基于混合扫描顺序的光场图像压缩方法与流程
本发明涉及光场图像压缩技术领域,尤其涉及一种基于混合扫描顺序的光场图像压缩方法。
背景技术:
光场相机可以记录下空间场景中的光线强度和方向信息(即光场信息)。在光场相机内部,一个微透镜阵列被放置在CCD传感器前方,并位于主透镜的焦距附近。每个微透镜对应于一个像素块(即宏像素),光场图像由N*M个宏像素组成,其中N和M分别为微透镜阵列的高和宽。若将每个微透镜视为小孔,则主透镜背面在每个宏像素上成倒立的像——即每个宏像素可视为对主透镜在特定方向上的一个采样。
相同空间分辨率下,数据量要数百倍于传统2D图像(二代光场相机拍摄单幅YUV图像大小50M左右),这是制约光场技术应用的一个重要因素。因此一套光场图像的高效压缩方案对于图像的存储传输是必须的。
一个直接的压缩方案是将宏像素阵列视为2D图像,使用传统的JPEG标准压缩。很显然这种方法无法充分利用光场本身的结构特征。实际操作中亦不能取得很好的压缩效果。
基于量化和小波变换的技术,将图像做DCT或小波变换后对系数进行量化编码,去除视差冗余。该方法往往在接收端需要将光场图像全部或大部分重建,因此接收端渲染时间长、无法实时支持一些光场特有操作(如,切换任意视角)。
Multiview-coding(MVC)技术亦被使用在光场编码中,但现有方案仅考虑计算生成光场图像。计算生成与自然拍摄的光场图像相比视角少(前者通常仅包含10个视角以内,后者多达上百)。因此MVC编码技术在自然拍摄光场图像上直接应用,存在运算复杂度过高的问题,且因产生大量头信息导致编码效率低。
技术实现要素:
本发明的目的是提供一种基于混合扫描顺序的光场图像压缩方法,显著提升了压缩效果。
本发明的目的是通过以下技术方案实现的:
一种基于混合扫描顺序的光场图像压缩方法,包括:
将光场图像分解为二维的视角图阵列;
对于二维的视角图阵列中不规则区域使用横向zigzag扫描方式,在规则区域使用U形扫描方式,从而将二维的视角图阵列合成为伪视频序列;
再利用标准视频编码器采用视频帧间编码和/或帧内编码方式对伪视频序列进行压缩编码。
所述将光场图像分解为二维的视角图阵列包括:
将光场图像去马赛克后,进行旋转拉伸,使得光场图像中的宏像素长宽像素个数相同;
在不同宏像素中的相同位置提取像素,从而构成二维的视角图阵列。
由上述本发明提供的技术方案可以看出,将光场图像分解为视频,能够通过视频帧间编码和帧内编码,充分发掘利用视角图之间的信息冗余,对光场图像进行高效压缩编码;依据实际拍摄得到的视角图排列方式,设计特定的混合扫描方式,使得伪视频序列中相邻帧之间的相似性更高,进一步提高了编码效果。
附图说明
为了更清楚地说明本发明实施例的技术方案,下面将对实施例描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域的普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他附图。
图1为本发明实施例提供的基于混合扫描顺序的光场图像压缩方法的流程图;
图2为本发明实施例提供的提取不同宏像素中的相同位置像素来构成二维的视角图阵列的示意图;
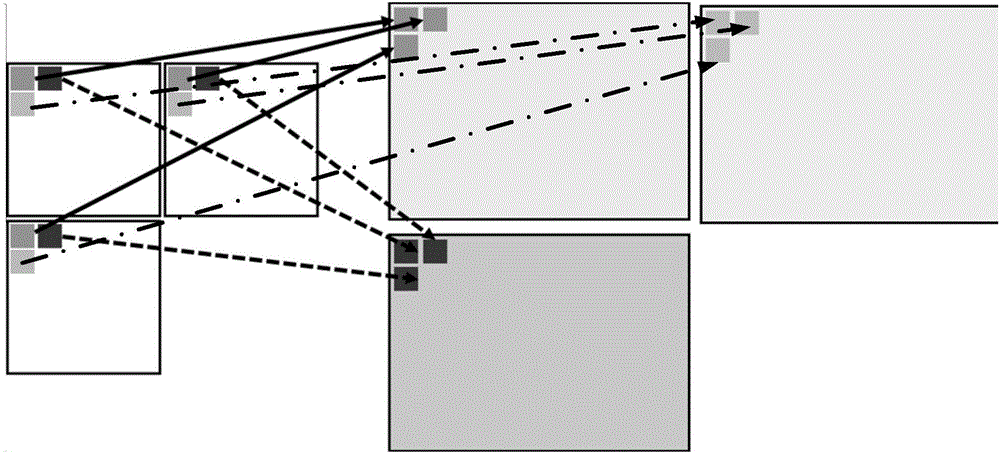
图3为本发明实施例提供的混合扫描方式的示意图。
具体实施方式
下面结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明的保护范围。
图1为本发明实施例提供的基于混合扫描顺序的光场图像压缩方法的流程图,如图1所示,其主要包括如下步骤:
步骤11、将光场图像分解为二维的视角图阵列。
一副光场图像由宏像素组成,每个宏像素可以视为对主透镜的采样,因此每个宏像素中相同位置的像素可以视为对主透镜相同位置的不同方向光线的采样。将不同宏像素块相同位置的像素点取出组成二维图像,构成从特定主透镜区域对场景观察结果,即视角图。
本步骤的具体处理过程如下:
1)将光场图像去马赛克后,进行旋转拉伸,使得光场图像中的宏像素长宽像素个数相同。
2)如图2所示,在不同宏像素中的相同位置提取像素,从而构成二维的视角图阵列。
步骤12、对于二维的视角图阵列中不规则区域使用横向zigzag扫描方式,在规则区域使用U形扫描方式,从而将二维的视角图阵列合成为伪视频序列。
将二维的视角图阵列合成伪视频序列,须要注意到原本的视角图实际排列为二维阵列,相邻的视角图之间的信息冗余更高,为了使得伪视频序列中的前后帧在实际的视角图阵列中位置更为接近本发明实施例提出了混合扫描方式,即不规则区域使用横向zigzag扫描方式,在规则区域使用U形扫描方式。
如图3所示为混合扫描方式的示意图,从黑点出发,按照箭头线逐个扫描遍历所有图像。由于实际拍摄得到的光场图像宏像素可能存在黑边(即图3左上、右上、左下、右下所示的没有包含任何有效信息的像素点),因此分解图像会得到一些黑色的视角图。在混合扫描过程中我们会跳过这些无效图像。
步骤13、再利用标准视频编码器采用视频帧间编码和/或帧内编码方式对伪视频序列进行压缩编码。
本领域技术人员可以理解,标准视频编码器为常规视频编码器,例如,HEVC或JEM。
压缩编码后获得的码流文件,可以根据实际需求存储或者传输。
如果进行传输,则在接收端使用相应的解码器进行解码时,按照照混合扫描方式的对应关系,从视频序列中恢复出视角图阵列,进而得到原始光场图像。
本发明实施例的上述方案,主要具有如下优点:
1)将光场图像分解为视频,能够通过视频帧间编码和帧内编码,充分发掘利用视角图之间的信息冗余,对光场图像进行高效压缩编码;依据实际拍摄得到的视角图排列方式,设计特定的混合扫描方式,使得伪视频序列中相邻帧之间的相似性更高,进一步提高了编码效果。
2)相对于传统的JPEG标准压缩,本发明实施例上述方案的压缩效果显著提升,且在低码率时可以提供更好的视觉体验和主观感受。
3)与已有的基于DCT或小波变换的压缩方案对比,本发明实施例上述方案无需在压缩性能和光场视角随机访问之间做权衡,且与光场图像拍摄参数无关。最后一点尤其重要,因为各类型相机的参数相差极大,如Lytro和相机阵列的构造完全不同;即使是Lytro同代产品的不同相机个体,其相机微透镜阵列的参数也因为目前的工艺水平而存在差异。
4)相对于MVC编码方案,本发明实施例上述方案的复杂度与视角个数是线性关系,计算资源的需求也大为降低;未来的光场图像角度分辨率(即视角个数)会继续增长以满足场景重建需求,因此本发明方法具有良好的可扩展性。
另一方面,为了说明上述方案的效果还进行了验证实验。
本实验中使用公开光场数据集EPFL中的12幅光场图像进行分解和压缩,这些光场图像均由Lytro二代相机拍摄得到。
采用本发明上述实施例的方式对这些光场图像进行压缩编码,编码器设置帧结构为“IPPP……”(I代表帧内编码帧,P代表前向预测编码帧,IPPP….表示低时延编码结构,即在编码时只有第一帧采用帧内预测,剩余帧都采用前向预测),GOP(即图像组,在对视频进行压缩时,要先将视频序列分割为若干的组图像,分别对各组图像进行压缩)大小设置为10。此外,还使用传统的JPEG标准压缩方式对光场图像直接进行压缩,压缩率取10,20,40和100,同时调整QP(量化参数)使码率对齐。BD-PSNR(表示码率和失真之间的关系,其中失真用PSNR(峰值信噪比)来衡量)结果如下表1所示:
表1本发明方案的压缩效率与传统的JPEG标准压缩方式对比
此外,将QP固定为50时本发明提供平均压缩率为7107,平均PSNR为27.79dB。而传统的JPEG标准压缩方式在压缩率为100时平均PSNR为25.51dB。更重要的是,本发明方案可以在低码率是提供更好的主观视觉效果。
通过以上的实施方式的描述,本领域的技术人员可以清楚地了解到上述实施例可以通过软件实现,也可以借助软件加必要的通用硬件平台的方式来实现。基于这样的理解,上述实施例的技术方案可以以软件产品的形式体现出来,该软件产品可以存储在一个非易失性存储介质(可以是CD-ROM,U盘,移动硬盘等)中,包括若干指令用以使得一台计算机设备(可以是个人计算机,服务器,或者网络设备等)执行本发明各个实施例所述的方法。
以上所述,仅为本发明较佳的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明披露的技术范围内,可轻易想到的变化或替换,都应涵盖在本发明的保护范围之内。因此,本发明的保护范围应该以权利要求书的保护范围为准。
- 还没有人留言评论。精彩留言会获得点赞!