广播电视节目推荐系统及方法与流程
本发明涉及广播电视领域,更为具体地,涉及一种广播电视节目推荐系统及方法。
背景技术:
广播电视节目资源的极大丰富,带来了收视用户的节目类型偏好多样化,对用户进行分群,找到具有不同收视偏好的用户群体,进行个性节目推荐,是广播电视领域亟待解决的问题。在传统广播电视领域,对用户收视行为研究采用电话随机调查法或日记记录法,无法建立全网用户的采集样本数据,节目推荐技术的研究进展缓慢。随着广播电视数字化时代的到来,全网用户收视数据和节目播出数据库的建立,以及数据挖掘技术的急速发展,电视节目推荐技术的研究迎来契机。
现有的个性化推荐方法主要包括协同过滤推荐和基于内容的推荐,这两种方法重点在于如何获取用户的历史行为信息,如何表征目标项目的特征信息,以及如何将用户兴趣和项目特征信息相对应,但由于数据稀疏性和冷启动问题,推荐效果具有很大的局限性,例如,没有考虑不同兴趣偏好的用户信息干扰推荐效果,没有考虑网络拓扑结构对推荐效果的影响。
技术实现要素:
鉴于上述问题,本发明的目的是提供考虑不同用户对不同节目的收视偏好和网络拓扑结构,降低推荐效果的局限性的广播电视节目推荐系统及方法。
根据本发明的一个方面,提供一种广播电视节目推荐系统,包括:输入单元,输入预推荐客体、收视偏好指标以及收视时间段,其中,预推荐客体集合为U={u1,...,ui...,un},其中,ui为推荐客体中的用户;节目数据库,将上述收视时间段内各节目的播放信息存储为节目数据源,其中,播放节目的集合为S={s1,...,sj...,sm};收视数据库,将预推荐客体在上述收视时间段内的收视信息存储为收视数据源;收视偏好空间构建模块,分别从节目数据库和收视数据库调取计算收视偏好指标所需的节目数据源和收视数据源,计算预推荐客体内各用户的收视偏好指标,构成收视偏好矩阵,即,收视偏好空间;连接网络构建模块,根据上述收视偏好矩阵计算预推荐客体中用户之间的连接关系值,以每一个用户为节点,当用户之间的连接关系值大于设定阈值时,在两个用户之间建立路径,形成预推荐客体中不同用户之间的连接网络;信任度确定单元,根据上述连接网络中的节点和路径确定不同用户之间的信任度,其中,
其中,tp(ui,uj)表示用户ui和uj之间的信任度,trust(ui,uj)表示对信任度tp(ui,uj)进行归一化处理结果,trust(ui,uj)∈[0,1];sig(·)为符号函数,其定义为Mpd表示用户之间的平均路径长度,符号表示向上取整运算,对于节点数为Nnode边数Nedge的连接网络,其任意两点间的平均路径长度step表示可达路径上用户ui到uj的跳数;ui->uj表示用户ui到用户ui的路径;节目推荐度确定单元,根据信任度确定单元获得的不同用户之间的信任度和不同用户对不同节目的收视偏好确定不同用户对不同节目的推荐度,其中,用户ui对节目sj的收视偏好,表示为用户ui推荐节目sj的节目推荐度;节目单生成单元,分别以预推荐客体中的每一个用户为节点,按照与所述每一个用户的信任度由高到低的顺序选取设定数量的用户,按照所述设定数量的用户对不同节目的推荐度由高到低的顺序选取设定数量的节目,生成所述每一个用户的节目单。
根据本发明的另一个方面,提供一种广播电视节目推荐方法,包括:输入预推荐客体、收视偏好指标以及收视时间段,其中,预推荐客体集合为U={u1,...,ui...,un},其中,ui为推荐客体中的用户;将上述收视时间段内各节目的播放信息存储为节目数据源,其中,播放节目的集合为S={s1,...,sj...,sm};将预推荐客体在上述收视时间段内的收视信息存储为收视数据源;调取计算收视偏好指标所需的节目数据源和收视数据源,计算预推荐客体内各用户的收视偏好指标,构成收视偏好矩阵;根据上述收视偏好矩阵计算预推荐客体中用户之间的连接关系值,以每一个用户为节点,当用户之间的连接关系值大于设定阈值时,在两个用户之间建立路径,形成预推荐客体中不同用户之间的连接网络;根据连接网络中的节点和路径确定不同用户之间的信任度,其中,
其中,tp(ui,uj)表示用户ui和uj之间的信任度,trust(ui,uj)表示对信任度tp(ui,uj)进行归一化处理结果,trust(ui,uj)∈[0,1];sig(·)为符号函数,其定义为Mpd表示用户间的平均路径长度,符号表示向上取整运算,对于节点数为Nnode边数Nedge的连接网络,其任意两点间的平均路径长度step表示可达路径上用户ui到uj的跳数;ui->uj表示用户ui到用户ui的路径;根据不同用户之间的信任度和不同用户对不同节目的收视偏好确定不同用户对不同节目的推荐度,其中,用户ui对节目sj的收视偏好,表示为用户ui推荐节目sj的节目推荐度;以预推荐客体中的每一个用户为节点,按照与所述每一个用户的信任度由高到低的顺序选取设定数量的用户,按照所述设定数量的用户对不同节目的推荐度由高到低的顺序选取设定数量的节目,生成所述每一个用户的节目单。
本发明所述广播电视节目推荐系统及方法根据不同用户对不同节目的收视偏好构建网络拓扑结构的连接网络,并根据所述连接网络的结构(节点和路径)确定不同用户对不同节目的推荐度,降低了推荐的局限性,增加了推荐的准确性。
附图说明
通过参考以下结合附图的说明,并且随着对本发明的更全面理解,本发明的其它目的及结果将更加明白及易于理解。在附图中:
图1是本发明广播电视节目推荐方法的流程图;
图2是本发明广播电视节目推荐方法一个优选实施例的流程图;
图3a和3b是本发明采用串联节点优化法优化连接网络的示意图;
图4a和4b是本发明采用分叉节点优化方法优化连接网络的示意图;
图5a和5b是本发明采用合并节点优化方法优化连接网络的示意图;
图6是本发明广播电视节目推荐系统的构成框图;
图7是广播电视节目推荐系统一个优选实施例的构成框图;
图8是本发明平均绝对值误差评定指标和设定阈值的关系示意图;
图9是本发明平均绝对值误差评定指标、社区稠密性系数和社区的设定数量的关系示意图。
在所有附图中相同的标号指示相似或相应的特征或功能。
具体实施方式
在下面的描述中,出于说明的目的,为了提供对一个或多个实施例的全面理解,阐述了许多具体细节。然而,很明显,也可以在没有这些具体细节的情况下实现这些实施例。以下将结合附图对本发明的具体实施例进行详细描述。
以下将结合附图对本发明的具体实施例进行详细描述。
图1是本发明广播电视节目推荐方法的流程图,如图1所示,所述广播电视节目推荐方法,包括:
在步骤S100中,输入预推荐客体、收视偏好指标以及收视时间段(例如,2003年1月1日至2014年1月1日),其中,预推荐客体集合为U={u1,...,ui...,un},ui为预推荐客体中的用户;所述收视偏好指标包括收视时长、收视占比等,其中,收视占比是指某类节目单位播出时间内,用户的收视时长。
在步骤S110中,将上述收视时间段内各节目的播放信息存储为节目数据源,其中,播放节目的集合为S={s1,...,sj...,sm},优选地,所述播放信息还包括从网站上采集各节目的节目标签的集合T={t1,...,tk...,tq},节目标签是对电视节目内容的多角度概括。
在步骤S120中,将预推荐客体在上述收视时间段内的收视信息存储为收视数据源。
在步骤S130中,调取计算收视偏好指标所需的节目数据源和收视数据源,计算预推荐客体内各用户的收视偏好指标,构成收视偏好矩阵,以收视占比为例进行说明,计算收视偏好指标所需的节目数据源为节目播出时长矩阵为在收视时间段内节目sj播出的总时长,收视数据源为节目收视时长矩阵表示用户ui在指定时间内收看节目sj的总时长,收视占比优选地,所述计算预推荐客体内各用户的收视偏好指标的方法包括以下步骤中的一个或多个:根据用户收视数据和节目播出数据计算节目兴趣偏好;采用词频-逆向节目频率算法计算节目标签权重;通过节目兴趣偏好和节目标签权重,计算节目标签兴趣偏好,其中,
其中,为用户ui对节目标签tk的兴趣度,值越大,用户对该节目类型的兴趣越高;为用户ui对节目sj的兴趣度,为用户ui对所有节目的收视占比均值;为节目sj所含标签tk的权重值,对节目sj标注的频率越高且对其他节目标注越少,则权重值越高,表示采用标签tk对节目sj标注的网站个数,表示节目sj所有标签在不同网站出现的个数之和,为节目集合中包含标签tk的节目数量,所述收视偏好指标可以是和的一个或多个。
在步骤S140中,根据上述收视偏好矩阵计算预推荐客体中用户之间的连接关系值,以每一个用户为节点,当用户之间的连接关系值大于设定阈值时,在两个用户之间建立路径,形成预推荐客体中不同用户之间的连接网络。
在步骤S150中,根据连接网络中的节点和路径确定不同用户之间的信任度,其中,
其中,tp(ui,uj)表示用户ui和uj之间的信任度,trust(ui,uj)表示对信任度tp(ui,uj)进行归一化处理结果,trust(ui,uj)∈[0,1];sig(·)为符号函数,其定义为Mpd表示用户间的平均路径长度,符号表示向上取整运算,对于节点数为Nnode边数Nedge的连接网络,其任意两点间的平均路径长度step表示可达路径上用户ui到uj的跳数;ui->uj表示用户ui到用户ui的路径。
在步骤S160中,根据不同用户之间的信任度和不同用户对不同节目的收视偏好确定不同用户对不同节目的推荐度,
其中,用户ui对节目sj的收视偏好指标,表示为用户ui推荐节目sj的节目推荐度,值越大表明向用户推荐优先级越高;
在步骤S170中,以预推荐客体中的每一个用户为节点,按照与所述每一个用户的信任度由高到低的顺序选取设定数量的用户,按照所述设定数量的用户对不同节目的推荐度由高到低的顺序选取设定数量的节目,生成所述每一个用户的节目单。
在步骤S140中,优选地,包括构建关系网络方法和构建相似网络方法中的一种或两种,所述连接关系值包括关系键和相似度中的一个或两个,所述连接网络包括关系网络和相似网络中的一个或两个,其中,
所述构建关系网络的方法包括:根据收视偏好矩阵确定用户之间的关系键,当用户之间的关系键大于设定关系键阈值时,在用户之间建立路径,当用户之间的关系键不大于设定关系键阈值时,在用户之间不建立路径,从而形成不同用户之间的关系网络,其中,
其中,表示对收视偏好进行归一化处理后结果,表示用户ui与用户uj的关系键,值越大表明用户共同收看的节目类型越多,用户信任关系越紧密,为用户ui和用户uj共同收看的节目的集合;
构建相似网络的方法包括:根据收视偏好矩阵确定不同用户之间的相似度,构建用户相似度矩阵,当用户之间的相似度大于设定相似度阈值时,在用户之间建立路径,当用户之间的相似度不大于设定相似度阈值时,在用户之间不建立路径,从而形成不同用户之间的相似网络,其中
其中,d(ui,uj)表示用户ui与用户uj之间的欧式距离,σ为尺度参数,Aij表示用户ui与用户uj之间的相似度。
进一步,优选地,步骤S140中,既构建相似网络又构建关系网络时,在步骤S170中,包括:分别以预推荐客体中每一个用户为节点,在关系网络中按照与所述每一个用户的信任度由高到低的顺序选取设定数量的第一组用户,按照第一组用户对不同节目的推荐度由高到低的顺序选取设定数量的第一组节目;分别以预推荐客体中每一个用户为节点,在相似网络中按照与所述每一个用户的信任度由高到低的顺序选取设定数量的第二组用户,按照第二组用户对不同节目的推荐度由高到低的顺序选取设定数量的第二组节目;所述第一组节目和第二组节目的交集作为所述每一个用户的节目单,形成预推荐客体中每一个用户的节目单。
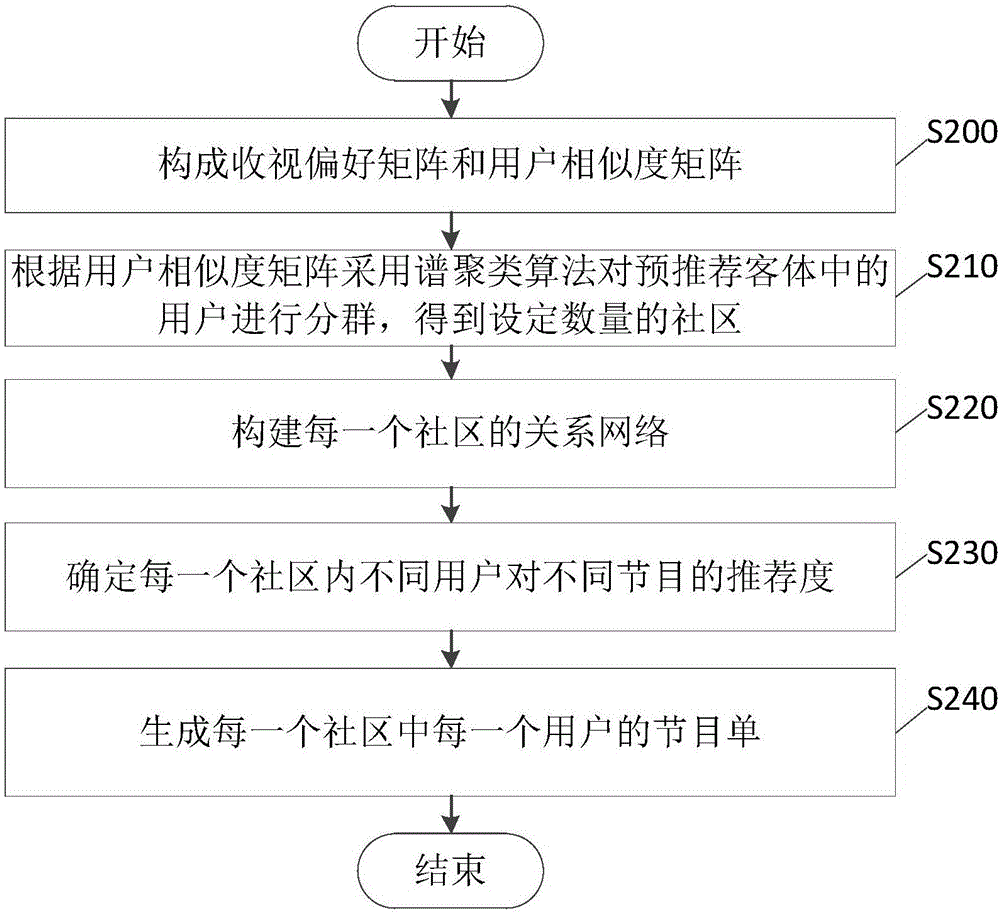
在本发明的一个优选实施例中,如图2所示,所述节目推荐方法包括:
在步骤S200中,调取计算收视偏好指标所需的节目数据源和收视数据源,计算预推荐客体内各用户的收视偏好指标,构成收视偏好矩阵,根据收视偏好矩阵确定不同用户之间的相似度,构建用户相似度矩阵,例如,根据用户对节目标签的兴趣度构建用户相似度矩阵,也就是说,
在步骤S210中,根据所述用户相似度矩阵,采用谱聚类算法对预推荐客体中的用户进行分群,得到设定数量的社区,例如,对高斯核相似度矩阵A进行对角变换,构建对角矩阵D,通过矩阵乘法,计算高斯核相似度矩阵A的Laplacian矩阵L,
找出Laplacian矩阵L的前a个最大特征值对应的特征向量Va,其中,L*Va=λ*Va,λ、Va分别表示矩阵L的特征值和特征向量,a值等于用户分群数目,1≤a≤n;
对特征向量Va进行行归一化处理,得到用户分群矩阵Y,
将用户分群矩阵Y的每一行看作是Rk空间中的一个点,对其使用K-MEANS算法得到K个聚类,将数据点yi划分到聚类j中,当且仅当Y的第i行被划分到聚类j中,即得到K个社区;
在步骤S220中,在每一个社区中,分别以每一个用户为节点,根据收视偏好矩阵所述每一用户与其他用户之间的关系键,当关系键大于设定关系键阈值时,在用户之间建立路径,形成每一个社区的关系网络,优选地,通过不同用户对节目标签的兴趣度确定不同用户之间的关系键,
其中,表示对节目类型tk进行归一化处理后结果,表示节目类型tk的信息熵,表示节目类型tk的变异系数,表示节目类型tk的重要性,为用户ui和用户uj共同收看的节目标签的集合;
在步骤S230中,在每一个社区内,根据社区的关系网络中的节点和路径确定每一个社区内不同用户之间的信任度,从而确定每一个社区内不同用户对不同节目的推荐度,优选地,所述推荐度还包括节目标签的推荐度,进一步,优选地,还可以通过节目标签的推荐度来确定节目的推荐度,其中
其中,表示为用户ui对节目标签tk的推荐度,为标准化因子;
在步骤S240中,在每一个社区中,分别以每一个用户为节点,按照与所述每一个用户的信任度由高到低的顺序选取设定数量的用户,按照所述设定数量的用户对不同节目的推荐度由高到低的顺序选取设定数量的节目,生成每一个社区中每一个用户的节目单。
在图1和图2示出的两个实施例中,采用图2所示的节目推荐方法(第二种节目推荐方法)较图1所示的节目推荐方法(第一种节目推荐方法)更具有针对性,推荐效果更好,其中,
第一种节目推荐方法用户对象集为U={u1,...,ui...,un},第一种节目推荐方法的全局质量函数为其中,uφ为全局数据中心,
第二种节目推荐方法的用户聚类为C={c1,...,cj…,cK},其中,C为社区的集合,用户聚类质量度量函数其中Nj为第j个聚类cj中的对象个数,为第j个聚类cj中的聚类中心,
因为所以用户聚类质量函数Ec≤全局质量函数Eall,越接近聚类中心的对象和,越能体现的该聚类中心的兴趣偏好,针对该聚类中心的推荐就越对这些对象有效果和针对性,因此,聚类质量度量函数E越小,表示聚类的质量越好,推荐的效果也就越好。
为了保证建立连接关系的设定阈值和社区数的准确性,优选地,所述节目推荐方法还包括一下步骤中的一个或两个:
根据平均用户连接关系值和平均绝对值误差评定指标调整所述设定阈值,其中,平均绝对误差指标(Mean Absolute Error,MAE),
其中,MAE越小,用户实际评分和预测评分的偏差越小,说明推荐精准度越高,表示用户ui对节目sj的实际收视偏好,详细地将在图8的说明中进行描述;
根据平均绝对值误差评定指标和社区稠密性系数调整所述社区的设定数量,所述社区的数量越多,所述社区稠密性系数越大,所述MAE值越小,节目推荐的准确性越高,详细地将在图9的说明中进行描述。
为了使得连接网络与用户的收视偏好更加符合,优选地,如图3-5所示,所述节目推荐方法还包括一下步骤中的一种或多种:
根据串联节点优化方法对连接网络进行优化,具体地,将连接网络中连接关系为串联的节点称为串联节点,当两个串联节点之间存在直接连接路径和通过其他节点相连的间接路径时,比较间接路径上多个串联节点之间的连接关系值乘积与直接连接路径上两个串联节点之间的连接关系值,当所述乘积大于所述直接连接路径的连接关系值时,去掉直接连接路径,以关系键为例进行说明,如图3a所示,当节点u1与u3除一条直接路径外,还通过u2存在一条间接路径,u2作为中间人联系着u1和u3,当时,去掉节点u1与u3间的直接路径(图3b示出);
根据交叉节点优化方法对连接网络进行优化,具体地,在连接网络中,一个节点通过另一个节点与其他多个节点连接,所述另一个节点称为分叉节点,生成分叉节点的克隆节点,从而使得所述一个节点与所述其他多个节点通过克隆节点和分叉节点形成多条路径,其中,所述克隆节点与其他节点的连接关系值和所述分叉节点与其他节点的连接关系值相等,如图4a所示,当节点u1通过u2与u3、u4存在连接关系时,u2为分叉节点,生成分叉节点u2的克隆节点u′2,并将原u2与u4的关系键移植到u′2与u4的关系键,原u1与u2的关系键复制到u1与u′2的关系键形成u1到u4的两条间接路径(图4b示出);
根据合并节点优化方法对连接网络进行优化,具体地,在连接网络中,多个节点均通过一个节点与另一个节点连接,所述一个节点为合并节点,生成合并节点的克隆节点,从而使得所述多个节点分别通过合并节点和克隆节点形成到所述另一个节点的多条路径,其中,所述克隆节点与其他节点的连接关系值和所述合并节点与其他节点的连接关系值相等,如图5a所示,当节点u1、u2通过u3与u4存在连接关系时,u3为合并节点,生成合并节点u3的克隆节点u′3,并将原u2与u3的关系键移植到u2与u′3的关系键原u3与u4的关系键复制到u′3与u4的关系键形成u1到u4以及u2到u4的两条间接路径(图5b示出)。
图6是本发明所述节目推荐系统的构成框图,如图6所示,所述节目推荐系统100包括:
输入单元110,输入预推荐客体、收视偏好指标以及收视时间段;
节目数据库120,将上述收视时间段内各节目的播放信息存储为节目数据源;
收视数据库130,将预推荐客体在上述收视时间段内的收视信息存储为收视数据源,
收视偏好空间构建模块140,分别从节目数据库120和收视数据库130调取计算收视偏好指标所需的节目数据源和收视数据源,计算预推荐客体内各用户的收视偏好指标,构成收视偏好矩阵,即,收视偏好空间;
连接网络构建模块150,根据上述收视偏好空间构建模块140构建的收视偏好矩阵计算预推荐客体中用户之间的连接关系值,以每一个用户为节点,当用户之间的连接关系值大于设定阈值时,在两个用户之间建立路径,形成预推荐客体中不同用户之间的连接网络,优选地,所述连接网络构建模块150包括关系网络构建单元151或相似网络构建单元152,所述连接关系值包括关系键或相似度,所述连接网络包括关系网络或相似网络,其中,所述关系网络构建单元151,根据收视偏好矩阵确定用户之间的关系键,当用户之间的关系键大于设定关系键阈值时,在用户之间建立路径,当用户之间的关系键不大于设定关系键阈值时,在用户之间不建立路径,从而形成不同用户之间的关系网络;所述相似网络构建单元152,根据收视偏好矩阵确定不同用户之间的相似度,构建用户相似度矩阵,当用户之间的相似度大于设定相似度阈值时,在用户之间建立路径,当用户之间的相似度不大于设定相似度阈值时,在用户之间不建立路径,从而形成不同用户之间的相似网络;
信任度确定单元160,根据上述连接网络构建模块150构建的连接网络中的节点和路径确定不同用户之间的信任度;
节目推荐度确定单元170,根据信任度确定单元160获得的不同用户之间的信任度和不同用户对不同节目的收视偏好确定不同用户对不同节目的推荐度;
节目单生成单元180,分别以预推荐客体中的每一个用户为节点,按照与所述每一个用户的信任度由高到低的顺序选取设定数量的用户,按照所述设定数量的用户对不同节目的推荐度由高到低的顺序选取设定数量的节目,生成所述每一个用户的节目单。
在本发明的一个实施例中,上述节目推荐系统100中:
所述连接网络构建模块150包括关系网络构建单元151和相似网络构建单元152,分别根据关系键构建关系网络和根据相似度构建相似网络;
所述节目单生成单元180包括:第一组节目获得单元(未示出),分别以预推荐客体中每一个用户为节点,在关系网络中按照与所述每一个用户的信任度由高到低的顺序选取设定数量的第一组用户,按照第一组用户对不同节目的推荐度由高到低的顺序选取设定数量的第一组节目;第二组节目获得单元(未示出),分别以预推荐客体中每一个用户为节点,在相似网络中按照与所述每一个用户的信任度由高到低的顺序选取设定数量的第二组用户,按照第二组用户对不同节目的推荐度由高到低的顺序选取设定数量的第二组节目;节目单确定单元(未示出),所述第一组节目和第二组节目的交集作为所述每一个用户的节目单一个用户的节目单,形成预推荐客体中每一个用户的节目单。
在本发明的另一个实施例中,如图7所示,所述节目推荐系统100'与节目推荐系统100的区别在于还包括分群单元153,且所述关系网络构建单元构建的是分群单元150划分的每一个社区的关系网络,而不是构建整个预推荐客体的关系网络,其中:
分群单元153,根据相似度网络构建单元152构建的用户相似度矩阵,采用谱聚类算法对预推荐客体中的用户进行分群,得到设定数量的社区,
关系网络构建单元151',以分群单元153的每一个社区中的每一个用户为节点,根据收视偏好矩阵确定所述每一用户与其他用户之间的关系键,当关系键大于设定关系键阈值时,在用户之间建立路径,形成每一个社区的关系网络;
节目单生成单元180,在每一个社区中,分别以每一个用户为节点,按照与所述每一个用户的信任度由高到低的顺序选取设定数量的用户,按照所述设定数量的用户对不同节目的推荐度由高到低的顺序选取设定数量的节目,生成每一个社区中每一个用户的节目单。
优选地,本发明所述节目推荐系统100和100'还包括:
优化模块(未示出),根据串联节点优化方法、分叉节点优化方法和合并节点优化方法中的一种或多种对连接网络进行优化;
推荐效果评定单元(未示出),包括:第一评定单元(未示出),根据平均用户连接关系值和平均绝对值误差评定指标调整所述设定阈值;第二评定单元(未示出),根据平均绝对值误差评定指标和社区稠密性系数调整所述社区的设定数量。
在本发明的一个具体实施例中,选取中国某省市广播电视数据节目数据源和收视数据源,其中预推荐客体包含了该省市1千广播电视用户,节目数据源和收视数据源包含了上述用户一个月的收视信息,包含了46个频道、不同类型节目的播出信息,以每名用户每天每个频道10条收视记录为例,共计1000名用户*46个卫视频道*30天*10条跳转记录/天=1.38*107条节目收视数据。选取用户在当月前两周的收视数据作为训练集来为计算推荐结果,选取当月后二周的数据作为测试集来评估推荐效果,对第一评定单元和第二评定单元进行说明。
在第一评定单元中,以设定关系键阈值δ为例进行说明,设定关系键阈值δ是用户间连接关系的生成条件,当用户关系键时,用户间建立连接关系,δ越大,则要求社区内用户共同喜爱的节目类型更加集中,即要求社区特征更加明显,将上述预推荐客体划分为4类社区,每类社区群体具有不同群体特征和平均用户关系键值选择MAE指标,评估信任阈值δ对不同特征社区推荐效果的影响,如表1所示,
表1
对表1以折线图进行图示,如图8所示,以曲线形状代表不同收视偏好的社区群体,每类群体具有不同的平均用户关系键值以曲线趋势表示δ对指标的影响,如图8所示,当δ相同时,随着增加,MAE值降低,节目推荐准确性会随之增大;当δ不同时,如果此时δ增加会产生更加可靠的信任关系,从而带来节目推荐准确性增加,但如果此δ的增加会导致用户信任关系的减少,从而带来节目推荐准确性随着骤减,由于考虑到不同社区的平均用户关系键值多数集中在70%左右,将δ设定为70%。
在第二评定单元中,将用户稠密性系数定义为一定时期内用户收看过的节目类型与播出的节目类型总数之比,通过将用户稠密性系数求和,可以得到社区稠密性系数μc,
选取不同的用户社区数C与社区稠密性系数μc,采用平均绝对误差MAE指标,评估用户社区数C与社区稠密性系数μc对推荐效果的影响,如表2所示,
表2
对表2以曲面图进行图示,如图9所示,以横轴和纵轴分别表示用户社区数C与社区稠密性系数μc,以曲面的高度表示用户社区数C与社区稠密性系数μc对推荐准确性MAE指标的影响,如图9所示,MAE值随着用户社区数C与社区稠密性μc的增加而减少,即节目推荐准确性随着用户社区数C与社区数据稠密性μc的增加而增加,这是由于在用户总数不变的情况下,用户社区数C的增加会带来社区内邻居用户的增加,社区稠密性系数μc的增加会带来用户对相同节目类型的收视共性,提升用户间信任度水平,从而提高节目推荐准确性。
本发明所述节目推荐系统及方法包括至少四种节目单推荐系统及方法,以节目推荐系统为例进行说明,一个节目推荐系统,以广播电视用户为节点,以不同用户间的关系键构建关系网络,在关系网络中确定不同用户对不同节目的推荐度,按照推荐度由高到低的顺从关系网络获得所述用户的节目单;另一种节目推荐系统,以广播电视用户为节点,以不同用户间的收视偏好相似度构建相似网络,在相似网络中确定不同用户对不同节目的推荐度,按照推荐度由高到低的顺从相似网络获得所述用户的节目单;第三种节目推荐系统是上述两种节目推荐系统的交集,也就是说,分别在关系网络和相似网络中确定不同用户对不同节目的推荐度,按照推荐度由高到低的顺从关系网络和相似网络获得两组节目,两组节目的交集即为所述用户的节目单;第四种节目推荐系统,对预推荐客体中的广播电视用户进行分群,在分群后的每一个社区中以广播电视用户为节点构建每一个社区的关系网络,得到每一个社区中不同用户对不同节目的推荐度,在每一个社区中按照推荐度由高到低的顺从每一个社区的关系网络获得每一个社区中不同用户的节目单,另外,也可以通过节目标签的推荐度代替上述节目的推荐度,得到另外的四种节目推荐系统。
另外,本发明所述节目推荐系统及方法,还可以根据节目之间的相似性推荐预播出的节目生成的节目单给广播电视用户。
综上所述,参照附图以示例的方式描述了根据本发明提出的广播电视节目推荐系统及方法。但是,本领域技术人员应当理解,对于上述本发明所提出的系统及方法,还可以在不脱离本发明内容的基础上做出各种改进。因此,本发明的保护范围应当由所附的权利要求书的内容确定。
- 还没有人留言评论。精彩留言会获得点赞!