一种面向超融合一体机的资源监控系统的制作方法
本发明涉及计算机领域,尤其涉及一种面向超融合一体机的资源监控系统。
背景技术:
超融合是云计算的一个新分支,主要关注于虚拟计算、分布式存储与虚拟网络的融合,定位于实现私有云平台。目前超融合集群以最少3个物理节点组成,每个节点都处于对等的地位,集群扩展以节点线性扩展的方式扩展。但目前在实际生产环境中,超融合平台由众多物理机以及运行在物理机上的超融合相关服务组成,当平台规模变大时,集群的物理服务器会很多,上面运行着成千上万的租户的虚拟机实例,单纯依靠系统管理员的经验和运维人员来进行监控和维护是不现实也不合理的。
传统的资源监控方案中,如Ganglia,一般采用侵入式的数据采集方式,这种监控方式会影响到虚拟机的用户体验,而且对于恶意用户恶意关闭监控程序等现象没有很好的解决办法,同时也会增加系统的复杂程度。因此需要一个简单高效的系统将整个集群的物理资源和虚拟资源等同时监控起来,监控系统不会随着监控数据的增加被压垮,同时降低虚拟机监控的侵入性。
技术实现要素:
有鉴于现有技术的上述缺陷,本发明所要解决的技术问题是提供一种面向超融合一体机的资源监控系统,本系统通过Libvirt接口等方式,减少监控系统的侵入性,同时使用基于ZooKeeper的分布式架构,来保证整个监控集群的高可用性。
为实现上述目的,本发明提供了一种面向超融合一体机的资源监控系统,包括若干个HcpMonitor监控组件,所述HcpMonitor监控组件包括MonitorServer模块和MonitorClient模块;
若干个所述HcpMonitor监控组件依据ZooKeeper客户端框架选择其中一个MonitorServer模块为主控节点,其他MonitorServer模块作为随从节点处于待命状态,所述MonitorClient模块从ZooKeeper组件中采集数据,将采集到的数据传送到AMQP Message Middle文件中,其中作为主控节点的MonitorServer模块从AMQP Message Middle文件中读取到数据后,进行数据分析处理,通过ZooKeeper集群进行分布式管理。
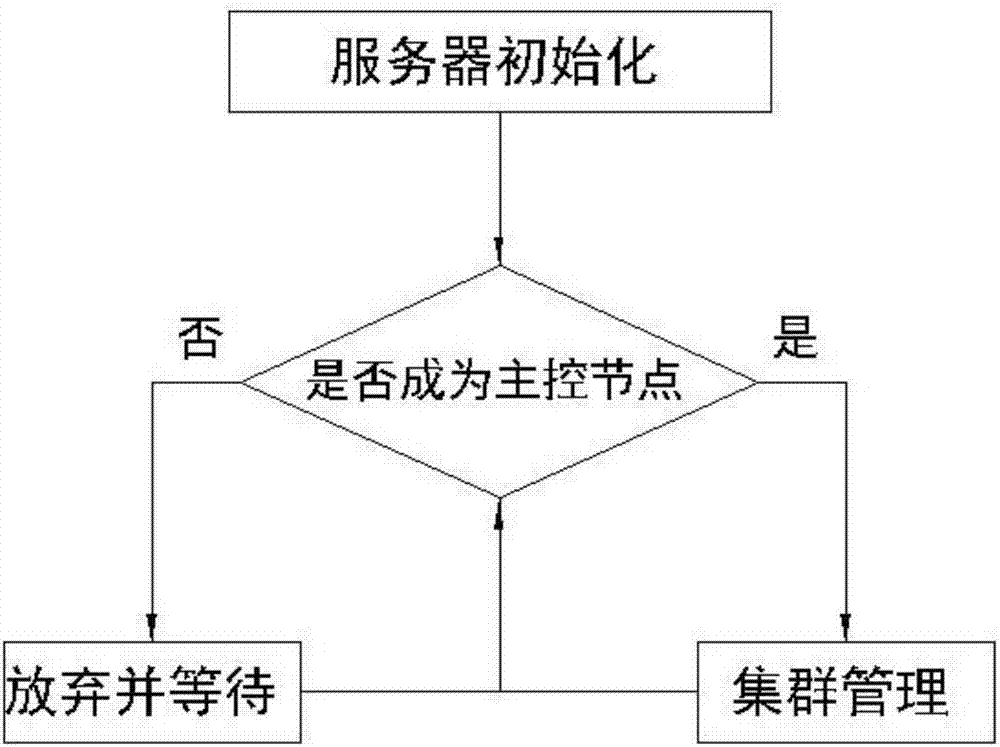
较佳的,所述MonitorServer模块工作流程包括如下步骤:
S1:服务器初始化;
S2:判断是否成为主控节点,如果否,则执行步骤S3,否则,则执行步骤S4;
S3:放弃等待,放弃CPU占用并且等待,并定时执行步骤S2。
S4:集群管理,管理HcpMonitor监控组件集群的主循环,包括设置监听器,处理数据等工作,执行完毕后,继续执行步骤S2。
较佳的,所述MonitorClient模块中包括数据收集器和主循环器;
所述数据收集器主要使用Linux常见的系统工具以及Python脚本调用Libvirt的方式来获取物理机和虚拟机对应的监控信息;
所述主循环器的流程如下:
A1:获取物理机状态;
A2:获取物理机数据;
A3:获取监控数据;
A4:数据适配器处理;
A5:判断是否结束,是则结束程序,否则执行步骤A1。
较佳的,所述步骤S1中服务器初始化流程如下:
S1-1:初始化ZooKeeper路径,对ZooKeeper中所有使用到的路径根据应有的状态进行初始化,如果不存在的则进行创建;
S1-2:初始化清理线程,启动一根线程定时清理集群中所有长期未处理的请求和未响应的事件,防止集群资源的浪费;
S1-3:初始化配置线程,启动集群配置的更新线程,该线程的主要工作是定时同步所修改的集群配置,让集群配置可以更新同步到每台物理机上。
较佳的,所述步骤S4中集群管理的流程如下:
S4-1:设置监听器,初始化所有的监听事件,包括/hosts、/hosts-ephemeral以及/monitor等,并且根据所触发的节点事件来生成集群的事件,包括物理节点上线、物理节点掉线、虚拟机上线、虚拟机掉线等等;
S4-2:清理旧数据,新选出来的主控节点会对旧主控节点产生的集群数据进行清理,防止有数据不一致的情况发生;
S4-3:判断是否结束程序,如果是则结束成程序,否则继续执行下一步;
S4-4:收集数据;
S4-5:数据处理;
S4-6:返回步骤S4-3继续执行。
本发明的有益效果是:本发明提出了一种面向超融合一体机的资源监控系统,此监控系统基于超融合基础架构下,系统简单高效的,减少监控系统的侵入性,可用性高,最大限度的共享超融合基础架构已有的资源,数据采集、处理高效。
附图说明
图1是本发明总体结构图;
图2是本发明MonitorServer模块工作流程图;
图3是本发明主循环器的工作流程图;
图4是本发明服务器初始化工作流程图;
图5是本发明集群管理的工作流程图;
具体实施方式
下面结合附图和实施例对本发明作进一步说明:
如图1所示,本实施例包括若干个HcpMonitor监控组件,所述HcpMonitor监控组件包括MonitorServer模块和MonitorClient模块;若干个所述HcpMonitor监控组件依据ZooKeeper客户端框架选择其中一个MonitorServer模块为主控节点,其他MonitorServer模块作为随从节点处于待命状态,所述MonitorClient模块从ZooKeeper组件中采集数据,将采集到的数据传送到AMQP Message Middle文件中,其中作为主控节点的MonitorServer模块从AMQP Message Middle文件中读取到数据后,进行数据分析处理,并将数据传输给ZooKeeper集群和MariaDB Cluster数据库集群,通过ZooKeeper集群进行分布式管理。
如图2所示,所述MonitorServer模块工作流程包括如下步骤:
S1:服务器初始化;
S2:判断是否成为主控节点,如果否,则执行步骤S3,否则执行步骤S4;
S3:放弃等待,放弃CPU占用并且等待,并每隔一段时间定时执行步骤S2,本实施例每隔5s或者10s定时执行步骤S2。
S4:集群管理,管理HcpMonitor监控组件集群的主循环,包括设置监听器,处理数据等工作,执行完毕后,继续执行步骤S2。
如图3所示,所述MonitorClient模块中包括数据收集器和主循环器;
所述数据收集器主要使用Linux常见的系统工具以及Python脚本调用Libvirt的方式来获取物理机和虚拟机对应的监控信息;
所述主循环器的流程如下:
A1:获取物理机状态;
A2:获取物理机数据;
A3:获取监控数据;
A4:数据适配器处理;
A5:判断是否结束,是则结束程序,否则执行步骤A1。
如图4所示,所述步骤S1中服务器初始化流程如下:
S1-1:初始化ZooKeeper路径,对ZooKeeper中所有使用到的路径根据应有的状态进行初始化,如果不存在的则进行创建;
S1-2:初始化清理线程,启动一根线程定时清理集群中所有长期未处理的请求和未响应的事件,防止集群资源的浪费;
S1-3:初始化配置线程,启动集群配置的更新线程,该线程的主要工作是定时同步所修改的集群配置,让集群配置可以更新同步到每台物理机上。
如图5所示所述步骤S4中集群管理的流程如下:
S4-1:设置监听器,初始化所有的监听事件,包括/hosts、/hosts-ephemeral以及/monitor等,并且根据所触发的节点事件来生成集群的事件,包括物理节点上线、物理节点掉线、虚拟机上线、虚拟机掉线等等;
S4-2:清理旧数据,新选出来的主控节点会对旧主控节点产生的集群数据进行清理,防止有数据不一致的情况发生;
S4-3:判断是否结束程序,如果是则结束成程序,否则继续执行下一步;
S4-4:收集数据;
S4-5:数据处理;
S4-6:返回步骤S4-3继续执行。
以上详细描述了本发明的较佳具体实施例。应当理解,本领域的普通技术人员无需创造性劳动就可以根据本发明的构思作出诸多修改和变化。因此,凡本技术领域中技术人员依本发明的构思在现有技术的基础上通过逻辑分析、推理或者有限的实验可以得到的技术方案,皆应在由权利要求书所确定的保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!