一种基于一对多网络的减少图像压缩效应的方法与流程
本发明涉及图像处理领域,尤其是涉及了一种基于一对多网络的减少图像压缩效应的方法。
背景技术:
在这个信息爆炸的时代,网络上传播的图像数量迅速增加。人们通常会用图像有损压缩来节省带宽和存储空间。其中,JPEG是最广泛使用的有损压缩技术。然而,图像有损压缩会导致信息丢失和压缩伪影,这严重地降低了用户体验。因此,如何恢复美观的无伪影图像受到人们越来越多的关注。人们已经提出许多方法来抑制JPEG压缩效应,如用稀疏编码来重建无伪影图像,但是这种方法通常会伴随着嘈杂的边缘和非自然区域;而采用ARCNN来恢复图像,会使图像变得过于光滑,相比于压缩的图片,其含有的纹理更少。
本发明提出了一种基于一对多网络的减少图像压缩效应的方法,采用一对多网络,包括建议元件和测量元件;建议组件以JPEG压缩图像作为输入,然后输出一系列无伪影的候选图像,由测量组件进一步估计其输出质量。本发明实现了从一个JPEG压缩图像有效地恢复无伪影的图像,通过合并感知损失,自然损失和JPEG损失这三个损失函数来建立测量组件,为用户提供一系列候选图像,并让用户选择他们所喜欢的图像,减少了图像的压缩效应,大大提高了图像的恢复质量。
技术实现要素:
针对有损压缩会降低图片质量的问题,本发明的目的在于提供一种基于一对多网络的减少图像压缩效应的方法,采用一对多网络,包括建议元件和测量元件;建议组件以JPEG压缩图像作为输入,然后输出一系列无伪影的候选图像,由测量组件进一步估计其输出质量。
为解决上述问题,本发明提供一种基于一对多网络的减少图像压缩效应的方法,其主要内容包括:
(一)输入JPEG压缩图像;
(二)建议组件生成无伪影的候选图像;
(三)测量组件评估输出质量。
其中,所述的一对多网络,它被分解为建议元件和测量元件;建议组件以JPEG压缩图像作为输入,然后输出一系列无伪影的候选图像,由测量组件进一步估计其输出质量;一对多网络实现了从一个JPEG压缩图像有效地恢复无伪影的图像,为用户提供一系列高质量的候选图像,并让用户选择他们所喜欢的图像。
其中,所述的输入JPEG压缩的图像,利用MATLAB的JPEG编码器生成JPEG压缩图像;JPEG编码器首先将图像分为8×8个编码块,然后对每个块应用离散余弦变换(DCT);在DCT之后,64个DCT系数中的每一个与量化表一起被均匀地量化;解码时,JPEG解码器对量化系数执行逆DCT以获得像素值。
其中,所述的建议组件生成无伪影的候选图像,建议组件提供了一个F模型,将映射F开发为深层CNN;要启用一对多属性,在网络中引入辅助变量Z作为隐藏的附加输入;网络采用压缩图像Y作为输入;同时它从具有标准偏差1的以零为中心的正态分布对Z进行采样,然后将Y和Z两者馈送到网络中以进行非线性映射;
压缩图像Y和采样的Z作为两个不同分支的输入,这两个分支的输出被级联;在级联特征映射之上,进一步执行聚合子网络以生成无伪影预测;
在建议组件中,每个分支包含5个剩余单元,并且聚合子网络包括10个剩余单元;每一个剩余的单位包括两个批量规范化层,两个ReLU层和两个卷积层;
在将压缩图像转发到网络之前,通过步幅-2的4×4卷积层对其进行下采样;最后,网络输出由步幅-2的4×4解卷积层上采样,以保持图像大小。
进一步地,所述的上采样,使用滤波器大小为4的步幅-2解卷积层进行上采样,将过滤器表示[w1,w2,w3,w4];假设对一个输入的常数[…,c,…]应用解卷积,其中c是标量;预期输出应该是常量;然而,实际输出是c*;如果要求实际输出满足预期输出,则训练的过滤器应该满足w1+w3=w2+w4;
要使最终输出为常数,可应用“移动和平均”策略,在获得解卷积输出(表示为deconv)之后,执行以下两个步骤:
1)重复deconv并将其右移1像素;
2)平均deconv和移位版本。
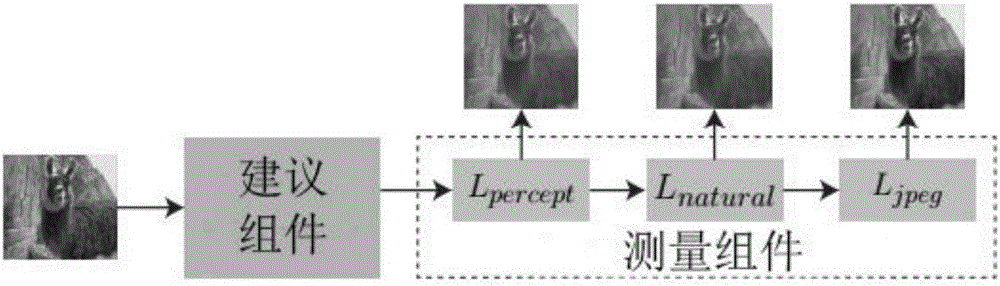
其中,所述的测量组件评估输出质量,从建议组件获得一个输出后,采用测量组件估计是否令人满意,因此定义了三个测量损失函数:感知损失,自然损失和JPEG损失。
进一步地,所述的感知损失,用于图像分类的预训练的深度网络的特征可以很好地描述感知信息;从较低层提取的特征倾向于保留照片上准确的信息,而较高层特征对颜色,纹理和形状差异不变;因此,感知损失被定义来促进和X共享类似的高层特征:
其中,φ是从网络计算的功能,Hφ是特征尺寸。
进一步地,所述的自然损失,我们希望尽可能恢复无伪像的图像为“自然”图像,因此构建一个附加网络D来区分图像是从建议组件F生成还是一个自然图像;网络D执行二进制分类,并输出输入为“自然”的概率;将这个概率作为测量分量的第二损失加到的负对数上,激励具有高概率:
网络D也需要训练,它使用二进制熵损失作为其优化目标:
从公式(2)和公式(3)可以看出,网络F和网络D彼此竞争:网络F试图生成无伪影的图像其对于网络D难以与自然图像区分,同时训练网络D,避免网络F产生伪像。
进一步地,所述的JPEG损失,JPEG标准由各种预定义的参数组成,通过利用这些参数,我们可以获得像素值的下限和上限;对于压缩,JPEG编码器通过量化表划分输入图像的DCT系数,然后将结果舍入到最接近的整数;JPEG解码器乘以后面的量化表进行减压;因此,压缩图像Y和对应的未压缩图像X之间的关系可以表示为:
其中,Xdct和Ydct分别是X和Y的DCT系数,Q是量化表,i和j是在DCT域的指标,公式(4)暗示我们写下以下的DCT系数范围约束:
所以每个恢复的无伪影图像也应满足式(5),我们提出以下JPEG损失:
其中,是的尺寸;可以看出,JPEG损失是截短的L2损失;DCT系数落在下限/上限之外(如:)的重构图像将被惩罚。
进一步地,所述的三个测量损失函数,通过合并这三个损失函数来建立测量组件:
一对多网络使用批量梯度下降进行优化;图像准备为网络输入大小相同的的补丁;将λ1设置为0.1,λ2则需要一些特殊处理;JPEG编码器分别对每个8×8非重叠编码块执行量化;而对于与编码块边界未对准的片,我们不能获得其DCT系数;因此,我们根据给定的补丁设置不同的λ2值;一般来说,网络训练在每个迭代过程中包括两个主要步骤:
1)修正建议分量F,用方程(3)优化判别网络D;
2)修正网络D,用测量分量(即公式(7))优化提议分量F;如果输入块与JPEG编码块边界对准,则将λ2设置为0.1;否则将λ2设置为0。
附图说明
图1是本发明一种基于一对多网络的减少图像压缩效应的方法的系统流程图。
图2是本发明一种基于一对多网络的减少图像压缩效应的方法的流程示意图。
图3是本发明一种基于一对多网络的减少图像压缩效应的方法的建议组件生成无伪影的候选图像。
图4是本发明一种基于一对多网络的减少图像压缩效应的方法的“移动和平均”策略。
具体实施方式
需要说明的是,在不冲突的情况下,本申请中的实施例及实施例中的特征可以相互结合,下面结合附图和具体实施例对本发明作进一步详细说明。
图1是本发明一种基于一对多网络的减少图像压缩效应的方法的系统流程图。主要包括输入JPEG压缩图像,建议组件生成无伪影的候选图像,测量组件评估输出质量。
其中,利用MATLAB的JPEG编码器生成JPEG压缩图像;JPEG编码器首先将图像分为8×8个编码块,然后对每个块应用离散余弦变换(DCT);在DCT之后,64个DCT系数中的每一个与量化表一起被均匀地量化;解码时,JPEG解码器对量化系数执行逆DCT以获得像素值。
其中,测量组件评估输出质量,从建议组件获得一个输出后,采用测量组件估计是否令人满意,因此定义了三个测量损失函数:感知损失,自然损失和JPEG损失。
感知损失,用于图像分类的预训练的深度网络的特征可以很好地描述感知信息;从较低层提取的特征倾向于保留照片上准确的信息,而较高层特征对颜色,纹理和形状差异不变;因此,感知损失被定义来促进和X共享类似的高层特征:
其中,φ是从网络计算的功能,Hφ是特征尺寸。
自然损失,我们希望尽可能恢复无伪像的图像为“自然”图像,因此构建一个附加网络D来区分图像是从建议组件F生成还是一个自然图像;网络D执行二进制分类,并输出输入为“自然”的概率;将这个概率作为测量分量的第二损失加到的负对数上,激励具有高概率:
网络D也需要训练,它使用二进制熵损失作为其优化目标:
从公式(2)和公式(3)可以看出,网络F和网络D彼此竞争:网络F试图生成无伪影的图像其对于网络D难以与自然图像区分,同时训练网络D,避免网络F产生伪像。
JPEG损失,JPEG标准由各种预定义的参数组成,通过利用这些参数,我们可以获得像素值的下限和上限;对于压缩,JPEG编码器通过量化表划分输入图像的DCT系数,然后将结果舍入到最接近的整数;JPEG解码器乘以后面的量化表进行减压;因此,压缩图像Y和对应的未压缩图像X之间的关系可以表示为:
其中,Xdct和Ydct分别是X和Y的DCT系数,Q是量化表,i和j是在DCT域的指标,公式(4)暗示我们写下以下的DCT系数范围约束:
所以每个恢复的无伪影图像也应满足式(5),我们提出以下JPEG损失:
其中,是的尺寸;可以看出,JPEG损失是截短的L2损失;DCT系数落在下限/上限之外(如:)的重构图像将被惩罚。
通过合并这三个损失函数来建立测量组件:
一对多网络使用批量梯度下降进行优化;图像准备为网络输入大小相同的的补丁;将λ1设置为0.1,λ2则需要一些特殊处理;JPEG编码器分别对每个8×8非重叠编码块执行量化;而对于与编码块边界未对准的片,我们不能获得其DCT系数;因此,我们根据给定的补丁设置不同的λ2值;一般来说,网络训练在每个迭代过程中包括两个主要步骤:
1)修正建议分量F,用方程(3)优化判别网络D;
2)修正网络D,用测量分量(即公式(7))优化提议分量F;如果输入块与JPEG编码块边界对准,则将λ2设置为0.1;否则将λ2设置为0。
图2是本发明一种基于一对多网络的减少图像压缩效应的方法的流程示意图。采用一对多网络,其被分解为建议元件和测量元件;建议组件以JPEG压缩图像作为输入,然后输出一系列无伪影的候选图像,由测量组件进一步估计其输出质量。
图3是本发明一种基于一对多网络的减少图像压缩效应的方法的建议组件生成无伪影的候选图像。建议组件提供了一个F模型,将映射F开发为深层CNN;要启用一对多属性,在网络中引入辅助变量Z作为隐藏的附加输入;网络采用压缩图像Y作为输入;同时它从具有标准偏差1的以零为中心的正态分布对Z进行采样,然后将Y和Z两者馈送到网络中以进行非线性映射;
压缩图像Y和采样的Z作为两个不同分支的输入,这两个分支的输出被级联;在级联特征映射之上,进一步执行聚合子网络以生成无伪影预测;
在建议组件中,每个分支包含5个剩余单元,并且聚合子网络包括10个剩余单元;每一个剩余的单位包括两个批量规范化层,两个ReLU层和两个卷积层;
在将压缩图像转发到网络之前,通过步幅-2的4×4卷积层对其进行下采样;最后,网络输出由步幅-2的4×4解卷积层上采样,以保持图像大小。
图4是本发明一种基于一对多网络的减少图像压缩效应的方法的“移动和平均”策略。在建议组件生成无伪影的候选图像的过程中,使用滤波器大小为4的步幅-2解卷积层进行上采样,将过滤器表示[w1,w2,w3,w4];假设对一个输入的常数[…,c,…]应用解卷积,其中c是标量;预期输出应该是常量;然而,实际输出是c*;如果要求实际输出满足预期输出,则训练的过滤器应该满足w1+w3=w2+w4;
要使最终输出为常数,可应用“移动和平均”策略,在获得解卷积输出(表示为deconv)之后,执行以下两个步骤:
1)重复deconv并将其右移1像素;
2)平均deconv和移位版本。
对于本领域技术人员,本发明不限制于上述实施例的细节,在不背离本发明的精神和范围的情况下,能够以其他具体形式实现本发明。此外,本领域的技术人员可以对本发明进行各种改动和变型而不脱离本发明的精神和范围,这些改进和变型也应视为本发明的保护范围。因此,所附权利要求意欲解释为包括优选实施例以及落入本发明范围的所有变更和修改。
- 还没有人留言评论。精彩留言会获得点赞!