服务调用链路分析方法及系统与流程
本发明属于计算机技术领域,尤其涉及一种服务调用链路分析方法及系统。
背景技术:
随着互联网技术高速发展,为了支撑日益增长的庞大业务量,通常将服务整合、拆分,使得服务不仅能通过集群部署抵挡流量冲击,又能根据业务需要进行灵活扩展。
但是,一个请求少则经过三、四个服务调用完成,多则跨越几十个甚至上百个服务节点。即使分布式系统的开发者,也很难清楚地说出某个服务的调用链路,而且,服务调用链路动态变化。这种分布式结构,如果业务流出现错误和异常,如何定位哪个节点出现了问题,如何分析服务链路的瓶颈并对其进行优化。因此,亟需一种分布式调用链跟踪系统,其中,zipkin是一款开源的分布式实时数据追踪系统,其主要功能是聚焦来自各个异构系统的实时监控数据,用来追踪分布式微服务架构下的系统延时问题,但是,zipkin功能单一,只能实时分析调用状况,不能得到整个系统中各个应用之间的调用关系、调用耗时等参数,不能很好地预估各个环节的薄弱点。
技术实现要素:
有鉴于此,本申请实施例提供一种服务调用分析方法及装置,以解决现有的调用链跟踪系统无法获得整个系统的调用关系、调用耗时等参数,不能预估各个调用环节的薄弱点的问题。
第一方面,本申请提供一种服务调用链路分析方法,应用于服务端,包括:
获取服务调用请求的对应的日志信息,所述日志信息包括所述调用追踪标识、服务名、调用类型、调用时间信息、调用节点信息、调用结果和异常信息,所述调用追踪标识与所述服务调用请求一一对应,且所述调用追踪标识在服务调用请求对应的调用链路中传递;
根据所述日志信息得到所述调用追踪标识对应的调用信息,所述调用信息包括整个服务调用链路中各个调用节点对应的调用时间、服务名、调用耗时、调用来源信息及调用关系;
将所述调用信息及所述调用追踪标识对应存储到数据库中;
分析数据库中每一个调用追踪标识对应的调用信息,得到整个服务调用系统中各个节点之间调用关系,以及各个节点的调用参数。
可选地,将所述调用信息及所述调用追踪标识对应存储到数据库中,包括:
以所述调用追踪标识为行/列关键字,以调用节点信息为列/行关键字,对应存储所述调用信息,且所述数据库中所述调用节点的先后顺序与所述调用追踪标识对应的调用关系一致。
可选地,所述方法还包括:
为所述调用信息创建索引,所述索引包括服务名、调用耗时、异常信息和调用方信息。
可选地,所述根据所述日志信息得到所述调用追踪标识对应的调用信息,包括:
根据所述调用时间信息计算每个节点对应的调用耗时;
分析包含所述调用追踪标识的全部日志信息,得到所述调用追踪标识对应的各个节点之间的调用关系;
分析包含所述调用追踪标识的全部日志信息,得到所述调用追踪标识对应的调用来源信息。
可选地,所述分析数据库中每一个调用追踪标识对应的调用信息,得到整个服务调用系统中各个节点之间调用关系,以及各个节点的调用参数,包括:
以所述调用追踪标识为单元从所述数据库中读取对应的调用信息;
解析所述调用追踪标识对应的调用信息,得到具有依赖关系的调用树,所述调用树中各个节点的值包括调用次数、异常次数和调用耗时;
对所述调用树中每个节点的值进行聚合分析,得到每秒查询率、平均耗时、调用关系和调用来源。
可选地,所述获取所述服务调用请求的日志信息,包括:
从日志消息队列中读取所述服务调用请求对应的日志信息,所述日志消息队列中的信息由设置在客户端和服务端的上下文信息的埋点收集得到。
第二方面,本申请提供一种服务调用链路分析系统,应用于服务端,包括:
数据获取模块,用于获取服务调用请求的对应的日志信息,所述日志信息包括所述调用追踪标识、服务名、调用类型、调用时间信息、调用节点信息、调用结果和异常信息,所述调用追踪标识与所述服务调用请求一一对应,且所述调用追踪标识在服务调用请求对应的调用链路中传递;
实时处理模块,用于根据所述日志信息得到所述调用追踪标识对应的调用信息,所述调用信息包括整个服务调用链路中各个调用节点对应的调用时间、服务名、调用耗时、调用来源信息及调用关系;
数据存储模块,用于将所述调用信息及所述调用追踪标识对应存储到数据库中;
离线分析模块,用于分析数据库中每一个调用追踪标识对应的调用信息,得到整个服务调用系统中各个节点之间调用关系,以及各个节点的调用参数。
可选地,所述数据存储模块具体用于:
以所述调用追踪标识为行/列关键字,以调用节点信息为列/行关键字,对应存储所述调用信息,且所述数据库中所述调用节点的先后顺序与所述调用追踪标识对应的调用关系一致。
可选地,所述系统还包括:
索引创建模块,用于为所述调用信息创建索引,所述索引包括服务名、调用耗时、异常信息和调用方信息。
可选地,所述离线分析模块具体用于:
以所述调用追踪标识为单元从所述数据库中读取对应的调用信息;
解析所述调用追踪标识对应的调用信息,得到具有依赖关系的调用树,所述调用树中各个节点的值包括调用次数、异常次数和调用耗时;
对所述调用树中每个节点的值进行聚合分析,得到每秒查询率、平均耗时、调用关系和调用来源。
本申请实施例提供的服务调用链路分析方法,服务端接收到客户端发送的服务调用请求后,生成该服务调用请求唯一对应的调用追踪标识,且该调用追踪标识在整个调用链路中传递。服务端获取调用对应的全部日志信息,然后,对日志信息进行处理得到该调用追踪标识对应的调用信息,并将该调用信息存储到数据库中。最后,离线分析数据库中存储的调用信息,得到整个服务调用系统中各个节点之间的调用关系及调用参数。该方法将调用关系存储数据库中,然后对数据库中的数据进行离线分析,得到整个服务调用系统的调用关系、调用耗时、依赖度等信息。以便下一步分析服务调用系统中的性能瓶颈并进行优化。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
图1是一种典型的服务系统的架构示意图;
图2是本申请实施例一种服务调用链路分析方法流程图;
图3是本申请实施例另一种服务调用链路分析方法的流程图;
图4是本申请实施例一种服务调用链路分析系统的示意图;
图5是本申请实施例另一种服务调用链路分析系统的示意图。
具体实施方式
为使本发明实施例的目的、技术方案和优点更加清楚,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
请参见图1,示出了一种典型的服务架构示意图,该服务系统包括六个微服务分别是:A、B、C、D、E和F。例如,该服务系统中包含3个微服务路由:新用户注册由微服务A,B,C和E实现,其中,微服务之间的调用关系是A调用B,B调用C,C调用E;下订单由微服务A,B,C和D实现;支付由微服务A,B,C,D和F实现。
在微服务架构中,微服务之间存在着复杂的调用关系,导致系统的开发者都很难搞清楚整个微服务系统中微服务之间的调用关系,当整个调用链路出现性能瓶颈时,很难定位出问题出在哪个节点上。本发明实施例提供的服务调用链路分析方法,收集调用过程中的调用信息,并存储到数据库中,然后,对数据库中的调用信息进行离线分析,获得整个服务系统的调用关系、调用耗时等信息。以便根据这些信息分析整个服务调用系统的性能瓶颈并进行优化。
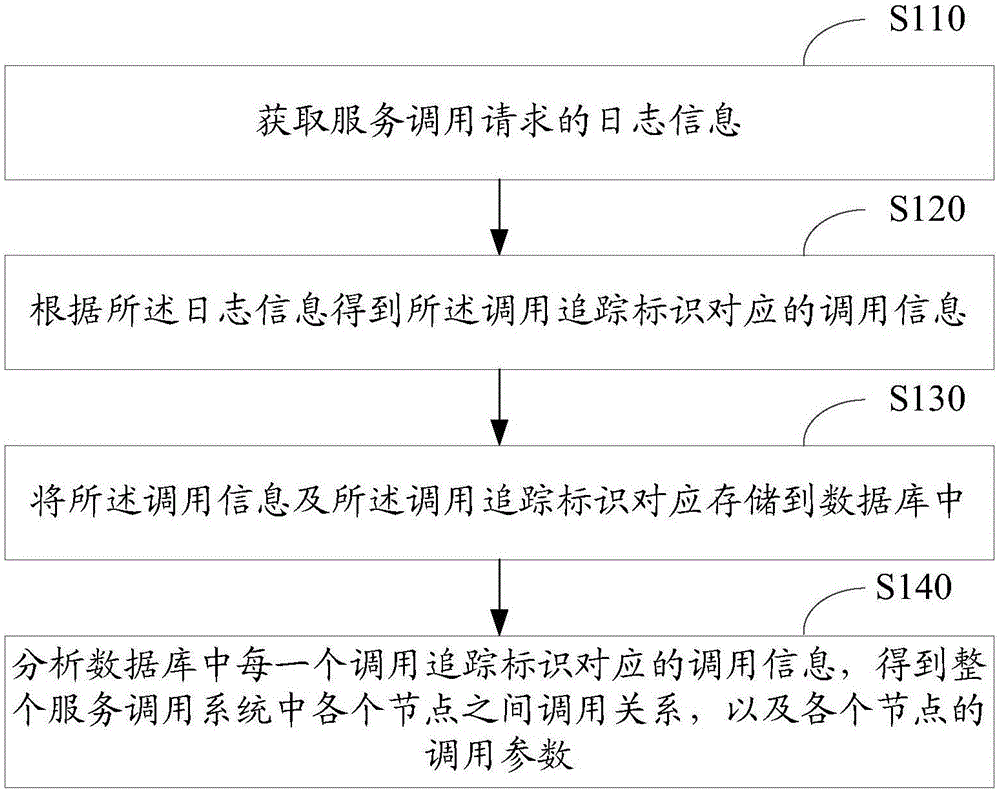
请参见图2,示出了本申请实施例一种服务调用链路分析方法流程图,该方法应用于服务端中,如图2所示,该方法可以包括以下步骤:
S110,获取服务调用请求的日志信息;
所述日志信息包括所述调用追踪标识、服务名、调用类型、调用时间信息、调用节点信息、调用结果和异常信息。
服务系统中的服务端接收客户端发送的服务调用请求后,生成与所述服务调用请求唯一对应的调用追踪标识,即调用追踪标识与服务调用请求一一对应,且调用追踪标识在服务调用请求对应的调用链路中传递。
在服务系统中的客户端和服务端均设置埋点,通过埋点收集服务调用过程中的数据。数据埋点的四个阶段包括:客户端发起请求时埋点、服务端接收请求时埋点、服务端返回请求时埋点、客户端接收请求时埋点。
各个埋点将收集的数据发送给数据收集模块。其中,日志数据包括:调用追踪标识、调用开始时间、调用类型、协议类型、调用方IP和端口、请求的服务名、调用耗时、调用结果、异常信息和消息报文等信息。
S120,根据所述日志信息得到所述调用追踪标识对应的调用信息;所述调用信息包括整个服务调用链路中各个调用节点对应的调用时间、服务名、调用耗时、调用来源信息及调用关系。
实时分析收集到的日志信息,获得调用追踪标识对应的调用信息,该调用信息包括:调用时间、调用耗时调用来源信息及整个调用链路的调用关系。
其中,调用耗时通过计算调用开始时间和接收到调用结果之间时间差得到。
在本申请一种可能的实现方式中,可以利用Storm集群从消息队列读取数据并进行处理分析过滤,提高系统的并发性能。
S130,将所述调用信息及所述调用追踪标识对应存储到数据库中。
以调用追踪标识为行(或列)关键字,以调用节点信息(例如,调用节点ID)为列(行)关键字,以调用追踪标识和调用节点所对应的调用信息为由行/列确定的位置对应的数据信息。
而且,所述数据库中所述调用节点的先后顺序与调用链路中的调用关系一致。例如,整个调用链路的调用关系是A-C-D-E-F,则存储时调用节点ID的顺序是A-C-D-E-F。
S140,分析数据库中每一个调用追踪标识对应的调用信息,得到整个服务调用系统中各个节点之间调用关系,以及各个节点的调用参数。
在本申请一种可能的实现方式中,以所述调用追踪标识为单元从所述数据库中读取对应的调用信息;解析所述调用追踪标识对应的调用信息,得到具有依赖关系的调用树,所述调用树中各个节点的值包括调用次数、异常次数和调用耗时;对所述调用树中每个节点的值进行聚合分析,得到每秒查询率、平均耗时、调用关系和调用来源。
例如,利用Hadoop集群对HBase集群中的数据进行离线分析,其中,利用Hadoop MapReduce从HBase中读取数据并进行离线分析,在map阶段,从HBase中以单个调用链路为单位读取数据,然后解析,组成具有依赖关系的调用树,以调用次数、异常次数、调用耗时等信息作为value写入reduce;在reduce阶段对数据进行聚合分析,得到QPS(Query Per Second,每秒查询率)、平均耗时、依赖关系、调用来源等信息。
本申请实施例提供的服务调用链路分析方法,服务端接收到客户端发送的服务调用请求后,生成该服务调用请求唯一对应的调用追踪标识,且该调用追踪标识在整个调用链路中传递。服务端获取调用对应的全部日志信息,然后,对日志信息进行处理得到该调用追踪标识对应的调用信息,并将该调用信息存储到数据库中。最后,离线分析数据库中存储的调用信息,得到整个服务调用系统中各个节点之间的调用关系及调用参数。该方法将调用关系存储数据库中,然后对数据库中的数据进行离线分析,得到整个服务调用系统的调用关系、调用耗时、依赖度等信息。以便下一步分析服务调用系统中的性能瓶颈并进行优化。
请参见图3,示出了本申请实施例另一种服务调用链路分析方法的流程图,该方法应用于服务端。本实施例在图2所示实施例的基础上还包括以下步骤:
S210,利用ElasticSearch为调用信息创建索引,所述索引包括服务名、调用耗时、异常信息和调用方信息。
ElasticSearch是一个基于Lucene的搜索服务器,它提供了一个分布式多用户能力的全文搜索引擎。
在利用ElasticSearch为调用信息创建索引时,以整个链路为单位建立索引,只需要一条服务调用链路中根结点的数据。因此,在对日志信息实时处理时,需要过滤掉kafka队列中的非根结点数据,得到根结点数据。而且,实时处理和索引创建两个阶段所要求的数据格式不相同,因此,需要对实时处理后的数据进行格式转换。
实时处理阶段,从kafka队列中读取数据并过滤掉不符合条件的数据,然后,对数据进行格式转换、计算调用耗时、分析调用来源组合消息,并将分析结果提供给ElasticSearch。
ElasticSearch创建的索引可以是整个调用链路的服务名、调用耗时、调用时间、异常信息、用户ID等信息,用户可以利用这些索引查询调用链路列表中的调用追踪标识,然后,利用调用追踪标识从数据存储模块中查找该调用链路对应的调用信息。
本实施例提供的服务调用链路分析方法,对实时处理后得到的调用信息创建服务调用链路索引,提高查询效率,根据查询得到的调用追踪标识从存储调用信息的数据库中查询得到服务调用链路对应的数据。
对于前述的各方法实施例,为了简单描述,故将其都表述为一系列的动作组合,但是本领域技术人员应该知悉,本发明并不受所描述的动作顺序的限制,因为依据本发明,某些步骤可以采用其他顺序或者同时进行。其次,本领域技术人员也应该知悉,说明书中所描述的实施例均属于优选实施例,所涉及的动作和模块并不一定是本发明所必须的。
相应于上述的服务调用链路分析方法实施例,本申请还提供了服务调用链路分析系统实施例。
请参见图4,示出了本申请实施例一种服务调用链路分析系统的示意图,如图4所示,该系统包括数据获取模块110、实时处理模块120、数据存储模块130和离线分析模块140,其中,数据获取模块110包括埋点和数据收集模块。
数据获取模块110,用于获取服务调用请求的日志信息。
在客户端和服务端均设置有埋点,通过埋点收集服务调用过程中的日志数据;数据埋点的四个阶段包括:客户端发起请求时埋点、服务端接收请求时埋点、服务端返回请求时埋点、客户端接收请求时埋点。
各个埋点将收集的数据发送给数据收集模块。其中,日志数据包括:调用追踪标识、调用开始时间、调用类型、协议类型、调用方IP和端口、请求的服务名、调用耗时、调用结果、异常信息和消息报文等信息。
客户端和服务端的埋点收集到的日志数据提供给数据收集模块,其中,数据收集模块是kafka队列。Kafka队列是由Linkedin开发的一个分布式的消息队列系统。通过埋点将数据发送至kakfa队列,实现了工程解耦,消息异步传输,提高并发。
为了减轻上传日志数据对业务的影响,采用异步方式上报到服务调用链路分析系统的后台。
实时处理模块120,用于根据所述日志信息得到所述调用追踪标识对应的调用信息,所述调用信息包括整个服务调用链路中各个调用节点对应的调用时间、服务名、调用耗时、调用来源信息及调用关系。
实时处理模块120可以通过storm集群实现,Storm适用于处理潜在无限的流式数据。从消息队列读取数据并进行处理分析过滤,提高系统的并发性能。
实时处理模块120从kafka队列中读取数据并进行实时处理,主要处理过程包括:过滤掉不符合条件的数据(例如,过滤重复数据)、计算每个节点的调用耗时以及分析调用来源消息等,并将处理后的结果存储到数据存储模块130中。
数据存储模块130采用HBase集群实现,数据存储模块中的数据以调用追踪标识作为行(或列)关键字,调用节点ID作为列(或行)关键字,而且,调用节点ID的先后顺序即节点的调用顺序,这样,能把一整条的调用链路聚合起来。
离线分析模块140,用于分析数据库中每一个调用追踪标识对应的调用信息,得到整个服务调用系统中各个节点之间调用关系,以及各个节点的调用参数。
在本申请一种可能的实现方式中,离线分析模块140可以通过Hadoop集群实现。
Hadoop是一个由Apache基金会所开发的分布式系统基础架构。用户可以在不了解分布式底层细节的情况下,开发分布式程序,充分利用集群的威力进行高速运算和存储。Hadoop框架核心的设计是:HDFS(Hadoop Distributed File System,Hadoop分布式文件系统)和MapReduce。HDFS为海量的数据提供了存储,而MapReduce为海量的数据提供了计算,MapReduce是一种编程模型,用于大规模数据集(大于1TB)的并行运算。
在本申请一种可能的实现方式中,利用Hadoop MapReduce从HBase中读取数据并进行离线分析,在map阶段,从HBase中以单个调用链路为单位读取数据,然后解析,组成具有依赖关系的调用树,以调用次数、异常次数、调用耗时等信息作为value写入reduce;在reduce阶段对数据进行聚合分析,得到QPS(Query Per Second,每秒查询率)、平均耗时、依赖关系、调用来源等信息。
本申请实施例提供的服务调用链路分析系统,服务端接收到客户端发送的服务调用请求后,生成该服务调用请求唯一对应的调用追踪标识,且该调用追踪标识在整个调用链路中传递。服务端获取调用对应的全部日志信息,然后,对日志信息进行处理得到该调用追踪标识对应的调用信息,并将该调用信息存储到数据库中。最后,离线分析数据库中存储的调用信息,得到整个服务调用系统中各个节点之间的调用关系及调用参数。利用该装置将调用关系存储数据库中,然后对数据库中的数据进行离线分析,得到整个服务调用系统的调用关系、调用耗时、依赖度等信息。以便下一步分析服务调用系统中的性能瓶颈并进行优化。
请参见图5,示出了本申请实施例另一种服务调用链路分析系统的示意图,本实施例在图2所示实施例的基础上还可以包括索引创建模块160。
索引创建模块160,接收实时处理模块处理后的数据结果,并对数据结果创建索引。
索引创建模块160利用elasticsearch集群实现,ElasticSearch是一个基于Lucene的搜索服务器,它提供了一个分布式多用户能力的全文搜索引擎。
索引创建模块为调用信息创建索引时,以整个链路为单位建立索引,只需要一条服务调用链路中根结点的数据,因此,实时处理模块130需要过滤掉kafka队列中的非根结点数据,得到根结点数据。而且,实时处理模块和索引创建模块所要求的数据格式不相同,因此,需要实时处理模块对处理后的数据进行格式转换。
实时处理模块130从kafka队列中读取数据并过滤掉不符合条件的数据,然后,对数据进行格式转换、计算调用耗时、分析调用来源组合消息,并将分析结果写入索引创建模块160中。
索引创建模块创建的索引可以是整个调用链路的服务名、调用耗时、调用时间、异常信息、用户ID等信息,用户可以利用这些索引查询调用链路列表中的调用追踪标识,然后,利用调用追踪标识从数据存储模块中查找该调用链路对应的调用信息。
本实施例提供的服务调用链路分析系统,对实时处理后得到的调用信息创建服务调用链路索引,提高查询效率,根据查询得到的调用追踪标识从存储调用信息的数据库中查询得到服务调用链路对应的数据。
需要说明的是,本说明书中的各个实施例均采用递进的方式描述,每个实施例重点说明的都是与其他实施例的不同之处,各个实施例之间相同相似的部分互相参见即可。对于装置类实施例而言,由于其与方法实施例基本相似,所以描述的比较简单,相关之处参见方法实施例的部分说明即可。
最后,还需要说明的是,在本文中,诸如第一和第二等之类的关系术语仅仅用来将一个实体或者操作与另一个实体或操作区分开来,而不一定要求或者暗示这些实体或操作之间存在任何这种实际的关系或者顺序。而且,术语“包括”、“包含”或者其任何其他变体意在涵盖非排他性的包含,从而使得包括一系列要素的过程、方法、物品或者设备不仅包括那些要素,而且还包括没有明确列出的其他要素,或者是还包括为这种过程、方法、物品或者设备所固有的要素。在没有更多限制的情况下,由语句“包括一个……”限定的要素,并不排除在包括所述要素的过程、方法、物品或者设备中还存在另外的相同要素。
对所公开的实施例的上述说明,使本领域技术人员能够实现或使用本发明。对这些实施例的多种修改对本领域技术人员来说将是显而易见的,本文中所定义的一般原理可以在不脱离本发明的精神或范围的情况下,在其它实施例中实现。因此,本发明将不会被限制于本文所示的这些实施例,而是要符合与本文所公开的原理和新颖特点相一致的最宽的范围。
以上所述仅是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!