一种机房内活跃IP数据的采集方法和装置与流程
本发明涉及IP数据采集技术领域,特别涉及一种机房内活跃IP数据的采集方法和装置。
背景技术:
随着技术的发展,目前已经能够实现通过采集的流量数据形成活跃数据方式,对网络之间互连的协议(Internet Protocol,简称“IP”)数据进行有效采集。
现有技术中,机房的流量采集设备(如,信息安全管理系统EU采集设备)采集上报IP活跃数据中,通常包含有机房外IP数据的“噪音”,严重影响数据质量。流量采集设备通常可以采集到活跃IP数据的属性IP地址、IP访问量、访问端口等,但大量的采集设备由于自身无法分清楚数据流向上下行,因而使活跃IP数据中有大量机房外IP数据,大量的“噪音”数据使得采集到的活跃数据失去原有的数据意义,无法通过采集到的IP数据进行有效分析。因此,需要一种有效的活跃IP数据采集方法,来降低采集到的活跃IP数据中的机房外IP数据,提到采集到的活跃IP数据的有效性。
技术实现要素:
为了解决现有技术的问题,本发明实施例提供了一种机房内活跃IP数据的采集方法和装置。所述技术方案如下:
一方面,本发明实施例提供了一种机房内活跃IP数据的采集方法,所述方法包括:
从原始流量数据中,采集待测的活跃IP及其相应的IP数据;
采用预设的traceroute(即路由跟踪)拨测技术并配合相应的机器学习算法,判断待测的活跃IP是否属于机房内的IP;
剔除待测的活跃IP中的机房外IP,并采集机房内的活跃IP对应的IP数据。
在本发明实施例上述的机房内活跃IP数据的采集方法中,所述采用预设的traceroute拨测技术并配合相应的机器学习算法,判断待测的活跃IP是否属于机房内IP,包括:
从一个预设的起始IP向一个目标IP进行拨测,并记录其访问路程中经由的最后一跳的路由IP及其相应的目标IP,所述目标IP属于待测的活跃IP;
依据预设的Fruchterman-Reingold布局算法,对记录的路由IP进行聚集排布处理;
当选取一定范围内路由IP聚集排布密度大于预设聚集密度标准时,判定选取范围内的路由IP对应的目标IP,属于机房内的IP。
在本发明实施例上述的机房内活跃IP数据的采集方法中,在采集机房内的活跃IP数据之前,所述方法还包括:
检测待测活跃IP的预设单位时间内访问量,并将访问量小于预设访问量标准的待测活跃IP归属于机房外IP;
检测待测活跃IP的访问端口的端口号,并将端口号不规则的待测活跃IP归属于机房外IP。
在本发明实施例上述的机房内活跃IP数据的采集方法中,所述机器学习算法包括:支持向量机、人工神经网络、adaboost中至少一种。
在本发明实施例上述的机房内活跃IP数据的采集方法中,在判断待测的活跃IP数据是否属于机房内IP数据之前,所述方法还包括:
对采集待测的活跃IP数据中重复的IP数据进行去重处理。
另一方面,本发明实施例提供了一种机房内活跃IP数据的采集装置,所述装置包括:
采集模块,用于从原始流量数据中,采集待测的活跃IP及其相应的IP数据;
判断模块,用于采用预设的traceroute拨测技术并配合相应的机器学习算法,判断待测的活跃IP是否属于机房内的IP;
处理模块,用于剔除待测的活跃IP中的机房外IP,并采集机房内的活跃IP对应的IP数据。
在本发明实施例上述的机房内活跃IP数据的采集装置中,所述判断模块包括:
拨测单元,用于从一个预设的起始IP向一个目标IP进行拨测,并记录其访问路程中经由的最后一跳的路由IP及其相应的目标IP,所述目标IP属于待测的活跃IP;
处理单元,用于依据预设的Fruchterman-Reingold布局算法,对记录的路由IP进行聚集排布处理;
判断单元,用于当选取一定范围内路由IP聚集排布密度大于预设聚集密度标准时,判定选取范围内的路由IP对应的目标IP,属于机房内的IP。
在本发明实施例上述的机房内活跃IP数据的采集装置中,所述判断模块,还用于检测待测活跃IP的预设单位时间内访问量,并将访问量小于预设访问量标准的待测活跃IP归属于机房外IP;
所述判断模块,还用于检测待测活跃IP的访问端口的端口号,并将端口号不规则的待测活跃IP归属于机房外IP。
在本发明实施例上述的机房内活跃IP数据的采集装置中,所述机器学习算法包括:支持向量机、人工神经网络、adaboost中至少一种。
在本发明实施例上述的机房内活跃IP数据的采集装置中,所述处理模块,还用于对采集待测的活跃IP数据中重复的IP数据进行去重处理。
本发明实施例提供的技术方案带来的有益效果是:
通过从原始流量数据中,采集待测的活跃IP及其相应的IP数据;采用预设的traceroute(即路由跟踪)拨测技术并配合相应的机器学习算法,判断待测的活跃IP是否属于机房内的IP;剔除待测的活跃IP中的机房外IP,并采集机房内的活跃IP对应的IP数据。这样该机房内活跃IP数据的采集方法,能有效剔除属于机房外的活跃IP,使得采集到的机房内的活跃IP数据准确性和有效性大大提升,为后续的数据分析提供了良好的数据基础。此外,该方法还对采集待测的活跃IP数据中重复的IP数据进行去重处理,并通过检测待测活跃IP的预设单位时间内访问量,将访问量小于预设访问量标准的待测活跃IP归属于机房外IP;通过检测待测活跃IP的访问端口的端口号,将端口号不规则的待测活跃IP归属于机房外IP;进一步筛选出了待测活跃IP数据中的无效数据,更进一步地提高了采集到的活跃IP数据的有效性。
附图说明
为了更清楚地说明本发明实施例中的技术方案,下面将对实施例描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
图1是本发明实施例一提供的一种机房内活跃IP数据的采集方法流程图;
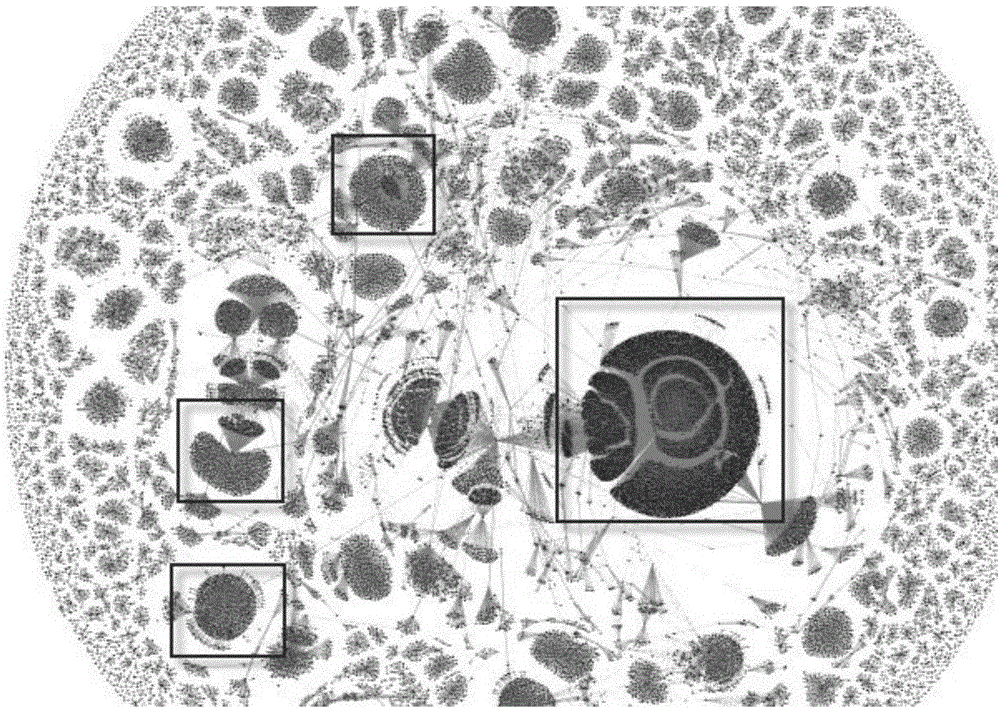
图2是本发明实施例一提供的一种IP聚集排布示例图;
图3是本发明实施例二提供的一种机房内活跃IP数据的采集装置结构示意图;
图4是本发明实施例二提供的一种判断模块的结构示意图。
具体实施方式
为使本发明的目的、技术方案和优点更加清楚,下面将结合附图对本发明实施方式作进一步地详细描述。
实施例一
本发明实施例提供了一种机房内活跃IP数据的采集方法,参见图1,该方法可以包括:
步骤S11,从原始流量数据中,采集待测的活跃IP及其相应的IP数据。
在本实施例中,活跃IP数据的来源是原始流量数据,可以通过各种采集设备采集,如由互联网数据中心(Internet Data Center,简称“IDC”)/互联网服务提供商(Internet Service Provider,简称“ISP”)的信息安全管理体系(Information Security Management System,简称“ISMS”)下辖的执行单元采集原始流量中的数据,并对采集到的数据进行解析,生成活跃IP数据。
需要说明的是,IP活跃数据能够从数据流量中采集大量的IP数据信息,采集的数据是实时存在的客观数据,其数据价值极高,但由于采集技术参差不齐,很多垃圾数据混杂其中,使采集数据的准确度大打折扣,甚至存在大量的重复数据以及非机房内IP数据。因此,需要对IP活跃数据进行去重降噪处理。
步骤S12,对采集待测的活跃IP数据中重复的IP数据进行去重处理。
在本实施例中,对于同一活跃IP采集到的重复数据,可以先对其进行去重处理,以大大降低后续数据处理的计算量,提到后续数据处理的效率。
步骤S13,采用预设的traceroute(即路由跟踪)拨测技术并配合相应的机器学习算法,判断待测的活跃IP是否属于机房内的IP。
在本实施例中,由于所有到达机房内目的IP的路径必然要经过机房的出入口路由,因此,通过对大量待测目的IP进行反复拨测,并产生相应的路径数据,然后,通过路径数据得到路由IP数据,并进一步可以得到机房的关键路由IP,最后,进行聚合关联分析后,从而分析出待测目的IP与所在机房的对应关系。
具体地,在本实施例中,上述步骤S13可以通过如下方式实现:
a,从一个预设的起始IP向一个目标IP进行拨测,并记录其访问路程中经由的最后一跳的路由IP及其相应的目标IP,该目标IP属于待测的活跃IP。
在本实施例中,采用预设的traceroute拨测技术,是先从一个预设的起始IP向一个待测的目标IP进行拨测,并记录其访问路程中经由的最后一跳的路由IP及其相应的目标IP。当然,上述拨测过程是大量重复进行的,记录的最后一跳的路由IP及其相应的目标IP形成的数据可以进行建表储存。
b,依据预设的Fruchterman-Reingold布局算法,对记录的路由IP进行聚集排布处理。
在本实施例中,Fruchterman-Reingold布局算法(简称RF算法),在网络布局算法中,是属于力引导布局算法类别的一种布局算法。在上述步骤a中采集到了大量的路由IP形成的数据,经过Fruchterman-Reingold布局算法进行聚集排布处理,形成了如图2所示的布局(图2仅为一个示例)。在实际应用中,上述聚集排布处理可以通过Gephi软件来进行。
c,当选取一定范围内路由IP聚集排布密度大于预设聚集密度标准时,判定选取范围内的路由IP对应的目标IP,属于机房内的IP。
在本实施例中,由于所有到达机房内目的IP的路径必然要经过机房的出入口路由,因此,属于机房内的IP应该会聚集的较为紧密,而属于机房外的IP则会呈现松散的排列。
需要说明的是,在本实施例中,不仅仅可以通过traceroute拨测技术,来判断活跃IP是否属于机房内IP,还可以通过对活跃IP的访问量以及访问端口的分析,来进一步排除那些明显属于机房外的IP。
步骤S14,检测待测活跃IP的预设单位时间内访问量,并将访问量小于预设访问量标准的待测活跃IP归属于机房外IP。
在本实施例中,单位时间内,部署在机房内的服务器内的服务器往往拥有相对比较大的访问量,而机房外IP,一般指客户IP,一般拥有比较小的访问量,因此,可以根据检测待测活跃IP的预设单位时间内访问量,来排除明显属于机房外的IP。
步骤S15,检测待测活跃IP的访问端口的端口号,并将端口号不规则的待测活跃IP归属于机房外IP。
在本实施例中,机房内IP一般是作为服务器IP,如内容发布服务、邮件服务、远程服务等,会具有比较规则的端口号,而机房外IP一般是源IP(即客户端IP),生产访问请求时,一般为生成比较不规则的端口号。在实际应用中,可以通过采集活跃IP的端口号信息或采用主动端口扫描,检测IP的使用情况,部署在机房内的服务器往往作为网站服务或其他服务,拥有相对比较规则的端口号。
在实际应用中,步骤S14和步骤S15中的两种判断方法单独使用时,其结果的准确性有时难以到达预期目标,为此,一般我们可以将步骤S14与步骤S13,或者,步骤S15与步骤S13,或者,步骤S13至步骤S15结合起来使用,以增强判断结果的准确性。
此外,在上述三种判断方法之外,还可以通过从原始流量数据中还能够提取到包含有URL/域名相关的数据,通过分析处理能够获得内容服务或者网络服务等特征数据,通过这些特征数据能够得到活跃域名与IP关系,而这部分中出现的IP数据往往是机房内IP,因此可以作为依据来判断IP是否机房内IP。
需要说明的是,上述步骤S13-S15中所涉及到的三种判断方法,均可以与预设的机器学习算法相配合,使得判断过程更加智能高效。
具体地,在上述步骤S13-S15中,机器学习算法包括:支持向量机、人工神经网络、adaboost中至少一种。
在本实施例中,支持向量机(Support Vector Machine,即SVM)是与相关的学习算法有关的监督学习模型,可以分析数据,识别模式,它在解决小样本、非线性及高维模式识别中表现出许多特有的优势,并能够推广应用到函数拟合等其他机器学习问题中。人工神经网络(Artificial Neural Network,即ANN)是从信息处理角度对人脑神经元网络进行抽象,建立某种简单模型,按不同的连接方式组成不同的网络。Adaboost是一种迭代算法,其核心思想是针对同一个训练集训练不同的分类器(弱分类器),然后把这些弱分类器集合起来,构成一个更强的最终分类器。
在本实施例中,采用人工智能分析技术,在拥有相对充分的样本数据及充分训练的情况下,能够在大数据分析特征结果的基础上,对大数据量数据拥有更加准确的判断结果,有效的判定一个IP是否机房内IP,对于IP数据处理有着重要意义。
下面简要说明一下,上述判断方法如何与机器学习算法相配合的:
第一步,剔除机房外IP特征数据。根据机房外IP数据特征,一般IP机房外为源IP(即客户端IP),在活跃数据中其特征是端口号随机且访问端口不规则(一般随机生成)。因此采用支持向量机建模,以访问量数量和是否访问特定端口作为输入参量,以一定量的已知数据作为训练数据,训练该模型对输入数据是否是机房外数据进行判断,并将该步骤中判定的机房外IP的数据剔除掉。
第二步,经过第一步剔除处理后,能够得到剔除掉非机房内的IP的数据,这些经过初步剔除处理的数据还需要进行更进一步的分析判断,才能将机房内的IP数据提取出来。因此,可以采用人工神经网络技术和支持向量机SVM技术,对剔除数据进行traceroute技术判定、访问量及常用端口判定、活跃域名出现数据等判定,以提升数据为机房内数据的判断的准确性,具体如下:
(1)根据各个技术判定的输入数据情况,对于traceroute拨测分析可以使用支持向量机的方法:支持向量机的输入是traceroute得到的输入IP的外部IP接入量,输出是判定输入IP是否为机房内IP的结果——(X(接入IP数量),Y(是否机房内IP-0/1)),通过已知数据训练支持向量机,使其能够根据traceroute的结果进一步判断IP是否为机房内IP。
(2)对于是否访问常用端口与访问量合并判断,可以采用人工神经网络技术:在进行人工神经网络训练时,以输入IP的访问量和端口是否规则作为输入,输出结果为该IP是否为机房内IP——(X1(端口是否规则),X2(访问量),Y(是否机房内IP-0/1)),使用已知数据作为培训数据,训练人工神经网络依据输入IP的端口情况、访问量多少对该IP是否机房内IP做出判断,给出判断结果。
(3)对于流量中的内容服务(网站服务)特征判定,即该访问量流量数据中还有URL、域名或访问内容相关特征,则将其判定为机房内IP。但无法区分“上下行”的流量采集设备,可能将爬虫爬取的(机房->机房外)的域名及IP数据记录;单独使用该判断方法无法判断IP是否为机房外。
第三步,通过上一步的处理,我们能够同时得到三个有一定准确度的判定结果——支持向量机依据traceroute的判定结果(1/0)、人工神经网络依据输入IP本身访问量及开放端口规则情况的判定结果(1/0)、直接根据是否在活跃数据中出现域名相关数据判断(1/0)。由于每种单独的特征判断都无法准确判定是否为该IP为机房内IP;因此,需要采用adaboost方式将三种判定结果进行总和,以大量已知数据作为训练样本,将三个判断的判定结果作为输入,训练adaboost模型在各个判断结果的基础上提升判断结果的准确性。
这三步处理中,都用采用了一定量的已知数据作为训练数据,该数据应是真实数据,应同时包含一定量的非机房内数据以及机房内数据,并且,应拥有完整的数据结构,能够查询到其开通端口及访问量情况,能够在活跃域名数据中查询到对应数据,通过traceroute拨测能够获得其相应外部接入IP数量。随后,对支持向量机、人工神经网络、adaboost等模型进行培训的时候,分别依据培训数据的访问量、端口、外部接入IP数量、等因素作为输入特征,判定结果同给定结果进行对比。经由多轮大量训练数据培训过后的判断结果能够最准确的说明一个IP数据是否为机房内IP。
步骤S16,剔除待测的活跃IP中的机房外IP,并采集机房内的活跃IP对应的IP数据。
在本实施例中,通过上述判断方法,将属于机房外的待测活跃IP进行剔除,能有效提高对机房内的活跃IP数据的准确采集,大大提到了采集数据的有效性。在实际应用中,在获取3个以上目标机房的IP数据作为训练前提下,经由已知IP抽样测试,本发明对机房内IP判断的准确率达到90-95%以上。
本发明实施例通过从原始流量数据中,采集待测的活跃IP及其相应的IP数据;采用预设的traceroute(即路由跟踪)拨测技术并配合相应的机器学习算法,判断待测的活跃IP是否属于机房内的IP;剔除待测的活跃IP中的机房外IP,并采集机房内的活跃IP对应的IP数据。这样该机房内活跃IP数据的采集方法,能有效剔除属于机房外的活跃IP,使得采集到的机房内的活跃IP数据准确性和有效性大大提升,为后续的数据分析提供了良好的数据基础。此外,该方法还对采集待测的活跃IP数据中重复的IP数据进行去重处理,并通过检测待测活跃IP的预设单位时间内访问量,将访问量小于预设访问量标准的待测活跃IP归属于机房外IP;通过检测待测活跃IP的访问端口的端口号,将端口号不规则的待测活跃IP归属于机房外IP;进一步筛选出了待测活跃IP数据中的无效数据,更进一步地提高了采集到的活跃IP数据的有效性。
实施例二
本发明实施例提供了一种机房内活跃IP数据的采集装置,采用了实施例一所述的方法,参见图3,该装置可以包括:采集模块100、判断模块200、处理模块300。
采集模块100,用于从原始流量数据中,采集待测的活跃IP及其相应的IP数据。
在本实施例中,活跃IP数据的来源是原始流量数据,可以通过各种采集设备采集,如由IDC/ISP信息安全管理系统ISMS下辖的执行单元EU采集原始流量中的数据,并对采集到的数据进行解析,生成活跃IP数据。
需要说明的是,IP活跃数据能够从数据流量中采集大量的IP数据信息,采集的数据是实时存在的客观数据,其数据价值极高,但由于采集技术参差不齐,很多垃圾数据混杂其中,使采集数据的准确度大打折扣,甚至存在大量的重复数据以及非机房内IP数据。因此,需要对IP活跃数据进行去重降噪处理。
判断模块200,用于采用预设的traceroute(即路由跟踪)拨测技术并配合相应的机器学习算法,判断待测的活跃IP是否属于机房内的IP。
在本实施例中,由于所有到达机房内目的IP的路径必然要经过机房的出入口路由,因此,通过对大量待测目的IP进行反复拨测,并产生相应的路径数据,然后,通过路径数据得到路由IP数据,并进一步可以得到机房的关键路由IP,最后,进行聚合关联分析后,从而分析出待测目的IP与所在机房的对应关系。
处理模块300,用于剔除待测的活跃IP中的机房外IP,并采集机房内的活跃IP对应的IP数据。
在本实施例中,通过上述判断方法,将属于机房外的待测活跃IP进行剔除,能有效提高对机房内的活跃IP数据的准确采集,大大提到了采集数据的有效性。在实际应用中,在获取3个以上目标机房的IP数据作为训练前提下,经由已知IP抽样测试,本发明对机房内IP判断的准确率达到90-95%以上。
具体地,参见图4,该判断模块200可以包括:拨测单元201、处理单元202、判断单元203。
拨测单元201,用于从一个预设的起始IP向一个目标IP进行拨测,并记录其访问路程中经由的最后一跳的路由IP及其相应的目标IP,该目标IP属于待测的活跃IP。
在本实施例中,采用预设的traceroute拨测技术,是先从一个预设的起始IP向一个待测的目标IP进行拨测,并记录其访问路程中经由的最后一跳的路由IP及其相应的目标IP。当然,上述拨测过程是大量重复进行的,记录的最后一跳的路由IP及其相应的目标IP形成的数据可以进行建表储存。
处理单元202,用于依据预设的Fruchterman-Reingold布局算法,对记录的路由IP进行聚集排布处理。
在本实施例中,Fruchterman-Reingold布局算法(简称RF算法),在网络布局算法中,是属于力引导布局算法类别的一种布局算法。在上述步骤a中采集到了大量的路由IP形成的数据,经过Fruchterman-Reingold布局算法进行聚集排布处理。在实际应用中,上述聚集排布处理可以通过Gephi软件来进行。
判断单元203,用于当选取一定范围内路由IP聚集排布密度大于预设聚集密度标准时,判定选取范围内的路由IP对应的目标IP,属于机房内的IP。
在本实施例中,由于所有到达机房内目的IP的路径必然要经过机房的出入口路由,因此,属于机房内的IP应该会聚集的较为紧密,而属于机房外的IP则会呈现松散的排列。
需要说明的是,在本实施例中,不仅仅可以通过traceroute拨测技术,来判断活跃IP是否属于机房内IP,还可以通过对活跃IP的访问量以及访问端口的分析,来进一步排除那些明显属于机房外的IP。
进一步地,判断模块200,还用于检测待测活跃IP的预设单位时间内访问量,并将访问量小于预设访问量标准的待测活跃IP归属于机房外IP。
在本实施例中,单位时间内,部署在机房内的服务器内的服务器往往拥有相对比较大的访问量,而机房外IP,一般指客户IP,一般拥有比较小的访问量,因此,可以根据检测待测活跃IP的预设单位时间内访问量,来排除明显属于机房外的IP。
判断模块200,还用于检测待测活跃IP的访问端口的端口号,并将端口号不规则的待测活跃IP归属于机房外IP。
在本实施例中,机房内IP一般是作为服务器IP,如内容发布服务、邮件服务、远程服务等,会具有比较规则的端口号,而机房外IP一般是源IP(即客户端IP),生产访问请求时,一般为生成比较不规则的端口号。在实际应用中,可以通过采集活跃IP的端口号信息或采用主动端口扫描,检测IP的使用情况,部署在机房内的服务器往往作为网站服务或其他服务,拥有相对比较规则的端口号。
可选地,机器学习算法包括:支持向量机、人工神经网络、adaboost中至少一种。
在本实施例中,采用人工智能分析技术,在拥有相对充分的样本数据及充分训练的情况下,能够在大数据分析特征结果的基础上,对大数据量数据拥有更加准确的判断结果,有效的判定一个IP是否机房内IP,对于IP数据处理有着重要意义。
可选地,处理模块300,还用于对采集待测的活跃IP数据中重复的IP数据进行去重处理。
在本实施例中,对于同一活跃IP采集到的重复数据,可以先对其进行去重处理,以大大降低后续数据处理的计算量,提到后续数据处理的效率。
本发明实施例通过从原始流量数据中,采集待测的活跃IP及其相应的IP数据;采用预设的traceroute(即路由跟踪)拨测技术并配合相应的机器学习算法,判断待测的活跃IP是否属于机房内的IP;剔除待测的活跃IP中的机房外IP,并采集机房内的活跃IP对应的IP数据。这样该机房内活跃IP数据的采集装置,能有效剔除属于机房外的活跃IP,使得采集到的机房内的活跃IP数据准确性和有效性大大提升,为后续的数据分析提供了良好的数据基础。此外,该装置还对采集待测的活跃IP数据中重复的IP数据进行去重处理,并通过检测待测活跃IP的预设单位时间内访问量,将访问量小于预设访问量标准的待测活跃IP归属于机房外IP;通过检测待测活跃IP的访问端口的端口号,将端口号不规则的待测活跃IP归属于机房外IP;进一步筛选出了待测活跃IP数据中的无效数据,更进一步地提高了采集到的活跃IP数据的有效性。
上述本发明实施例序号仅仅为了描述,不代表实施例的优劣。
需要说明的是:上述实施例提供的机房内活跃IP数据的采集装置在实现机房内活跃IP数据的采集方法时,仅以上述各功能模块的划分进行举例说明,实际应用中,可以根据需要而将上述功能分配由不同的功能模块完成,即将设备的内部结构划分成不同的功能模块,以完成以上描述的全部或者部分功能。另外,上述实施例提供的机房内活跃IP数据的采集装置与机房内活跃IP数据的采集方法实施例属于同一构思,其具体实现过程详见方法实施例,这里不再赘述。
本领域普通技术人员可以理解实现上述实施例的全部或部分步骤可以通过硬件来完成,也可以通过程序来指令相关的硬件完成,所述的程序可以存储于一种计算机可读存储介质中,上述提到的存储介质可以是只读存储器,磁盘或光盘等。
以上所述仅为本发明的较佳实施例,并不用以限制本发明,凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!