混合网络流调度方法和交换机与流程
本发明涉及通信领域,尤其涉及混合网络流调度方法和交换机。
背景技术:
云应用向数据中心网络(DCN,Datacenter Network)注入网络流。所述网络流可以分为三类。
类型1:有截止时间的网络流。有一些应用,例如网络搜索、推荐和广告等,生成的网络流通常都是有截止时间的。这些有截止时间的网络流的大小通常也是容易提前获取的。对这些应用而言,延迟会影响其用户体验,因此,这些应用对网络流都会设定一些延迟条件,例如截止时间。对于只包含这一类网络流的流量,基于EDF(Earliest Deadline First,最早截止时间优先)的算法(例如,给截止时间早的网络流更高优先级的pFabric,和利用剩余期限作为网络流的临界的PDQ)是用来最小化截止时间错过率最常见的算法。
类型2:无截止时间但大小已知的网络流。有一些应用,例如虚拟机迁移(VM-migration)、数据备份等,生成的网络流没有延迟条件。这些网络流的大小通常在传输前就已经知道。这一类网络流虽然没有截止时间,但也都希望能够早点完成。对于只包含这一类网络流的流量,基于SJF(Shortest Job First,最短任务优先)的算法(例如,给更小的网络流更高优先级的PASE和pFabric,和利用剩余期限作为网络流的临界的PDQ)是用来最小化平均FCT(Flow Completion Time,网络流完成时间)最常见的方法。
类型3:无截止时间且大小未知的网络流。其他的网络流可以被归于这一类。有很多应用无法在网络流开始的时候就提供大小/截止时间信息(例如:数据库查询响应和HTTP分块传输。对于只包含这一类网络流的流量,最常见的方法是尽力而为算法(例如DCTCP)。近来,PIAS在不知道网络流大小的情况下模仿SJF实现了比DCTCP更优的FCT。
以上三种类型的网络流是共存于数据中心网络(DCN)中的。而如何调度这些混合网络流是一个很重要的问题。虽然针对每一种类型的网络流都有已知的调度算法(基于SJF或者EDF),但罕见能够处理混合网络流的算法。已经被提出的这些算法要么注重最大化有截止时间的网络流在截止时间前的完成率,要么注重最小化无截止时间的网络流的FCT(Flow Completion Time,网络流完成时间),然而它们并没有同时将这两方面都考虑进来。更糟的是,如果只是简单地将现有的调度算法进行合并,其效果也并不好。比如说,针对有截止时间的网络流的调度策略为了让有截止时间的网络流能够在其截止时间前完成,可能会过于激进的占据所有带宽,从而影响到无截止时间网络流的FCT。例如pFabric或者基于EDF(Earliest Deadline First,最早截止时间优先)的调度算法,它们不适合应用于混合网络流调度的主要原因就是他们会激进地为有截止时间的网络流抢占带宽从而影响到那些无截止时间的网络流。pFabric令有截止时间的网络流的优先级高于无截止时间的网络流。因此,有截止时间的网络流会激进地占据所有的带宽很快地完成(早于其截止时间很多就完成,这是不必要的)。而相应的代价是增加了短的无截止时间网络流的FCT。网络中有截止时间的流越多,这个问题就越严重。
为了更加清楚的表示仅仅使用基于临界的调度算法(SJF或EDF)会影响混合网络流中不同类型网络流的表现,下面将用ns-3实验数据进行说明。实验中发送端和接收端通过交换机连接,所述服务器的输出容量为1Gbps。实验中还使用DCTCP在端主机处进行速率控制。
图1示出仅使用SJF算法对网络流进行调度时有截止时间网络流的截止时间错过率。图1中横坐标表示在类型2网络流中比类型1网络流小的网络流所占的比例,纵坐标表示类型1网络流的截止时间错过率。由图可见,当类型1网络流比1%的类型2网络流小时,截止时间错过率为0。当所述比例来到20百分位时(13KB),所述截止时间错过率超过40%。
由此我们可以得出一个结论:仅使用SJF算法对网络流进行调度会影响到类型1网络流。这是由于SJF算法仅由网络流的大小便决定哪个网络流可以先执行,因此会阻碍类型1网络流在其截止时间前完成,特别是对那些相对大的有截止时间的网络流的影响更大。
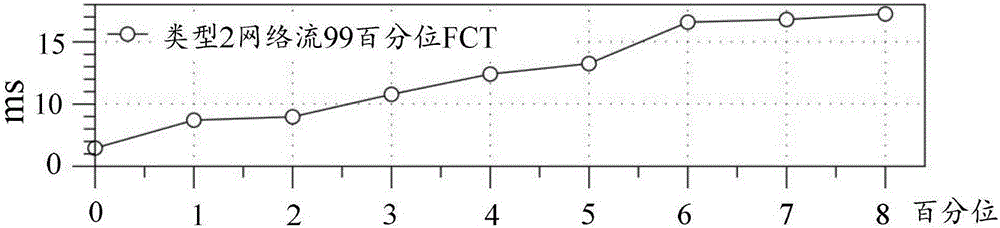
下面,将对有截止时间的网络流的调度算法改为EDF,并令类型1网络流严格拥有比类型2网络流更高的优先级。参见图2,图2中横坐标表示类型1网络流占总流量的比例,纵坐标表示类型2网络流99百分位的FCT。由图2可知,类型2网络流的尾延迟随着有截止时间的网络流在总流量中的比例增大而增大。这是因为,类型1网络流拥有比类型2网络流更高的优先级,因此类型2网络流只能使用类型1网络流剩下的带宽。由于类型1网络流通过激进的速率控制(DCTCP)激进地占据带宽,因此会影响到其他类型网络流的表现。
由此我们可以得出一个结论:对类型1网络流使用EDF算法,对类型2和类型3网络流使用SJF算法也仍会影响到类型2和类型3网络流。这是因为,类型1网络流占据了所有的带宽,使其在截止时间到来之前很多就早早地完成(然而这并不需要),而代价就是增加了类型2和类型3网络流的FCT。
相关的传输协议还有很多,下面简要介绍一些。
DCTCP(Data Center Transmission Control Protocol,数据中心传输控制协议)是一种用于DCN(Data Center Network,数据中心网络)的尽力而为的传输协议,它的拥塞控制策略可以很好的与ECN结合。DCTCP是截止时间不知晓的,并且由于DCTCP网络流平均共享带宽,因此它不能模拟SJF(Shortest Job First,最短作业优先调度)。
D3(Deadline-driven Delivery,截止时间驱使交付)通过贪婪算法处理有截止时间的网络流,但是会引起优先级倒置的问题,并且需要对服务器做出很大改动。具体的,它将网络流速率设为γ=M/δ加上除去所有有截止时间的网络流的需求后剩余链路带宽的平均值。然而,如图3所示,D3会出现优先级反转的问题。D3总是尽可能的为先到达的网络流分配速率。在图3(a)中,网络流C没能在其截止时间内完成,因为更早的网络流A和网络流B不肯为网络流C让出它们的带宽。而从图3(b)中可以看出,对于网络流A和网络流B,即使它们为网络流C让出带宽也并不影响它们自己在截止时间前完成。
D2TCP(Deadline-aware Datacenter TCP,截止时间知晓的数据中心传输控制协议)在DCTCP的基础上对类型1网络流增加了截止时间知晓。但D2TCP不能用来处理类型2和类型3网络流。
FCP(Flexible Control Protocol,灵活的控制协议)同样应用了D3,并且它增加了代价机制。
PDQ(Preemptive Distributed Quick flow scheduling,抢占式分布的快速流调度)和pFabric(最小接近最优的数据传输)都是基于临界的网络流调度策略,但他们可能会影响到其他无截止时间的网络流。
PASE综合了以上传输层策略,但是不能直接解决混合网络流调度的问题。并且,PASE需要网络控制层的协调速率仲裁。
PIAS(Practical Information-Agnostic flow Scheduling,实际的信息不可知网络流调度)是信息不可知的网络流调度策略,它可以不用知道网络流的大小模拟SJF(Shortest Job First,最短任务优先调度)。PIAS对大小未知的网络流有效,但是对其它的不行。PIAS将所有的网络流都当作既不知道截止时间也不知道大小的网络流进行处理,这显然对无截止时间的网络流造成影响。
除了不能很好地处理混合流的问题外,上述很多调度算法都需要对交换机进行很大程度的改动,或者设置复杂的控制面以对每个网络流设置速率,这些都使得它们在实际应用中很难实行。
总而言之,现有的调度算法不能同时满足以下三个需求:
第一,最大化有截止时间的网络流在截止时间前的完成率。
第二,最小化无截止时间的网络流的FCT。
第三,可直接适用于现售的DCN商品硬件。
技术实现要素:
本发明实施例所要解决的技术问题在于,如何在使大部分有截止时间的网络流在其截止时间之前完成的同时提升无截止时间的网络流的FCT。
为了解决上述技术问题,本发明实施例提供了一种混合网络流的调度方法,所述混合网络流包括类型1、类型2和类型3三种网络流,其中所述类型1网络流为有截止时间的网络流,所述类型2网络流为无截止时间但大小已知的网络流,所述类型3网络流为无截止时间且大小未知的网络流,所述混合网络流在链路上传输,所述链路具有带宽,所述调度方法包括:
将所述类型1网络流分配至具有最高优先级的队列中,通过公式(a)计算拥塞窗口,占用与所述拥塞窗口相对应的带宽向所述链路发送所述类型1网络流;
其中,
s表示所述类型1网络流,当前τs(t)表示在t时刻所述类型1网络流的往返时间,Ws(t)表示t时刻的拥塞窗口,Ws(t+τs(t))表示t+τs(t)时刻的拥塞窗口,L(s)表示所述链路,γs(t)表示在t时刻所述类型1网络流的期望速率,Zs(t)表示在t时刻所述类型1网络流的虚拟队列,Ms(t)表示在t时刻要完成所述类型1网络流还需要传输的剩余数据大小,δs(t)表示在t时刻所述类型1网络流距离截止时间到来还剩余的时间,∑l∈L(s)Ql(t)表示在t时刻所述链路上的总的队列长度,∑l∈L(s)λl(t)表示在t时刻所述链路的总的链路代价;
将所述类型2和类型3网络流分配至其他优先级的队列中,占用所述类型1网络流使用剩余的带宽向所述链路发送所述类型2和类型3网络流。
优选的,在t时刻的所述总的队列长度由公式(b)计算得到:
∑l∈L(s)Ql(t)≈K+Fs(t)×Ws(t) 公式(b)
其中,K为显示拥塞指示的阈值,Fs(t)表示根据距t时刻最近一个拥塞窗口发送的类型1网络流的数据包中所述显示拥塞指示有标记的数据包的比例,Ws(t)表示t时刻的拥塞窗口。
优选的,在t时刻的所述总的链路代价由公式(c)计算得到:
∑l∈L(s)λl(t)=C-(Fs(t)Ws(t)-Fs(t-τs(t))Ws(t-τs(t))-2)/τs(t) 公式(c)
其中C表示所述链路的容量,Fs(t)表示根据距t时刻最近一个拥塞窗口发送的类型1网络流的数据包中所述显示拥塞指示有标记的数据包的比例,Fs(t-τs(t))表示根据距t-τs(t)时刻最近一个拥塞窗口发送的类型1网络流的数据包中所述显示拥塞指示有标记的数据包的比例,Ws(t-τs(t))表示t-τs(t)时刻的拥塞窗口。
进一步地,当判断一个所述类型1网络流不能在其截止时间前完成时,丢弃所述一个类型1网络流。
优选的,若所述一个类型1网络流的虚拟队列的队列长度大于所述链路的容量,则判定所述一个类型1网络流不能在其截止时间前完成。
优选的,若所述一个类型1网络流的期望速率大于所述链路的容量,则判定所述一个类型1网络流不能在其截止时间前完成。
进一步地,所述将类型2和类型3网络流分配至其他优先级的队列中进一步包括:
依据分离阈值{β}对所述类型2网络流进行划分,将大小处于(βi-1,βi]之间的类型2网络流分配至优先级为i的队列中;
依据筛选阈值{α}对所述类型3网络流进行划分,将已发送的字节数处于(αi-1,αi]之间的类型3网络流分配至优先级为i的队列中;
所述i越小优先级越高。
进一步地,所述分离阈值{β}和所述筛选阈值{α}基于公式(d)、(e)、(f)计算得到:
约束条件:
其中M为所述分离阈值{β}或所述筛选阈值{α}所构成的区间的个数,F1(·)、F2(·)、F3(·)为所述三种类型网络流各自的流量分布。
进一步地,所述分离阈值{β}和所述筛选阈值{α}随网络中流量的改变而周期性地更新。
进一步地,当一个网络流经历了N个TCP超时时,提升所述一个网络流的优先级,所述N为大于1的整数。
进一步地,每一个网络流对应一个N值,所述N值按照[2,10]的平均分布随机选取。
优选的,通过以下方式提升所述一个网络流的优先级:当所述一个网络流为类型2网络流时,按照所述一个网络流的剩余数据大小重新对所述一个网络流进行划分并分配至相应的优先级队列;当所述一个网络流为类型3网络流时,将所述一个网络流移至用于类型2和类型3网络流的队列中优先级最高的队列。
相应地,本发明还提供一种交换机,所述交换机向链路发送混合网络流,所述混合网络流包括类型1、类型2和类型3三种网络流,其中所述类型1网络流为有截止时间的网络流,所述类型2网络流为大小已知的无截止时间的网络流,所述类型3网络流为大小未知的无截止时间的网络流,所述链路具有带宽,其特征在于,所述交换机包括拥塞窗口计算模块、调度模块,其中
所述拥塞窗口计算模块用于根据公式(a)计算拥塞窗口;
其中,
s表示所述类型1网络流,τs(t)表示在t时刻所述类型1网络流的往返时间,Ws(t)表示t时刻的拥塞窗口,Ws(t+τs(t))表示t+τs(t)时刻的拥塞窗口,L(s)表示所述链路,γs(t)表示在t时刻所述类型1网络流的期望速率,Zs(t)表示在t时刻所述类型1网络流的虚拟队列,Ms(t)表示在t时刻要完成所述类型1网络流还需要传输的剩余数据大小,δs(t)表示在t时刻所述类型1网络流距离截止时间到来还剩余的时间,∑l∈L(s)Ql(t)表示在t时刻所述链路上的总的队列长度,∑l∈L(s)λl(t)表示在t时刻所述链路的总的链路代价;
所述调度模块用于将类型1网络流分配至具有最高优先级的队列中,占用与所述拥塞窗口相对应的带宽向所述链路发送所述类型1网络流,同时将所述类型2和类型3网络流分配至其他优先级的队列中,占用所述类型1网络流使用剩余的带宽向所述链路发送所述类型2和类型3网络流。
进一步地,所述交换机支持显示拥塞指示,在t时刻所述总的队列长度由公式(b)计算得到:
∑l∈L(s)Ql(t)≈K+Fs(t)×Ws(t) 公式(b)
其中,K为所述显示拥塞指示的阈值,Fs(t)表示根据距t时刻最近一个拥塞窗口发送的类型1网络流的数据包中所述显示拥塞指示有标记的数据包的比例,Ws(t)表示t时刻的拥塞窗口。
进一步地,在t时刻所述总的链路代价由公式(c)计算得到:
∑l∈L(s)λl(t)=C-(Fs(t)Ws(t)-Fs(t-τs(t))Ws(t-τs(t))-2)/τs(t) 公式(c)
其中C表示所述链路的容量,Fs(t)表示根据距t时刻最近一个拥塞窗口发送的类型1网络流的数据包中所述显示拥塞指示有标记的数据包的比例,Fs(t-τs(t))表示根据距t-τs(t)时刻最近一个拥塞窗口发送的类型1网络流的数据包中所述显示拥塞指示有标记的数据包的比例,Ws(t-τs(t))表示t-τs(t)时刻的拥塞窗口。
进一步地,所述交换机还包括判断模块,所述判断模块用于判断一个类型1网络流能否在其截止时间前完成;
所述调度模块进一步用于在所述判断模块判定所述一个类型1网络流不能在其截止时间前完成时,丢弃所述一个类型1网络流。
优选的,所述判断模块在所述一个类型1网络流的虚拟队列的队列长度大于所述链路的容量时判定所述一个类型1网络流无法在其截止时间前完成。
优选的,所述判断模块在所述一个类型1网络流的期望速率大于所述链路的容量时判定所述一个类型1网络流无法在其截止时间前完成。
进一步地,所述交换机还包括阈值计算模块,所述阈值计算模块用于根据公式(d)、(e)、(f)计算分离阈值{β}和筛选阈值{α};
约束条件:
其中M表示所述分离阈值{β}或所述筛选阈值{α}所构成的区间的个数,F1(·)、F2(·)、F3(·)为所述三种类型网络流各自的流量分布;
所述调度模块进一步用于依据所述分离阈值{β}对所述类型2网络流进行划分,将大小处于(βi-1,βi]之间的类型2网络流分配至优先级为i的队列中,依据筛选阈值{α}对所述类型3网络流进行划分,将已发送的字节数处于(αi-1,αi]之间的类型3网络流分配至优先级为i的队列中,所述i越小优先级越高。
优选的,所述阈值计算模块随网络中流量的改变而周期性地计算所述分离阈值{β}和所述筛选阈值{α}。
进一步地,所述交换机还包括N值选取模块,所述N值选取模块用于为每个网络流按照[2,10]的平均分布随机选取一个N值,所N为大于1的整数;
所述调度模块进一步还用于在一个网络流经历了N个TCP超时时,提升所述一个网络流的优先级。
优选的,所述调度模块通过以下方式提升所述一个网络流的优先级:当所述一个网络流为类型2网络流时,按照所述一个网络流的剩余数据大小重新对所述一个网络流进行划分并分配至相应的优先级队列;当所述一个网络流为类型3网络流时,将所述一个网络流移至用于类型2和类型3网络流的队列中优先级最高的队列。
进一步地,所述交换机还包括信息添加模块,所述信息添加模块用于在所述交换机发送的每个类型1网络流的所述数据包中添加所述交换机处的队列长度和链路代价。
进一步地,所述交换机还包括信息传递模块,所述信息传递模块通过发送套接字并利用setsockopt设置每个数据包的mark将所述网络流的信息传递至内核空间网络堆栈。
实施本发明实施例,具有如下有益效果:
1、本发明可以系统地处理混合网络流,能够使很大程度地保证有截止时间的网络流在其截止时间之前完成,同时减小无截止时间的网络流的FCT。
2、而本发明只需要网络ECN(Explicit Congestion Notification,显示拥塞指示)的支持,不需要对交换机进行硬件改动,也无需设置复杂的控制面以对各个网络流分别设置速率。
附图说明
图1是仅使用SJF算法对网络流进行调度时有截止时间网络流的截止时间错过率;
图2是使用EDF算法进行调度对有截止时间网络流的完成率的影响的示意图;
图3是现有技术D3和最优情况下的对比图;
图4是本发明一个实施例的示意图;
图5是本发明另一个实施例的示意图;
图6是用于估计队列长度的示意图;
图7是本发明实施例与现有技术DCTCP和pFabric的性能对比图;
图8是本发明实施例与DCTCP的性能对比图;
图9是三种网流的放弃方案的性能对比图;
图10是ECN的效果的示意图;
图11是队列数量对类型2和类型3网络流FCT的影响的示意图
图12是脊柱-叶子拓扑结构示意图;
图13是不同工作负载的示意图;
图14是本发明实施例与现有技术D3、D2TCP和是pFabric的性能对比图;
图15是本发明实施例中网络流时效对抗饥饿的效果示意图;
图16是不同阈值用于不同类型的工作负载产生的场景示意图;
图17是类型2网络流在不同场景中平均FCT的对比图;
图18是本发明实施例在瓶颈链路下的性能示意图。
具体实施方式
为使本发明的目的、技术方案和优点更加清楚,下面将结合附图对本发明作进一步地详细描述。
面向用户的数据中心应用(如网页搜索,社交网络,零售,推荐系统等)对延迟具有严苛的要求。由这些应用生成的长短不一的网络流都具有严格的截止时间,那些没能在截止时间内完成的网络流将被直接从结果中删除。而这既影响用户体验,又浪费带宽,同时也造成供应商的收入减少。很多现今的数据中心传输协议都是在互联网刚出现时制定的,如TCP(Transmission Control Protocol,传输控制协议),他们并没有对有关截止时间的部分进行明确的规定,因此他们的表现在目前看来很多都不够理想。有资料显示,在TCP协议下,很大一部分网络流(7%至25%以上不等)都没能在截止时间内完成。
而与此同时,其他应用的网络流的需求也有所不同。例如:并行计算应用、虚拟机迁移以及数据备份,它们并不给网络流指定具体的截止时间,但也是希望所述网络流能够尽早完成。
因此,需要一种能够系统地解决混合网络流问题的方法。所述方法能够使最大程度地保证有截止时间的网络流在其截止时间之前完成,同时能够减小无截止时间的网络流的FCT。
处理混合网络流的核心在于使有截止时间的网络流在其截止时间前完成,同时让无截止时间的网络流尽快地完成。因此,类型1网络流应该尽量少地占用带宽,只要类型1网络流能够刚刚好在截止时间前完成即可,从而最大程度地给类型2和类型3网络流让出带宽以优化他们的FCT。
如图4所示,在本发明的一个实施例中,本发明调度方法首先将所述类型1网络流分配至具有最高优先级的队列中,通过公式(a)计算拥塞窗口,占用与所述拥塞窗口相对应的带宽向所述链路发送所述类型1网络流;然后将所述类型2和类型3网络流分配至其他优先级的队列中,占用所述类型1网络流使用剩余的带宽向所述链路发送所述类型2和类型3网络流;
其中,
s表示所述类型1网络流τs(t)表示在t时刻所述类型1网络流的往返时间,Ws(t)表示t时刻的拥塞窗口,Ws(t+τs(t))表示t+τs(t)时刻的拥塞窗口,L(s)表示所述链路,γs(t)表示在t时刻所述类型1网络流的期望速率,Zs(t)表示在t时刻所述类型1网络流的虚拟队列,Ms(t)表示在t时刻要完成所述类型1网络流还需要传输的剩余数据大小,δs(t)表示在t时刻所述类型1网络流距离截止时间到来还剩余的时间,∑l∈L(s)Ql(t)表示在t时刻所述链路上的总的队列长度,∑l∈L(s)λl(t)表示在t时刻所述链路的总的链路代价。
在该实施例中,类型1网络流被分配至最高优先级的队列,而类型2和类型3网络流被分配至其他相对较低的优先级队列中,即所述类型1网络流的优先级要高于所述类型2和类型3网络流。除此之外,所述类型2和类型3网络流使用的是类型1网络流使用剩余的带宽。因此,本发明实施例可以防止类型1网络流被激进的类型2或类型3网络流抢去带宽。
其次,本发明实施例通过拥塞窗口更新方程,即公式(a),控制类型1网络流的发送速率,使得类型1网络流尽可能地在其截止时间前完成的同时能够让出更多的带宽给类型2和类型3网络流。
具体的,上述公式(a)中的第一项(源):Θ(γs(t),xs(t))是网络流期望速率γs(t)的增函数,γs(t)=Ms(t)/δs(t)。一个网络流的γs(t)值越大说明这个网络流越紧急,即它剩余要传的数据还很多和/或它的截止时间马上就要到了。这一项保证了越紧急的网络流抢夺资源的能力越强。第二项(网络):∑ι∈L(s)(Qι(t)+λι(t))是所述类型1网络流所要通过的链路的拥塞总和。如果某一链路处于拥塞状态,那么使用该链路的设备会降低发送速率。这保证了网络流能够根据拥塞状况相应地做出反应。上述第一项和第二项的相互配合,使得类型1网络流既能在截止时间内完成又能让出更多的带宽给类型2和类型3网络流。
需要指出的是,上述第二项(网络)是依据路径而计算的,这需累计每一跳信息,因此无法从源处直接获得。为解决这个问题,本发明提出两种解决方法。
方法一:
在本发明的一个实施例中,提供了一种利用现售交换机具有的功能,即ECN(Explicit Congestion Notification,显示拥塞指示),来计算上述二项(网络)的方法。
具体的,在该实施例中,t时刻的所述总的队列长度由公式(b)计算得到:
∑ι∈L(s)Ql(t)≈K+Fs(t)×Ws(t) 公式(b)
其中,K为显示拥塞指示的阈值,Fs(t)表示根据距t时刻最近一个拥塞窗口发送的类型1网络流的数据包中所述显示拥塞指示有标记的数据包的比例,Ws(t)表示t时刻的拥塞窗口。
同时,在t时刻的所述总的链路代价由公式(c)计算得到:
∑l∈L(s)λl(t)=C-(Fs(t)Ws(t)-Fs(t-τs(t))Ws(t-τs(t))-2)/τs(t) 公式(c)
其中C表示所述链路的容量,Fs(t)表示根据距t时刻最近一个拥塞窗口发送的类型1网络流的数据包中所述显示拥塞指示有标记的数据包的比例,Fs(t-τs(t))表示根据距t-τs(t)时刻最近一个拥塞窗口发送的类型1网络流的数据包中所述显示拥塞指示有标记的数据包的比例,Ws(t-τs(t))表示t-τs(t)时刻的拥塞窗口。
上述实施例利用现售交换机具有的功能,以一种简便实用地方式解决了无法从源处直接获得总的队列长度及总的链路代价的问题。
方法二:
在本发明的另一个实施例中,所述交换机从所述链路接收数据包,所述接收到的数据包中携带所述总的队列长度和所述总的链路代价的信息,通过读取所述接收到的数据包便可获取当前时刻的所述总的队列长度和当前时刻的所述总的链路代价。
更具体地,在本实施例中,所述网络中的每个交换机在其发送的每个数据包包头的附加字段中增加并存储器自己的队列长度及链路代价。这样所述数据包在经过其路径上的每一个交换机时都会获得该交换机处的队列长度及链路代价,从而得到整条路径上的总的队列长度和总的链路代价。
本实施例不是通过ECN来估计所述队列长度和所述链路代价,而是直接将每个交换机的信息进行记录,因此得到得队列长度和链路代价信息更加的准确。
在本发明的另一个实施例中,本发明调度方法在判断一个类型1网络流无法在其截止时间前完成时,丢弃所述一个类型1网络流。
在截止时间到来之前就丢弃那些肯定无法在其截止时间前完成的网络流,可以更早地让类型1网络流让出更多的带宽给类型2和类型3网络流,从而减小类型2和类型3网络流的FCT。
而选择丢弃掉哪些网络流是一个NP难的问题。对此,本发明实施例还提出两种优选的丢弃方案。方案1,若判定所述一个类型1网络流的虚拟队列的队列长度大于所述链路的容量,即Zs(t)>maxl∈L(s)Cl,丢弃所述一个类型1网络流。方案2,若判定所述一个类型1网络流的期望速率大于所述链路的容量,即γs(t)>maxl∈L(s)Cl,丢弃所述一个类型1网络流,其中γs(t)为所述网络流在当前时刻的期望速率,可通过完成所述网络流还需要传输的剩余数据大小Ms(t)和距离截止时间到来还剩的时间δs(t)来计算,即γs(t)=Ms(t)/δs(t)。
实施上述实施例,可以进一步的让类型1网络流让出更多的带宽给类型2和类型3网络流,从而减小类型2和类型3网络流的FCT。
上面描述的实施例主要介绍了如何对类型1网络流进行处理,下面的实施例将重点介绍如何对类型2和类型3网络流进行处理。
本发明将类型2和类型3网络流置于多个低优先级队列中,利用类型1网络流剩下的带宽在端主机处采用激进的速率控制算法占满链路对类型2和类型3网络流进行处理。
在本发明的一个实施例中,本发明调度方法根据网络流的大小信息对类型2和类型3网络流分别进行分离和筛选处理,并进一步利用网络中多个低优先级队列来最小化这些网络流的FCT。
该实施例的主要思想是:如果网络流的大小已知(类型2网络流),则按照它们的大小依据SJF的思想,将它们分离至各个优先级队列中。如果网络流的大小未知(类型3网络流),则根据已经发送的比特数将它们从高优先级队列筛选至低优先级队列,模仿网络流大小未知的SJF。虽然已有文献提出对类型3网络流实行筛选处理,然而本发明是对类型2和类型3网络流一起进行处理,因此解决的是不同的技术问题。
具体的,在该实施例中,本发明调度方法依据分离阈值{β}对所述类型2网络流进行划分,将大小处于(βi-1,βi]之间的类型2网络流分配至优先级为i的队列中;并依据筛选阈值{α}对所述类型3网络流进行划分,将已发送的字节数处于(αi-1,αi]之间的类型3网络流分配至优先级为i的队列中;其中所述i越小优先级越高。
由于类型2网络流的大小是已知的,因此理论上对它们实行SJF是比较容易的。本发明根据类型2网络流的大小将其分离至不同优先级的队列中。越小的网络流分配至越高优先级的队列中。本发明使用有限个数的优先级队列,并通过将大小在一个范围内的类型2网络流分配至同一个优先级队列的方法来模仿SJF,这也可以视为是SJF的一个量子化版本。本发明使用{β}来表示分离阈值。β0=0,βK=∞。
与类型2网络流不同,类型3网络流的大小并不知道。因此,没有真实的信息让类型3网络流能够按照近似SJF的方法被分离至不同的优先级队列中去。对此,本发明提出了一种解决的办法,能够在不知道网络流大小的情况下模拟SJF。
具体的,在类型3网络流存续的期间,本发明根据所述网络流已经发送的字节数将高优先级队列的网络流筛选至低先级队列中。在此过程中,小的网络流会在头几个优先级队列中就完成,而大的网络流最终将沉入最低的优先级队列中。用这样的方法,本发明可以保证小的网络流的优先级总体上是高于长的网络流。所有的类型3网络流在开始的时候都给予最高的优先级,随着网络流发送字节的增加,它们被逐渐移入更低优先级的队列。
通过实施上述实施例,可以充分地利用剩余的带宽减小类型2和类型3网络流的FCT。
在本发明的另一个实施例中,本发明调度方法还提供了一种计算所述分离阈值{β}和所述筛选阈值{α}的方法。
首先,通过求解下述具有线性约束条件的二次规划问题得到相应的
约束条件:
其中M为所述分离阈值{β}或所述筛选阈值{α}所构成的区间的个数,F1(·)、F2(·)、F3(·)为所述三种类型网络流各自的流量分布。
其次,根据公式(e)(f)反推分离阈值{β}和所述筛选阈值{α}。
公式(d)描述的是一个具有线性约束条件的二次规划问题。这种问题可以用半正定规划包来求解,所述半正定规划包在很多解决程序中都是有的。本发明使用MATLAB的CVXtoolbox来求解。由于问题的复杂度与交换机中队列的数量有关,和网络的规模无关,因此不超过10秒钟就可以在试验床机器上完成求解。
实施上述实施例,可以利用现有的软件快速地获得分离阈值{β}和所述筛选阈值{α},实用性强。
阈值的计算需要知道整个网络中网络流的大小信息。采集并分析在大型DCN中所有流量轨迹是很耗时且不实际的。而本发明采用端主机模块来采集所有网络流的包括大小在内的信息,并将所述信息报告给中心主体,由所述中心主体计算阈值。所述报告和计算都是周期性地进行。在每个周期中,一组新的阈值被分发至端主机模块。
DCN中的流量会随着时间和空间变化。由于类型1网络流在最高优先级队列中,所以这种变化并不会影响类型1网络流。然而所述变化会对类型2和类型3网络流产生影响,因为类型2和类型3网络流需要根据基于阈值被分离和筛选到多个队列中,而上述阈值是基于全局流量分布而求出的。因此,在本发明的另一个实施例中,所述分离阈值{β}和所述筛选阈值{α}随网络中流量的改变而周期性地更新。
获得与流量匹配的阈值是件很有挑战的事。首先,分布是一直变化的,并且采集大小和分发阈值都需要时间。其次,流量在空间也是变化的,并且基于全局流量分布而求出的分离阈值和筛选阈值可能无法对每个交换机都是最优。当流量和阈值出现不匹配的情况时,长的网络流的数据包可能被错误的分离(类型2网络流),或者在更高优先级的队列中停留的时间过长(类型3网络流),或者短的网络流的数据包被错误的分离(类型2网络流)或者过早的被筛选至更低优先级的队列中(类型3网络流)。无论这两种情况的哪一种,短的网络流都可能排在长的网络流之后,造成延迟的增加。
用于估计网络项的ECN功能同样也能用于解决这个问题。通过ECN,本发明可以有效地保持低缓冲占用,并最小化长的网络流对短的网络流的影响。因此,本发明可以解决阈值-流量不匹配问题,也就是说本发明对流量改变具有弹性。
所述弹性让本发明不需要频繁的更新阈值,因此本发明以固定的时间周期性地更新所述阈值。时间间隔主要取决于从网络中采集信息和向网络中分发信息的时间,这与网络规模相关。然而,本发明的阈值计算跟网络规模无关,并且很快,大部分情况下是秒级的。
在本发明的另一个实施例中,如果一个网络流已经经历了N个TCP超时,则本发明提升它的优先级。这是因为,若交换机使用严格优先级队列则可能会造成一些网络流的饥饿。
在一个极端的例子中,有截至时间的网络流必须占用所有的带宽才能在其截止时间到来之前完成,这种情况下无截止时间的网络流也是会饥饿。但是并没有多少传输机制能够处理这样的问题,而且如果是这样的情况发生,那说明运营商应该考虑增加整个网络的容量了。
在一个场景中,有截止时间的网络流和在相对高优先级队列中的小的无截止时间的网络流可能会造成最低优先级队列中的大的无截止时间流的饥饿。考虑到这一点,本发明通过在端主机处观察超时事件来识别处于饥饿状态的网络流,并引入网络流时效N来提升那些处于饥饿状态的网络流的优先级。
实施上述实施例,可以很大程度地解决网络流的饥饿问题。
在本发明的一个优选实施例中,如果所述网络流是一个类型2网络流,则本发明根据它剩余的大小重新将它分离至队列中。如果所述网络流是一个类型3网络流,则本发明将其移入无截止时间流的最高优先级的队列中,并重新进行筛选。
在本发明的一个优选实施例中,本发明为每个网络流依照[2,10]的平均分布选取一个N,从而避免拥塞碰撞。
虽然这样提升优先级可能会造成数据包的重排,但这不是个大问题,因为TCP可以很好的处理它。网络流时效对于解决饥饿问题很有效,并且没有什么副作用。
与所述混合网络流的调度方法对应地,本发明还提供一种交换机,所述交换机向链路发送混合网络流,所述混合网络流包括类型1、类型2和类型3三种网络流,其中所述类型1网络流为有截止时间的网络流,所述类型2网络流为无截止时间但大小已知的网络流,所述类型3网络流为无截止时间且大小未知的网络流,所述链路具有带宽。如图5所示,所述交换机包括拥塞窗口计算模块、调度模块,其中所述拥塞窗口计算模块用于根据公式(a)计算拥塞窗口;所述调度模块用于将类型1网络流分配至具有最高优先级的队列中,占用与所述拥塞窗口相对应的带宽向所述链路发送所述类型1网络流,同时将所述类型2和类型3网络流分配至其他优先级的队列中,占用所述类型1网络流使用剩余的带宽向所述链路发送所述类型2和类型3网络流;
其中,
s表示所述类型1网络流,τs(t)表示在t时刻所述类型1网络流的往返时间,Ws(t)表示t时刻的拥塞窗口,Ws(t+τs(t))表示t+τs(t)时刻的拥塞窗口,L(s)表示所述链路,γs(t)表示在t时刻所述类型1网络流的期望速率,Zs(t)表示在t时刻所述类型1网络流的虚拟队列,Ms(t)表示在t时刻要完成所述类型1网络流还需要传输的剩余数据大小,δs(t)表示在t时刻所述类型1网络流距离截止时间到来还剩余的时间,∑l∈L(s)Ql(t)表示在t时刻所述链路上的总的队列长度,∑l∈L(s)λl(t)表示在t时刻所述链路的总的链路代价。
进一步地,在本发明一个实施例中,所述交换机支持显示拥塞指示,在t时刻所述总的队列长度由公式(b)计算得到:
∑l∈L(s)Ql(t)≈K+Fs(t)×Ws(t) 公式(b)
其中,K为所述显示拥塞指示的阈值,Fs(t)表示根据距t时刻最近一个拥塞窗口发送的类型1网络流的数据包中所述显示拥塞指示有标记的数据包的比例,Ws(t)表示t时刻的拥塞窗口。
在t时刻所述总的链路代价由公式(c)计算得到:
∑l∈L(s)λl(t)=C-(Fs(t)Ws(t)-Fs(t-τs(t))Ws(t-τs(t))-2)/τs(t) 公式(c)
其中C表示所述链路的容量,Fs(t)表示根据距t时刻最近一个拥塞窗口发送的类型1网络流的数据包中所述显示拥塞指示有标记的数据包的比例,Fs(t-τs(t))表示根据距t-τs(t)时刻最近一个拥塞窗口发送的类型1网络流的数据包中所述显示拥塞指示有标记的数据包的比例,Ws(t-τs(t))表示t-τs(t)时刻的拥塞窗口。
进一步地,在本发明一个实施例中,所述交换机还包括判断模块,所述判断模块用于判断一个类型1网络流能否在其截止时间前完成;
所述调度模块进一步用于在所述判断模块判定所述一个类型1网络流不能在其截止时间前完成时,丢弃所述一个类型1网络流。
优选的,所述判断模块在所述一个类型1网络流的虚拟队列的队列长度大于所述链路的容量时判定所述一个类型1网络流无法在其截止时间前完成。
优选的,所述判断模块在所述一个类型1网络流的期望速率大于所述链路的容量时判定所述一个类型1网络流无法在其截止时间前完成。
进一步地,在本发明一个实施例中,所述交换机还包括阈值计算模块,所述阈值计算模块用于根据公式(d)、(e)、(f)计算分离阈值{β}和筛选阈值{α};
约束条件:
其中M表示所述分离阈值{β}或所述筛选阈值{α}所构成的区间的个数,F1(·)、F2(·)、F3(·)为所述三种类型网络流各自的流量分布;
所述调度模块进一步用于依据所述分离阈值{β}对所述类型2网络流进行划分,将大小处于(βi-1,βi]之间的类型2网络流分配至优先级为i的队列中,依据筛选阈值{α}对所述类型3网络流进行划分,将已发送的字节数处于(αi-1,αi]之间的类型3网络流分配至优先级为i的队列中,所述i越小优先级越高。
优选的,所述阈值计算模块随网络中流量的改变而周期性地计算所述分离阈值{β}和所述筛选阈值{α}。
进一步地,在本发明一个实施例中,所述交换机还包括N值选取模块,所述N值选取模块用于为每个网络流按照[2,10]的平均分布随机选取一个N值,所N为大于1的整数;
所述调度模块进一步还用于在一个网络流经历了N个TCP超时时,提升所述一个网络流的优先级。
优选的,所述调度模块通过以下方式提升所述一个网络流的优先级:当所述一个网络流为类型2网络流时,按照所述一个网络流的剩余数据大小重新对所述一个网络流进行划分并分配至相应的优先级队列;当所述一个网络流为类型3网络流时,将所述一个网络流移至用于类型2和类型3网络流的队列中优先级最高的队列。
在本发明的一个实施例中,所述交换机还包括信息添加模块。所述信息添加模块用于在所述交换机发送的每个数据包包头的附加字段中增加并存储器所述交换机处的队列长度及链路代价。这样所述数据包在经过其路径上的每一个交换机时都会获得该交换机处的队列长度及链路代价,从而得到整条路径上的总的队列长度和总的链路代价。
在实际应用时,实施本发明调度方法还是需要克服很多困难的。首先,对于类型1和类型2网络流,本发明需要获得网络流信息(例如:大小,截止时间)才能实行网络流的调度。所述网络流信息可以通过修改用户空间的应用来获得,一些现有技术也有相关内容的介绍。然而,将网络流信息传递至内核空间网络堆栈还是很具挑战的。现有技术并没有公开相关内容。
为了解决这个问题,在本发明的一个实施例中,所述交换机还包括信息传递模块,所述信息传递模块通过发送套接字并利用setsockopt设置每个数据包的mark将所述网络流的信息传递至内核空间网络堆栈。在Linux内核中,mark是sk_buff结构的一个无符号的32位整数变量。通过改变mark的值可以将每网络流信息传送给内核。考虑到mark只有32位,在一个实施例中,可以使用12位来表示截止时间(单位:ms),剩下的20位来表示大小(单位:KB)。因此,mark最大可表示1GB的大小和4s的截止时间。这已经可以满足绝大多数数据中心应用的需求了。
包标注模块用于维持每网络流状态并在端主机处给数据包标注优先级。本发明的一个实施例在Linux内核模块上实现。包标注模块在TX数据路径NetfilterLocal_Out处设置挂钩,位于TCP/IP堆栈和TC之间。
包标注操作网络流程如下:1)当一个出站包被Netfilter挂钩拦截下来,它将被导入基于哈希的网络流表。2)网络流表中的每个网络流具有5个元组,分别是src IP,dst IP,src port,dst port和protocol.对每个出站包都进行鉴定,看它属于哪一个网络流(或者新建一个网络流条目)并更新每网络流状态(通过mark提取类型1和类型2网络流的网络流大小以及截止时间信息,并增加类型3网络流已经发送的字节数)。3)基于所述网络流信息,相应地更改IP头的DSCP域以使数据包在交换机上进入不同的队列。
如今的NIC(Network Interface Card,网络接口卡)使用很多卸载机制来降低CPU(Central Processing Unit,中央处理器)的开支。当使用LSO(Large Segmentation Offloading,大段卸载机制)时,包标注模块可能不能够为每个独立的具有最大传输单元大小的数据包(MTU-sized packet)正确地设定DSCP值。为了评估因此而带来的影响,本申请测量1G试验床中有效载荷数据的TCP段的长度。平均段长度仅为7.2KB,这对包标注的影响非常小。我们把它归因为具有小带宽延迟积(BDP,bandwidth delay product)的数据中心网络TCP窗口尺寸较小。将包标注模块设置在NIC模块可以彻底避免这个影响。
本发明的一个实施例采用上述最优拥塞窗口更新方法处理类型1网络流,同时在端主机对类型2和类型3网络流采用DCTCP。在实施DCTCP时,在Linux内核2.6.38.3下使用DCTCP补丁。将上述最优拥塞窗口更新方法作为接收方Netfilter内核模块。该模块拦截有截止时间网络流的TCP包,依据上述方法更改接收窗口大小。这样的做法避免了为不同版本操作系统的网络堆栈打补丁。
本发明依据RTT估计值和被ECN标记的数据包的比例更新拥塞窗口。因此,获得准确的RTT对本发明是非常重要的。由于由接收端向发送端的网络流量可能不够,我们只能通过使用TCP时间戳选项来获取RTT。然而,现在的TCP时间戳选项都是毫秒级别的,达不到数据中心网络的要求。因此,我们将时间戳修改为微秒级的。
本发明只要求ECN和严格优先级队列,这两者现售交换机都是有的。本发明在交换机处实施严格优先级队列并依据DSCP域对数据包进行分类。本发明基于当前队列长度和一个标记阈值对ECN标记进行配置。
很多现售交换机芯片都提供多种配置ECN标记的方法。例如,本发明使用的Broadcom BCM#56538,它支持对不同出口主体(队列、端口和服务池)进行ECN标记。在每队列ECN标记(per-queue ECN marking)中,每个队列都有其自己的标记阈值并且独立地进行ECN标记。在每端口ECN标记(per-port ECN marking)中,每个端口被分配一个单独的标记阈值,并且当属于该端口的所有队列大小的总和超过所述标记阈值时标记所述数据包。每端口ECN标记不能像每队列ECN标记一样提供队列之间的隔离。
尽管如此,本发明还是使用每端口ECN标记。原因有二。一是每端口ECN标记具有更高的猝发容忍能力。对每队列ECN标记来说,每个队列都需要一个ECN标记阈值h以充分地独立使用所述链路(例如,对1G链路,DCTCP需要h=20个数据包)。当所有队列都处于活跃状态时,需要共享内存的大小至少是标记阈值乘以队列数量那么大,而这对大多数浅缓冲的现售交换机而言都是难以支持的。二是每端口ECN标记可以缓和所述饥饿问题。因为它在有许多低优先级网络流的数据包排队时会将高优先级的网络流往后推。
除了上述有益之处,本发明对同向流调度也是有好处。
同向流是一种重要的抽象,它识别网络流之间的相互依附性。本发明通过将优先级暴露给网络层,有助于同向流的调度。有截止时间的同向流可以简单地看作是本发明中的类型1网络流。由于他们具有最高的优先级,因此可以保证他们在截止时间前完成。
对于其他两种类型,同向流调度需要多个服务器在应用级的共同协调来决定同向流的发送顺序。本发明可以简单地用数据包的优先级来表示所述顺序。高优先级的数据包早于低优先级的数据包被发送,同样优先级的数据包共享带宽。
下面,详细说明本发明上述几个实施例中涉及公式的推导及计算过程。
首先建立系统模型。假设有所述系统包含L条链路,每条所述链路具有Clbps(bits per second,每秒传输位数)的容量。整个系统中活跃的网络流的数量为S。在t时刻,网络流s的传输速率为xs(t)bps,还需传输的剩余数据大小用Ms(t)来表示。距离截止时间到来还剩的时间用δs(t)来表示。在发送数据的请求中,应用将截止时间信息传递给传输层。定义γs(t)=Ms(t)/δs(t)为网络流s在时刻t的期望速率,在下一个RTT(Round Trip Time,往返时间)的期望速率为
其中τs(t)是网络流s在t时刻的RTT。假定网络流s通过链路L(s)的一个固定组路由。对于链路l,使用yl来表示总的总的输入速率,yl=∑s∈S(l)xs,其中S(l)表示在链路l上传输的一组网络流。
最大程度地减少有截止时间网络流造成的影响是本发明的一个目的。本发明没有选择使用有截止时间网络流的总的总的速率,而是用每包延迟来表示有截止时间网络流造成的影响。这是因为无截止时间的网络流对每包延迟更敏感,特别是当有截止时间网络流在高优先级队列中时影响最大,如图2所示。
以最小化每包延迟的长期平均值为目标。用dl(yl)表示一个数据包在到达速率为yl的链路l上的延迟。对于网络流s,平均包延迟定义为∑l∈L(s)dl(yl)。链路l的延迟,dl(yl),是yl的函数,是链路l的总的总的到达速速率。dl(yl)是一个正的、凸的、递增的函数。定义目标方程为每个源的每包延迟的总和的时间平均。
其中,是一个L×1的向量。
为了稳定队列,需要每个源都控制其发送速率xs(t),使每条链路l的总的总的速率yl(t)=∑s∈s(l)xs(t)满足实际情况下,由于交换机中存在缓冲装置,暂时的过载也是允许的。因此我们将限制条件设为超过链路容量的网络流将受到惩罚。
为了使网络流能够在截止时间前完成,需要令传输速率大于等于所述期望速率,用长期时间平均来放宽所述条件可以得到:
这个公式基本上在表达,对于每一个期望速率是γs(t)的网络流,所述传输速率xs(t)平均上讲要大于所述期望速率γs(t)以实现在截止时间前完成所述网络流。本发明对限制条件的放宽是基于实际中不存在存续时间无限长的网络流而做出的。
本发明的目标是导出最优源速率一个S×1的向量,来最小化长期每包延迟,同时让网络流能够在截止时间前完成。为此,本发明构建如下所述随机最小化问题来满足上述需求。
约束条件:xs(t)>0,
本发明利用李雅普诺夫优化框架(Lyapunov optimization framework)将所述最小化问题转换成一个凸问题,然后基于所述凸问题的最优解导出最优拥塞窗口更新方程。漂移加惩罚(Drift-plus-penalty)方法是李雅普诺夫优化的关键技术。漂移加惩罚方法在保持排队网络的稳定的同时最优化目标的时间平均(所述目标可以是,例如,每包延迟)。
接下来介绍如何利用漂移加惩罚方法将问题(4)转换为凸规划问题。在所述李雅普诺夫优化框架下,需要考虑以下几个方面:
1、所有链路的队列稳定性:首先定义L(t)为排队系统在t时刻的稳定性。所述L(t)在控制理论中被称为李雅普诺夫方程(Lyapunov function)。对于一个交换网络,本发明使用二次型李雅普诺夫方程:
李雅普诺夫漂移(Lyapunov drift)定义为两个连续时刻之间的差Δ(tk)=L(tk+1)-L(tk)。要获得一个稳定的排队系统,需要使李雅普诺夫方程漂移向负方向趋近于0。通过使用漂移加惩罚方法,本发明可以控制源的传输速率,最小化网络李雅普诺夫漂移的上限,并由此实现网络的稳定性。
2、截止时间约束条件:要解决公式(4)中截止时间约束条件,本发明将所述截止时间约束条件转换为虚拟队列。设网络流s在时刻t的虚拟队列为Zs(t),输入是所述期望速率,输出是实际速率。
要使所述虚拟队列稳定,需要:
类似于交换机的包队列,所述虚拟队列也可以通过最小化李雅普诺夫漂移来实现稳定性。现将所述虚拟队列一并进行考虑,所述李雅普诺夫方程变为
由于所述虚拟队列的输入γs(t)平均而言是小于所述输出xs(t)的,因此如果所述虚拟队列是稳定的,那么所述截止时间约束条件便即可满足。
3、最小化影响(每包延迟):上述两点都关于“漂移”,接下来本发明进一步用“惩罚”来实现本发明的目标,最小化每包延迟。首先建立漂移加惩罚的表达式其中V是非负权重用于确保的时间平均任意接近最优解(在O(1/V)内),相应的O(V)来平衡平均队列大小。通过最小化漂移加惩罚表达式的上限,可以最小化所述每包延迟的时间平均,并且使包队列和虚拟队列的网络保持稳定。
4、凸问题:最后,本发明要解决凸问题:
约束条件:
本发明将每一时刻t的长期(t→∞)随机延迟最小化问题(4)转换为漂移加惩罚最小化问题(7)。为了求出问题的解,本发明提出自适应源速率控制算法。
通过考虑最优解的属性以及上述问题的KKT条件(Karush-Kuhn-Tucker condition),可以得出用于求解问题(7)最优解的初级算法。公式(8)可以解决队列系统的稳定问题,并可以最小化网络的整体每包延迟。
其中,λl(t)=d′l(yl(t))
每个网络流都根据公式(8)调整其传输速率。公式(8)可以重新写为:
其中,
然后可以导出最优拥塞窗口更新方程:
在拥有公式(10)的基础上,现在来讨论实际算法设计。
上述第一项(源)可以从上层应用中获得。然而,获取上述第二项(网络)并不容易。由于链路代价λl(t)以及队列的长度Ql(t)的总和是依据路径而计算的,这需累积每一跳信息,因此无法从源处直接获得。可以将所述总和存储在数据包头的附加字段,并让每个交换机为每个数据包在所述附加字段增加并存储其自己的代价及队列长度。然而,现售交换机并不具有这个功能。为了实现本发明的目的,本发明采用现售交换机可用的功能,即ECN,来估计上述第二项(网络)。
首先关注每个网络流的总的总的队列长度Q。用F(0≤F≤1)来表示在最后一个拥塞窗口中被标记的数据包的比例。F对每个拥塞窗口都进行更新。DCTCP和D2TCP通过计算F来估计拥塞的程度,本发明进一步利用F来估计队列的长度。
本发明将DCN构架视为一个交换机。当前数据中心的拓扑结构使得构架的对分带宽很大。这将带宽的争夺推向了边缘交换机(假设负载平衡做得很好)。作为一个为数据中心设计的传输协议,经常在构架的出口交换机处发现瓶颈链路。连接瓶颈链路的交换机称为瓶颈交换机。本发明的估计策略将对瓶颈交换机的排队行为进行建模。
图6显示了网络流s如何基于F估计队列长度。假设ECN阈值为K,所述K是判断交换机是否处于拥塞状态的阈值。假设当前队列长度为Q,并且假设网络流s的最后窗口尺寸为Ws(t)。由ECN标记的网络流s的窗口Ws(t)中的数据包的部分在图中显示为白色。因此可以得到Fs(t)≈(Ql(t)-K)/Ws(t)。然后可以得到Ql(t)≈K+Fs(t)×Ws(t),本发明用此近似值作为每个网络流的总的总的队列长度。
链路代价代表了具体链路的拥塞程度,它通常通过M/M/1延迟公式进行估计。d(y)=1/(C-y)。因此,链路代价与延迟方程的倒数成正比d′(y)=(C-y)-2。到达速率可以在源处直接通过两个连续的队列进行估计
基于上述估计以及公式(10),实际的拥塞窗口更新方程可描述为:
其中
接下来描述如何获得能够最小化类型2和类型3网络流平均FCT的最佳分离阈值{β}和最佳筛选阈值{α}。
首先,获取不同类型网络流大小的累积密度方程作为已知条件。定义F1(·)、F2(·)、F3(·)为所述三种类型网络流各自的流量分布。定义F(·)为总分布。因此有
依据类型2网络流的大小,按照分离阈值{β},类型2网络流被分离至不同的优先级。按照筛选阈值{α},类型3网络流被筛选至不同个优先级。定义网络的负载为ρ,0≤ρ≤1。假设网络中的网络流按照泊松分布到达。对于优先级为j的类型2网络流,它的期望FCT的上限为
对于大小在[αj-1,αj)之间的类型3网络流,它将经历各优先级的延迟直至第j个优先级。一个上限被定义为其中是类型3网络流在第j个队列中平均花费的时间。从而有
因此问题可以描述为选择阈值{α,β}的一组最优解,目标是最小化网络中类型2和类型3网络流的平均FCT。
约束条件:α0=0,αM=∞,αj-1<αj,j=1,…,M
β0=0,βM=∞,βj-1<βj,j=1,…,M
为了简化符号,定义θj=F3(αj)-F3(αj-1)。表示大小在[βj-1,βj)之间的类型2网络流的比例。θj表示大小在[αj-1,αj)之间的类型3网络流的比例。要解决的问题可以重写写为:
其中是类型1网络流的部分。
可以认为上述问题是一个二次比例和的问题(因为)。现有技术已经有解决这种问题的方法了。本发明使用松弛技术解决上述目标的下限问题。可以注意到这一项是严格小于1的。因此肯定比上述问题的下限还低。因此,需要一组和{θ}能够让下限最低。因此,问题可以重新被写为:
约束条件:
至此,所述问题被放松成一个具有线性约束条件的二次规划问题。这种问题可以用半正定规划包来求解,所述半正定规划包在很多解决程序中都是有的。本发明使用MATLAB的CVXtoolbox来求解。由于问题的复杂度与交换机中队列的数量有关,和网络的规模无关,因此不超过10秒钟就可以在试验床机器上完成求解。
下面,详细介绍对本发明上述几个实施例进行仿真的实验结果。
我们使用试验床实验和ns-3离散事件模拟器进行模拟。
试验床实验主要从微观视角对本发明的性能进行测试。主要目的是显示本发明是如何工作的,以及显示本发明的运行结果。
首先建立试验床,包括16个服务器,每个服务器都具有Intel 4核2.8GHz处理器,8G内存。所述服务器运行Debian 6.0 64位Linux2.6.38.3内核并搭载Broadcom BCM5719NetXtreme Gigabit Ethernet NICs.NIC卸载机制被设置为默认选项以降低CPU的负荷。所有服务器连接至具有4MB共享内存的Pronto 3295 48-port Gigabit Ethernet交换机。所述交换机支持ECN和严格优先权排队,最多具有8类服务队列。基础RTT为~100us。
本发明缺省使用8个优先级队列。设置每端口ECN标记的阈值为30KB。实验中建立用户/服务器模型以产生流量,并在应用层测量FCT(flow completion time,网络流完成时间)。在一个服务器上运行的用户应用向其他15个服务器发出数据请求。所述请求是基于泊松过程产生的动态工作负载。
本发明只需要刚好够用的带宽就可以让类型1网络流在其截止时间前完成。因此,本发明可以为类型2和类型3网络流让出更多的带宽。为了证明这一点,我们用图7来展示本发明的试验床实验。在这个实验中,4个网络流共享1Gbps链路。可以观测到,有截止时间网络流如预期的一样正常地运行着,并且刚好在截止时间到来前结束。成功地为其他网络流节省了带宽。然而,对DCTCP,可以看到网络流1和3没能在截止时间内完成,他们分别延迟了21ms和13ms,而网络流2和网络流4又过多的占用带宽使得他们相对其截止时间早早地就完成了。pFabric虽然都在截止时间内完成,但是占用了全部的带宽。
本发明通过模仿SJF来优化类型2和类型3网络流的FCT。类型2网络流的优先级基于所述类型2网络流的大小而定,并按照量化了的SJF进行调度。类型3网络流也是以一种类SJF的方式进行调度。实验中使用网络搜索工作负载(图13),并对比本发明与DCTCP工作在80%负载时的效果,其中所述DCTCP是一种平均共享的调度方案。图8显示了对应于不同大小的网络流的FCT。可以观察到,对于小至中等大小的网络流,本发明的效果优于DCTCP;而对于大的网络流,本发明的效果逊于DCTCP。这说明尽管提前不知道类型3网络流的大小,本发明模仿SJF对类型3网络流进行调度。
根据剩余速率尽早的丢弃网络流可以把带宽让出给其他的网络流,让其他的网络流能够在截止时间前完成。图9示出用于实现网络流的丢弃的3个方案。1)根据Z(t)丢弃网络流(当Zs(t)>maxl∈L(s)Cl时丢弃所述网络流),2)根据期望速率(当γs(t)>maxl∈L(s)Cl时丢弃所述网络流),3)永不放弃。可以看到方案1的整体效果比较好,虽然方案1丢弃的网络流比方案2多,但是错过截止时间的网络流的数目相对较少(被丢弃的网络流也算入错过截止时间的网络流)。方案2放弃网络流的条件比较高,这导致有一些已无法在截止时间内完成的网络流还在传送数据,浪费带宽。
为了评估ECN处理阈值-流量不匹配的效果,可以人为地生成工作负载,令所述工作负载80%的网络流为30KB,20%的网络流为10MB。实验工作在80%负载的情况下。假设所有网络流都是类型3网络流,并分配2个优先级队列。显然,最佳的分离阈值为30KB。而在实验中,阈值分别设为20KB、30KB、2MB。在第一种情况下,短的网络流被提早地分离至低优先级的队列种。而在第三种情况下,长的网络流在高优先级的队列中停留的时间过长。在这两种情况下,由于长的网络流形成的队列,短的网络流的数据包都会经历长时间延迟。图10可见30KB短网络流的FCT。当阈值为30KB时,两种方案都实现了理想的FCT。不具有ECN时FCT甚至更低9%,这是因为每端口ECN的虚假标记。然而对于大阈值(2MB)或者小阈值(20KB),无论是均值还是99百分位,具有ECN时都能够获得比不具有ECN时更低57%~85%的FCT。具有ECN时,本发明能够有效地控制队列的形成,从而缓和阈值-流量不匹配的问题。
图11显示了队列数量对类型2和类型3网络流的FCT的影响。实验中使用的流量时通过网络搜索工作负载生成的。实验测量2、4和7个优先级队列的情况(第一个队列留给类型1网络流)。可以观察到:1)队列数量更多时平均FCT总体上更好。这是因为队列数量更多时,本发明可以更好地将类型2和类型3网络流分离至不同队列中,从而提高总体性能。2)短的网络流的平均FCT在三种情况下都差不多。这说明,在只有2个队列时,短的网络流最受益。
接下来使用常见的DCN拓扑结构下的DCN工作负载对本发明进行模拟仿真。测试本发明在瓶颈场景中网络流完成度、饥饿、网络流量变化这几个方面的极限值。
首先用ns-3模拟器实施大规模包级别仿真,并利用fnss生成不同的场景。如图12所示,具有叶脊网络拓扑(spine-and-leaf fabric)的144个服务器。这是DCNs产品的的常见拓扑结构。包括4个核心交换机,9个架顶式交换机(ToR,Top-of-Rack),每个所述架顶式交换机有16个服务器。这是一个多跳、多瓶颈设置用以完成我们的评估。服务器至架顶式交换机链路设为10G。架顶式交换机的上行链路为40G。
如图13所示,在这个测试中使用了两个广泛使用的DCN网络流量工作负载:一个是网络搜索工作负载,一个是数据挖掘工作负载。在这些工作负载中,超过一半的网络流都小于100KB。这体现的是真实DCN网络流量的状况。当然也会存在一些情况倾向于大的尺寸。为了深入研究,我们生成了一个工作负载“Long Flow”.在这个工作负载中,网络流的尺寸均匀分布在1KB到10MB之间.这表示有一半的网络流比5MB大。
下面将本发明与DCTCP,D2TCP,D3和pFabric进行比较.首先,设定DCTCP的参数,按照参考文件(ALIZADEH,M.,GREENBERG,A.,MALTZ,D.A.,PAHDYE,J.,PATEL,P.,PRABHAKAR,B.,SENGUPTA,S.,AND SRIDHARAN,M.Data center tcp(dctcp).In ACM SIGCOMM’10)设置参数,并设置交换机ECN标记阀值,将10Gbps链路设为65包,40Gbps链路设为250包。在ns-3上实行D2TCP和D3。包格式和交换机操作按照文献(WILSON,C.,BALLANI,H.,KARAGIANNIS,T.,AND ROWTRON,A.Better never than late:meeting deadlines in datacenter networks.In ACM SIGCOMM’11)中的设置。并按照文献(VAMANAN,B.,HASAN,J.,AND VIJAYKUMAR,T.Deadline-aware datacenter tcp(d2tcp).In ACM SIGCOMM’12),将D2TCP的d设为0.5≤d≤2,将D3的基础速率设为每RTT一段。对于pFabric,按照文献(MUNIR,A.,BAIG,G.,IRTEZA,S.,QAZI,I.,LIU,I.,AND DOGAR,F.Friends,not foesAaxsynthesizing existing transport strategies for data center networks.In Proc.of SIGCOMM(2014))中的缺省参数进行设置。并按照EDF调度。每次仿真持续60秒。
本发明在很少地牺牲有截止时间网络流的利益的条件下,可以减少无截止时间网络流的FCT。为了更加清楚的表明这个结果,我们将本发明与D2TCP,D3和pFabric(EDF)进行了比较。在该仿真中,网络流的大小是依据数据挖掘工作负载而选择的,源和目的地是随机选择的。通过按照以下分配原则控制有类型1网络流的负载(总期望速率Γ):记录所有活跃的类型1网络流的总期望速率对每个新网络流,如果我们标记这个网络流为类型1网络流,并分配一个尽可能实现Γ的截止时间(最小截止时间为5ms)否则,我们标记这个网络流类型2或类型3网络流。Γ在80%到100%之间变化。三种网络流的总网络负载总是100%。
由图14(a)可知,与D2TCP相比,本发明只有一少部分(7%)网络流错过了截止时间。由图14(b)可知,在满负载时本发明与D3,D2TCP,和pFabric相比在95百分位FCT时分别减少65.12%,42.08%和49.25%。实际上,在仿真中,本发明完成了多达100倍的无截止时间网络流(当Γ=100%时,本发明为4985,pFabric为45,D2TCP为184)。可以注意到本发明并不是像EDF那样的最优截止时间调度法则。有些只有EDF能够满足的截止时间本发明并不能满足。然而,本发明的价值在于,本发明在有截止时间网络流存在的情况下,降低无截止时间网络流的FCT,同时比之前提到的几个截止时间知晓策略效果要好。
仿真中使用了Long Flow流量,因为在其他2种真实负载中只有个别情况下会出现饥饿。接下来将对比几种与网络流时限相关的策略。对类型2网络流:1)提升1个优先级(操作系统中常用方法);2)将优先级提升至和剩余大小对应的优先级(本发明方法);对类型3网络流:3)提升1个优先级;4)提升至最高优先级(本发明方法);
由图15可知,对类型2和类型3网络流,当设置了网络流时效时,大的网络流的FCT比没有设置网络流时效时有明显降低。由图15还可知,策略2比策略1效果好;策略4比策略3效果好。这是因为,在多优先级队列系统中仅提升一个优先级并不总是能够解决饥饿。当饥饿发生时,饥饿的网络流可能是被高其好几个优先级的网络流阻挡,因此只提升一个优先级的话所述饥饿的网络流将仍然处于饥饿状态。总之,网络流时效可以有效地处理饥饿问题,从而改善长的网络流的FCT。
为了评估本发明对阈值的敏感度,实验对四组[{α},{β}]阈值进行测试。其中第一组和第二组阈值是分别是通过对60%和80%网络搜索工作负载计算得出的。第三组和第四组阈值分别是通过对60%和80%数据挖掘工作负载计算得出的。实验将这四组阈值用于不同类型的工作负载(都工作在80%负载的情况下)生成如图16所示的12个场景。除了第2个和第8个,其他的场景都出现了阈值-流量不匹配的情况。每种类型构成总流量的1/3。
首先,对类型1网络流来说,在图16所示的所有场景中,本发明的截止时间错过率都接近于0。这是因为类型1网络流具有最高的优先级,不受流量变化的影响。
其次,对于类型2和类型3网络流来说,图17显示了类型2网络流的FCT。在网络搜索中,只有第2个场景的阈值和流量是匹配的。这个场景的FCT也是最低的。第1个场景和第2个场景的FCT差不多,第3个和第4个场景的FCT差一点,但也不明显。在数据挖掘中,只有第8个场景的阈值和流量是匹配的。这个场景的FCT也是最低的。在Long Flow中,所有场景的阈值和流量都是不匹配的,FCT也比前面两组的长。但是在每个场景中,本发明都能获得比DCTCP更好的FCT。对于类型3网络流,这个结论也是相似的。
总之,对于类型2和类型3网络流,本发明在阈值和流量匹配时表现最佳。当阈值和流量不匹配时,FCT略有变差(但仍比DCTCP好很多)。这说明本发明对流量变化具有弹性。其中一个原因是本发明使用了基于ECN的速率控制来缓和所述不匹配。
以上所有仿真都是假定完全对分带宽网络的基础上进行的,这个能够满足公式(11)中估计网络项在一个交换机的假定。为了计算网络项,我们有意通过使1(目的地架顶式交换机),2(源/目的地架顶式交换机),3(源/目的地架顶式交换机和核)过载的方式创造交叉架有截止时间网络流的瓶颈情景。在模拟器中我们获得真实队列长度和估计队列长度。
在图18中,各瓶颈链路具有不同的负载。定义平均队列估计误差为图18显示了上述平均队列估计误差和平均错过截止时间率。可以观察到,当设定偏离我们的假设时(包括瓶颈的负载和数量都对估计的准确度产生负影响),队列估计误差增大。然而,即便如此,本发明仍然能够保证在100%负载2条瓶颈线路时<10%的错过率。这是因为,剩余速率累积,源项会提升发送率,即使在网络项不准确时。
综上所述,本发明实施例提供了一种网络流调度方法和一种交换机。实施本发明实施例可以在使大部分有截止时间的网络流在其截止时间之前完成的同时提升无截止时间的网络流的FCT。
以上所述是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也视为本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!