基于成本最优化布局电网数据节点的方法和装置与流程
本发明涉及电网技术领域,特别是涉及基于成本最优化布局电网数据节点的方法和基于成本最优化布局电网数据节点的装置。
背景技术:
计量基础设施(Advanced Metering Infrastructur,AMI)作为智能电网广义概念的一部分,在AMI中,智能电表从住宅和工业消费者位置收集能源消耗和电能质量测量数据并发送给控制中心,因此AMI也被视为智能电表和控制中心之间的过渡点。AMI系统使用数据聚合节点(也称为集中器)来管理远离控制中心的大量电表数据。数据聚合节点通常被设置在电线杆的顶端,它们的主要任务是从智能电表收集数据并发送给控制中心。在包括AMI的智能电网的组网问题上,国内外提出了以下几种方案:
方案1:采用Hopfield神经网络对无线传感器网络分簇的方法,针对低功耗自适应集簇分层型协议(Low Energy Adaptive Clustering Hierarchy,LEACH)的不足予以改进,使各个簇头的分布与各节点的能量消耗更均衡;方案2:基于跳数的无线传感器网络节点定位方法,结合链式协议和休眠调度的优点,通过最小距离入链和LEADER节点选取策略避免形成长链和部分节点死亡时导致网络节点分布不均匀的问题;方案3:基于数据融合的多径路由方法,在源节点发送数据包之前进行数据聚合操作,为事件触发型传感器网络模型提供节能、健壮的路由策略。
然而,现有的组网方案均未涉及到数据聚合节点的布局策略,并且组网算法较为复杂,组网整体实现成本较高。
技术实现要素:
基于此,本发明实施例提供了基于成本最优化布局电网数据节点的方法和装置,能够在保证网络覆盖的前提下,获得成本最优化的电网数据节点布局策略。
本发明一方面提供一种基于成本最优化布局电网数据节点的方法,包括:
获取组网基础信息;所述组网基础信息包括:单个数据聚合节点的安装成本、智能电表传输单位数据单位距离所消耗的能量、单位能量价格以及智能电表向数据聚合节点传输数据的时间间隔;
将所述组网基础信息输入预设的节点布局模型;所述节点布局模型以数据传输成本和数据聚合节点安装成本的总开销为目标,以将各个数据聚合节点设置在对应的电线杆上以及无线覆盖率为约束,以数据聚合节点的布局信息为待求解的对象;
对所述节点布局模型进行迭代求解,得到所述总开销最小时的数据聚合节点的布局信息。
本发明另一方面提供一种基于成本最优化布局电网数据节点的装置,包括:
信息收集模块,用于获取组网基础信息;所述组网基础信息包括:单个数据聚合节点的安装成本、智能电表传输单位数据单位距离所消耗的能量、单位能量价格以及智能电表向数据聚合节点传输数据的时间间隔;
模型构建模块,用于将所述组网基础信息输入预设的节点布局模型;所述节点布局模型以数据传输成本和数据聚合节点安装成本的总开销为目标,以将各个数据聚合节点设置在对应的电线杆上以及无线覆盖率为约束,以数据聚合节点的布局信息为待求解的对象;
求解模块,用于对所述节点布局模型进行迭代求解,得到所述总开销最小时的数据聚合节点的布局信息。
上述技术方案,通过获取组网基础信息;所述组网基础信息包括:单个数据聚合节点的安装成本、智能电表传输单位数据单位距离所消耗的能量、单位能量价格以及智能电表向数据聚合节点传输数据的时间间隔;将所述组网基础信息输入预设的节点布局模型;所述节点布局模型以数据传输成本和数据聚合节点安装成本的总开销为目标,以将各个数据聚合节点设置在对应的电线杆上以及无线覆盖率为约束,以数据聚合节点的布局信息为待求解的对象;对所述节点布局模型进行迭代求解,得到所述总开销最小时的数据聚合节点的布局信息。只需确定一个电线杆的子集,将一定数量的数据聚合节点安装到对应的在电线上,既能够对所有智能电表的无线覆盖,又能最小化组网成本。
附图说明
图1为一实施例的基于成本最优化布局电网数据节点的方法的示意性流程图;
图2为一实施例的K-means算法对所述节点布局模型进行求解的示意性流程图;
图3为一实施例的基于成本最优化布局电网数据节点的装置的示意性结构图。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
图1为一实施例的基于成本最优化布局电网数据节点的方法的示意性流程图;如图1所示,本实施例中的基于成本最优化布局电网数据节点的方法包括步骤:
S11,获取组网基础信息;所述组网基础信息包括:单个数据聚合节点的安装成本、智能电表传输单位数据单位距离所消耗的能量、单位能量价格以及智能电表向数据聚合节点传输数据的时间间隔。
S12,将所述组网基础信息输入预设的节点布局模型;所述节点布局模型以数据传输成本和数据聚合节点安装成本的总开销为目标,以将各个数据聚合节点设置在对应的电线杆上以及无线覆盖率为约束,以数据聚合节点的布局信息为待求解的对象。
S13,对所述节点布局模型进行迭代求解,得到所述总开销最小时的数据聚合节点的布局信息。
本实施例对数据聚合节点的最佳位置进行了限制,主要目标是在不同的计密度和无线通信技术下最小化安装成本和数据传输成本。主要的约束条件是限制数据聚合节点的位置从一组现有的电线杆集合中选择,额外的约束是来自网络覆盖和单个数据聚合节点的最大连接数。进一步的,利用对所述节点布局模型进行迭代求解,得到所述总开销最小时的数据聚合节点的布局信息,所述布局信息包括:数据聚合节点的位置以及数量。
在一优选实施例中,所述节点布局模型的约束还包括:每个智能电表仅与一个数据聚合节点数据通信;和/或,每个数据聚合节点对应的智能电表的数量不超过设定的最大数量。
在一优选实施例中,采用改进的K-means算法作为一个合适的启发式用以解决数据聚合节点位置的问题,以用更低的时间复杂度达到接近于最优的开销。
下面结合一具体应用场景对上述实施例的基于成本最优化布局电网数据节点的方法进行说明。该应用场景为:设定配电网使用悬挂在电线杆上的架空配电线路,并将电能传送给配备智能电表的家庭或者企业。一些电线杆上有数据聚合节点,它们都通过无线连接到智能电表的子集。数据聚合节点本身也通过无线的方式连接到控制中心(UC)。并且,假设配电网系统中有NSM个智能电表,Npoles根电线杆,K个数据聚合节点和一个控制中心(UC)的网络,且智能电表、电线杆以及UC的位置是已知的。智能电表和数据聚合节点可以被配备不同的通信技术,例如WiFi、WiMAX、IEEE 802.15.4(ZigBee)和802.15.4g标准等。智能电表的总量可利用公式NSM=ρSMπr2估计获得,式中r表示组网区域的半径,ρSM表示组网区域中的智能电表密度,ρSM的大小取决于该组网区域是农村、城市还是郊区。
基于上述应用场景,限定数据聚合节点被放置在电线杆上,并且它们的主要任务是从智能电表收集数据并发送给UC。假设单跳通信是从智能电表到达数据聚合节点并从数据聚合节点到UC,单跳通信期望得到最小延迟。
数据聚合节点收到来自智能电表的数据之后,进行合并和压缩,然后发送给UC。设定数据聚合节点的数据压缩比率β,β的大小依赖于数据聚合节点所使用的数据和算法的关联。
多个智能电表可以连接到一个数据聚合节点,即多个智能电表可以被一个数据聚合节点支持;数据传输拥挤的可能性很低,主要取决于低频和米内发送的数据信息的数量。例如在六天中的一段时间,在上行链路中,每间隔240分钟从住宅智能电表中发送一次2400字节的数据,在下行链路中,只有25字节的数据被发送。
用A来定义可以连接到数据聚合节点的智能电表的最大数量,并且定义在一个给定的服务区域内,可用的电线杆和智能电表的比率为ρ=Npoles/NSM。对于一个密集的组网环境(例如城市地区),对于大量的智能电表,电线杆影响能量分布是合乎情理的,ρ的值可以很小。
数据传输模型:
为了保证链路的可靠性,使得智能电表根据给定的传输功率传输数据到数据聚合节点,需要调整传输功率Ptx。传输M个数据包d距离(因数8乘以M是数据包的bit数),需要消耗的能量可以表示为:
Etx=8MγEbκPL(d) (1)
其中γ表示传输数据时调制解调器消耗的功率和传输功率的比率,Eb是传输每bit数据所消耗的能量,κ表示衰减极限,d0表示预设的单位距离,PL(d0)表示单位距离的路径损耗,PL(d)表示距离d的路径损耗,可以表示为:
其中α表示预设的路径损耗指数,PL(d)是根据距离d和路径损耗指数α得到的路径损耗。
基于上述的组网环境和数据传输模型,规划数据聚合节点的位置的基本目标是选择一个电线杆的子集P,在其上部安装数据聚合节点使得所需要的数据聚合节点的数量最小化,同时实现对所有智能电表的无线覆盖。数据聚合节点安装成本,被定义为购买数据聚合节点的开销和数据聚合节点初始安装的劳动力成本。此外,还需减少通信开销,通过数据传输消耗的能量来测量。
假设网络工作的时间为Tm,为了精确的表示成本函数,用α表示一个数据聚合节点的安装成本。总安装成本cinst是选择的电线杆数目的α倍。同时,让g表示单位能源的价格(例如消费1千瓦时能量的价格)。可得到数据传输开销为:
其中TI表示智能电表传向数据聚合节点传输数据的时间间隔,所以表示智能电表在Tm时间内总的数据传输次数。
无线覆盖需要至少有一个数据聚合节点的无线网络热点连接到每个智能电表,这意味着需要智能电表到数据聚合节点的距离要小于智能电表的最大传输距离dmax。此外,最多A个智能电表可以连接到一个数据聚合节点。
基于上述说明,在一优选实施例中,所述节点布局模型可构建为:
b=g8MγEbκTm/TI;
Etx=8MγEbκPL(d);
xj∈{0,1},1≤j≤Npoles;
yij∈{0,1},1≤i≤NSM,1≤j≤Npoles;
所述节点布局模型的右侧的第一项是计算数据聚合节点的安装成本,第二项是计算数据传输成本;第二项的第一部分是计算从智能电表到其对应的数据聚合节点传输数据的总开销,第二项的第二部分是计算从数据聚合节点到UC传输数据的开销。
所述节点布局模型的约束包括:
d′j≤d′max,1≤j≤Npoles;(6)
dij≤dmax,1≤i≤NSM,1≤j≤Npoles;(7)
yij≤xj,1≤i≤NSM,1≤j≤Npoles;(9)
其中,约束(5)、(6)、(7)保证无线覆盖,约束(8)限制每个数据聚合节点上的智能电表的最大数量。约束(9)保证数据聚合节点选择和布局维护的关系,也就是一个智能电表只能连接到一个被选择用于安装数据聚合节点的杆上。
公式(4)中的优化是一种整数规划,寻找最优解会带来一个指数的时间复杂度。对于大型网络,需要低复杂度算法来解决布局问题。公式(4)中的优化也可以视为一个限制数据聚合节点数量的大小和数据聚合节点位置的聚类问题。在一优选实施例中,采用改进的K-means算法对所述节点布局模型进行迭代求解,得到所述总开销最小时的数据聚合节点的布局信息,接下来将介绍改进的K-means算法。
传统K-means算法是很典型的基于距离的聚类算法,采用距离作为相似性的评价指标,即认为两个对象的距离越近,其相似度就越大。该算法认为簇是由距离靠近的对象组成的,因此把得到紧凑且独立的簇作为最终目标。k个初始类聚类中心点的选取对聚类结果具有较大的影响,因为在该算法第一步中是随机的选取任意k个对象作为初始聚类的中心,初始地代表一个簇。该算法在每次迭代中对数据集中剩余的每个对象,根据其与各个簇中心的距离将每个对象重新赋给最近的簇。当考察完所有数据对象后,一次迭代运算完成,新的聚类中心被计算出来。如果在一次迭代前后,聚类中心与聚类中心的相等或距离小于指定阈值,说明算法已经收敛。算法过程如下:
1)从N个对象选取K个作为初始聚类中心;
2)对剩余的每个对象测量其到每个聚类中心的距离,并把它归到最近的聚类中心的类;
3)重新计算已经得到的各个类的聚类中心;
4)迭代2~3步直至新的聚类中心与原聚类中心相等或距离小于指定阈值,算法结束。
可见,传统的K-means算法在每次迭代中,智能电表选择最近的簇头(数据聚合节点)。因此如果第i个智能电表属于第k个簇,设置yik=1,否则yik=0。然后,簇头的位置更新点为它所连接的智能电表的中心点。当两个连续的迭代对簇头位置的改变小于一个阈值时K-means算法终止。
相比之下,本发明采用改进的K-means算法对所述节点布局模型进行迭代求解的原理包括:考虑智能电表-数据聚合节点和数据聚合节点-UC和传输成本,结合控制中心的位置u,将对聚类簇头的位置进行迭代所采用的方程设定为:
其中,u表示控制中心的位置,yik′为二进制数,当第i个智能电表属于第k′个聚类簇头时,yik′=1;当第i个智能电表不属于第k′个聚类簇头时,yik′=0;ak′表示第k′个聚类簇头的迭代位置,si表示第i个智能电表的位置,d′max表示第i个智能电表与控制中心的最大距离。
其中w是一个考虑数据压缩对数据聚合节点-UC链路影响的压缩比率β和覆盖比率(也就是)的函数,从而避免智能电表的簇头不会被拉向UC,消除UC无法连接到某些智能电表的问题,进而保证了网络覆盖率。
此外,在迭代过程中,可能会出现违反约束(8)的问题。针对该情况,对每一个数据聚合节点都设置一个标签,以标明当前它所连接的智能电表的数目。当一个智能电表试图连接到一个标签大于等于A的数据聚合节点时,该智能电表放弃该数据聚合节点,选择下一个可用的数据聚合节点。
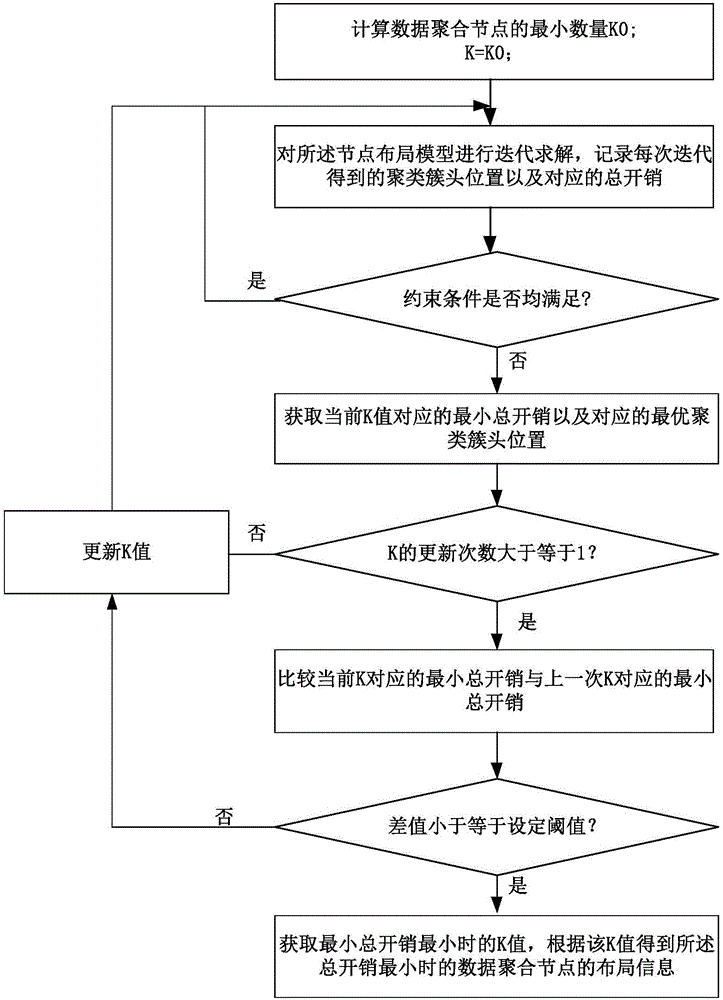
基于上述改进的K-means迭代算法,参考图3所示,对所述节点布局模型进行迭代求解的过程包括如下步骤:
步骤一,计算数据聚合节点的最小数量K0:
其中,ρSM表示电线杆和智能电表的比率,dmax表示智能电表的最大传输距离,A表示单个数据聚合节点通信连接的智能电表的最大数量;
式(12)中的初始估计提供了数据聚合节点数量的最小值。这是因为在高密度组网区域(即任意小于K0的值K<K0都不能满足约束(8);另一方面,在低密度组网区域(即也至少需要K0个数据聚合节点以确保所有智能电表的有效通信范围内至少有一个数据聚合节点。
步骤二,将数据聚合节点作为聚类簇头,聚类簇头的数量为K,初始时K=K0;采用改进的K-means算法对所述节点布局模型进行迭代求解,记录每次迭代得到的聚类簇头位置以及对应的总开销;所述改进的K-means算法能够在聚类簇头位置的迭代过程中根据智能电表的位置以及控制中心的位置,将各个聚类簇头的位置分别映射到距离其最近的电线杆;
以及在聚类簇头迭代过程中,根据当前聚类簇头的位置检测预设的约束条件是否均满足,若任一约束条件不满足,结束聚类簇头的迭代,获取当前K对应的最小总开销以及对应的聚类簇头位置(作为当前K对应的最优聚类簇头位置),执行步骤三;若全部约束条件均满足,继续下一次聚类簇头的迭代;
步骤三,若当前K的更新次数大于等于1,比较当前K对应的最小总开销与上一次K对应的最小总开销,若两者的差值小于等于设定的阈值,执行步骤四;否则,对K值进行更新,返回步骤二;
步骤四,获取最小总开销最小时的K值,根据该K值对应的最优聚类簇头位置得到所述总开销最小时的数据聚合节点的布局信息。
即,从(12)中得到的K0开始,k←0,其中,k为预设的更新数据聚合节点数量的增量,初始时,该值为0;
初始化各聚类簇头的位置;
运行改进的K-means算法迭代更新各聚类簇头的位置,将各聚类簇头的位置与距离其最近的电线杆匹配;
将公式(4)中得到的总开销赋值给Fi;或者,
如果公式(5)-(8)不满足,则Fi←∞;
end for
Ck←min{Fi}
diff←Ck-Ck-1
k←k+1
While diff≤tolerance
Return min{Ck}。
其中,NumTries为预设的最大迭代次数,同一个K值,可对应多个不同的聚类簇头的位置及对应的总开销;因此当跳出for循环时,可从集合{Fi}中得到该K值对应的总开销最小的Fi,作为该K值对应的最优成本,并将对应的聚类簇头的位置作为该K值对应的最优簇头布局。Tolerance为预设的阈值,当K值更新前后各自对应的最优成本的差diff大于设定阈值时,更新K值,即将K值加1,得到新的K值,重新进行上述迭代求解。当K值更新前后各自对应的最优成本的差diff小于等于设定阈值时,结束对公式(4)的求解,输出求解过程中得到的最优成本的最小值min{Ck}、对应的K值以及对应的最优簇头布局。
基于上述实施例的基于成本最优化布局电网数据节点的方法,基于数据聚合节点的安装成本以及数据传输成本,将聚合节点的布局问题转化为数据聚合节点布局的整型规划问题,并通过改进的K-means算法寻找数据聚合节点的最优布局。仿真表明,与现有搜索寻找数据聚合节点最优位置的算法相比,上述实施例所提的算法可以用更低的时间复杂度达到接近于最优成本的数据聚合节点布局方案。
需要说明的是,对于前述的各方法实施例,为了简便描述,将其都表述为一系列的动作组合,但是本领域技术人员应该知悉,本发明并不受所描述的动作顺序的限制,因为依据本发明,某些步骤可以采用其它顺序或者同时进行。此外,还可对上述实施例进行任意组合,得到其他的实施例。
基于与上述实施例中的基于成本最优化布局电网数据节点的方法相同的思想,本发明还提供基于成本最优化布局电网数据节点的装置,该装置可用于执行上述基于成本最优化布局电网数据节点的方法。为了便于说明,基于成本最优化布局电网数据节点的装置实施例的结构示意图中,仅仅示出了与本发明实施例相关的部分,本领域技术人员可以理解,图示结构并不构成对装置的限定,可以包括比图示更多或更少的部件,或者组合某些部件,或者不同的部件布置。
图3为本发明一实施例的基于成本最优化布局电网数据节点的装置的示意性结构图;如图3所示,本实施例的基于成本最优化布局电网数据节点的装置包括:信息收集模块310、模型构建模块320以及求解模块330,各模块详述如下:
信息收集模块310,用于获取组网基础信息;所述组网基础信息包括:单个数据聚合节点的安装成本、智能电表传输单位数据单位距离所消耗的能量、单位能量价格以及智能电表向数据聚合节点传输数据的时间间隔;
模型构建模块320,用于将所述组网基础信息输入预设的节点布局模型;所述节点布局模型以数据传输成本和数据聚合节点安装成本的总开销为目标,以将各个数据聚合节点设置在对应的电线杆上以及无线覆盖率为约束,以数据聚合节点的布局信息为待求解的对象;
在一优选实施中,所述节点布局模型的约束还包括:每个智能电表仅与一个数据聚合节点数据通信;和/或,每个数据聚合节点对应的智能电表的数量不超过设定的最大数量。
求解模块330,用于对所述节点布局模型进行迭代求解,得到所述总开销最小时的数据聚合节点的布局信息。
在一优选实施中,所述数据聚合节点的布局信息包括:数据聚合节点的位置以及数量。
在一优选实施例中,所述节点布局模型为:
b=g8MγEbκTm/TI;
Etx=8MγEbκPL(d);
xj∈{0,1},1≤j≤Npoles;
yij∈{0,1},1≤i≤NSM,1≤j≤Npoles;
所述节点布局模型的约束包括:
d′j≤d′max,1≤j≤Npoles;
dij≤dmax,1≤i≤NSM,1≤j≤Npoles;
yij≤xj,1≤i≤NSM,1≤j≤Npoles;
其中,β表示数据聚合节点对收到的智能电表数据进行合并和压缩的压缩比率,Npoles表示电线杆的数量,NSM表示智能电表的数量,cinst表示数据聚合节点的总安装成本;Etx表示智能电表传输M个数据包的数据d距离所消耗的能量,γ表示传输数据时调制解调器消耗的功率和传输功率的比率,Eb是传输每bit数据所消耗的能量,κ表示预设的衰减极限,α表示预设的路径损耗指数,d0表示预设的单位距离,PL(d0)表示单位距离的路径损耗,PL(d)表示距离d的路径损耗;ctx表示传输d距离的传输成本;dij表示第i个智能电表与第j个电线杆的距离,dj′表示第j个电线杆与控制中心的距离;二进制值xj表示一个数据聚合节点是否安装在电线杆j上,若安装在电线杆j上,则xj为1,否则xj为0;二进制值yij表示第i个智能电表是否通信连接到第j个电线杆上的数据聚合节点,若是,yij为1,若否,yij为0;Tm表示网络工作的时间,TI表示智能电表传向数据聚合节点传输数据的时间间隔。
需要说明的是,上述示例的基于成本最优化布局电网数据节点的装置的实施方式中,各模块之间的信息交互、执行过程等内容,由于与本发明前述方法实施例基于同一构思,其带来的技术效果与本发明前述方法实施例相同,具体内容可参见本发明方法实施例中的叙述,此处不再赘述。
此外,上述示例的基于成本最优化布局电网数据节点的装置的实施方式中,各功能模块的逻辑划分仅是举例说明,实际应用中可以根据需要,例如出于相应硬件的配置要求或者软件的实现的便利考虑,将上述功能分配由不同的功能模块完成,即将所述基于成本最优化布局电网数据节点的装置的内部结构划分成不同的功能模块,以完成以上描述的全部或者部分功能。其中各功能模既可以采用硬件的形式实现,也可以采用软件功能模块的形式实现。
本领域普通技术人员可以理解,实现上述实施例方法中的全部或部分流程,是可以通过计算机程序来指令相关的硬件来完成,所述的程序可存储于一计算机可读取存储介质中,作为独立的产品销售或使用。所述程序在执行时,可执行如上述各方法的实施例的全部或部分步骤。其中,所述的存储介质可为磁碟、光盘、只读存储记忆体(Read-Only Memory,ROM)或随机存储记忆体(Random Access Memory,RAM)等。
在上述实施例中,对各个实施例的描述都各有侧重,某个实施例中没有详述的部分,可以参见其它实施例的相关描述。
以上所述实施例仅表达了本发明的几种实施方式,不能理解为对本发明专利范围的限制。应当指出的是,对于本领域的普通技术人员来说,在不脱离本发明构思的前提下,还可以做出若干变形和改进,这些都属于本发明的保护范围。因此,本发明专利的保护范围应以所附权利要求为准。
- 还没有人留言评论。精彩留言会获得点赞!