基于权重因子的HadoopHDFS数据块分布优化算法的制作方法
本发明涉及移动通信网络大数据优化和规划
技术领域:
,具体涉及一种基于权重因子的HadoopHDFS数据块分布优化算法。
背景技术:
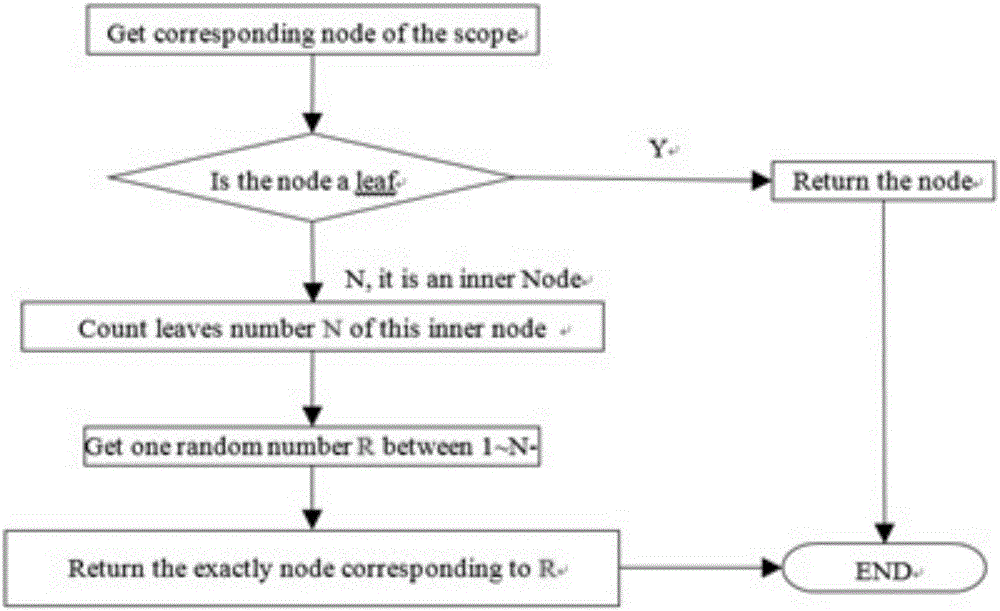
:HadoopHDFS副本技术即分布式数据复制技术,是分布式计算的一个重要组成部分。如图1所示,该技术允许数据在多个服务器端共享,一个本地服务器可以存取不同物理地点的远程服务器上的数据,也可以使所有的服务器均持有数据的拷贝。块副本存放位置的选择严重影响HDFS的可靠性和性能。HDFS采用机架敏感(rackawareness)的副本存放策略来提高数据的可靠性、可用性和网络带宽的利用率。一般情况下复制因子(文件的副本数)为3,HDFS的副本放置策略是:将第一个副本放在本地节点,将第二个副本放到本地机架上的另外一个节点,而将第三个副本放到不同机架上的节点。上述的现有技术方案存在如下问题:第一是,HDFS的默认副本放置策略是一个随机选择策略,副本放置的最终状态很难被控制。其具体表现如下:1)其是利用将副本放置在不同的机架上来达到高可靠性和数据块的均匀分布存储的,但如果数据中心只有一个机架,那么该副本放置策略就退化为一个随机选择策略,数据块的均匀分布和可靠性就很难被保证。2)其并没有考虑到节点负载的情况,即使有一个节点的负载远高于其他节点,按照默认的副本放置策略,这个节点还是有可能被持续的写入数据。3)其主要是对前三个副本的放置位置做出了考虑,如果需要放置更多的副本,则后面的副本放置会采用随机选择的策略。第二是,当然在HDFS系统中也有个叫均衡器(Balancer)的守护进程。它会将数据块从负载较高的节点移动到负载较低的节点上,从而达到数据块重新分配的目的,最终使得整个集群分布均衡。虽然均衡器能在一定程度上解决问题,但是它也是存在缺陷的:1)它对于集群数据块均衡的调节具有滞后性。2)均衡器的调节和数据块的移动都需要一定资源的消耗。第三是,Hadoop集群的建设和扩容都是分阶段进行的,随着硬件的升级换代,服务器的配置必然会出现不同的配置情况。差异主要集中在CPU和硬盘上。比如:1)主流采用Inter的CPU,其中8C/10C主频和缓存差别大,会影响Datanode处理性能,性能强的等待弱的。2)SATA数据盘的容量越来越大,目前主流的规格:单SATA盘7200RPM4TB。Hadoop集群数据自动均衡后,造成部分服务器的大容量磁盘空间浪费,无法使用。HDFS缺省的数据存储策略,会采用同等的方式来选择服务器,算法不够灵活造成分配不均匀。因此,最终会使得所有Datanode服务器的空间使用基本相同。这样会使得单节点磁盘空间总量小的服务器,其空间就会先满。当磁盘空间占用满了之后,集群会采用失败重试(重选)的方式来解决,这会导致很多上层应用出现访问HDFS超时的情况。技术实现要素:本发明的目的在于针对现有技术的缺陷和不足,提供基于权重因子的HadoopHDFS数据块分布优化算法,采用一种实时数据块分布算法,对HDFS的副本放置策略做出适当的优化,使数据落地过程中始终达到集群数据块负载均衡,并且尽量减少此过程带来的额外资源消耗。本发明所述的基于权重因子的HadoopHDFS数据块分布优化算法,它采用如下的方法步骤:步骤一:采用如下的选择策略:chooseLocalStorage(本地)到chooseLocalRack(本机架)到chooseRemoteRack(远端机架)最后到chooseRandom(全集群);步骤二:在步骤一的基础上,在现有技术的chooseRandom算法的基础上,引入一个权重来调整随机数在不同DataNode上的分布策略,将原有chooseRandom算法改造成如图5所示算法;步骤三:步骤二中的陈述的权重是指:把可用存储容量作为随机选择的一个权重因子,节点权重=1+(权重系数*存储容量可用百分比);因而可用容量百分比大的节点就更容易被选择作为存储节点。步骤四:步骤三中所陈述的权重可由空间利用率来决定,通过权重分配算法进行计算,其线性调整权重采用如下的计算公式:权重的大小和剩余空间利用率成线性关系:W=1+(r*c)。本发明有益效果为:本发明所述的基于权重因子的HadoopHDFS数据块分布优化算法,采用一种实时数据块分布算法,对HDFS的副本放置策略做出适当的优化,使数据落地过程中始终达到集群数据块负载均衡,并且尽量减少此过程带来的额外资源消耗。【附图说明】此处所说明的附图是用来提供对本发明的进一步理解,构成本申请的一部分,但并不构成对本发明的不当限定,在附图中:图1是本发明
背景技术:
中HadoopHDFS副本技术示意图;图2是本发明中的选择策略的拓扑结构示意图;图3是本发明的测试中动态变化的权重示意图;图4是本发明中的权重/可用容量百分比走势示意图;图5是本发明的算法流程图;图6是传统的chooseRandom算法的流程图。【具体实施方式】下面将结合附图以及具体实施例来详细说明本发明,其中的示意性实施例以及说明仅用来解释本发明,但并不作为对本发明的限定。本具体实施方式所述的基于权重因子的HadoopHDFS数据块分布优化算法,它采用如下的方法步骤:步骤一:如图2所示,采用如下的选择策略:chooseLocalStorage(本地)到chooseLocalRack(本机架)到chooseRemoteRack(远端机架)最后到chooseRandom(全集群);步骤二:在步骤一的基础上,在现有技术的chooseRandom算法的基础上,引入一个权重来调整随机数在不同DataNode上的分布策略,将原有chooseRandom算法改造成如图5所示算法;步骤三:步骤二中的陈述的权重是指:把可用存储容量作为随机选择的一个权重因子,节点权重=1+(权重系数*存储容量可用百分比);因而可用容量百分比大的节点就更容易被选择作为存储节点。步骤四:步骤三中所陈述的权重可由空间利用率来决定,通过权重分配算法进行计算,其线性调整权重采用如下的计算公式:权重的大小和剩余空间利用率成线性关系:W=1+(r*c)。本发明的设计思想原理如下:本发明是在一种在原本chooseRandom算法的基础上进行优化改造方法,原来的chooseRandom算法是如图6所示算法;上述算法中,1)缺省是随机的,不考虑任何其它因素。2)通过一个均匀分布的随机数来选择集群中的一个DataNode。本发明改造后的算法涉及以下方面:1)引入一个权重调整随机数在不同DataNode上的分布策略;2)权重由可用空间利用率来决定;3)改动过的算法是把可用存储容量作为随机选择的一个权重因子,节点权重=1+(权重系数*存储容量可用百分比)。这样可用容量百分比大的节点就更容易被选择作为存储节点。这个功能是被系统层面调用,每次写文件都会涉及调用如下程序流程:选择算法只是每次操作单次选择,若考虑空间利用率或其他动态参数,则选择算法的结果也会是动态变化的。本发明里权重分配算法:1)线性调整权重:权重的大小和剩余空间利用率成线性关系W=1+(r*c);Weight(nodeo):functiontocomputetheweightofanodew=1+(r*c)Wherewistheoutputweightofthenodeo,cpresentsfreevolumeofthenodeo,thevalueofcisbetween0and1risauserinputthreshold,thevalueofrisbetween0and10.Withthegrowthofr,thenodewithhighervolumewillgetlargerweight.Ifvalueofris0thenvolumeofthenodewillhavenoeffectonweightofnode.2)使用效果:相对来说,整体空间利用率有提升随着数据的积累,容量小的主机权重在变小,且变化速度更快3)说明:如图3所示,本次测试时,R=10;动态变化的权重,并不能保证全部空间可以被100%利用。4)本发明的测试数据对比如下:HOSThost132host155host156host157host158总容量(G)total8101370165011001375测试前used%1.64%13.21%10.97%1.58%12.44%加权算法used%98%78%72%92%72%缺省算法预计used%100%59%49%74%59%本发明中着重提出了,在chooseRandom算法中把可用存储容量作为随机选择的一个权重因子,节点权重=1+(权重系数*存储容量可用百分比)。这样可用容量百分比大的节点就更容易被选择作为存储节点,从而使得本算法优于现有的计算方法。本发明与现有技术方案相比,其技术优点如下:1)通过调整算法,可以相对改善不同服务器的空间利用率情况。2)还可以根据现场的数据特点调整算法,改变空间利用率的均衡情况。3)本次改变只是调整了选择算法本身,与写文件等操作无关,并不会引入性能问题。本发明有益效果为:本发明所述的基于权重因子的HadoopHDFS数据块分布优化算法,采用一种实时数据块分布算法,对HDFS的副本放置策略做出适当的优化,使数据落地过程中始终达到集群数据块负载均衡,并且尽量减少此过程带来的额外资源消耗。以上所述仅是本发明的较佳实施方式,故凡依本发明专利申请范围所述的构造、特征及原理所做的等效变化或修饰,均包括于本发明专利申请范围内。当前第1页1 2 3
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1