通过网络传送媒体的系统及方法与流程
本发明涉及一种通过网络传送影像与声音等媒体的系统及方法,特别是指一种于用户装置上渲染虚拟现实(Virtual-Reality;简称VR)影像的3D对象的方法,该方法通过在用户装置渲染3D对象来结合由服务器提供的VR场景的2D视频串流。
背景技术:
过去几年间,在线游戏已成为世界潮流,随着云端计算相关系统与科技的发展,一种利用服务器串流游戏内容并提供服务的技术也已问世。
一种传统的提供云端游戏服务的方法为通过服务器负责几乎所有的运算,亦即,当要提供云端游戏服务时,该服务器需要产生一包括多个可由参与者移动或控制的3D对象的虚拟3D环境。在已知技术中,这些3D对象可包含音效,之后依据参与者(玩家)的控制动作,该服务器即将虚拟3D环境与3D对象结合并渲染至游戏机上一具有立体声的2D游戏屏幕上。之后,该服务器即将渲染后的影像与立体声以一包含声音的2D视频串流通过网络传输至玩家的装置上,玩家装置于接收后,仅需译码并显示该2D视频串流,而不需进行额外的3D渲染计算。然而,前述在同一服务器上为众多的玩家执行渲染计算的传统技术,将导致执行3D渲染计算的服务器负载过大;此外,因玩家所见画面皆以经过破坏性压缩的2D视频串流形式传输,因此,无论是影像与声音的质量均与原显示3D对象的质量有一段落差,且服务器与玩家装置间的大量网络通信带宽,亦成为一大问题。
虚拟现实(Virtual-Reality;简称VR)技术在近期已非常流行。为了为人眼提供一个VR的视觉感受,虚拟的VR场景必须包含一个专供人类 左眼观赏的影像以及另一专供人类右眼观赏的影像。本发明提供一种通过网络传送影像与声音等媒体的系统及方法,其通过在用户装置渲染3D对象来结合由服务器提供的VR场景的2D视频串流。
技术实现要素:
本发明的主要目的在于提供一种通过网络传送如影像与声音等媒体的系统及方法,可降低服务器的负载,提升用户装置上显示的影像与声音的质量,并节省服务器与用户装置间的通讯带宽;本发明方法的特点为在用户装置渲染3D对象(也称为3D模型)来结合由服务器提供的VR场景的2D视频串流,以达到于用户装置上渲染虚拟现实(Virtual-Reality;简称VR)影像的3D对象的结果。
为了达到上述目的,本发明提供了一种通过网络传送媒体的系统及方法,该媒体包括多个影像。此系统包括一服务器及一用户装置,此方法包括下列步骤:
步骤(A):在一服务器上执行一虚拟现实(VR)应用程序,以产生一包含多个3D模型的虚拟的VR 3D环境,每一3D模型均搭配一指示该3D模型是否预存在一用户装置中的状态;
步骤(B):该服务器检验该多个3D模型的状态,以决定哪一个3D模型要被编码为一2D视频串流所包含的一左眼影格及一右眼影格,其编码方式为将非预存在该用户装置中的多个3D模型编码至该左眼影格及该右眼影格中;
步骤(C):该服务器至少将该2D视频串流的该左眼影格及该右眼影格、通过网络传送到该用户装置;其中,该服务器亦将该非预存在用户装置中的该多个3D模型以一预定顺序传送至该用户装置;当该用户装置接收到由该服务器传送来的该多个3D模型时,该用户装置即将该多个3D模型储存并发出一信息至该服务器,以改变该多个3D模型的状态,并指示该多个3D模型当前为预存在该用户装置中;以及
步骤(D):该用户装置将该自该服务器接收的该左眼影格及该右眼影格解码,并利用该左眼影格及该右眼影格作为渲染该多个预存在用户装置中但未包含在该左眼影格及该右眼影格中的3D模型的一背景画面,以产生作为包含有一VR场景的一输出视频串流的一混合VR影格。
于一实施例中,于该步骤(D)中,在该用户装置将自该服务器接收的该左眼影格及该右眼影格译码之后,该用户装置进一步将该左眼影格及该右眼影格合并为一合并的VR影格,然后使用该合并的VR影格当作该背景画面来渲染该多个预存在用户装置中但未包含在该左眼影格及该右眼影格中的3D模型,以产生作为包含有该VR场景的该输出视频串流的该混合VR影格。
于一实施例中,该服务器还包括:
一VR场景传输器,为编译在该VR应用程序中或于运行时间中动态链接在该VR应用程序上的一链接库;其中,该VR场景传输器包含所有该3D模型以及每一该3D模型的该状态的一列表,该状态用以指明该3D模型的状态为“Not Ready(未备妥)”、“Loading(下载中)”及“Ready for Client(用户已下载)”之一;以及
一VR场景服务器,为以该VR应用程序于该服务器上执行的一服务器程序;其中,VR场景服务器作为该VR场景传输器及该用户装置间信息传递的一中继站,该VR场景服务器亦作为供该用户装置自该服务器下载必要的该3D模型的一下载服务器程序。
于一实施例中,该用户装置还包括:
一VR场景客户端,为一于该用户装置上运转的程序,用以产生该输出视频串流并通过该网络与该服务器连通;
一影格结合器,用以将该左眼影格与该右眼影格合并为该合并的VR影格;以及
一VR场景快取,用以储存至少一之前自该服务器下载的该3D模型。
附图说明
图1为本发明通过网络传送媒体的系统一标准实施例的示意图;
图2为本发明系统架构一实施例的示意图;
图3A为本发明通过网络传送媒体的方法一实施例的流程图;
图3B为本发明通过网络传送媒体的方法另一实施例的流程图;
图4A、4B及4C为本发明方法如何传送视讯串流及3D模型一实施例的示意图;
图5A、5B及5C为本发明方法如何决定哪个3D模型须被编码至影格一实施例的示意图;
图6A、6B及6C为本发明方法如何传送具声音的视讯串流及3D声音一实施例的示意图;
图7A、7B及7C为本发明方法如何决定哪个3D声音须被编码至具声音的视讯串流影格一实施例的示意图;
图8为本发明的虚拟现实(VR)场景系统的系统架构一实施例的示意图;
图9为说明本发明的虚拟现实(VR)场景系统的影格结合器的功能的一实施例示意图;
图10为本发明的VR场景系统的系统架构的第二实施例的示意图;
图11为本发明的VR场景系统的系统架构的第三实施例的示意图。
附图标记说明:1~服务器;3~网络(基地台);4~网络;21~用户装置(智能手机);22~用户装置(笔记本电脑);23~用户装置(桌面计算机);51~使用者眼睛;52~投影面;70~服务器;71、71a~人;72、72a~房屋;73、73a~影格;74~用户装置;75~视讯串流影格;81、81a~声音;82、82a~声音;83、83a、1711、1712、1713~影格;85~视讯串流影格;100、1100~应用程序;110、1110~场景传输器(链接库);120、1120~场景服务器;121~数据封包器;170、1170~场景客户端(程序);1111、 1171~影格结合器;190、1190~场景快取;60~67、661、60a~67a、661a~步骤;101~114、122、124、172、174、176、192、194、1101、1112~1115、1122、1124、1172、1174、1176、1192、1194~路径。
具体实施方式
为了能更清楚地描述本发明所提出的通过网络传送媒体的系统与方法,以下将配合图式详细说明。
本发明运用之一为在线游戏,其玩家使用一用户装置通过网络于一服务器上进行游戏,此服务器依玩家的指令动作并于用户装置上产生视讯;例如,当一玩家在用户装置采取动作时,此一动作即会传送至服务器装置并于其上计算一影像,再将影像回传至用户装置。在许多在线游戏中,服务器所产生的2D影像包括在视线范围内其他对象的3D渲染(Rendering)。
本发明通过服务器提供用户装置所需的3D模型及3D声音,以于服务器及用户装置间进行位于视线范围内对象的3D渲染解析,例如,服务器提供一些或所有的3D模型及3D声音至用户装置,并夹带每一3D模型或3D声音相关的诠译数据,比如位置,座向及状态数据等。
举例说明,在游戏初始,所有在用户装置上与游戏相关的影像(包括相关的3D渲染)为通过网络由服务器产生,成为具立体声的2D视频串流。本发明的系统通过网络,在视线范围内推送3D模型及3D声音等媒体及其渲染信息至用户装置,较近(靠近眼睛)的对象优先推送。本发明系统尽可能于用户装置上进行3D模型及3D声音的渲染,退而求其次则是于服务器上进行如3D模型或3D声音等的渲染。
一3D模型或一3D声音既存于用户装置上,服务器仅需提供对象(3D模型或3D声音)的诠译数据至用户装置,用户装置可据此渲染这些对象并将结果呈现于服务器所提供的任何具立体声的2D视讯上;除非用户装置的要求,否则服务器将不会对此3D模型及3D声音进行渲染。本发明方法此一安排将节省服务器上的GPU计算,服务器可维护一动态数据库,包含 3D模型及3D声音,以提高与用户通讯的效率。
本发明中,用户装置所显示的包含下列的组合:(a)一于服务器上渲染的3D场景,结果为具立体声的2D视频串流的形式,传送至客户端并由用户装置所播放,以及(b)自服务器上下载并储存于用户装置上,由用户装置自行渲染3D模型及3D声音的结果,此一具立体声的2D视讯串流与用户装置上渲染的3D模型及3D声音的混合,将会在降低带宽占用的情形下创造出一缤纷的3D场景以及动人的环场音效。
在一实施例中,传送至用户装置的具立体声的2D视讯串流夹带3D模型及3D声音的诠译数据,用户装置会检测自己是否存有此3D模型及3D声音,如果没有的话,用户装置将会自服务器下载所需的3D模型及3D声音,下载后,用户装置会将其储存并建立数据清单,以备之后重建场景所需。如此,视频串流的延迟与需要大量带宽等问题,将会获得改善,且由用户装置端自行渲染,将可得到质量更佳的影像(因未经过视频压缩)。
前述的诠译数据将允许用户装置可在不遗漏或重复任何3D模型或3D声音的情形下正确地混合用户装置端以3D模型及3D声音所渲染的结果,与服务器提供的具立体声的2D视讯串流;如前所述,当用户装置储存所有需要的3D模型及3D声音后,用户装置即可重建完整的3D场景及声音,此时,服务器即不再需要进行任何渲染、直至一新加入但用户装置端未储存的一新的3D模型或3D声音出现时止,而当遇到一新的3D模型时,服务器会将此新的3D模型及其后的所有件对象进行渲染,直到用户装置可自行渲染此新3D模型为止。此外,如果遇到一新的3D声音,则服务器会将此3D声音渲染,直至其可为用户装置端运用时止。
用户装置会尽可能地将下载的3D模型及3D声音存放(快取)于自己的储存装置上,以避免往后执行时需要重复下载,因此,网络的带宽成本将会进一步降低,如果无法储存,下载和渲染会在执行时完成。
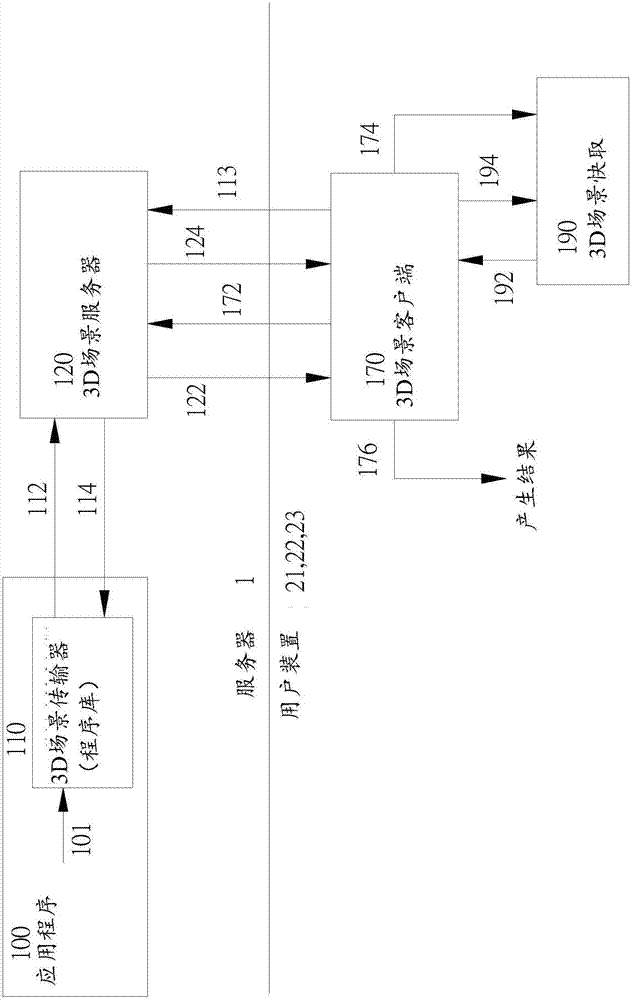
如图1所示为本发明通过网络传送媒体的系统一标准实施例的示意 图。服务器1为用以执行一提供服务的应用程序,此服务可为(但不限定为)一云端在线游戏服务;多个用户装置21、22、23可通过一网络4链接(登入)至服务器1,以使用由服务器1上运转的应用程序所提供的服务。在此实施例中,网络4为一因特网,用户装置21、22、23为可连接至因特网的任何电子装置,例如(但未局限于)智能手机21、数字板、笔记本电脑22、桌面计算机23、视讯游戏机或智能型电视等,一些用户装置21、22通过一行动基地台无线链接至网络4,另一些用户装置则可通过一路由器以有线的方式链接至网络4上;在服务器1上运转的应用程序可产生一包含多个3D模型及3D声音的虚拟3D环境,每一3D模型或3D声音并搭配状态,指示3D模型或3D声音是否预存在一用户装置21、22、23中。在本发明的一较佳实施例中,对每一用户装置而言,皆有一对应的独立应用程序,亦即,一应用程序仅提供服务给一用户装置,但多个应用程序可同时在同一个服务器上执行,以提供服务至多个用户装置。如图所示,用户装置21、22、23通过网络4链接至服务器1,以获取由应用程序产生且包含至少一些3D模型及3D声音的媒体,此一系统架构与其特征详述于图2及相关的叙述中。
图2所示为本发明系统架构一实施例的示意图。
本发明中,应用程序100于一服务器1上运转,用以产生3D影像3D声音的渲染结果,通常为一3D游戏。3D场景传输器110为一链接库(library),于应用程序100在编译时期与的静态链接,或于应用程序100执行期间与的动态链接;3D场景客户端(程序)170则是一于用户装置21、22、23上执行的程序,用以产生并输出由应用程序100生成的3D影像及3D声音渲染结果。在此实施例中,对每一用户装置21、22、23而言,其皆对应有各别独立的应用程序100及场景传输器110。
本发明中,3D场景客户端170及3D场景快取190,组成客户端的程序与执行方法,以发挥用户装置本身渲染3D模型与3D声音的运算能力。
3D场景服务器120为一与应用程序100共同于服务器1上执行的一服务器程序,作为服务器1的3D场景传输器110与用户装置21、22、23的3D场景客户端170间信息传递的中继站。同时亦作为一文件下载服务器,供用户装置21、22、23的3客户端170自服务器1下载必要3D模型及3D声音。3D场景传输器110存储有一个清单,列出所有3D模型及3D声音以及模型或声音的状态,此状态用以指明每一个3D模型或3D声音的状态为(1)“Not Ready(未备妥)”、(2)“Loading(下载中)”、及(3)“Ready for Client(用户已下载)”之一。
应用程序100的主程序通过API呼叫链接库的方式(图2的路径101)将3D场景信息传送至3D场景传输器110,此3D场景信息包括名称、位置、速度、属性、座向及所有其他3D模型及3D声音渲染所需的数据。在3D场景传输器110接收此类数据后,即可执行下列程序。
步骤(a):对3D模型而言,将所有需渲染的3D模型排序,其排序方式可为相对一虚拟位置(如3D投影面或使用者的眼睛)从近到远排序。
对3D声音而言,将所有需渲染的3D声音排序,其排序方式可为相对一虚拟位置(如3D投影面或使用者的眼睛)从近到远排序。
在某些情况下,3D场景中的一3D模型A会包覆或迭覆在另一3D模型B上,例如,模型A可为一房屋,模型B则可为房屋中的一桌子,在此情形下,哪一个模型较接近仿真位置实是一模棱两可的问题,此时,模型A及模型B将会被视为同一3D模型,可称为3D模型(A+B)。
有些对场景的已知信息可用于辅助排序,例如,游戏中的地面,可被视为在其他3D对象下的一大而平的3D模型,通常,用户的眼睛会高于地面,因此,地面的3D模型在排序中需特别处理,以避免它显示于其他3D模型前。
步骤(b):对于3D模型言,从最近点(最接近眼睛者)寻找第一个不具有“Ready for Client”状态的3D模型“M”,换言之,第一个3D模型“M”的 状态为"Not Ready"状态,(在此之后,"Not Ready"状态简称为NR状态);当然,也可能并无此类的3D模型存在(例如所有将被显示的3D模型皆被标示为“Ready for Client”状态)。
对于3D声音言,从最近点(最接近眼睛者)寻找第一个不具有“Ready for Client”状态的3D声音“S”,换言之,第一个3D声音“S”的状态为"Not Ready"状态,(在此之后,"Not Ready"状态简称为NR状态);当然,也可能并无此类的3D声音存在(例如所有将被显示的3D声音皆被标示为“Ready for Client”状态)。
步骤(c):对于3D模型言,服务器渲染3D模型M及其后所有的3D模型,也就是所有比M距离眼睛更远的3D模型。(如果没有3D模型M,则以一黑屏幕显示),编码渲染后的结果为一2D视讯串流影格(frame)。
对于3D声音言,在服务器1上渲染(播放)所有不具有"ready for client"状态的3D声音(如果没有此类3D声音,则产生一静音),接着,编码渲染后的结果为具步骤(C)中的2D视频串流影格的立体声。注意:接续3D模型S后的3D声音仅在其状态非为"Ready for Client"时才会被渲染,此与步骤(C)中的3D模型不同。
步骤(d):传送下列六个信息至3D场景服务器120(路径112):[Info 112-A]、[Info 112-B]、[Info 112-C]、[Info 112-D]、[Info 112-E]及[Info 112-F]),而3D场景服务器120会将以上信息传送至3D场景客户端170(路径122)。
[Info 112-A]为3D模型M前所有3D模型的状态信息(或称诠释数据)。注意可能无此类的模型存在。此类模型皆具有“Ready for Client”状态,意谓着这些模型已经预载于客户端装置,客户端装置21、22、23上面的3D场景客户端(程序)170已经可以自行渲染这些模型。为了减少数据传输带宽,3D场景传输器110可以不必传送全部的状态信息,只要传送状态信息中,本次渲染与上次渲染的差异即可。
[Info 112-B]如果服务器找到了3D模型M且其用户装置的状态为“Not Ready”时,服务器将更改其用户状态为“Loading”,并送出一3D模型M的下载指示,要求客户端下载此3D模型M;如果用户状态已为“Loading”,则不要送出任何指示,因下载指示已送出。
[Info 112-C]为步骤(C)中的编码后的视信串流影格。
[Info 112-D]指所有状态为"ready for client"的3D声音(亦可能无此类3D声音存在)的状态信息(或称诠释数据),此类声音型皆具有“Ready for Client”状态,意味着这些声音已经预载于客户端装置,客户端装置21、22、23上面的3D场景客户端(程序)170已经可以自行渲染(播放)这些声音。为了减少数据传输带宽,3D场景传输器110可以不必传送全部的状态信息,只要传送状态信息中,本次渲染与上次渲染的差异即可。
[Info 112-E]如果服务器找到了3D声音S、且其用户状态为“Not Ready”时,更改其用户状态为“Loading”,并送出一3D声音S的下载指示,要求客户端下载此3D声音S;如果用户状态已为“Loading”,则不要送出任何指示,因下载指示已送出。
[Info 112-F]为步骤(C)中的编码后的立体声。
当每次应用程序100的主程序将新的3D场景数据更新至3D场景传输器110时,重复步骤(a)~(d),通常,应用程序100的主程序会在每一次的渲染中更新此类数据。
一俟3D场景客户端170接收前述数据后,即进行后述的渲染程序。
步骤(i):译码[Info 112-C]的视讯影格并使用这影格作为后续3D模型渲染的背景;此外,并译码具有[Info 112-F]视讯的立体声并使用其为后续3D声音渲染的背景声音。
步骤(ii):在步骤(i)编码后的视信影格上渲染所有[Info 112-A]中的3D模型,为降低网络带宽占用,3D场景客户端170将会储存此一[Info 112-A]信息至内存中,因此下次3D场景传输器110可仅传送下次渲染与本次渲 染间的状态[Info 112-A]差异,不需要传送全部的状态信息;相同地,当在渲染所有属[Info 112-D]的3D声音时,将的混以步骤(i)中解碼的立体声,为了降低网络带宽占用,3D场景客户端170将会储存此一[Info 112-D]信息至内存中,因此下次3D场景传输器110可仅传送下次渲染与本次渲染间的状态[Info 112-D]差异,不需要传送全部的状态信息。
步骤(iii):步骤(ii)中,混合了服务器传来的具立体声的视讯影格,与3D场景客户端170自行渲染的3D模型与3D声音,将两者混合结果输出,成为一具声音的输出视讯串流(路径176)。
如果提供有[Info 112-B]的状态,3D场景客户端170将依下列程序处理3D模型M。
步骤(I):搜寻3D场景快取190(路径174),3D场景快取190包含之前下载及储存于用户装置21、22、23中的3D模型数据库。
步骤(II):如果3D场景快取190中已经有3D模型M,则执行步骤(V)。
步骤(III):如果3D场景快取190中没有3D模型M,则3D场景客户端170将会送出一下载需求至3D场景服务器120(路径172),3D场景服务器120将会回传3D模型M的数据给3D场景客户端170(路径124)。
步骤(IV):一3D模型完全下载后,3D场景客户端170即将其存入3D场景快取190(路径194),藉此,当下次具有类似需求时,即不需再进行下载。
步骤(V):3D场景客户端170将自3D场景快取190中,提取3D模型M(路径192)。
步骤(VI):一下载完成(或之前早已下载),3D场景客户端170即可提取3D模型M;3D场景客户端170将会送出一“3D model is ready on client(3D模型已在用户装置上)”的信息至3D场景服务器120(路径113),3D场景服务器120将会转送此信息至3D场景传输器110(路径114)。
步骤(VII):一3D场景传输器110接收此信息后,即会将3D模型M 的状态由“Loading”改为“Ready for Client”。
步骤(VIII):在下一次的渲染中,3D场景传输器110将会知晓3D模型M现已预载于用户装置中,故将会请3D场景客户端170自行渲染,因此,服务器1将不再需要渲染此一3D模型M。
如果提供有[Info 112-E]的状态,3D场景客户端170将依下述程序备妥3D声音S。(类同前述对于关于[Info 112-B]所描述者)
步骤(I):搜寻3D场景快取190(路径174),3D场景快取190包含之前下载及储存于用户装置21、22、23中的3D声音数据库。
步骤(II):如果3D场景快取190中备有3D声音,则执行步骤(V)。
步骤(III):如果3D场景快取190中未备有3D声音,则3D场景客户端170将会送出一下载需求至3D场景服务器120(路径172),3D场景服务器120将会回传3D声音的数据给3D场景客户端170(路径124)。
步骤(IV):一3D声音完全下载后,3D场景客户端170即将其存入3D场景快取190(路径194),藉此,当下次具有类似需求时,即不需再进行下载。
步骤(V):3D场景客户端170将自3D场景快取190中提取3D声音S(路径192)。
步骤(VI):一下载完成(或之前早已下载)、3D场景客户端170即可提取3D声音S;3D场景客户端170将会送出一“3D sound is ready on client(3D声音已在用户装置上)”的信息至3D场景服务器120(路径113),而3D场景服务器120将会转送此信息至3D场景传输器110(路径114)。
步骤(VII):一俟3D场景传输器110接收此信息后,即会将3D声音S的状态由“Loading”改为“Ready for Client”。
步骤(VIII):在下一次的渲染中,3D场景传输器110将会知晓3D声音S现已预载于用户装置中,故将会请求3D场景客户端170自行渲染(播放),因此,服务器1即不再需要渲染此一3D声音S。
在最初始时,用户装置21、22、23中是没有任何3D模型及3D声音的,所以3D场景传输器110将会渲染所有3D模型及3D声音并将其结果编码为具立体声的2D视频串流,3D场景传输器110将会把3D模型的下载需求[Info 112-B]以及3D声音的下载需求[Info 112-E]自最近点送至3D投影面(或使用者的眼睛),3D场景客户端170将会自3D场景服务器120下载每一3D模型或3D声音,或者自3D场景快取190上一一提取;而当更多的3D模型及3D声音可为3D场景客户端170取得时,3D场景传输器110将会自动通知3D场景客户端170自行渲染这些模型及声音,并减少由3D场景传输器110渲染的3D模型及3D声音的数量,藉此,在编码过的2D视讯串流中的3D模型及3D声音会越来越少,直至最后3D场景客户端170上可取得所有的3D模型及3D声音时为止,而之后,在此阶段中,仅剩不具声音的黑色屏幕,换言之,服务器1不需再传送2D视频串流至用户装置21、22、23中,且服务器1及用户装置21、22、23间的通讯带宽占用亦可大幅降低。
本发明中,一新的3D模型N出现在实景时,3D场景传输器110即会(1)通知3D场景客户端170仅渲染所有位于此新的3D模型N前的所有3D模型(相对用户眼睛言),(2)通知3D场景客户端170下载此新的3D模型N,以及(3)3D场景传输器110将会渲染此新的3D模型N及所有位于其后的所有模型并将其结果编码为一具声音的2D视频串流,之后,再将此具声音的2D视频串流传送至3D场景客户端170,于是,3D场景客户端170可在3D模型N在用户装置上备妥前,持续重制应用程序100的3D影像及声音的渲染结果。
而当一新的3D声音T出现在实景时,3D场景传输器110即会(1)通知3D场景客户端170下载此新的3D声音T,以及(2)3D场景传输器110将会渲染此新的3D声音T并将其结果编码为一立体声,之后,再将此立体声与2D视频串流传送至3D场景客户端170,于是,3D场景客户端170 可在3D声音T在用户装置上备妥前,持续重制应用程序100的3D影像及声音的渲染结果。在此一程序中,仅渲染新的3D声音T,3D场景传输器110并不需再渲染其他3D声音T后方的所有3D声音,此一作法是因为声音的本质是与影像不同,影像会挡住其后影像的显示,但声音不会。
背景音乐可视为一具一预定3D位置的3D声音,为能尽早下载背景音乐,所定义的预定3D位置应越接近用户眼睛越好。
为降低服务器负载,或避免由不稳定的网络数据传递所产生的噪音,服务器可放弃视讯中所有3D声音的编码。在此情形下,3D声音仅于其下载及预存在一用户装置中后、始于用户装置上播放。
对于3D声音言,服务器1检验3D声音的状态,以决定那一个3D声音需被编码为一具立体声的2D视频串流,其编码方式为将非预存在用户装置中的3D声音编码至视频影格中;其中,当一3D声音被编码为视讯影格中的立体声时,其左右声道的音量由其位置及相对用户耳朵的速度所决定;其中,背景音乐可定义为一预定位置上的3D音效。
图3A所示为本发明通过网络传送媒体的方法一实施例的流程图;当开始通过网络传送影像时(步骤60),在一服务器上执行一应用程序产生一包含多个3D模型的虚拟3D环境(步骤61),每一3D模型均搭配一状态,该状态指示此3D模型是否预存在用户装置中。
服务器接着检验3D模型的状态(步骤62),以决定哪一个3D模型需被编码进2D视频串流影格,非预存在用户装置中的3D模型,将被编码至影格中;服务器将以某一虚拟位置(通常是3D投影面或使用者眼睛)为准,由近到远,一一检验各3D模型的状态,在检验中,当发现第一个未预存在用户装置中的3D模型时,即将此一发现的3D模型标记为一NR状态,接着,无论其后的3D模型是否预存在用户装置中,此一3D模型M及其后方的所有3D模型皆会被编码至影格中(步骤63);而当任何3D模型的位置改变时或者当排序参考用的虚拟位置改变时,即重新执行前述的检 验,且依最新的检验结果决定一3D模型是否须被编码至视讯影格中。
步骤64:在2D视频串流影格编码后,服务器即将此2D视频串流影格以及未预存在用户装置中的3D模型(亦即此具有NR状态的3D模型及其后方的所有3D模型)以一预定顺序传送至用户装置,此一预定顺序自最接近3D投影面(或使用者眼睛)的一点到最远点3D投影面的一点的顺序;一用户装置接收2D视频串流影格(步骤65),用户装置即译码自服务器传来的影格并使用此影格作为渲染预存在用户装置中但未包含于影格中的3D模型的背景,以产生一具声音的输出视频串流的混合影格(步骤66);当用户装置接收由服务器传来的3D模型时,用户装置即将此3D模型储存并随后传送一信息到服务器,通知服务器更改3D模型的状态为"现在已预存在用户装置中",之后,用户装置将服务器传来的视频串流与自行渲染结果,两者混合输出,成为新的视讯。
在步骤62中,当一新的3D模型出现在3D环境中时,无论其后方的3D模型是否预存在用户装置中,即将新的3D模型与其后方所有3D模型编码至影格中。
在步骤64中,服务器亦将未被编码至视讯串流影格中的3D模型的状态信息(或称诠释数据)传送至用户装置;用户装置于接收及检验状态信息时依下列方式进行:如果接收到的状态信息中的任何3D模型为非预存在用户装置中,则用户装置即送出一需求至服务器,以下载3D模型(步骤661),状态信息包括每一未被编码至影格中的诠译数据,每一诠译数据包括3D模型的一名称、一位置、一速度、一座向、以及一属性及每一3D模型的状态。
图3B所示为本发明通过网络传送媒体的方法另一实施例的流程图;当开始通过网络传送声音时(步骤60a),在一服务器上执行一应用程序产生一包含多个3D声音的虚拟3D环境(步骤61a),每一3D声音均搭配一状态,该状态指示此3D声音是否预存在用户装置中。
服务器接着检验3D声音的状态(步骤62a),以决定哪一个3D声音需被编码进2D视频串流影格,非预存在用户装置中的3D声音将被编码至影格中;服务器将以某一虚拟位置(通常是3D投影面或使用者眼睛)为准,由近到远,一一检验各3D声音的状态,在检验中,当发现第一个未预存在用户装置中的3D声音时,即将此一发现的3D声音标记为一NR状态。
步骤64a:在包含声音的视频串流影格编码后,服务器即将此具声音的2D视频串流影格以及未预存在用户装置中的3D声音(亦即此具有NR状态的3D声音)以一预定顺序传送至用户装置,此一预定顺序自最接近3D投影面(或使用者眼睛)的一点到最远点3D投影面的另一点的顺序;一用户装置接收包含声音的视频串流影格(步骤65a)后,用户装置即译码包含于视讯串流中的音频(亦即声音)并使用此音频作为渲染预存在用户装置中但未包含于视讯串流影格中的3D声音的背景,以产生一混合音频(步骤66a);当用户装置接收由服务器传来的3D声音时,用户装置即将此3D声音储存并随后传送一信息到服务器,通知服务器更改3D声音的状态为"现在已预存在用户装置中",之后,用户装置将服务器传来的视频串流中的音讯与自行渲染(播放)3D声音的结果,两者混合输出,成为新的音讯。
在步骤62a中,当一新的3D声音出现在3D环境中时,即行将新的3D声音编码至具声音的2D视讯串流影格中,然而,此新的3D声音并不影响其他3D声音是否被渲染,此点与前述步骤62中的3D模型不同。
在步骤64a中,服务器亦将未被编码至影格中的3D声音的状态信息传送至用户装置;用户装置于接收及检验状态信息时依下列方式进行:如果接收到的状态信息中的任何3D声音为非预存在用户装置中者,则用户装置即送出一需求至服务器,以下载3D声音(步骤661a),状态信息包括每一未被编码至影格中的诠译数据,每一诠译数据均包括3D声音的一名称、一位置、一速度、一座向、以及一属性及每一3D声音的状态。
如图4A、4B及4C所示为本发明方法如何传送视信串流及3D模型一 实施例的示意图。
如图4A所示,当初始用户装置74登入服务器上运转的应用程序70时,并未有任何3D模型预存在用户装置中,因此,服务器渲染所有的3D模型(包括一人71及其后的一房屋72),所有的3D模型应皆显示在用户装置的屏幕上,服务器将渲染结果编码为一2D视讯串流影格73,接着,将此影格73传送至用户装置74。在此阶段中,影格73包括人71及房屋72,用户装置74仅输出此一影格73,而不需渲染其他对象。
接着,如图4B所示,服务器70开始先将3D模型传送至用户装置,从最接近用户装置屏幕3D投影面的3D模型开始;在此实施例中,与房屋72比较,人71是较接近3D投影面(或使用者眼睛),因此,人71的3D模型先传送至用户装置74,一人71的3D模型传送并储存在用户装置74上后,用户装置74即传送一信息至服务器70,以告知人71的3D模型现已预存在用户装置74中;之后,服务器70渲染房屋72、编码其渲染结果为一2D视讯串流影格73a,传送此影格73a与人71a的诠译数据至用户装置74,用户装置74随即自动利用诠译数据渲染人,再结合人的渲染结果与影格73a(包含房屋),以获得相同的输出结果;此程序(例如服务器以一次一个的方式将3D模型传送至用户装置74)将一再重复,直到所有客户端需要显示的3D模型,都已被传送及预存在用户装置中74时为止。
如图4C所示,一用户装置74拥有所有的3D模型(包括人与房屋的3D模型),服务器不需再进行渲染操作,亦不需再传送视讯串流影格(组件75);服务器仅需传送3D模型的诠译数据(包含人71a及房屋72a)至用户装置74。用户装置将可自行渲染所有3D模型,以获得相同输出结果。
如图6A、6B及6C所示为本发明方法如何传送具声音的视讯串流及3D声音一实施例的示意图。
如图6A所示,当初始用户装置74登入服务器上运转的应用程序70时,并未有任何3D声音预存在用户装置中,因此,服务器渲染所有的3D 声音(包括一声音81及其后的一声音82),所有的3D声音应皆呈现在用户装置的扬声器上,服务器将渲染结果编码为一具声音的视信串流影格83,接着,将此具声音的视信串流影格83传送至用户装置74。在此阶段中,具声音的视信串流影格83包括声音81及声音82,用户装置74仅输出此一具声音的视讯串流影格83,而不需渲染(播放)其他声音。
接着,如图6B所示,服务器70开始先将3D声音传送至用户装置,从最接近用户装置屏幕3D投影面的3D声音开始;在此实施例中,与声音82比较,声音81是较接近3D投影面(或使用者眼睛),因此,声音81的3D声音先传送至用户装置74,一声音81的3D声音传送并储存在用户装置74上后,用户装置74即传送一信息至服务器70,以告知声音81现已预存在用户装置74中;之后,服务器70渲染声音82,编码其渲染结果为一具声音的2D视信串流影格83a,传送此影格83a以及声音81的诠译数据至用户装置74,用户装置74随即自动利用诠译数据渲染(播放)声音,再结合声音的渲染结果与影格83a(包含声音),以获得相同的输出结果;此程序(例如服务器以一次一个的方式将3D声音传送至用户装置74)将一再重复,直到所有需要在用户装置的扬声器上播放的3D声音,都已被传送及预存在用户装置中74时为止。
如图6C所示,一用户装置74拥有所有的3D声音(包括声音81与声音82的3D声音),服务器不需再进行渲染操作,也因此视讯串流影格(组件85)仅包括影像而不包括声音;服务器仅需传送3D声音81的诠译数据(包含声音81a及声音82a)至用户装置74。用户接着将可自行渲染(播放)所有3D声音,以获得相同输出结果。
如图5A、5B及5C所示为本发明方法如何决定哪个3D模型须被编码至影格一实施例的示意图。
在本发明中,服务器将所有要被渲染的3D模型依一预定顺序排序,此预定顺序为:相对一虚拟位置(如用户装置屏幕的3D投影面52、或使用 者眼睛51)从近到远的顺序。如图5A所示,四个对象A、B、C及D需显示于用户装置的屏幕上,其中对象A最接近投影面52,然后依次为对象B、对象C及对象D,当初始用户装置登入服务器上运转的应用程序时,并未有任何3D声音预存在用户装置中,因此,服务器渲染所有的对象A、对象B、对象C及对象D,将渲染结果编码为一视讯串流影格,再将此影格传送至用户装置。同时,服务器开始一一依预定顺序将对象A、对象B、对象C及对象D等3D模型传送出,亦即,对象A的3D模型会先被传送,然后依次是对象B、对象C及对象D,直至显示于用户装置上的所有3D模型皆被传送完为止。
如图5B所示,在对象A及B的3D模型皆预存在用户装置中后,当服务器依前述从近到远的预定顺序检验3D模型的状态时,服务器将会发现对象C是第一个未预存在用户装置中的对象,因此,服务器会将对象C及位于对象C后的所有其他对象(如对象D)渲染,无论对象D的3D模型是否预存在用户装置中,而此时,服务器不会对对象A及B的3D模型进行渲染,而之所以如此,是因为此时对象A及B既是预存在用户装置中又是位于该对象C之前。
如图5C所示,当一新的对象E显示在应用程序创造的虚拟3D环境中时,对象E及其后的所有对象皆会为服务器所渲染,无论此对象是否预存在用户装置中,例如,如图5C所示,与对象B、对象C及对象D比较,新的对象E相对较接近3D投影面52,虽然对象B的3D模型已预存在用户装置中,但因对象B示位于新的对象E之后,故服务器会对所有的对象E、C、B及D进行渲染,即使对象B可能仅部分为其前面的其他对象所覆盖。
如图7A、7B及7C所示为本发明方法如何决定哪个3D声音须被编码至具声音的视讯串流影格一实施例的示意图。
在本发明中,服务器将所有要被渲染的3D声音依一预定顺序排序, 此预定顺序为:相对一虚拟位置(如用户装置屏幕的3D投影面52、或使用者眼睛51)、从近到远的顺序。如图7A所示,四个3D声音A、B、C及D需于用户装置的扬声器上播放,其中声音A最接近投影面52,然后依次为声音B、声音C及声音D,当初始用户装置登入服务器上运转的应用程序时,并未有任何3D声音预存在用户装置中,因此,服务器渲染所有的声音A、声音B、声音C及声音D,将渲染结果编码为一具声音的视讯串流影格,再将此影格传送至用户装置。同时,服务器开始一一依预定顺序将声音A、声音B、声音C及声音D的数据传送出,亦即,声音A的3D声音会先被传送,然后依次是声音B、声音C及声音D,直至所有3D声音皆储存入用户装置后为止。
如图7B所示,在声音A及B的3D声音皆预存在用户装置中后,当服务器依前述从近到远的预定顺序检验3D声音的状态时,服务器将会发现声音C是第一个未预存在用户装置中的声音,因此,服务器会将声音C及位于声音C后的所有其他声音(如声音D)渲染,而服务器不会对声音A及B的3D声音进行渲染,因在此阶段中,声音A及B已预存在用户装置中。
如图7C所示,当一新的声音E加入至应用程序所创造的虚拟3D环境中时,声音E将会为服务器所渲染,但此渲染将不会影响到其他声音的渲染,此与处理图5C中的3D模型不同,如图7C所示,与声音B、声音C及声音D比较,新的声音E相对较接近3D投影面52,不似图5C中的3D模型,预存在用户装置中的声音(如声音A及B)仍会为用户装置所渲染,但非预存在用户装置的声音(如声音E、C及D)则为服务器所渲染。
本发明上述的技术也可被运用于虚拟现实(Virtual-Reality;简称VR)场景系统,来将服务器所执行的VR场景应用程序所产生的3D模型及VR视频串流通过网络传送给用户装置,以下将详述。
为了为人眼提供一个VR的视觉感受,虚拟的VR场景必须包含一个 专供人类左眼观赏的影像、以及另一专供人类右眼观赏的影像。如图8所示为本发明的VR场景系统的系统架构一第一实施例的示意图。
本发明中的场景服务器1120是一个执行于一具有VR场景应用程序1100(也简称为VR应用程序或应用程序)的服务器1上的服务器计算机软件,用以产生包含有多个3D模型的一虚拟VR 3D环境。VR场景应用程序1100也是于服务器1上运转,通常为一VR游戏。VR场景服务器1120为一与应用程序1100共同于服务器1上执行的一服务器程序,作为服务器1的VR场景传输器1110与用户装置21、22、23的VR场景客户端1170间信息传递的中继站。VR场景服务器1120同时亦作为一文件下载服务器,供用户装置21、22、23的VR场景客户端1170自服务器1下载必要的3D模型。VR场景传输器1110为一链接库(library),于VR场景应用程序1100在编译时期与的静态链接,或于VR场景应用程序1100执行期间与的动态链接。VR场景客户端(程序)1170则是一于用户装置21、22、23上执行的程序,用以在用户装置内产生并输出由VR场景应用程序1100生成的3D影像渲染结果。在此实施例中,对每一用户装置21、22、23而言,其皆对应有独立的VR场景应用程序1100及VR场景传输器1110。VR场景传输器1110存储有一个清单,列出所有3D模型以及各个3D模型是否已被储存在用户装置的状态,此状态用以指明每一个3D模型在用户装置中的状态为(1)“Not Ready(未备妥)”、(2)“Loading(下载中)”、及(3)“Ready for Client(用户已下载)”之一。
服务器1会检查这些3D模型状态,以决定哪些3D模型需被编码在一2D视讯串流的一左眼影格,而哪些3D模型需被编码在该2D视频串流的一右眼影格,于本发明中,那些没有被预先储存在用户装置21、22、23中的3D模型都会被编码在该左眼影格及右眼影格中。为了达到此功能,VR场景应用程序1100的主程序通过API呼叫链接库的方式(图8的路径1101)将VR场景信息传送至VR场景传输器1110,此VR场景信息包括名 称、位置、速度、属性、座向及所有其他3D模型渲染所需的数据。在VR场景传输器1110接收此类数据后,即可执行下列程序。
步骤(a):对所有3D模型而言,将左眼影格中所有需渲染的3D模型排序,其排序方式可为相对一虚拟位置(如3D投影面或使用者的左眼睛)从近到远排序。
步骤(b):对于3D模型言,从最近点(最接近使用者的左眼睛者)寻找第一个不具有“Ready for Client”状态的3D模型“M”,换言之,第一个3D模型“M”的状态为"Not Ready"状态,(在此之后,"Not Ready"状态简称为NR状态);当然,也可能并无此类的3D模型存在(例如所有将被显示的3D模型皆被标示为“Ready for Client”状态)。
步骤(c):对于3D模型言,由服务器1来渲染3D模型M及其后所有的3D模型,也就是所有比M距离左眼睛更远的3D模型。(如果没有3D模型M,则以一黑屏幕显示),编码渲染后的结果为一2D视频串流的左眼影格(frame),提供给使用者的左眼观看。
步骤(d):针对右眼影格来重述上述的步骤(a)至(c),也就是把上述步骤(a)至(c)中所述的左眼睛的操作都改为右眼睛,藉此产生另一2D视频串流的另一影格也就是右眼影格,提供给使用者的右眼观看。
步骤(e):为左眼影格传送下列三个信息至VR场景服务器1120(路径1112):[Info 1112-A]、[Info 1112-B]及[Info 1112-C],以及,为右眼影格传送下列三个信息至VR场景服务器1120(路径1113):[Info 1113-A]、[Info 1113-B]及[Info 1113-C]。
步骤(f):VR场景服务器1120中的数据封包器121会把左、右两眼的信息([Info 1112-A]、[Info 1112-B]、[Info 1112-C]、[Info 1113-A]、[Info 1113-B]及[Info 1113-C])打包成一个信息封包。
步骤(g):VR场景服务器1120会将步骤(f)中产生的信息封包传送至用户装置21、22、23中的VR场景客户端1170(路径1122)。
[Info 1112-A]为3D模型M前所有3D模型的状态信息(或称诠释数据)。注意可能无此类的模型存在。此类模型皆具有“Ready for Client”状态,意味着这些模型已经预载于用户装置,用户装置21、22、23上面的VR场景客户端(程序)1170已经可以自行渲染这些模型。为了减少数据传输带宽,VR场景传输器1110可以不必传送全部的状态信息,只要传送状态信息中,本次渲染与上次渲染的差异即可。
[Info 1112-B]如果服务器找到了3D模型M、且其在用户装置预先储存的状态为“Not Ready”时,服务器将更改其用户状态为“Loading”,并送出一3D模型M的下载指示,要求用户装置下载此3D模型M;如果用户状态已为“Loading”,则不要送出任何指示,因下载指示已送出。
[Info 1112-C]为步骤(c)中的编码后的左眼的视频串流影格,也就是左眼影格。
[Info 1113-A]、[Info 1113-B]及[Info 1113-C]基本上是分别实质相同于[Info 1112-A]、[Info 1112-B]及[Info 1112-C],只不过[Info 1113-A]、[Info 1113-B]及[Info 1113-C]是关于右眼影格。
当每次VR场景应用程序1100的主程序将新的VR场景数据更新至VR场景传输器1110时,重复步骤(a)~(g),通常,VR场景应用程序1100的主程序会在每一次的渲染周期中更新此类数据。
一VR场景客户端1170接收前述数据后,即进行后述的渲染程序。
步骤(i):解碼[Info 1112-C and Info 1113-C]中的视讯影格(包括左眼影格与右眼影格两者)并将这两影格传送给影格结合器1171。
步骤(ii):影格结合器1171将这两影格(包括左眼影格1711与右眼影格1712两者)合并成为一合并的VR影格1713(请参阅第9图),作为后续3D模型渲染的背景。
步骤(iii):在步骤(ii)编码后的合并的VR影格上渲染所有[Info 1112-A and Info 1113-A]中的3D模型。为降低网络带宽占用,VR场景客户端1170 将会储存此一[Info 1112-A and Info 1113-A]信息至内存中,因此下次VR场景传输器1110可仅传送下次渲染与本次渲染间的[Info 1112-A and Info 1113-A]状态的差异,不需要传送全部的状态信息。
步骤(iv):输出步骤(iii)中的渲染结果以作为一包含了VR场景的输出视频串流中的一渲染后的混合VR影格,也就是最终被输出的视频串流结果(路径1176)。在此实施例中,该用户装置是一眼镜或头盔造型的电子装置,其包括了分别位于使用者左眼与右眼前方的两个显示屏幕;其中,左边的屏幕用来显示供用户左眼观看的影像(影格),右边的屏幕用来显示供用户右眼观看的影像(影格)。该输出视频串流中的混合VR影格是以下述方式播放于用户装置的这两屏幕上,亦即,将该混合VR影格中每一行的左半部各像素都显示于该左眼屏幕,而该混合VR影格中每一行的右半部各像素则都显示于该右眼屏幕,以提供用户虚拟现实(VR)的视觉感受。
如果提供有[Info 1112-B]与[Info 1113-B]的状态时,表示有3D模型M需要被VR场景客户端1170准备,此时,VR场景客户端1170将依下列程序处理3D模型M。
步骤(I):搜寻VR场景快取1190(路径1174),VR场景快取1190包含之前下载及储存于用户装置21、22、23中的3D模型数据库。
步骤(II):如果VR场景快取1190中已经有3D模型M,则直接执行步骤(V)。
步骤(III):如果VR场景快取1190中没有3D模型M,则VR场景客户端1170将会送出一下载需求至VR场景服务器1120(路径1172),VR场景服务器1120将会回传3D模型M的数据给VR场景客户端1170(路径1124)。
步骤(IV):一3D模型完全下载后,VR场景客户端1170即将其存入VR场景快取1190(路径1194),藉此,当下次具有类似需求时,即不需再 进行下载。
步骤(V):VR场景客户端1170将会自VR场景快取1190中,提取3D模型M(路径1192)。
步骤(VI):一下载完成(或之前早已下载),VR场景客户端1170即可提取3D模型M;VR场景客户端1170将会送出一“3D model is ready on client(3D模型已在用户装置上)”的信息至VR场景服务器1120(路径1115),VR场景服务器1120将会转送此信息至VR场景传输器1110(路径1114)。
步骤(VII):一VR场景传输器1110接收此信息后,即会将3D模型M的状态由“Loading”改为“Ready for Client”。
步骤(VIII):在下一次的渲染中,VR场景传输器1110将会知晓3D模型M现已预载于用户装置中,故将会请VR场景客户端1170自行渲染,因此,服务器1将不再需要渲染此一3D模型M。
在最初始时,用户装置21、22、23中是没有任何3D模型的,所以VR场景传输器1110将会渲染所有3D模型并将其结果编码为包括左眼影格与右眼影格的2D视频串流。VR场景传输器1110将会把3D模型的下载需求[Info 1112-B]及[Info 1113-B],从最接近3D投影面(或使用者的左眼或右眼)者开始处理。VR场景客户端1170将会自VR场景服务器1120下载每一3D模型,或者自VR场景快取1190上一一提取。而当更多的3D模型可由VR场景客户端1170取得时,VR场景传输器1110将会自动通知VR场景客户端1170自行渲染这些模型及声音,并减少由VR场景传输器1110渲染的3D模型的数量。藉此,在编码过的具有左眼影格与右眼影格的2D视讯串流中的3D模型会越来越少,直至最后VR场景客户端1170上可取得所有的3D模型时为止;而之后,在此阶段中,仅剩黑色屏幕是由服务器1来编码,换言之,服务器1不需再传送2D视频串流至用户装置21、22、23中,且服务器1及用户装置21、22、23间的通讯带宽占用亦可大幅降低。
一新的3D模型N出现在VR场景时,VR场景传输器1110即会(1)通知VR场景客户端1170仅渲染所有位于此新的3D模型N前的所有3D模型(相对用户的左眼或右眼而言),(2)通知VR场景客户端1170下载此新的3D模型N,以及(3)VR场景传输器1110将会渲染此新的3D模型N及所有位于其后的所有模型、并将其结果编码为一包含左眼影格与右眼影格的2D视频串流。之后,再将此包含左眼影格与右眼影格的2D视频串流传送至VR场景客户端1170。于是,VR场景客户端1170仍可在3D模型N于用户装置上备妥前持续重制VR场景应用程序1100的3D影像渲染结果。
图10为本发明的VR场景系统的系统架构的第二实施例的示意图。于图10所示的第二实施例中,大部分组件与功能实质上是相同或类似于图8所的第一实施例,唯独其影格结合器1111是位于VR场景传输器1110中,而非位于VR场景客户端1170;也因此,图10中相同或类似的组件将会被给予和图8相同的编号,且不赘述其细节。
如图10所示,VR场景应用程序1100的主程序通过API呼叫链接库的方式将VR场景信息传送至VR场景传输器1110,此VR场景信息包括名称、位置、速度、属性、座向及所有其他3D模型渲染所需的数据。在VR场景传输器1110接收此类数据后,即可执行下列程序。
步骤(a):对所有3D模型而言,将左眼影格中所有需渲染的3D模型排序,其排序方式可为相对一虚拟位置(如3D投影面或使用者的左眼睛)从近到远排序。
步骤(b):对于3D模型言,从最近点(最接近使用者的左眼睛者)寻找第一个不具有“Ready for Client”状态的3D模型“M”,换言之,第一个3D模型“M”的状态为"Not Ready"状态,(在此之后,"Not Ready"状态简称为NR状态);当然,也可能并无此类的3D模型存在。
步骤(c):在服务器1中把3D模型“M”及所有后续的3D模型都进行渲染(倘若不存在所述的3D模型“M”时,则直接产生一黑屏幕)然后储存在 内存中。
步骤(d):针对右眼影格来重述上述的步骤(a)至(c),也就是把上述步骤(a)至(c)中所述的左眼睛的操作都改为右眼睛,藉此产生一右眼影格,提供给使用者的右眼观看。
步骤(e):由影格结合器1111将已渲染的左眼影格与右眼影格合并成为一2D视频串流中的一合并的VR影格。
步骤(e):为左眼影格与右眼影格传送下列三个信息至VR场景服务器1120(路径1112):[Info 1112-A]、[Info 1112-B]及[Info 1112-C],然后,VR场景服务器1120会再将其传送至用户装置21、22、23中的VR场景客户端1170(路径1122)。
[Info 1112-A]为3D模型M前所有3D模型的状态信息(或称诠释数据)。注意可能无此类的模型存在。此类模型皆具有“Ready for Client”状态,意味着这些模型已经预载于用户装置,用户装置21,22,23上面的VR场景客户端(程序)1170已经可以自行渲染这些模型。为了减少数据传输带宽,VR场景传输器1110可以不必传送全部的状态信息,只要传送状态信息中,本次渲染与上次渲染的差异即可。
[Info 1112-B]如果服务器找到了3D模型M、且其在用户装置预先储存的状态为“Not Ready”时,服务器将更改其用户状态为“Loading”,并送出一3D模型M的下载指示,要求用户装置下载此3D模型M;如果用户状态已为“Loading”,则不要送出任何指示,因下载指示已送出。
[Info 1112-C]为步骤(e)中的已渲染且包含了左眼影格与右眼影格的视频串流影格中的合并的VR影格。
一VR场景客户端1170接收前述数据后,即进行后述的渲染程序。
步骤(i):解码[Info 1112-C]中的合并的VR影格并将其作为后续3D模型渲染时的背景。
步骤(ii):在该合并的VR影格上渲染所有[Info 1112-A]中的3D模型。 为降低网络带宽占用,VR场景客户端1170将会储存此一[Info 1112-A]信息至内存中,因此下次VR场景传输器1110可仅传送下次渲染与本次渲染间的[Info 1112-A]状态的差异,不需要传送全部的状态信息
步骤(iii):输出步骤(ii)中的渲染结果以作为一包含了VR场景的输出视频串流中的一渲染后的混合VR影格,也就是最终被输出的视频串流结果(路径1176)。
图11为本发明的VR场景系统的系统架构的第三实施例的示意图。于图11所示的第三实施例中,大部分组件与功能实质上是相同或类似于图8的第一实施例,只是此第三实施例已不再具有影格结合器;也因此,图11中相同或类似的组件将会被给予和图8相同的编号,且不赘述其细节。
如图11所示,VR场景服务器1120是一个执行于一具有VR场景应用程序1100的服务器1上的服务器计算机软件,用以产生包含有多个3D模型的一虚拟VR 3D环境。VR场景服务器1120为一与应用程序1100共同于服务器1上执行的一服务器程序,作为服务器1的VR场景传输器1110与用户装置21、22、23的VR场景客户端1170间信息传递的中继站。VR场景服务器1120同时亦作为一文件下载服务器,供用户装置21、22、23的VR场景客户端1170自服务器1下载必要的3D模型。VR场景传输器1110存储有一个清单,列出所有3D模型以及各个3D模型是否已被储存在用户装置的状态,此状态用以指明每一个3D模型在用户装置中的状态为(1)“Not Ready(未备妥)”、(2)“Loading(下载中)”、及(3)“Ready for Client(用户已下载)”之一。
服务器1会检查这些这些3D模型的该状态,以决定哪些3D模型需被编码在一2D视讯串流的一左眼影格,而哪些3D模型需被编码在该2D视频串流的一右眼影格,于本发明中,那些没有被预先储存在用户装置21、22、23中的3D模型都会被编码在该左眼影格及右眼影格中。为了达到此功能,VR场景应用程序1100的主程序通过API呼叫链接库的方式(图11 的路径1101)将VR场景信息传送至VR场景传输器1110,此VR场景信息包括名称、位置、速度、属性、座向及所有其他3D模型渲染所需的数据。在VR场景传输器1110接收此类数据后,即可执行下列程序。
步骤(a):对所有3D模型而言,将左眼影格中所有需渲染的3D模型排序,其排序方式可为相对一虚拟位置(如3D投影面或使用者的左眼睛)从近到远排序。
步骤(b):对于3D模型言,从最近点(最接近使用者的左眼睛者)寻找第一个不具有“Ready for Client”状态的3D模型“M”,换言之,第一个3D模型“M”的状态为"Not Ready"状态,(在此之后,"Not Ready"状态简称为NR状态);当然,也可能并无此类的3D模型存在(例如所有将被显示的3D模型皆被标示为“Ready for Client”状态)。
步骤(c):对于3D模型言,由服务器1来渲染3D模型M及其后所有的3D模型,也就是所有比M距离左眼睛更远的3D模型。(如果没有3D模型M,则以一黑屏幕显示),编码渲染后的结果为一2D视频串流的一左眼影格(frame),提供给使用者的左眼观看。
步骤(d):针对右眼影格来重述上述的步骤(a)至(c),也就是把上述步骤(a)至(c)中所述的左眼睛的操作都改为右眼睛,藉此产生另一2D视频串流的另一影格也就是右眼影格,提供给使用者的右眼观看。
步骤(e):为左眼影格传送下列三个信息至VR场景服务器1120(路径1112):[Info 1112-A]、[Info 1112-B]及[Info 1112-C],以及,为右眼影格传送下列三个信息至VR场景服务器1120(路径1113):[Info 1113-A]、[Info 1113-B]及[Info 1113-C]。
步骤(f):VR场景服务器1120中的数据封包器121会把左、右两眼的信息([Info 1112-A]、[Info 1112-B]、[Info 1112-C]、[Info 1113-A]、[Info 1113-B]及[Info 1113-C])打包成一个信息封包。
步骤(g):VR场景服务器1120会将步骤(f)中产生的信息封包传送至用 户装置21、22、23中的VR场景客户端1170(路径1122)。
[Info 1112-A]为3D模型M前所有3D模型的状态信息(或称诠释数据)。注意可能无此类的模型存在。此类模型皆具有“Ready for Client”状态,意味着这些模型已经预载于用户装置,用户装置21,22,23上面的VR场景客户端(程序)1170已经可以自行渲染这些模型。为了减少数据传输带宽,VR场景传输器1110可以不必传送全部的状态信息,只要传送状态信息中,本次渲染与上次渲染的差异即可。
[Info 1112-B]如果服务器找到了3D模型M、且其在用户装置预先储存的状态为“Not Ready”时,服务器将更改其用户状态为“Loading”,并送出一3D模型M的下载指示,要求用户装置下载此3D模型M;如果用户状态已为“Loading”,则不要送出任何指示,因下载指示已送出。
[Info 1112-C]为步骤(c)中的编码后的左眼的视频串流影格,也就是左眼影格。
[Info 1113-A]、[Info 1113-B]及[Info 1113-C]基本上是分别实质相同于[Info 1112-A]、[Info 1112-B]及[Info 1112-C],只不过[Info 1113-A]、[Info 1113-B]及[Info 1113-C]是关于右眼影格。
当每次VR场景应用程序1100的主程序将新的VR场景数据更新至VR场景传输器1110时,重复步骤(a)~(g),通常,VR场景应用程序1100的主程序会在每一次的渲染周期中更新此类数据。
一俟VR场景客户端1170接收前述数据后,即进行后述的渲染程序。
步骤(i):解码[Info 1112-C and Info 1113-C]中的视讯影格(包括左眼影格与右眼影格两者)并将这两影格储存于不同的内存空间。
步骤(ii):在解码后的左眼影格与右眼影格上分别渲染所有[Info 1112-A and Info 1113-A]中所包含的3D模型(如果此3D模型存在的话)。为降低网络带宽占用,VR场景客户端1170将会储存此一[Info 1112-A and Info 1113-A]信息至内存中,因此下次VR场景传输器1110可仅传送下次 渲染与本次渲染间的[Info 1112-A and Info 1113-A]状态的差异,不需要传送全部的状态信息。
步骤(iii):输出步骤(ii)中的渲染结果以作为一包含了VR场景的输出视频串流中的渲染后的一混合左眼影格与一混合右眼影格,也就是最终被输出的视频串流结果(路径1176)。其中,所述的混合左眼影格与混合右眼影格,可合并被称为如先前曾提及的混合VR影格。
于此实施例中,该用户装置是一眼镜或头盔造型的电子装置,其包括了分别位于使用者左眼与右眼前方的两个显示屏幕;其中,左边的屏幕用来显示供用户左眼观看的影像(影格),右边的屏幕用来显示供用户右眼观看的影像(影格)。该输出视频串流中的混合VR影格是以下述方式播放于用户装置的这两屏幕上,亦即,将该混合VR影格中的每一个混合左眼影格都显示于该左眼屏幕,而该混合VR影格中每一个混合右眼影格则都显示于该右眼屏幕,以提供用户虚拟现实(VR)的视觉感受。
而在另一实施例中,于用户装置的一屏幕上所输出的视频串流是在同一屏幕上依序轮流显示该混合左眼影格与该混合右眼影格。用户可配戴一眼镜造型的电子装置,其可以对应于该屏幕上所显示的混合左眼影格与该混合右眼影格来依序轮流开启与关闭其左眼窗口与右眼窗口,以提供用户虚拟现实(VR)的视觉感受。
以上所述的实施例不应用于限制本发明的可应用范围,本发明的保护范围应以本发明的权利要求范围内容所界定技术精神及其均等变化所含括的范围为主。即大凡依本发明权利要求范围所做的均等变化及修饰,仍将不失本发明的要义所在,亦不脱离本发明的精神和范围,故都应视为本发明的进一步实施状况。
- 还没有人留言评论。精彩留言会获得点赞!