概率模型并非最优。
针对VP9的熵转换编码的举例
如上所述,来自VP编码器的比特流由于1级安排而是次优的。本发明的一个实施例可应用至VP9编码器的比特流,以使用改进的/优化的概率模型来熵转换编码该比特流,从而提高性能。
视频内容在本质上是非平稳的。为了追踪多种编码符号的统计并且更新熵编码文本的参数来匹配,通过使用在每一个帧的开始示意编码文本的修正的帧头(frame header)旗标(flag),VP9利用向前文本更新(forward context update)。向前更新的语法设计为允许一个任意的结点概率(node probability)的子集更新,而同时保持其他的不变。由于不需要基于遇到的标记计数的中间计算,解码速度能够显著地提高。更新被区别地编码,以允许更新的编码文本的更有效的说明,考量到VP9中可用的标记的扩展集合,这一点是宝贵的。
此外,VP9也在编码每一帧的结尾使用后向适应(backward adaptation),从而使得对解码速度的影响降到最低。具体来说,针对每一个编码帧,首先一个前向更新修改各种从该帧的开始的初始状态开始的编码的符号的熵编码文本。然后,该帧的所有的编码的符号使用该修改的编码状态来编码。在该帧的结束,编码器与解码器都期待具有该帧的各种实际编码或者解码的符号的累积数量。使用这些实际的分布,应用一个后向更新的步骤,以适用该熵编码文本作为下一帧使用的基准。换言之,在后向适应模式中,从当前帧收集的统计用于下一帧的熵编码。
如上所述,针对VP9的熵编码的性能是折中的,以加速编码程序,特别是解码速度。如较早所述,外部存储所需是针对VP8与VP9使用次优熵编码的另一个原因。为了增强熵编码的性能,本发明的一个实施例使用概率分析以及后向适应来增强或者优化熵重新编码的性能。概率分析可以作为熵转换编码的一部分或者在熵转换编码的外部。依据这个实施例,概率分析并不依赖于VP9比特流的概率模型。替代地,熵转换编码依据当前帧的统计来获得编码每一当前帧的概率模型。熵转换编码的概率集合可依据一些准则(例如成本最优)来决定。
图7是依据本发明的实施例的针对VP9编码的比特流的熵转换编码的举例说明。该系统区块图也包含了其他相关的部分,例如VP9编码器以及与概率模型化相关的各种模块。熵转换编码器710包含熵重新编码模块712(图7中简述为熵编码)以及熵解码模块714(图7中简述为熵解码)。熵解码模块714用来解码包含通过一个次优熵编码器编码的比特流。在标记/语法元素从熵解码模块714恢复之后,标记/语法元素被熵编码重新模块712编码,其使用更准确的概率模型以达到更好的压缩效率。
如上所述,VP9以后向的方式更新概率模型,其中基于帧(N-1)的统计应用于帧N的编码。然而,来自帧(N-1)的统计可能与来自帧N的统计不匹配,从而压缩效率将降低。如图7所示,输入比特流是通过1级Vp9编码器720产生的,其包含了源编码模块722以及宏区块熵编码模块724。源编码模块722包含运动估计(ME)、运动补偿(MC)、转换(T)、量化(Q)、逆量化(IQ)、逆转换(IT)、标记产生、以及其他类型的源编码模块或者其组合。宏区块熵编码724使用初始概率集合732进行宏区块熵编码。在1级编码器中,执行后向概率适应来产生下一帧使用的初始概率模型。为了熵重新编码达到增强压缩性能的目的,使用概率分析以及后向适应模块730来提供概率模型给熵解码模块714以及熵重新编码模块712。概率分析以及后向适应模块730 从视频编码器720接收文本统计。一个概率集合对应当前帧N使用的概率模型,其是基于先前帧(即帧N-1)获得的。这个概率集合是基于帧N-1获得,提供给熵解码模块714来解码对应当前帧N的比特流。熵解码模块714输出恢复的当前帧N的标记/语法元素,其将通过熵重新编码器712使用基于帧N获得的概率集合来熵编码。
概率分析的目的是找到针对所有标记的最优化的概率。概率分析程序如下所述。对于每一标记T,T=1与T=0的出现的统计被收集。如果对应的事件数量分别是C(1)与C(0),T=1的最优概率Popt计算为(C(1)/(C(0)+C(1))。T的概率更新为一个新的概率Pnew,其在概率Pold与最优概率Popt之间。新的概率Pnew依据VP9决定为最小化的Bits_to_code_Pnew+C(1)*Cost(Pnew)+C(0)*Cost(1–Pnew)。在最优概率Popt决定之后,概率依据Padapted=Pprev_updated*(256–Rupdate)+Popt逐帧地适用,其中Pprev_updated是先前帧的Padapted,并且Rupdate代表更新率。
针对VP8的熵转换编码举例
在VP8中,概率表在帧头指派。语法元素是用来直接指示该概率是更新的或者与前一帧保持相同。VP9使用的向后适应并不适用于VP8。
图8是依据本发明的实施例的针对VP8编码的比特流的熵转换编码的举例说明。该系统区块图也包含了其他相关的部分,例如VP8编码器以及与概率模型化相关的各种模块。熵转换编码器810包含熵重新模块812以及熵解码模块814。熵解码模块814用来解码包含通过一个次优熵编码器编码的比特流。在标记/语法元素从熵解码模块814恢复之后,标记/语法元素被熵编码模块812编码,其使用更准确的概率模型以达到更好的压缩效率。
如图8所示,输入比特流是通过1级Vp8编码器820产生的,其包含了源编码模块822以及宏区块熵编码模块824。源编码模块822包含运动估计、运动补偿、转换、量化、逆量化、逆转换、标记产生、以及其他类型的源编码模块或者其组合。宏区块熵编码824使用初始 概率集合832进行宏区块熵编码。
如上所述,VP8以向前的方式更新概率模型,其中其中基于帧(N-1)的统计应用于帧N的编码,而并没有使用向后适应程序。然而,来自帧(N-1)的统计可能与来自帧N的统计不匹配,从而压缩效率将降低。概率更新在帧头中示意出来。概率分析模块830用来基于当前帧的文本统计获得当前帧的概率集合。所获得的文本概率集合834提供给熵重新编码模块812来编码从熵解码模块814恢复的标记/语法元素。
在图8中,概率分析模块830可嵌入熵转换编码器810。概率分析模块830也可设置在熵转换编码器810的外部。
针对H.264的熵转换编码的举例
H.264使用文本适应二进制算术编码(CABAC),其利用自适应文本模型化。由于CABAC能够自适应于正在处理的视频数据的统计,每一图像单元(例如通过使用一些预先定义的概率状态的切片)的所有的模型需要重新初始化。该预先定义的概率状态(即cabac_init_idc)是用于将初始偏移给文本变量。当熵转换编码器是在H.264编码中使用时,本发明的一个实施例评估所有的cabac_init_idc值,并且选择其中之一来获得最佳的压缩效率。
图9是依据本发明的实施例的针对H.264编码的比特流的熵转换编码器的设计的举例说明。该系统区块图也包含了其他相关的部分,例如H.264编码器以及其他模块来支持本发明的实施例。熵转换编码器910从H.264编码器920接收编码的比特流,其中使用一个预置的cabac_init_idc。熵转换编码器910将首先使用H.264解码器以预置的cabac_init_idc来解码接收到的H.264比特流,以恢复标记/语法元素。熵转换编码器接着评估针对所有可能初始文本表的产生的比特率,并选择其中一个来达到最优的压缩效率。最优比特流,即是使用最优初始文本表(即最优cabac_init_idc)来编码的比特流,从熵转换编码器910中输出。在图9中,选择器930用来选择最优比特流作为其最终 输出。然而,这种选择可在熵转换编码910中执行。
针对HEVC/H.265的熵转换编码举例
HEVC也与H.264相似地使用文本适应二进制算术编码(CABAC)。文本变量的初始化是通过语法元素cabac_init_flag来控制的。cabac_init_flag说明了决定针对文本变量使用的初始化程序中使用的初始化表的方法。依据本发明的一实施例评估与cabac_init_flag等于0以及等于1相关的比特率,并且选择cabac_init_flag来达到最佳的压缩效率。
图10是依据本发明的实施例的针对HEVC编码的比特流的熵转换编码器的设计的举例说明。该系统区块图也包含了其他相关的部分,例如HEVC编码器以及其他模块来支持本发明的实施例。熵转换编码器1010从HEVC编码器1020接收编码的比特流,其中使用一个预置的cabac_init_flag。熵转换编码器1010将首先使用HEVC解码器以预置的cabac_init_flag来解码接收到的HEVC比特流,以恢复标记/语法元素。熵转换编码器接着评估针对cabac_init_flag等于0与等于1产生的比特率,并选择其中一个来达到最优的压缩效率。最优比特流,即是使用最优初始文本表(即最优cabac_init_flag)来编码的比特流,从熵转换编码器1010中输出。在图10中,选择器1030用来选择最优比特流作为其最终输出。然而,这种选择可在熵转换编码1010中执行。
在上述举例说明中,假设熵转换编码能够接收到所需的信息,来获得改进的或者最优的概率模型,来重新编码标记/语法元素,从而提高压缩效率。其暗示熵转换编码存取视频编码器内部的一些信息,来获得改进的或者最优的概率模型。举例来说,在VP8与VP9的例子中,熵转换编码器存取文本统计。然而,熵转换编码器并非总是存取视频编码器内容的信息。举例来说,从网站下载的视频文件代表从一个编码器产生并且输出的视频数据。没有途径去存取该视频编码器内部的信息。在视频流来自广播端的情况下,仅仅产生的输出比特流是 可以获得的,而无法得知该视频编码器内部的信息。在这样的情况下,用于获得改进的/最优统计模型的信息需要从接收的比特流中获得。
据此,在本发明的另一个实施例中,用于获得改进的/最优的概率模型的信息是从接收的比特流中获得。概率模型是通过分析接收的比特流获得。为了分析接收到的比特流,比特流需要通过使用语法解码器来解码为标记/语法元素。该语法在熵编码中编码。因此,熵解码需要恢复标记/语法元素。标记/语法元素的统计被累计。在统计被累计之后,最优概率表(即最优概率模型)能被建立并用来重新编码恢复的标记/语法元素。
针对VP9的熵转换编码而没有存取编码器内部信息的举例
如上所述,来自Vp9编码器的比特流归因于1级布置,其是次优的。本发明的一个实施例应用至VP9编码器的输出比特流,来使用改进的/最优的概率模型熵转换编码该比特流,以增进性能。
图11是依据本发明的实施例的针对VP9编码的比特流的而不存取编码器内部信息的熵转换编码器设计的举例说明。熵转换编码器1110包含熵编码模块1112以及VP9熵解码模块1114。VP9熵解码模块1114用来解码包含通过一个次优熵编码器编码的比特流。在标记/语法元素从熵解码模块1114恢复之后,该标记/语法元素被熵编码模块1112编码,其使用更准确的概率模型以达到更好的压缩效率。
该系统区块图也包含了其他相关的部分,例如比特流分析器1120以及概率分析与后向适应1130。该比特流分析器1120用来分析接收到的比特流,并且包含如上所述的语法解码器。概率集合1132从概率分析获得,并且向后适应1130提供给熵编码模块1112来重新编码恢复的标记/语法元素。
针对VP8的熵转换编码而没有存取编码器内部信息的举例
图12是依据本发明的实施例的针对VP8编码的比特流的而不存取编码器内部信息的熵转换编码器设计的举例说明。熵转换编码器1210包含熵编码模块1212以及VP8熵解码模块1214。熵解码模块 1214用来解码包含通过一个次优熵编码器编码的比特流。在标记/语法元素从VP8熵解码模块1214恢复之后,该标记/语法元素被熵编码模块1212重新编码,其使用更准确的概率模型以达到更好的压缩效率。该系统区块图也包含了其他相关的部分,例如比特流分析器1220以及概率分析1230。该比特流分析器1220用来分析接收到的比特流,并且包含如上所述的语法解码器。概率集合1232从概率分析获得,并且向后适应1230提供给熵重新编码模块1212来重新编码恢复的标记/语法元素。
图13是依据本发明的实施例的利用熵转换编码器的视频编码系统的示例性流程。在步骤1310,通过应用第一熵编码至一组标记获得的第一压缩比特流被接收。在步骤1320,使用对应第一熵编码的第一熵解码来解码来解码第一压缩比特流为该组标记。在步骤1330,该组标记接着被使用第二熵编码重新编码为第二压缩比特流,其中该第二熵编码与该第一熵编码使用不同的统计、或不同的初始状态、或者两者都不同。
所示的流程图仅仅用来举例说明本发明的实施例。本领域的技术人员能够修改每一步骤、重新安排各个步骤、拆分步骤、或者结合步骤来实现本发明而不背离本发明的精神。在这个说明中,特定语法以及语意被使用来举例说明本发明的实施例。本领域技术人员可通过替代该语法与语意为等同的语法与语意来实现本发明,而不背离本发明的精神。本发明全文中所提及的“最优”、“最佳”,本领域技术人员可理解为可解决所要解决的技术问题的、具有可允许的误差范围的最优或者最佳。换言之,相对于比较的标的,在目前可获得的可能标的中,提供更佳的效果的标的即可称为“最优”、“最佳”,也可理解为“改进的”。
本发明针对算术编码的二进制字符串提供了一种高流量熵解码器。上述说明提供给本领域技术人员使得本领域技术人员能够基于提供的特定应用的文本以及其所需实现本发明。所描述的实施例的多种 修正变型对于本领域技术人员是显然存在的。因此,本发明并不仅仅局限于所提供与描述的例子,而应视为具有与所描述的精神与准则一致的最大化范围。在上述详细说明中,所提供的多种特定细节仅仅为了给本领域的技术人员提供整体理解。然而,本领域技术人员可理解本发明可实现。
所描述的例子视为举例说明而并非限制。本发明的范围由权利要求书指示而并非如上所述的具体说明。权利要求书的所有含义与范围的相同的改变也在其保护范围之下。
- 还没有人留言评论。精彩留言会获得点赞!