基于GPU的大规模连续变量量子密钥分发的数据协调方法与流程
本发明涉及连续变量量子密钥分发技术领域,尤其涉及一种基于gpu的大规模连续变量量子密钥分发的数据协调方法。
背景技术:
随着计算机信息技术的迅速发展,信息安全也占据着十分重要的地位。量子密钥分发(qkd)具有物理的无条件安全性,从而量子保密通信获得了人们的广泛关注。其中,连续变量量子密钥分发(cv-qkd)是量子保密通信领域中的一个重要分支,成为众多学者们研究的热点。cv-qkd的技术框架是alice发送端通过对光子进行相干态调制,将连续高斯变量x经量子信道传送至bob接收端,bob接收端通过零拍探测器探测后接收序列y。然而,由于一些不可避免的噪音以及第三方窃听者实际存在于量子信道,导致bob接收端接收的序列y会存在一些误码。为了纠正这些误码,需要对连续变量量子密钥分发进行数据协调,以去除窃听或信道噪声所引入的误码。因此,数据协调在本质上是一个纠错过程。
目前,cv-qkd的数据协调方法为:在cpu上使用低密度奇偶校验码(ldpc码)为基本错误校正码,采用逆向协调结合mlc/msd的协调方案来实现。
然而,由于cpu工作是串行的,cv-qkd数据协调的msd多级译码方案是各级分别进行ldpc译码,译码算法采用对数域译码,校验矩阵采用随机稀疏校验矩阵,矩阵规模大,加之需要bp(置信传播)多次译码才能校正错码,这使得译码速度缓慢,导致数据协调效率不高。
技术实现要素:
为了解决目前的大规模连续变量量子密钥分发的数据协调方法在cpu上实现,导致译码速度慢、数据协调效率不高的技术问题,本发明提供一种基于gpu的大规模连续变量量子密钥分发的数据协调方法。
本发明的技术方案是:
一种基于gpu的大规模连续变量量子密钥分发的数据协调方法,其包括:
步骤1,cpu将ldpc稀疏校验矩阵h以静态双向循环十字链表的方式进行存储,并通过cpu与gpu之间的通信接口将该ldpc稀疏校验矩阵h发送至gpu;
步骤2,cpu控制发送端alice通过量子信道将大规模连续变量量子x发送至接收端bob;cpu控制接收端bob首先通过零拍探测器探测到序列y后,对序列y进行量化,得到二进制离散序列y′;然后,cpu控制接收端bob使用多级编码调制将二进制离散序列y′分级,得到第1级码流序列、第2级码流序列、第3级码流序列和第4级码流序列,并将第3级码流序列和第4级码流序列经slepian-wolf编码器进行数据压缩后,得到编码后的第3级码流序列和编码后的第4级码流序列;接下来,cpu控制接收端bob将ldpc稀疏校验矩阵h与编码后的第3级码流序列和编码后的第4级码流序列分别相乘,得到第3级码流序列对应的校验子和第4级码流序列对应的校验子sj(j=3,4);最后,cpu控制接收端bob将第1级码流序列、第2级码流序列、第3级码流序列对应的校验子和第4级码流序列对应的校验子sj(j=3,4)通过理想经典信道发送回发送端alice;
步骤3,gpu根据发送端alice上的第3级码流序列对应的校验子和第4级码流序列对应的校验子sj(j=3,4)及发送端alice自身存储的边信息x,分配多个线程进行并行化多级解码,直至满足收敛条件或者达到最大迭代次数时译码结束。
可选地,所述步骤1中cpu将ldpc稀疏校验矩阵h以静态双向循环十字链表的方式进行存储,包括:
步骤1.1,cpu获取ldpc稀疏校验矩阵h中的非零元素的个数,申请静态大小为非零元素个数的连续内存,并将所有的非零元素存储在这片内存中;
步骤1.2,cpu以结构体数组的形式定义数据域,其中,数据域代表非零元素的节点,数据域里面的成员有似然比信息值及前后左右节点的位置地址信息值;位置地址信息值区别于动态链表中的指针类型,而是被定义为int的数据类型;第i个非零元素存放在静态内存中,在行上,i中的右位置地址信息值代表第i+1个非零元素的行位置,左位置地址信息值代表第i-1个非零元素的行位置;在列上,i中的前位置地址信息值代表第i+1个非零元素的列位置,后位置地址信息值代表第i-1个非零元素的列位置;
步骤1.3,cpu以数据域的形式生成行头指针域tx和列头指针域tf,这两个数组指向的地址是步骤1.1中申请的非零元素大小的静态内存的地址;
步骤1.4,cpu指向行头指针域tx和列头指针域tf,指针指向第一个非零元素的位置,获取到该第一个非零元素的所有信息后,cpu根据第一个非零元素中的位置地址信息值指向下一个非零元素的位置,得到下一个非零元素的信息后,指针又会根据位置地址信息值指向新的位置信息,依次执行下去即可获取到所有的非零元素的信息,从而得到以静态双向循环十字链表的方式存储的ldpc稀疏校验矩阵h。
可选地,所述步骤3中gpu根据发送端alice上的第3级码流序列对应的校验子和第4级码流序列对应的校验子sj(j=3,4)及发送端alice自身存储的边信息x,分配多个线程进行并行化多级解码,直至满足收敛条件或者达到最大迭代次数时译码结束,包括:
gpu根据发送端alice上的第3级码流序列对应的校验子和第4级码流序列对应的校验子sj(j=3,4)及发送端alice自身存储的边信息x,分配多个线程依据多级译码步骤更新非零元素数据域中的似然比信息值,直至满足收敛条件或者达到最大迭代次数时译码结束,其中,该似然比信息值就是指每一次译码步骤后的结果值,ldpc码可以由ldpc稀疏校验矩阵h唯一表示,ldpc稀疏校验矩阵行上的非零元素就称为校验节点,列上的非零元素称为变量节点;
其中,多级译码步骤如下:
步骤3.1,gpu进行信息初始化,即初始化
公式(1)中,
步骤3.2,gpu通过如下公式(2)计算校验节点传递给变量节点的外信息;
公式(2)中,对于1ttmax,1ppmax,tmax=1为级间迭代次数,p表示ldpc置信传播和积算法的迭代次数,pmax=100,sk表示校验序列中校验节点k对应的校验位,i′jk表示除变量节点ij外与校验节点k相连的所有变量节点的集合;
步骤3.3,gpu通过如下公式(3)计算变量节点传递给校验节点的外信息;
公式(3)中,k′ij表示除校验节点k外与变量节点ij相连的所有校验节点的集合;
步骤3.4,转至步骤3.2,直至p>pmax时执行步骤3.5;
步骤3.5,gpu通如下公式(4)和(5)对所有变量节点计算硬判决信息
步骤3.6,gpu根据硬判决信息
其中,
步骤3.7,令p=0,t=t+1,如果t>tmax则译码结束;否则,返回步骤3.2直至t>tmax。
本发明的实施例提供的技术方案可以包括以下有益效果:
通过将ldpc稀疏校验矩阵h以静态双向循环十字链表的方式进行存储,可以实现由gpu参与译码过程,又由于gpu具有并行处理结构,可以实现多线程数据计算。本发明通过静态双向十字循环链表的数据结构存储ldpc大规模稀疏校验矩阵h,只需存储非零元的信息,节省了内存,在内存中的存储地址连续,便于gpu将ldpc稀疏校验矩阵在cpu和gpu之间来回传输,从而解决了存储瓶颈。通过gpu固有的多线程计算结构,使多级解码在gpu上并行执行,提高了数据协调速率。因此,与背景技术相比,本发明具有能够缩短数据协调时间、提高译码速率及提高数据协调效率等优点。
附图说明
图1是本发明提供的基于gpu的大规模连续变量量子密钥分发的数据协调方法的流程图。
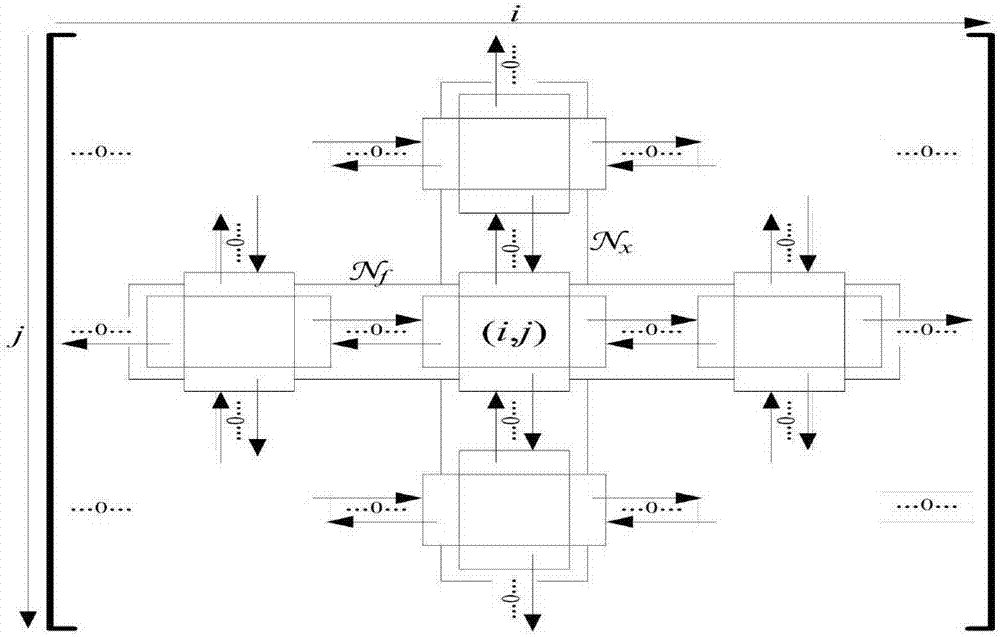
图2是本发明中以静态双向循环十字链表的方式存储的ldpc稀疏校验矩阵的结构图。
图3是基于gpu的大规模连续变量量子密钥分发的数据协调方法的过程示意图。
图4是gpu进行多级译码时级间迭代的消息传递tanner图。
具体实施方式
为使本发明的目的、技术方案和优点更加清楚,下面将结合附图对本发明实施方式作进一步地详细描述。
如图1所示,本实施例中的基于gpu的大规模连续变量量子密钥分发的数据协调方法包括如下步骤1至步骤3:
步骤1,cpu将ldpc稀疏校验矩阵h以静态双向循环十字链表的方式进行存储,并通过cpu与gpu之间的通信接口将该ldpc稀疏校验矩阵h发送至gpu。
ldpc稀疏校验矩阵h有三元组表和动态十字链表两种存储方式。三元组表法是针对固定非零元位置和个数的稀疏校验矩阵h;动态十字循环链表适合稀疏校验矩阵h中非零元的位置或个数经常变动时使用,但是在内存中存储地址是不连续的。然而,在gpu上运算时,传输的数据需要在内存中存储地址是连续的,固定大小的。因此,本发明中采用静态双向循环十字链表的数据结构存储ldpc稀疏校验矩阵h,对现有的动态链表进行改进,使之在内存中存储地址是连续,同时又保持链表的优势,从而使后续gpu可以参与多级译码,以实现并行运算。
其中,所述步骤1中cpu将ldpc稀疏校验矩阵h以静态双向循环十字链表的方式进行存储时,可以通过如下步骤1.1至步骤1.4来实现:
步骤1.1,cpu获取ldpc稀疏校验矩阵h中的非零元素的个数,申请静态大小为非零元素个数的连续内存,并将所有的非零元素存储在这片内存中;
步骤1.2,cpu以结构体数组的形式定义数据域,其中,数据域代表非零元素的节点,数据域里面的成员有似然比信息值及前后左右节点的位置地址信息值;位置地址信息值区别于动态链表中的指针类型,而是被定义为int的数据类型;第i个非零元素存放在静态内存中,在行上,i中的右位置地址信息值代表第i+1个非零元素的行位置,左位置地址信息值代表第i-1个非零元素的行位置;在列上,i中的前位置地址信息值代表第i+1个非零元素的列位置,后位置地址信息值代表第i-1个非零元素的列位置;
步骤1.3,cpu以数据域的形式生成行头指针域tx和列头指针域tf,这两个数组指向的地址是步骤1.1中申请的非零元素大小的静态内存的地址;
步骤1.4,cpu指向行头指针域tx和列头指针域tf,指针指向第一个非零元素的位置,获取到该第一个非零元素的所有信息后,cpu根据第一个非零元素中的位置地址信息值指向下一个非零元素的位置,得到下一个非零元素的信息后,指针又会根据位置地址信息值指向新的位置信息,依次执行下去即可获取到所有的非零元素的信息,从而得到以静态双向循环十字链表的方式存储的ldpc稀疏校验矩阵h。
本发明使用一种只记录1的位置方式的“静态双向循环十字链表”的方法存储ldpc稀疏校验矩阵h,这种存储方式充分结合了静态顺序存储和链式存储结构两者的优点,以静态顺序存储结构存储数据,但是每一个非零元之间的逻辑关系是使用节点的数组下标作为位置索引来维持节点与节点之间前驱和后继的关系,这种数组下标就类似于动态链表中的指针,用来指向下一个节点的位置。如图2所示,其为本发明中以静态双向循环十字链表的方式存储的ldpc稀疏校验矩阵的结构图。
进一步地,cpu与gpu之间的通信接口将该ldpc稀疏校验矩阵h发送至gpu时,cpu可以通过cuda定义的接口函数cudamemcpy()向设备gpu传输以静态双向循环十字链表存储的ldpc稀疏校验矩阵h。
步骤2,cpu控制发送端alice通过量子信道将大规模连续变量量子x发送至接收端bob;cpu控制接收端bob首先通过零拍探测器探测到序列y后,对序列y进行量化,得到二进制离散序列y′;然后,cpu控制接收端bob使用多级编码调制将二进制离散序列y′分级,得到第1级码流序列、第2级码流序列、第3级码流序列和第4级码流序列,并将第3级码流序列和第4级码流序列经slepian-wolf编码器进行数据压缩后,得到编码后的第3级码流序列和编码后的第4级码流序列;接下来,cpu控制接收端bob将ldpc稀疏校验矩阵h与编码后的第3级码流序列和编码后的第4级码流序列分别相乘,得到第3级码流序列对应的校验子和第4级码流序列对应的校验子sj(j=3,4);最后,cpu控制接收端bob将第1级码流序列、第2级码流序列、第3级码流序列对应的校验子和第4级码流序列对应的校验子sj(j=3,4)通过理想经典信道发送回发送端alice。
其中,步骤2为cpu对大规模连续变量量子x进行(mlc)的过程,具体多级编码过程除步骤2中所述外,还可以参考现有技术中的多级编码方式,此处不对这部分内容进行详细解释。
步骤3,gpu根据发送端alice上的第3级码流序列对应的校验子和第4级码流序列对应的校验子sj(j=3,4)及发送端alice自身存储的边信息x,分配多个线程进行并行化多级解码,直至满足收敛条件或者达到最大迭代次数时译码结束。
多级解码(msd)译码方法就是各级分别译码,每一级的译码结果对其它级的译码有指引作用。具体地,所述步骤3中gpu根据发送端alice上的第3级码流序列对应的校验子和第4级码流序列对应的校验子sj(j=3,4)及发送端alice自身存储的边信息x,分配多个线程进行并行化多级译码,直至满足收敛条件或者达到最大迭代次数时译码结束时,可以通过如下步骤3.1至步骤3.7来实现:
gpu根据发送端alice上的第3级码流序列对应的校验子和第4级码流序列对应的校验子sj(j=3,4)及发送端alice自身存储的边信息x,分配多个线程依据多级译码步骤更新非零元素数据域中的似然比信息值,直至满足收敛条件或者达到最大迭代次数时译码结束,其中,该似然比信息值就是指每一次译码步骤后的结果值,ldpc码可以由ldpc稀疏校验矩阵h唯一表示,ldpc稀疏校验矩阵行上的非零元素就称为校验节点,列上的非零元素称为变量节点;
其中,多级解码(msd)步骤如下:
步骤3.1,gpu进行信息初始化,即初始化
公式(1)中,
步骤3.2,gpu通过如下公式(2)计算校验节点传递给变量节点的外信息;
公式(2)中,对于1ttmax,1ppmax,tmax=1为级间迭代次数,级间迭代就是在变量节点到校验节点之间传递的外信息的基础上叠加节点内部流动的内信息;p表示ldpc置信传播和积算法的迭代次数,pmax=100,sk表示校验序列中校验节点k对应的校验位,i′jk表示除变量节点ij外与校验节点k相连的所有变量节点的集合;
步骤3.3,gpu通过如下公式(3)计算变量节点传递给校验节点的外信息;
公式(3)中,k′ij表示除校验节点k外与变量节点ij相连的所有校验节点的集合;
步骤3.4,转至步骤3.2,直至p>pmax时执行步骤3.5;
步骤3.5,gpu通如下公式(4)和(5)对所有变量节点计算硬判决信息
步骤3.6,gpu根据硬判决信息
其中,
步骤3.7,令p=0,t=t+1,如果t>tmax则译码结束;否则,返回步骤3.2直至t>tmax。
如图3所示,其为步骤2和步骤3所述的基于gpu的大规模连续变量量子密钥分发的数据协调方法的过程示意图。图4是gpu进行多级译码时级间迭代的消息传递tanner图,图4中黑色为外信息传递过程,白色为内信息传递过程。
为了验证本发明的实用性,在信道信噪比为4.9db以上、2×105个连续变量序列可靠协调以及协调效率为91.71%的情况下,分别基于geforcegt650m的gpu和2.5ghz、8g内存的cpu硬件平台进行译码测试,得到的结果如表1所示。
表1
由表1可得,基于gpu进行多级解码,其译码速率可达16.4kbit/s,相对于cpu平台,计算速度提高15倍以上。因此,与现有技术在cpu上进行数据协调相比,本发明中的基于gpu进行数据协调的方法不仅能够缩短数据协调时间,而且能够提高译码速率。
需要说明的是,以上所述仅为本发明的佳实施例,并不用以限制本发明,凡在本发明的精神和原则之内所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!