DCT域内视频分形脆弱水印算法的制作方法
本发明涉及视频图像处理技术领域,具体涉及一种DCT域内视频分形脆弱水印算法。
背景技术:
近年来,随着计算机网络和多媒体技术的快速发展,多媒体信息的拷贝和传播变得越来越容易,多媒体信息的版权和所有权也越来越容易被侵犯。因此,作为版权保护的有效手段,数字水印技术成为多媒体信息安全的一个研究热点。用于完整性认证的水印分为脆弱性水印和半脆弱性水印。脆弱性水印对任何篡改都具有很强的敏感性,适合用作多媒体数据的精确认证。如王让定、朱洪留等提出了H.264/AVC视频流完整性认证的脆弱水印算法,该算法嵌入和提取过程简单、快速,并且具有很好的隐蔽性。半脆弱性水印对譬如置换、剪切等恶意篡改具有敏感性,但是对譬如JPEG和MPEG有损压缩等处理具有鲁棒性。如曾骁、陈真勇等提出了用于内容认证的半脆弱可逆视频水印算法,该算法实现了对视频内容完整性的验证,但是对P帧和B帧的篡改只能定位到帧,并不能定位到篡改的具体位置。黄修训提出了用于视频内容完整性认证的半脆弱水印算法,该算法实现了视频恶意篡改的检测,篡改位置的准确定位和内容特征的重构恢复,但嵌入方法使视频质量有所下降,效果不够理想,水印嵌入对视频码率影响较大。
技术实现要素:
本发明的目的在于提供一种DCT域内视频分形脆弱水印算法,本算法分形技术和小波变换二者有机结合,提取经过DWT变换后视频I帧的分形特征,然后结合B、P帧的位置特征生成认证码,用Logistic混沌映射置乱后嵌入到每一帧指定的DCT块系数中。本算法在保证原视频质量的情况下,可以有效的检测到对视频的篡改和攻击,并且可以精确定位篡改和攻击的位置。
为了实现上述目的,本发明采用如下技术方案:DCT域内视频分形脆弱水印算法,包括如下步骤:
S1.对MPEG视频进行分帧,提取每一个GOP中的I帧和B、P帧,并转换为YUV色彩模式;
S2.计算I帧的分形特征W1;
S3.构造GOP中每一帧的位置特征W2;
S4.将W1和W2进行异或操作,得到水印信息W;
S5.在GOP相应的每一帧中嵌入对应的水印信息W。
进一步地,所述步骤S2中计算I帧的分形特征W1的步骤为:将I帧(M×N)的Y分量进行一级小波变换,并将变换后的系数划分为R块(b×b)和D块(2b×2b),利用仿射变换,寻找每一个R块的最佳匹配D块,记录所述D块的位置(m,n),若m和n的奇偶性相同,则该R块对应值为1,否则该R块对应值为0,则I帧的分形特征W1为一个的二值矩阵;其中,M×N是指视频I帧的大小,(m,n)为D块的位置。
进一步地,寻找每一个R块的最佳匹配D块之前,先对D块进行预分类。
进一步地,对D块进行预分类的步骤是:首先计算R块和D块方差的大小,设定方差阈值,对每一个R块,根据设定的方差阈值来确定D块的搜索子集,从而完成对D块的预分类。
进一步地,所述步骤S2中构造GOP中每一帧的位置特征W2的步骤为:将GOP中每一帧都进行b×b分块,然后对每块进行DCT变换,构造视频帧的位置特征:
W2(i,m×n)=((mi×ni)mod 7)mod 2
其中,i表示视频中的第i帧,(m,n)表示第i帧中DCT块的位置。
进一步地,所述步骤S4中,将W1和W2进行异或操作之后,再进行加密处理的步骤。
进一步地,所述加密处理的步骤是用Logistic混沌映射进行置乱处理。
进一步地,所述步骤S5中在GOP相应的每一帧中嵌入对应的水印信息W的具体步骤是,将要进行嵌入水印信息的视频帧进行b×b分块,然后分别对每块进行DCT变换,在每个DCT块中嵌入对应的水印信息。
进一步地,在每个DCT块中嵌入对应的水印信息时,只选择每个DCT块中的两个高频非0系数进行水印信息嵌入。
进一步地,两个所述高频非0系数是zig-zag扫描中最后两个非0系数,然后将两个相同的水印信息分别嵌入到这两个非0系数的LSB位上。
本发明提出了一种DCT域内视频分形脆弱水印算法,将水印信息嵌入到视频帧YUV色彩模式的Y分量中。根据DWT变换后系数的自相似性,结合分形的方法提取出视频I帧稳定的分形特征,然后根据每一帧的位置生成不同的位置特征,将位置特征和分形特征异或之后用Logistic混沌映射进行加密得到水印信息W,最后将得到的水印信息嵌入到GOP中每一个视频帧DCT变换后的高频系数中。实验结果表明,该算法能较好的保证视频的质量,满足水印不可见性的要求,并且对视频做一些常规的攻击,该算法可以有效地检测和精确定位到遭到攻击和篡改的位置,能满足视频完整性认证的要求。
附图说明
图1为水印嵌入前后效果图;
其中,(a)为原始帧(第16帧);(b)为水印帧,PSNR=49.16dB;(c)为原始帧(第30帧);(d)为水印帧,PSNR=48.57dB;
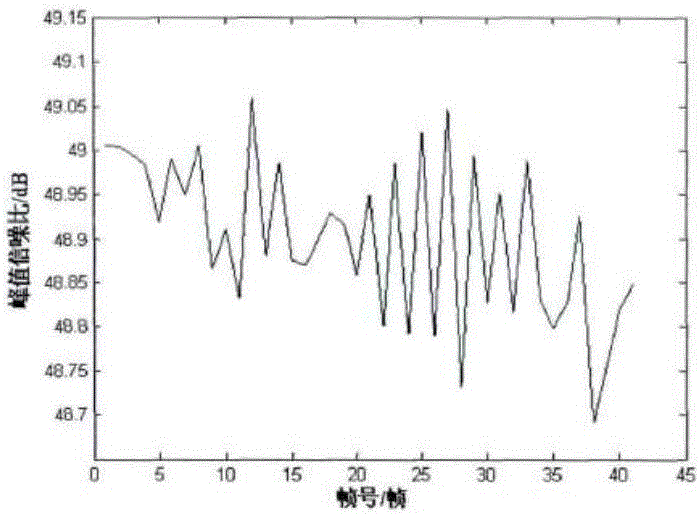
图2为PSNR变化图;
图3为原始帧检测结果;
其中,(a)Akiyo原始帧(未受攻击),检测结果Error=0%;(b)Foreman原始帧(未受攻击),检测结果Error=0%;
图4为椒盐噪声攻击结果;
其中,(a)椒盐噪声攻击(强度0.01),检测结果Error=15.06%;(b)椒盐噪声攻击(强度0.05)检测结果Error=41.64%;
图5为中值滤波攻击结果;
其中,(a)中值滤波攻击,检测结果Error=50.13%;(b)中值滤波攻击,检测结果Error=50.58%;
图6为MPEG压缩攻击结果;
其中,(a)MPEG压缩(压缩质量为60),检测结果Error=51.43%;(b)MPEG压缩(压缩质量为75),检测结果Error=49.65%;
图7为视频帧篡改定位;
其中,(a)Akiyo篡改帧,篡改定位结果;(b)Foreman篡改帧,篡改定位结果。
具体实施方式
下面结合具体实施方式对本发明的内容进行详细阐述。
DCT域内视频分形脆弱水印算法,包括如下步骤:
S1.对MPEG视频进行分帧,提取每一个GOP(Group of Pictures)中的I帧和B、P帧,并转换为YUV色彩模式,
在H.264压缩标准中I帧、P帧、B帧用于表示传输的视频画面。
其中,I帧又称帧内编码帧,是一种自带全部信息的独立帧,无需参考其他图像便可独立进行解码,可以简单理解为一张静态画面。视频序列中的第一个帧始终都是I帧,因为它是关键帧。
P帧又称帧间预测编码帧,需要参考前面的I帧才能进行编码,表示的是当前帧画面与前一帧(前一帧可能是I帧也可能是P帧)的差别。解码时需要用之前缓存的画面叠加上本帧定义的差别,生成最终画面。与I帧相比,P帧通常占用更少的数据位,但不足是,由于P帧对前面的P和I参考帧有着复杂的依赖性,因此对传输错误非常敏感。
B帧又称双向预测编码帧,也就是B帧记录的是本帧与前后帧的差别。也就是说要解码B帧,不仅要取得之前的缓存画面,还要解码之后的画面,通过前后画面的与本帧数据的叠加取得最终的画面。B帧压缩率高,但是对解码性能要求较高。
S2.计算I帧的分形特征W1;
1.将I帧(M×N)的Y分量进行一级小波变换,然后根据经典分形编码方法,将变换后的系数划分为R块(b×b)和D块(2b×2b),计算R块和D块方差的大小,设定方差阈值,方差阈值是经过多次试验之后确定的一个数值,防止小于阈值的D块数量过少。对每一个R块,根据设定的方差阈值来确定D块的搜索子集,从而完成对D块的预分类。利用仿射变换,从预分类的D块集合中找到最佳匹配的D块。这样把全局搜索范围变成了局部搜索范围,既保证了编码质量,又加快了搜索速度。最后将每一个R块对应的最佳匹配D块的位置(m,n)记录下来。若m和n的奇偶性相同,则该R块对应值为1,否则该R块对应值为0。这样就得到I帧的分形特征W1,是一个的二值矩阵。
S3.构造GOP中每一帧的位置特征W2。
将GOP中每一帧都进行b×b分块,然后对每块进行DCT变换,构造视频帧的位置特征:
W2(i,m×n)=((mi×ni)mod 7)mod 2 (1)
其中,i表示视频中的第i帧,m和n表示第i帧中DCT块的位置信息。
S4.将W1和W2进行异或操作,得到水印信息W。
将得到的W1和W2进行异或操作,然后用Logistic混沌映射进行置乱,得到最后的水印信息W。
Logistic混沌映射是一种有代表性的非线性混沌方程。虽然它有明确的形式,并且表达式中不含有任何随机因素,但是它却能得到随机的、对系数μ和初值的变化极为敏感的序列。其一般形式为:
Xn+1=μXn(1-Xn) (2)
其中,Xn为映射变量,取值范围为0≤Xn≤1;μ为系统参数,取值范围为0<μ≤4。当3.5699456<μ≤4时,系统处于混沌状态。用上式对水印信息进行置乱,增加了水印的安全性。使他人在不知道初值和μ的情况下,无法得到原水印信息。
S5.在GOP相应的每一帧中嵌入对应的水印信息W。
将要进行水印嵌入的视频帧进行b×b分块,然后对每块分别进行DCT变换。因为水印信息W是由视频I帧DWT系数的分形特征以及B、P帧的位置特征生成的,所以在相应GOP的每一帧中都要嵌入W。为了使嵌入的水印W具有较好的不可见性,只选择每个DCT块中的两个系数进行水印嵌入。同时为了保持视频流的稳定性,选择对高频的非0系数进行操作,将水印嵌入到zig-zag扫描中最后两个非0系数的LSB位上,在这两个系数中嵌入相同的水印信息,因为在高频区嵌入水印对篡改和攻击具有较强的敏感性。
介绍水印提取与完整性认证。
(1)利用嵌入水印之后的视频重新生成特征水印Wa。Wa与W的生成过程完全相同。因为水印嵌入时选择的是高频区的系数,所以不容易改变DWT系数中R块与D块的最佳匹配关系,即I帧的分形特征是非常稳定的。在视频未受到任何攻击的情况下,Wa与W应该完全相同。
(2)由于将水印分别嵌入到DCT块中的两个系数的LSB位上,所以通过提取视频帧DCT块的相应系数LSB位上的数字,即可得到水印信息Wa1和Wa2。
(3)比较Wa1和Wa2,若Wa1与Wa2完全相同,则将Wa1或Wa2与Wa作比较,计算错误率,计算公式为:
设定一个认证阈值η,若Error<η,完整性认证通过,否则,完整性认证不通过。如果视频帧完整性认证没有通过,比较Wa和Wa1,当Wa=Wa1时,记对应块的像素记为0,否则记对应块的像素为1,得到一个二值图像,图像中像素为1的部分就是被篡改的位置。若Wa1和Wa2不完全相同,计算错误率,计算公式为:
若Error<η,则将Wa1或Wa2与Wa作比较,否则,判定为认证不通过。如果完整性认证没有通过,对比Wa1与Wa2,当Wa1=Wa2时,记对应块像素为1,否则记对应块像素为0,得到一个二值图像,图像中像素为1的部分就是遭到篡改的位置。
实验结果与分析
实验中采用的视频序列为MPEG标准视频序列。下面给出Akiyo(每帧大小为352×288,共300帧)、Foreman(每帧大小为352×288,共300帧)标准测试序列的实验结果。视频完整性认证时,在没有对视频做任何攻击和篡改的情况下,提取的水印信息错误率必须为0。只要提取的水印信息错误率不为0,就认为视频遭到了一定程度的篡改和攻击。设置认证精度,当错误率小于阈值τ时,就可以认为完整性认证通过。经多次试验,设置认证的阈值为τ=0.001。
(1)不可见性检测
图1给出了Akiyo第16帧(关键帧)和第30帧(预测帧)嵌入水印前后的图像。从主观上看,加入水印前后几乎没有什么变化。客观上评价图像之间的差别常用峰值信噪比PSNR,PSNR值越大,表示图像质量越好。计算公式为:
式中,MSE为均方差。通过计算发现,嵌入水印之后视频帧PSNR变化幅度很小,仅有0.5dB左右。平均PSNR值为48.9dB,并且嵌入水印后每一帧视频的PSNR值都在48.5dB以上。说明利用该算法加入水印后,视频帧在视觉上没有变化,符合水印不可见性的原则。
(2)攻击检测
为了验证该算法的脆弱性,试验中对含有水印的视频进行了椒盐噪声、中值滤波和MPEG压缩等攻击。图3给出了含有水印的视频帧在不同攻击下认证结果图(白色部分为遭到篡改的部分)。
实验结果表明,在视频未受到任何攻击的情况下,检测结果错误率为0,保证了完整性认证的准确性。一旦检测结果错误率不为0,就说明了视频遭到了一定程度的篡改或攻击。
(3)椒盐噪声攻击
从图4中可以看出,椒盐噪声攻击强度越高,检测结果错误率越高。即使攻击强度很小,该算法也能检测出视频帧遭到了篡改或攻击。充分说明了该算法对攻击具有很强的灵敏性,即嵌入的水印具有较好的脆弱性。
(4)中值滤波攻击
如图5所示,实验结果表明,对视频帧进行中值滤波处理后,虽然肉眼观察不出什么视频帧发生了什么变化,但从检测结果可以看出,视频帧遭到了篡改或攻击。说明该算法对中值滤波攻击具有很强的敏感性。
(5)MPEG压缩攻击
从图6可以看出,随着压缩质量的提高,检测结果错误率越低。在压缩质量很高的情况下,该算法也能检测出视频帧遭到了篡改或攻击,说明了该算法对MPEG压缩攻击具有很强的敏感性。
(7)篡改定位
为了验证该算法对篡改部分定位的能力。实验中,在Akiyo视频中第16帧(关键帧)左上角加上ABCDEF字样,在Foreman视频第30帧(预测帧)左下角加上青科logo图案。篡改定位结果中白色部分为遭到篡改的区域。从实验结果中可以很明显的看出该算法对篡改攻击具有良好的敏感性,并且具有较高的定位精度。如图7所示。
本文提出了一种基于分形的视频脆弱水印算法,将水印信息嵌入到视频帧YUV色彩模式的Y分量中。根据DWT变换后系数的自相似性,结合分形的方法提取出视频I帧稳定的分形特征,然后根据每一帧的位置生成不同的位置特征,将位置特征和分形特征异或之后用Logistic混沌映射进行加密得到水印信息W,最后将得到的水印信息嵌入到GOP中每一个视频帧DCT变换后的高频系数中。实验结果表明,该算法能较好的保证视频的质量,满足水印不可见性的要求,并且对视频做一些常规的攻击,该算法可以有效地检测和精确定位到遭到攻击和篡改的位置,能满足视频完整性认证的要求。
- 还没有人留言评论。精彩留言会获得点赞!