一种数据处理方法、数据处理装置以及处理器与流程
本发明涉及通信技术领域,尤其涉及一种数据处理方法、数据处理装置以及处理器。
背景技术:
为了满足电子认证服务系统应用需求,国家密码管理局发布了SM3密码杂凑算法,SM3密码杂凑算法用于密码应用中的数字签名和验证、消息认证码的生成与验证以及随机数的生成,可以满足多种密码应用的安全需求。
SM3密码杂凑算法一般以512比特(bit)为一个消息分组,每个消息分组由16个32bit的字构成,针对每一个消息分组,将16个字依据扩展算法生成132个扩展字,将这些扩展字与8个32bit的输入状态字一起经过64轮迭代压缩操作,得到输出结果。迭代压缩算法属于计算密集型操作,每一次迭代循环都包括大量的循环位移、逻辑运算和算数运算等操作,如果使用普通的指令集,需要耗费许多指令才能算出一轮迭代结果,执行效率较低。可见,现有的迭代压缩算法的执行效率低下。
技术实现要素:
本发明实施例公开了一种数据处理方法、数据处理装置以及处理器,可以提高迭代压缩算法的执行效率。
本发明实施例第一方面公开一种数据处理方法,包括:
获取第i轮第一操作数、第i轮第二操作数和第i轮第三操作数,所述i为自然数;
执行第一指令,所述第一指令用于对所述第i轮第一操作数、所述第i轮第二操作数和所述第i轮第三操作数进行第i轮迭代压缩运算,得到第i轮目标操作数;
将所述第i轮目标操作数作为第i+1轮第二操作数,并将所述第i轮第二操作数作为第i+1轮第一操作数,所述第i+1轮第一操作数和所述第i+1轮第二操作数用于进行第i+1轮迭代压缩运算。
本方案适用于哈希算法(例如,SM3密码杂凑算法),第一指令为单指令多数据流,可以在一条指令中同时执行多个运算。本方案中仅用一条指令(第一指令)即可进行多轮迭代运算,与现有技术中需要采用多条普通指令集相比,可以提高迭代压缩算法的执行效率。
结合本发明实施例第一方面,在本发明实施例第一方面的第一种实现方式中,所述将所述第i轮目标操作数作为第i+1轮第二操作数,并将所述第i轮第二操作数作为第i+1轮第一操作数之后,所述方法还包括:
判断所述i是否小于第一预设值;
当所述i小于所述第一预设值时,将所述i的值加1,执行所述获取第i轮第一操作数、第i轮第二操作数和第i轮第三操作数的步骤。
对于哈希算法而言,迭代轮数不同,使用的算法有可能不同。基于第一指令的迭代压缩运算执行的次数没有达到第一预设次数(第一预设值+1)时,继续执行基于第一指令的迭代压缩运算,即在第一预设次数内使用的算法相同。对于SM3密码杂凑算法而言,前16轮迭代压缩运算与后48轮迭代压缩运算使用不同的算法,则第一预设值为15。
结合本发明实施例第一方面的第一种实现方式,在本发明实施例第一方面的第二种实现方式中,所述方法还包括:
当所述i等于或大于所述第一预设值时,获取第j轮第一操作数、第j轮第二操作数和第j轮第三操作数,所述j为大于所述第一预设值并且小于或等于第二预设值的正整数;
执行第二指令,所述第二指令用于对所述第j轮第一操作数、所述第j轮第二操作数和所述第j轮第三操作数进行第j轮迭代压缩运算,得到第j轮目标操作数;
将所述第j轮目标操作数作为第j+1轮第二操作数,并将所述第j轮第二操作数作为第j+1轮第一操作数,所述第j+1轮第一操作数和所述第j+1轮第二操作数用于进行第j+1轮迭代压缩运算。
基于第一指令的迭代压缩运算执行的次数达到预设次数(第一预设值+1)时,执行第二指令的迭代压缩运算。第一次执行第二指令的迭代压缩运算用到的操作数是执行第一指令达到预设次数时产生的“第一预设值+1”轮第一操作数和“第一预设值+1”轮第二操作数。
结合本发明实施例第一方面的第二种实现方式,在本发明实施例第一方面的第三种实现方式中,所述方法还包括:
所述将所述第j轮目标操作数作为第j+1轮第二操作数,并将所述第j轮第二操作数作为第j+1轮第一操作数之后,所述方法还包括:
判断所述j是否小于所述第二预设值;
当所述j小于所述第二预设值时,将所述j的值加1,执行所述获取第j轮第一操作数、第j轮第二操作数和第j轮第三操作数的步骤。
基于第二指令的迭代压缩运算执行的次数没有达到第二预设次数(第二预设值-第一预设值)时,继续执行基于第二指令的迭代压缩运算,即在第二预设次数内使用的算法相同。对于SM3密码杂凑算法而言,第二预设值为63。
结合本发明实施例第一方面的第三种实现方式,在本发明实施例第一方面的第四种实现方式中,所述方法还包括:
当所述j等于所述第二预设值时,将第j轮第一操作数和第j轮第二操作数输出。
本方案仅用两条指令(第一指令和第二指令)即可完成多轮迭代运算,与现有技术中需要采用多条普通指令集相比,可以提高迭代压缩算法的执行效率。对于SM3密码杂凑算法而言,前16轮迭代压缩运算使用第一指令,后48轮迭代压缩运算使用第二指令。
本发明实施例第二方面公开一种数据处理装置,包括:
获取单元,用于获取第i轮第一操作数、第i轮第二操作数和第i轮第三操作数,所述i为自然数;
第一执行单元,用于执行第一指令,所述第一指令用于对所述第i轮第一操作数、所述第i轮第二操作数和所述第i轮第三操作数进行第i轮迭代压缩运算,得到第i轮目标操作数;
处理单元,用于将所述第i轮目标操作数作为第i+1轮第二操作数,并将所述第i轮第二操作数作为第i+1轮第一操作数,所述第i+1轮第一操作数和所述第i+1轮第二操作数用于所述第一执行单元进行第i+1轮迭代压缩运算。
结合本发明实施例第二方面,在本发明实施例第二方面的第一种实现方式中,所述数据处理装置还包括:
第一判断单元,用于在所述处理单元将所述第i轮目标操作数作为第i+1轮第二操作数,并将所述第i轮第二操作数作为第i+1轮第一操作数之后,判断所述i是否小于第一预设值;
第一增加单元,还用于当所述i小于所述第一预设值时,将所述i的值加1;
所述第一执行单元,还用于当所述第一增加单元将所述i的值加1之后,获取第i轮第一操作数、第i轮第二操作数和第i轮第三操作数。
结合本发明实施例第二方面的第一种实现方式,在本发明实施例第二方面的第二种实现方式中,所述数据处理装置还包括:
所述获取单元,还用于当所述i等于或大于所述第一预设值时,获取第j轮第一操作数、第j轮第二操作数和第j轮第三操作数,所述j为大于所述第一预设值并且小于或等于第二预设值的正整数;
第二执行单元,用于执行第二指令,所述第二指令用于对所述第j轮第一操作数、所述第j轮第二操作数和所述第j轮第三操作数进行第j轮迭代压缩运算,得到第j轮目标操作数;
所述处理单元,还用于将所述第j轮目标操作数作为第j+1轮第二操作数,并将所述第j轮第二操作数作为第j+1轮第一操作数,所述第j+1轮第一操作数和所述第j+1轮第二操作数用于所述第二执行单元进行第j+1轮迭代压缩运算。
结合本发明实施例第二方面的第二种实现方式,在本发明实施例第二方面的第三种实现方式中,所述数据处理装置还包括:
第二判断单元,用于在所述处理单元将所述第j轮目标操作数作为第j+1轮第二操作数,并将所述第j轮第二操作数作为第j+1轮第一操作数之后,判断所述j是否小于所述第二预设值;
第二增加单元,用于当所述j小于所述第二预设值时,将所述j的值加1;
所述第二执行单元,还用于当所述第二增加单元将所述j的值加1之后,获取第j轮第一操作数、第j轮第二操作数和第j轮第三操作数。
结合本发明实施例第二方面的第三种实现方式,在本发明实施例第二方面的第四种实现方式中,所述数据处理装置还包括:
输出单元,用于当所述第二判断单元判断所述j等于所述第二预设值时,将第j轮第一操作数和第j轮第二操作数输出。
本发明实施例第三方面公开一种处理器,包括:
至少一个寄存器,用于存储用于第i轮迭代压缩运算的第i轮第一操作数、第i轮第二操作数和第i轮第三操作数,或者用于存储用于第j轮迭代压缩运算的第j轮第一操作数、第j轮第二操作数和第j轮第三操作数,所述i为小于或等于第一预设值的自然数,所述j为大于所述第一预设值并且小于或等于第二预设值的正整数;
指令解码器,用于对输入的指令码进行解码,得到第一指令和第二指令;
第一执行单元,用于执行所述第一指令,所述第一指令用于对所述至少一个寄存器中存储的所述第i轮第一操作数、所述第i轮第二操作数和所述第i轮第三操作数进行所述第i轮迭代压缩运算,得到第i轮目标操作数;将所述第i轮目标操作数作为第i+1轮第二操作数,并将所述第i轮第二操作数作为第i+1轮第一操作数,所述第i+1轮第一操作数和所述第i+1轮第二操作数用于所述第一执行单元进行第i+1轮迭代压缩运算;
第二执行单元,用于当所述第一执行单元累计完成预设轮数迭代压缩运算之后,执行所述第二指令,所述第二指令用于对所述至少一个寄存器中存储的所述第j轮第一操作数、所述第j轮第二操作数和所述第j轮第三操作数进行所述第j轮迭代压缩运算,得到第j轮目标操作数;将所述第j轮目标操作数作为第j+1轮第二操作数,并将所述第j轮第二操作数作为第j+1轮第一操作数,所述第j+1轮第一操作数和所述第j+1轮第二操作数用于所述第二执行单元进行第j+1轮迭代压缩运算。
本方案仅用两条指令(第一指令和第二指令)即可完成多轮迭代运算,与现有技术中需要采用多条普通指令集相比,可以提高迭代压缩算法的执行效率。
本发明实施例中,针对第i轮迭代压缩运算,数据处理装置获取第i轮第一操作数、第i轮第二操作数和第i轮第三操作数;执行第一指令,第一指令用于对第i轮第一操作数、第i轮第二操作数和第i轮第三操作数进行第i轮迭代压缩运算,得到第i轮目标操作数;将第i轮目标操作数作为第i+1轮第二操作数,并将第i轮第二操作数作为第i+1轮第一操作数,第i+1轮第一操作数和第i+1轮第二操作数用于进行第i+1轮迭代压缩运算。本发明实施例仅用一条指令(第一指令)即可进行多轮迭代运算,与现有技术中需要采用多条普通指令集相比,可以提高迭代压缩算法的执行效率。
附图说明
为了更清楚地说明本发明实施例中的技术方案,下面将对实施例中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
图1是本发明实施例公开的一种数据处理装置的架构示意图;
图2是本发明实施例公开的一种数据处理方法的流程示意图;
图3是本发明实施公开的一种基于第一指令的一轮迭代执行结果示意图;
图4是本发明实施公开的一种基于第一指令的多轮迭代执行结果示意图;
图5是本发明实施例公开的另一种数据处理方法的流程示意图;
图6是本发明实施例公开的一种数据处理装置的结构示意图;
图7是本发明实施例公开的一种处理器的结构示意图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
本发明实施例公开了一种数据处理方法、数据处理装置以及处理器,可以提高迭代压缩算法的执行效率。以下分别进行详细说明。
为了更好的理解本发明实施例,下面先对本发明实施例公开的一种处理器架构进行描述。
请参阅图1,图1是本发明实施例公开的一种数据处理装置的架构示意图。如图1所示,该数据处理装置10包括处理器11,处理器11包括用于接收和解码指令的指令解码器111、一个或多个执行单元112(图1仅示出一个)和至少一个寄存器113(图1仅示出一个)。
处理器11可以表示任何种类的指令处理器,包括通用处理器、专用处理器等等,例如可以是复杂指令集计算处理器、精简指令集计算处理器、超长指令字处理器、数字信号处理器等等,还可以是上述处理器的混合或者可以完全是其他类型的处理器。处理器11的实现形式包括但不限于专用集成电路(Application-Specific Integrated Circuit,ASIC)实现、现场可编程门阵列(Field Programmable Gate Array,FPGA)实现、复杂可编程逻辑器件(Complex Programmable Logic Device,CPLD)等等。指令解码器111生成并输出反映指令或者从指令导出的一个或多个微操作、伪代码、进入点、微指令、其他指令或其他控制信号。指令解码器111可以使用不同的机制来实现,包括但不限于微代码只读存储器(Read-Only Memory,ROM)、查找表、硬件实现、可编程逻辑阵列(Programmable Logic Arrays,PLA)等等。执行单元112接收指令解码器111的输出,执行单元112包括能够基于指令来执行操作的逻辑单元。执行单元112中包括一个或多个迭代压缩执行单元,用于执行迭代压缩指令。迭代压缩指令的各个源操作数和目的操作数可以分别隐式或者显式地指出。寄存器113可以是用于存储数据的存储位置或者设备,可以是至少128位宽的寄存器。寄存器113可以是软件可见的寄存器、可以被指令指定的寄存器、物理寄存器、重命名寄存器、临时寄存器等等。源操作数和目的操作数中的一些或者全部可以存储在寄存器组或者除寄存器之外的,例如系统存储器中的位置之类的存储位置中。
可选的,数据处理装置10还可以包括存储器、输入设备、输出设备等。
数据处理装置10可以用于执行哈希(Hash)算法,哈希算法可以将任意长度的二进制值转化为固定长度的二进制值。哈希算法可以包括SHA-1算法、SM3密码杂凑算法等等。下面以SM3密码杂凑算法举例进行说明。
对于长度为L(L<264)比特(bit)的消息m,SM3密码杂凑算法经过填充和迭代压缩,生成杂凑值,杂凑值的长度为256bit。消息m经过填充后变为m’,m’的比特长度为512的倍数,将m’按照512bit进行消息分组,每个消息分组的长度为512bit,每个消息分组由16个32bit的字构成,针对每一个消息分组,将16个字依据扩展算法生成132个扩展字,分别记为Wj(j=0,1,...67)、Wj'(j=0,1,...63),将这些扩展字与8个32bit的输入状态字一起经过64轮迭代压缩运算,得到长度为8个字(256bit)的输出结果。
迭代压缩运算的详细步骤介绍如下:
1、定义8个输入状态字为A、B、C、D、E、F、G、H,每个字均为32bit;
2、ABCDEFGH=Vi,Vi为上一个消息分组迭代压缩的输出;
3、for j=0to 63
SS1=((A<<<12)+E+(Tj<<<j))<<<7 公式1
TT1=FFj(A,B,C)+D+SS2+Wj' 公式3
TT2=GGj(E,F,G)+H+SS1+Wj 公式4
D=C 公式5
C=B<<<9 公式6
B=A 公式7
A=TT1 公式8
H=G 公式9
G=F<<<19 公式10
F=E 公式11
E=P0(TT2) 公式12
4、
其中
上述“<<<k”表示“循环左移k位操作”,表示“异或操作”,表示“与操作”,表示“或操作”,“-”表示“非操作”。
迭代压缩运算属于计算密集型操作,每一次迭代循环都包括大量的循环位移、逻辑运算和算数运算等操作,对于前16轮迭代压缩运算,每一轮需要23次操作(包括8次循环左移操作、8次加法操作和7次逻辑异或操作);对于后48轮迭代压缩运算,每一轮需要28次操作(包括8次循环左移操作、8次加法操作、3次逻辑异或操作、5次逻辑与操作、3次逻辑或操作和1次逻辑非操作)。如果使用普通的指令集,需要耗费许多指令才能算出一轮迭代结果,执行效率较低。
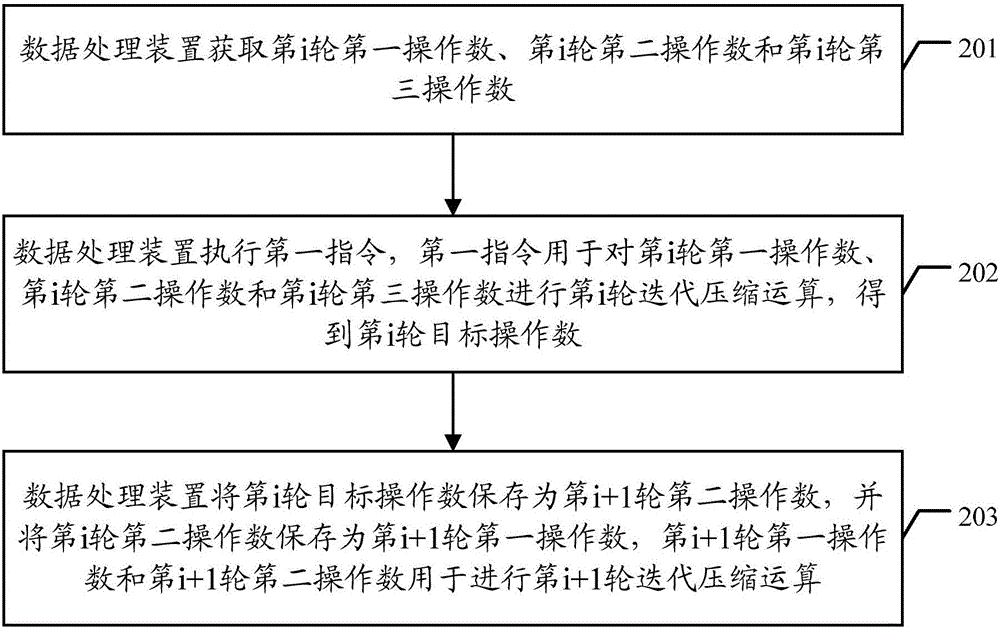
请参阅图2,图2是本发明实施例公开的一种数据处理方法的流程示意图。如图2所示,该数据处理方法包括如下步骤。
201,数据处理装置获取第i轮第一操作数、第i轮第二操作数和第i轮第三操作数,i为自然数。
其中,第i轮第一操作数、第i轮第二操作数和第i轮第三操作数可以存储在外部存储器中,也可以存储在寄存器中。下面以SM3密码杂凑算法为例,其中,第i轮第一操作数与第i轮第二操作数的长度相等,第i轮第一操作数为V1i,第i轮第二操作数为V2i,其中V1i为(Bj、Dj、Fj、Hj),V2i为(Aj、Cj、Ej、Gj)。例如,第0轮第一操作数为V10(B0、D0、F0、H0),第0轮第二操作数V20(A0、C0、E0、G0);第1轮第一操作数为V21(B1、D1、F1、H1),第1轮第二操作数为V11(A1、C1、E1、G1)。第i轮第三操作数V3i包括Wj(j=0,1,...67)、Wj'(j=0,1,...63)和Tj,V3i为(Wj'、Wj、Tj);例如,第0轮第三操作数V30为(W0'、W0、T0);第1轮第三操作数V31(W1'、W1、T1),在一种实施方式中,第i轮第三操作数V3i中的Tj可以是经过循环位移运算得到的,V3i为(Wj'、Wj、Tj<<<j)。Wj’。
202,数据处理装置执行第一指令,第一指令用于对第i轮第一操作数、第i轮第二操作数和第i轮第三操作数进行第i轮迭代压缩运算,得到第i轮目标操作数。
203,数据处理装置将第i轮目标操作数作为第i+1轮第二操作数,并将第i轮第二操作数作为第i+1轮第一操作数,第i+1轮第一操作数和第i+1轮第二操作数用于进行第i+1轮迭代压缩运算。
第一指令用于对三个操作数执行多个运算操作(例如,位移运算操作、加法操作、逻辑异或操作等等),最终得到目标操作数。具体来说,第一指令用于执行上述公式1至公式12的逻辑运算操作。
如图3所示,图3是本发明实施公开的一种基于第一指令的一轮迭代执行结果示意图。第i轮第一操作数为V1i(Bj、Dj、Fj、Hj),第i轮第二操作数为V2i(Aj、Cj、Ej、Gj),第i轮第三操作数为V3i(Wj'、Wj、Tj),执行第一指令,进行第i轮迭代压缩运算,得到第i轮目标操作数,并将第i轮目标操作数作为第i+1轮第二操作数V2i+1(Aj+1、Cj+1、Ej+1、Gj+1),将第i轮第二操作数作为第i+1轮第一操作数V1i+1(Bj+1、Dj+1、Fj+1、Hj+1),即Bj+1=Aj,Dj+1=Cj,Fj+1=Ej,Hj+1=Gj。
本发明实施中的第一指令为单指令多数据流(Single Instruction Multiple Data,SIMD),SIMD是一种实现数据并行处理的技术,可以在一条指令中同时执行多个运算。
本发明实施例中,步骤S201至步骤S203为第i轮迭代压缩运算的执行流程,其他轮迭代压缩运算依次类推,具体请参阅图4,图4是本发明实施公开的一种基于第一指令的多轮迭代执行结果示意图,在图3的基础上,将第i轮目标操作数作为第i+1轮第二操作数V2i+1(Aj+1、Cj+1、Ej+1、Gj+1),将第i轮第二操作数作为第i+1轮第一操作数V1i+1(Bj+1、Dj+1、Fj+1、Hj+1)之后,获取第i+1轮第三操作数为V3i+1(Wj+1'、Wj+1、Tj+1)继续执行第一指令,进行第i+1轮迭代压缩运算,得到第i+1轮目标操作数,并将第i+1轮目标操作数作为第i+2轮第二操作数V2i+2(Aj+2、Cj+2、Ej+2、Gj+2),将第i+1轮第二操作数作为第i+2轮第一操作数V1i+2(Bj+2、Dj+2、Fj+2、Hj+2),即Bj+2=Aj+1,Dj+2=Cj+1,Fj+2=Ej+1,Hj+2=Gj+1。接着继续执行第i+3轮迭代压缩运算,其他轮迭代压缩运算依次类推。
具体实现中,以SM3密码杂凑算法举例进行说明。
针对第i轮迭代压缩运算,定义各寄存器的内容如下:
V0:Bj、Dj、Fj、Hj //V0中的数据每进行四轮迭代压缩更新一次
V1:Aj、Cj、Ej、Gj //V1中的数据每进行四轮迭代压缩更新一次
V2:Wj、Wj+1、Wj+2、Wj+3 //V2中的数据每进行四轮迭代压缩更新一次
V3:Wj'、Wj+1'、Wj+2'、Wj+3' //V3中的数据每进行四轮迭代压缩更新一次
W0:Tj //W0中的数据每进行一轮迭代压缩更新一次
MOV V4.4S[1],V2.4S[3] //将Wj组织到V4中
MOV V4.4S[2],V3.4S[3] //将Wj'组织到V4中
ROR W0,W0,#31 //将Tj循环左移1位
MOV V4.4S[0],W0 //将Tj组织到V4中
SM3H0 V0,V1,V4 //将结果保存在V0中
前四条指令用于获取第i轮第三操作数,第五条指令SM3H0V0,V1,V4用于进行第i轮SM3迭代压缩运算。
SM3H0指令即为上述第一指令,SM3H0指令可以同时并行执行多个运算操作,与现有技术中需要采用多条普通指令集相比,可以提高迭代压缩算法的执行效率。
实施图2所示的方法,仅用一条指令(第一指令)即可进行多轮迭代运算,与现有技术中需要采用多条普通指令集相比,可以提高迭代压缩算法的执行效率。
请参阅图5,图5是本发明实施例公开的另一种数据处理方法的流程示意图。如图5所示,该数据处理方法包括如下步骤。
501,数据处理装置获取第i轮第一操作数、第i轮第二操作数和第i轮第三操作数,i为自然数。
502,数据处理装置执行第一指令,第一指令用于对第i轮第一操作数、第i轮第二操作数和第i轮第三操作数进行第i轮迭代压缩运算,得到第i轮目标操作数。
503,数据处理装置将第i轮目标操作数作为第i+1轮第二操作数,并将第i轮第二操作数作为第i+1轮第一操作数,第i+1轮第一操作数和第i+1轮第二操作数用于进行第i+1轮迭代压缩运算。
504,数据处理装置判断i是否小于第一预设值,若是,执行步骤505,若否,执行步骤506。
其中,第一预设值根据执行不同的哈希算法可以不同,对于SM3密码杂凑算法来说,前16轮迭代压缩运算与后48轮迭代压缩运算的算法不同(主要是布尔函数FFj(X,Y,Z)与布尔函数GGj(X,Y,Z)在前16轮与后48轮的运算规则不同),所以16轮迭代压缩运算采用第一指令,后48轮迭代压缩运算采用第二指令,所以第一预设值可以设为15。
505,数据处理装置将i的值加1,并执行步骤501。
当i小于第一预设值时,表明第一指令的执行次数没有达到预设次数,则需要继续执行第一指令,继续下一轮基于第一指令的迭代压缩运算。
506,数据处理装置获取第j轮第一操作数、第j轮第二操作数和第j轮第三操作数,j为大于第一预设值并且小于或等于第二预设值的正整数。
当i大于或等于第一预设值时,表明第一指令的执行次数已经达到预设次数,则执行第二指令,基于第二指令进行迭代压缩运算。
需要说明的是,数据处理装置获取第j轮第一操作数、第j轮第二操作数和第j轮第三操作数的方法与获取第i轮第一操作数、第i轮第二操作数和第i轮第三操作数的方法相同,此处不再详述。
507,数据处理装置执行第二指令,第二指令用于对第j轮第一操作数、第j轮第二操作数和第j轮第三操作数进行第j轮迭代压缩运算,得到第j轮目标操作数。
508,数据处理装置将第j轮目标操作数作为第j+1轮第二操作数,并将第j轮第二操作数作为第j+1轮第一操作数,第j+1轮第一操作数和第j+1轮第二操作数用于进行第j+1轮迭代压缩运算。
第二指令用于对三个操作数执行多个运算操作(例如,位移运算操作、加法操作、逻辑异或操作等等),最终得到目标操作数。具体来说,第一指令用于执行上述公式1至公式12的逻辑运算操作。第二指令与第一指令仅在具体的逻辑运算上有区别,第二指令的执行方式可以参见图2所示的第一指令的具体实施方式,此处不再赘述。
509,数据处理装置判断j是否小于第二预设值,若是,执行步骤510,若否执行步骤511。
对于SM3密码杂凑算法来说,第二预设值可以设为63。
510,数据处理装置将j的值加1,执行步骤506。
511,数据处理装置将第j轮第一操作数和第j轮第二操作数输出。
当第一指令与第二指令的累计执行次数达到预设次数时,整个迭代压缩运算完成,对于SM3迭代压缩运算而言,当第一指令与第二指令累计执行次数达到64次时,输出第63轮第一操作数和第63轮第二操作数,第63轮第一操作数和第63轮第二操作数组成8个字(A63、B63、C63、D63、E63、F63、G63、H63),共256bit的输出结果。整个64轮SM3迭代压缩运算过程中,仅仅使用了两条指令,即第一指令(用于前16轮迭代压缩运算)和第二指令(用于后48轮迭代压缩运算),即可完成64轮SM3迭代压缩运算,与现有技术中需要采用多条普通指令集相比,可以提高迭代压缩算法的执行效率。
具体实现中,以SM3密码杂凑算法举例进行说明。
在一个实施例中,定义各寄存器的内容如下:
V0:Bj、Dj、Fj、Hj //V0中的数据每进行四轮迭代压缩更新一次
V1:Aj、Cj、Ej、Gj //V1中的数据每进行四轮迭代压缩更新一次
V2:Wj、Wj+1、Wj+2、Wj+3 //V2中的数据每进行四轮迭代压缩更新一次
V3:Wj'、Wj+1'、Wj+2'、Wj+3' //V3中的数据每进行四轮迭代压缩更新一次
W0:Tj //W0中的数据每进行一轮迭代压缩更新一次
MOV V4.4S[1],V2.4S[3] //将Wj组织到V4中
MOV V4.4S[2],V3.4S[3] //将Wj'组织到V4中
ROR W0,W0,#31 //将Tj循环左移1位
MOV V4.4S[0],W0 //将Tj组织到V4中
SM3H0 V0,V1,V4 //将结果保存在V0中
上述过程完成了一次迭代压缩运算,前四条指令用于获取第i轮第三操作数,第五条指令SM3H0V0,V1,V4用于进行第i轮SM3迭代压缩运算。接下来三次迭代压缩运算如下:
MOV V4.4S[1],V2.4S[2] //将Wj+1组织到V4中
MOV V4.4S[2],V3.4S[2] //将Wj+1'组织到V4中
ROR W0,W0,#31 //将Tj+1循环左移1位
MOV V4.4S[0],W0 //将Tj+1组织到V4中
SM3H0 V1,V0,V4 //将结果保存在V1中
MOV V4.4S[1],V2.4S[1] //将Wj+2组织到V4中
MOV V4.4S[2],V3.4S[1] //将Wj+2'组织到V4中
ROR W0,W0,#31 //将Tj+2循环左移1位
MOV V4.4S[0],W0 //将Tj+2组织到V4中
SM3H0 V0,V1,V4 //将结果保存在V0中
MOV V4.4S[1],V2.4S[0] //将Wj+3组织到V4中
MOV V4.4S[2],V3.4S[0] //将Wj+3'组织到V4中
ROR W0,W0,#31 //将Tj+3循环左移1位
MOV V4.4S[0],W0 //将Tj+3组织到V4中
SM3H0 V1,V0,V4 //将结果保存在V1中
SM3H0指令即为上述第一指令,SM3H0指令可以同时并行执行多个运算操作,与现有技术中需要采用多条普通指令集相比,可以提高迭代压缩算法的执行效率。
第17轮迭代压缩运算的指令如下:
MOV V4.4S[1],V2.4S[3] //将Wj+16组织到V4中
MOV V4.4S[2],V3.4S[3] //将Wj+16'组织到V4中
ROR W0,W0,#31 //将Tj+16循环左移1位
MOV V4.4S[0],W0 //将Tj+16组织到V4中
SM3H1 V0,V1,V4 //将结果保存在V0中
SM3H1即为上述第二指令,当第一次执行第二指令时,执行第二指令的第一操作数为V0,第二操作数为V1,第三操作为V4。SM3H1指令可以同时并行执行多个运算操作,与现有技术中需要采用多条普通指令集相比,可以提高迭代压缩算法的执行效率。
在另一个实施例中,定义各寄存器的内容如下:
V0:Bj、Dj、Fj、Hj //V0中的数据每进行四轮迭代压缩更新一次
V1:Aj、Cj、Ej、Gj //V1中的数据每进行四轮迭代压缩更新一次
V2:Wj、Wj+1、Wj+2、Wj+3 //V2中的数据每进行四轮迭代压缩更新一次
V3:Wj'、Wj+1'、Wj+2'、Wj+3' //V3中的数据每进行四轮迭代压缩更新一次
W0:Tj //W0中的数据每进行一轮迭代压缩更新一次
MOV V4.4S[1],V2.4S[3] //将Wj组织到V4中
MOV V4.4S[2],V3.4S[3] //将Wj'组织到V4中
MOV V4.4S[0],W0 //将Tj组织到V4中
SM3C0 V0,V1,V4 //将结果保存在V0中
上述过程完成了一次迭代压缩运算,前三条指令用于获取第i轮第三操作数,第四条指令用于进行第i轮SM3迭代压缩运算,第四条指令SM3C0V0,V1,V4中,寄存器V0中数据为第一操作数,寄存器V1中数据为第二操作数,寄存器V4中数据为第三操作数。
接下来63次迭代压缩运算如下:
MOV V4.4S[1],V2.4S[2] //将Wj+1组织到V4中
MOV V4.4S[2],V3.4S[2] //将Wj+1'组织到V4中
MOV V4.4S[0],W0 //将Tj+1组织到V4中
SM3C1 V1,V0,V4 //将结果保存在V1中
MOV V4.4S[1],V2.4S[1] //将Wj+2组织到V4中
MOV V4.4S[2],V3.4S[1] //将Wj+2'组织到V4中
ROR W0,W0,#31 //将Tj+2循环左移1位
MOV V4.4S[0],W0 //将Tj+2组织到V4中
SM3C2 V0,V1,V4 //将结果保存在V0中
MOV V4.4S[1],V2.4S[0] //将Wj+3组织到V4中
MOV V4.4S[2],V3.4S[0] //将Wj+3'组织到V4中
ROR W0,W0,#31 //将Tj+3循环左移1位
MOV V4.4S[0],W0 //将Tj+3组织到V4中
SM3C3V1,V0,V4 //将结果保存在V1中
...
MOV V4.4S[1],V2.4S[2] //将Wj+63组织到V4中
MOV V4.4S[2],V3.4S[2] //将Wj+63'组织到V4中
MOV V4.4S[0],W0 //将Tj+63组织到V4中
SM3C63 V1,V0,V4 //将结果保存在V1中
上述64条迭代压缩运算中,获取每一轮的第三操作数只需要三条MOV指令,但是每一轮迭代压缩运算都用一条不同的指令,例如,第1轮迭代压缩运算使用指令SM3C0,第2轮迭代压缩运算使用指令SM3C1,第3轮迭代压缩运算使用指令SM3C2...第64轮迭代压缩运算使用指令SM3C63。
实施图5所示的方法,仅用两条指令(第一指令和第二指令)即可完成多轮迭代运算,与现有技术中需要采用多条普通指令集相比,可以提高迭代压缩算法的执行效率。
请参阅图6,图6是本发明实施例公开的一种数据处理装置的结构示意图,如图6所示,该数据处理装置可以包括获取单元601、第一执行单元602和处理单元603,其中:
获取单元601,用于获取第i轮第一操作数、第i轮第二操作数和第i轮第三操作数,i为自然数。
第一执行单元602,用于执行第一指令,第一指令用于对第i轮第一操作数、第i轮第二操作数和第i轮第三操作数进行第i轮迭代压缩运算,得到第i轮目标操作数。
处理单元603,用于将第i轮目标操作数作为第i+1轮第二操作数,并将第i轮第二操作数作为第i+1轮第一操作数,第i+1轮第一操作数和第i+1轮第二操作数用于第一执行单元进行第i+1轮迭代压缩运算。
本发明实施例中仅用一条指令(第一指令)即可进行多轮迭代运算,与现有技术中需要采用多条普通指令集相比,可以提高迭代压缩算法的执行效率。
该数据处理装置的实施可以参见图2-5所示的方法实施例,重复之处不再赘述。
请参阅图7,图7是本发明实施例公开的一种处理器的结构示意图,如图7所示,该处理器70包括至少一个寄存器701、指令解码器702、第一执行单元703和第二执行单元704。
至少一个寄存器701,用于存储用于第i轮迭代压缩运算的第i轮第一操作数、第i轮第二操作数和第i轮第三操作数,或者用于存储用于第j轮迭代压缩运算的第j轮第一操作数、第j轮第二操作数和第j轮第三操作数,i为小于或等于第一预设值的自然数,j为大于第一预设值并且小于或等于第二预设值的正整数;
指令解码器702,用于对输入的指令码进行解码,得到第一指令和第二指令;
第一执行单元703,用于执行第一指令,第一指令用于对至少一个寄存器中存储的第i轮第一操作数、第i轮第二操作数和第i轮第三操作数进行第i轮迭代压缩运算,得到第i轮目标操作数;将第i轮目标操作数作为第i+1轮第二操作数,并将第i轮第二操作数作为第i+1轮第一操作数,第i+1轮第一操作数和第i+1轮第二操作数用于第一执行单元进行第i+1轮迭代压缩运算;
第二执行单元704,用于当第一执行单元703累计完成预设轮数迭代压缩运算之后,执行第二指令,第二指令用于对至少一个寄存器中存储的第j轮第一操作数、第j轮第二操作数和第j轮第三操作数进行第j轮迭代压缩运算,得到第j轮目标操作数;将第j轮目标操作数作为第j+1轮第二操作数,并将第j轮第二操作数作为第j+1轮第一操作数,第j+1轮第一操作数和第j+1轮第二操作数用于第二执行单元进行第j+1轮迭代压缩运算。
图7中的处理器70可以调用指令执行图2至图5所示的方法。
处理器70可以表示任何种类的指令处理器,包括通用处理器、专用处理器等等,例如可以是复杂指令集计算处理器、精简指令集计算处理器、超长指令字处理器、数字信号处理器等等,还可以是上述处理器的混合或者可以完全是其他类型的处理器。处理器70的实现形式包括但不限于专用集成电路(Application-Specific Integrated Circuit,ASIC)实现、现场可编程门阵列(Field Programmable Gate Array,FPGA)实现、复杂可编程逻辑器件(Complex Programmable Logic Device,CPLD)等等。指令解码器702生成并输出反映指令或者从指令导出的一个或多个微操作、伪代码、进入点、微指令、其他指令或其他控制信号。指令解码器702可以使用不同的机制来实现,包括但不限于微代码只读存储器(Read-Only Memory,ROM)、查找表、硬件实现、可编程逻辑阵列(Programmable Logic Arrays,PLA)等等。第一执行单元703和第二执行单元704接收指令解码器702的输出,第一执行单元703和第二执行单元704包括能够基于指令来执行操作的逻辑单元。第一执行单元703和第二执行单元704用于执行迭代压缩指令。迭代压缩指令的各个源操作数和目的操作数可以分别隐式或者显式地指出。寄存器701可以是用于存储数据的存储位置或者设备,可以是至少128位宽的寄存器。寄存器701可以是软件可见的寄存器、可以被指令指定的寄存器、物理寄存器、重命名寄存器、临时寄存器等等。源操作数和目的操作数中的一些或者全部可以存储在寄存器组或者除寄存器之外的,例如系统存储器中的位置之类的存储位置中。
本发明实施例中仅用两条指令(第一指令和第二指令)即可完成多轮迭代运算,与现有技术中需要采用多条普通指令集相比,可以提高迭代压缩算法的执行效率。
本发明实施例的方法中的步骤可以根据实际需要进行顺序调整、合并和删减。
本发明实施例终端或设备中的单元或子单元可以根据实际需要进行合并、划分和删减。
本领域普通技术人员可以理解上述实施例的各种方法中的全部或部分步骤是可以通过程序来指令相关的硬件来完成,该程序可以存储于一计算机可读存储介质中,存储介质包括只读存储器(Read-Only Memory,ROM)、随机存储器(Random Access Memory,RAM)、可编程只读存储器(Programmable Read-only Memory,PROM)、可擦除可编程只读存储器(Erasable Programmable Read Only Memory,EPROM)、一次可编程只读存储器(One-time Programmable Read-Only Memory,OTPROM)、电子抹除式可复写只读存储器(Electrically-Erasable Programmable Read-Only Memory,EEPROM)、只读光盘(Compact Disc Read-Only Memory,CD-ROM)或其他光盘存储器、磁盘存储器、磁带存储器、或者能够用于携带或存储数据的计算机可读的任何其他介质。
以上对本发明实施例公开的一种数据处理方法、数据处理装置以及处理器进行了详细介绍,本文中应用了具体个例对本发明的原理及实施方式进行了阐述,以上实施例的说明只是用于帮助理解本发明的方法及其核心思想;同时,对于本领域的一般技术人员,依据本发明的思想,在具体实施方式及应用范围上均会有改变之处,综上所述,本说明书内容不应理解为对本发明的限制。
- 还没有人留言评论。精彩留言会获得点赞!