一种基于网络行为的木马检测方法与流程
本发明属于涉及网络安全技术领域,更具体地说,涉及一种基于网络行为的木马检测方法。
背景技术:
随着网络的广泛应用与规模的发展壮大,网络资源共享与信息交流为人类工作和生活提供了极大的便利。基于tcp/ip架构的计算机网络是一个开放和自由的网络,提高网络信息服务灵活性的同时,也方便了黑客的入侵和攻击。从当前apt(advancedpersistentthreats,高级持续性威胁)流程中可以看到,木马仍然是攻击者用于渗透进目标网络,进行远程控制的首要手段。因此,对木马的网络行为进行检测是apt检测的一个重要环节。
目前,针对木马的检测和防御的方法大致可以分为两大类:一类是基于主机的木马检测,该方法需要提前知道木马的文件特征值,建立木马检验特征库,在对木马进行检测时,将恶意软件特征值与特征库中木马进行特征对比。但是,因为木马特征库的建立存在滞后性,所以,这种方法不能检测到未知的木马程序,同时对一些现存的木马程序的变种,也难以实现有效检测;一类是基于网络的木马检测,该方法主要分为基于特征匹配的检测技术和基于协议分析的检测技术。其中,基于特征匹配的检测技术同样存在滞后性,对于新出现的木马程序和已存木马的变种程序难以准确检测。基于协议分析的检测技术,是一种需要和其他检测技术协同工作才能达到较好检测效果的木马检测技术。
随着互联网技术的迅猛发展,木马的种类日趋复杂化,并且,密码程序对计算机的危害也越来越大。木马的网络行为主要指木马在网络中与其他计算机之间的通信行为。木马通过网络通信,以实现对网络进行攻击、盗取用户信息、远程操控受控主机的恶意目的。因此,针对木马的网络通信行为进行及时准确的识别尤为重要。
不同木马程序在目的、采用的网络协议以及所针对的操作系统方面可能存在较大的差别,但是,木马程序终将通过网络通信进行客户端和服务端的连接。所以,木马程序在网络通信行为上存在着一定相似性。通过对大量木马程序的网络通信流量样本进行分析可以将木马程序的网络通信行为可以分为建立连接、保持连接和命令交互三个阶段。木马程序在不同的阶段,网络通信流量上表现出不同的特征,可以使用这样的特征来检测木马。
技术实现要素:
针对现有技术中存在的新出现的木马程序和已存木马的变种程序难以准确检测问题,本发明提供了一种基于网络行为的木马检测方法,它可以提高对木马程序的检测率,有效的对网络中存在的木马进行检测。
本发明的目的通过以下技术方案实现。
基于网络行为的木马检测方法,其特征在于,步骤如下:
s1对网络数据包进行协议解析,识别出完整的数据包内容,对原始数据进行规范化预处理,用于特征提取;
s2从基本、流量和内容三方面提取详细的特征;
s3采用r-svm(recursivesupportvectormachine,递归支持向量机)算法,根据各个特征的贡献度大小对提取出的大量数据特征进行降维处理,删除大量的冗余数据特征,然后根据筛选后的特征从原始数据集中提取,作为svm分类器的训练集;
s4采用组合核函数构建svm分类器,并利用网格搜索对核函数参数进行参数寻优。
更进一步的,步骤s1的具体步骤为1.对数据包进行协议解析;2.离散型数据连续化;3.将连续型数据归一化,针对网络数据流数据特征(均为非负数),可减少存储空间和运算次数,有效提高分类效果。
更进一步的,步骤s2的具体步骤为1.提取网络数据基本特征;2.提取网络数据流量特征;3.提取网络数据内容特征。可提取提取的特征包括基本特征、流量特征和内容特征,而不是局限于提取流量特征或协议特征,可使原始数据集候选特征更为全面,供后期特征处理使用。
更进一步的,步骤s3的具体步骤为1.使用当前所有候选特征训练支持向量机;2.比较当前的所有特征在支持向量机中的相对贡献大小,并按照贡献大小进行排序;3.根据事先确定好的递归选择特征数,选择出排序在前面的特征,转步骤1,直到达到所希望选择的特征数目结束。对数据进行特征处理,是通过r-svm算法,根据各个特征相对贡献度大小,筛选出所需特征数,以达到删除原始数据集冗余数据,降低特征空间维数的目的,从而在保证分类器分类准确性的前提下,提高分类速度。
更进一步的,步骤s4的具体步骤为1.利用多项式核函数和径向基核函数构建组合核函数;2.利用基于网格搜索的参数寻优,寻找核函数最优参数;3.将经过特征提取的数据作为训练集训练svm分类器,用作对木马检测。利用组合核函数建立svm分类器,是通过将多项式核函数和径向基核函数进行现行加权得到的核函数。多项式核函数是全局核函数,径向基核函数是局部核函数,两者分别适用于不同的数据分布,将两者进行现行加权组合,得到的核函数可同时具备两种核函数的优点,提高svm分类器的性能。
相比于现有技术,本发明的优点在于:
(1)本发明中利用r-svm特征提取算法来衡量各个特征在当前的svm模型中的贡献度大小,可有效删除冗余特征,降低数据特征空间的维度,以提高分类模型在保证分类正确率的前提下,降低分类模型结构的复杂性,达到降低模型训练时间和最终预测时间的目的;
(2)本发明中的svm算法中使用组合核函数,让最终的核函数同时具备全局合函数和局部核函数的优点,并且利用多重网格搜索确定参数寻优,最终选择了较为优秀的核函数及核参数,优化了svm分类性能,提高最终对木马程序的检测率。
(3)本发明通过对网络数据包进行协议解析,识别出完整的数据包内容,对原始数据进行规范化预处理,以用于特征提取。并从基本、流量和内容三方面提取尽量详细的特征,采用r-svm算法,根据各个特征的贡献度大小对提取出的大量数据特征进行降维处理,删除大量的冗余数据特征,然后根据筛选后的特征从原始数据集中提取,作为svm分类器的训练集。最后,采用组合核函数构建svm分类器,并利用网格搜索对核函数参数进行参数寻优,提高了svm分类器的性能。该方法可提高对木马程序的检测率,有效的对网络中存在的木马进行检测。
附图说明
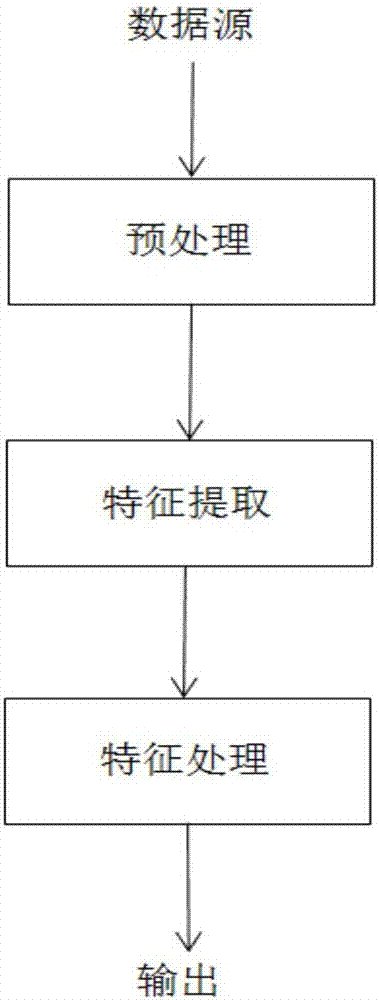
图1为本发明的整体过程流程图;
图2为为本发明的系统架构图。
具体实施方式
下面结合说明书附图和具体的实施例,对本发明作详细描述。
实施例1
图1所示的是一般的基于网络行为进行木马检测整体上的流程图,其核心工作单元是特征提取和特征处理,本发明对两个工作单元进行改进而最终实现对基于网络行为的木马检测方法实现改进。该一般流程图中,特征处理单元在本发明中就相当于一个利用组合核函数的svm算法流程。将本发明中的特征提取和特征处理方法应用于一般的基于网络行为的木马检测流程中即可得如图2所示的本发明的系统架构图。各个模块组件的具体实施方式如下:
1.预处理
数据源或原始数据集在被提取特征之前,需要进行规范化预处理预处理,将离散型数据连续化,将连续型数据归一化,并且可以识别出完整的请求报文,用于后期的特征提取,训练和检测。
2.特征提取
对于原始数据集特征的提取对svm分类算法的效率具有决定性作用。因此,特征提取必须尽可能的做到准确、简洁,才能够提高检测的准确性,降低误报率并且缩短检测时间,达到较好的实时性。为了能更有效的检测出目前木马的常用攻击类型,通过木马攻击的特征,考虑提取基本特征、流量特征和内容特征。这样可以弥补传统的基于协议分析检测手段仅通过协议匹配检测和传统的基于流量特征仅基于流量检测的不足。
(1)基本特征
tcp/ip协议时目前最为流行、应用的最为广泛的互联网协议,但是,基于tcp/ip架构的计算机网络是一个开放和自由的网络,提高网络信息服务灵活性的同时,也方便了黑客的入侵和攻击。因此,本发明主要考虑tcp、udp、icmp包。
因为大多数攻击难免会在包头留下相关痕迹,因此,可以提取数据包头的相关字段作为检测手段。对于tcp数据包,可以提取标识位、源端口、目的端口等特征;对于udp协议可提取源端口、目的端口等特征;对于icmp协议可提取数据字节数、服务类型等特征。
(2)流量特征
由于木马程序的恶意性目的,导致木马程序运行时在网络通信流量行为上和正常程序具有较大差异性。特别是在命令交互阶段,木马的通信流量会表现出会话时长大于普通通信流量、上传数据量大于下在数据量等特征。
(3)内容特征
有一些木马攻击类型例如u2r和r2l潜藏在数据包的负载部分。单一的数据包和正常连接区别不大。但是,有一些攻击发生时会明显的增加连接请求时长,因此,可以将请求长度作为特征。
3.特征处理
采用递归支持向量机算法(r-svm)对所提取出的大量特征属性做特征提取,删除相对不重要的冗余特征,降低数据特征空间的维度。
r-svm算法步骤:
(1)使用当前所有候选特征训练支持向量机;
(2)比较当前的所有特征在支持向量机中的相对贡献大小,并按照贡献大小进行排序;
(3)根据事先确定好的递归选择特征数,选择出排序在前面的特征,转(1),直到达到所希望选择的特征数目结束;
对于在算法第(1)步训练好的svm分类模型,r-svm通过寻找使两个样本在这个svm输出上分离的最开的特征作为最终特征选择的目标,利用两类样本平均svm输出值作为代表,定义当前特征分离度为:
其中,n1、n2是训练集当中w1、w2类样本的数量,把分离度表示成各个特征之和的形式为:
其中,d是当前候选特征数,wj是权向量w的第j个分量,mj+、mj-分别是两类样本在第j维特征的均值,如此,各个特征的贡献值为:
2.利用svm进行木马检测,利用组合和函数作为svm的内部核函数,并利用多重网格搜索进行参数寻优。
由于svm的性能主要取决于特征的提取及核函数的选取以及核函数参数的合理确定。在合理提取了特征之后,本发明利用组合核函数对传统svm中的单一核函数进行优化,即将一个全局核函数和一个局部核函数进行线性加权组合,构建组合核函数,使其同时具备局部核函数和全局核函数的优点。本发明选取多项式核函数和径向基核函数进行组合。组合后的构建的核函数为:
k(x,z)=u[(x·z)+1]d+vexp(-||x-z||2/σ2)
其中,u、v为加权系数,并且为正数;d为多项式核函数的幂指数;σ为径向基核函数的宽度参数。
当svm分类器的核函数确定后,其分类性能主要受核函数的参数、惩罚因子c以及宽度参数σ影响。目前,国际上并无公认的方法用于svm最优参数选取,目前常用基于网格搜索的参数寻优和基于各种优化算法的参数寻优。本发明采用基于网格搜索的svm最优参数确定方法。
基于网格搜索的svm参数寻优方法主要思路为:
(1)首先将参数c和σ在一定范围内取值;
(2)对于取定值的c和σ,把训练集作为原始数据集利用k折交叉验证法得到在此组c和σ下的训练集验证分类准确率
(3)最终取使得训练集验证分类准确率最高的一组c和σ作为最优参数。
将特征提取后的数据作为svm的训练集,输入svm分类器,对分类器进行训练,用于对测试集数据的检测。
当前,针对网络行为的木马病毒的检测方法中,主要使用c4.5决策树、朴素贝叶斯、svm等算法。其中,使用朴素贝叶斯算法,因为朴素贝叶斯算法要求各个特征间相互独立,而现实中数据无法满足,所以,检测率最低,只能达到86.5%左右。使用c4.5决策树算法,基于决策树算法进行了优化,可以达到88.9%的检测率。因为本发明所采用的svm算法,适用于高维度、小样本的数据分类预测工作,因此,使用基本svm算法对木马程序的检测率即可达到91.3%,结合本发明对原始数据进行降维,对svm核函数进行现行加权合并,并进行参数寻优,检测率应可以达到94%以上,并有效缩短了分类器训练时间。
以上示意性地对本发明创造及其实施方式进行了描述,该描述没有限制性,附图中所示的也只是本发明创造的实施方式之一,实际的结构并不局限于此。所以,如果本领域的普通技术人员受其启示,在不脱离本创造宗旨的情况下,不经创造性的设计出与该技术方案相似的结构方式及实施例,均应属于本专利的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!