一种基于类自然语言特征的算法生成域名检测方法与流程
本发明涉及算法生成域名检测领域,特别是一种基于类自然语言特征的算法生成域名检测方法。
背景技术:
域名系统是互联网中连接用户与互联网的桥梁,但由于其本身协议设计的脆弱性,大量的恶意行为通过域名系统进行控制和攻击,例如僵尸网络、木马病毒及高级持续威胁(advancedpersistentthreat,apt)攻击等。同时,在网络攻击中大量使用了dns定位技术、快速域名变换技术等域名生成技术,因此对生成域名进行检测显得尤为重要。目前,针对算法生成域名的检测主要可以分为以下两类:1)基于dns交互报文进行实时或准实时的深度报文检测(deeppacketinspection,dpi)检测方法;2)基于域名字符串本身的特征进行检测。
基于dns交互报文进行实时或准实时的dpi检测方法主要基于dns的通信行为、活动特征等进行检测,从而达到对算法生成域名的检测。比如,通过挖掘恶意域名有别于合法域名的通信特征以发现恶意域名;通过观察域名的字符组成及其查询请求者的相似性来聚类和检测僵尸网络使用的域名;通过统计域名查询请求的时间分布、域名映射ip地址的空间分布、生存时间值(timetolive,ttl)时间长短以及域名字面特征,发现恶意域名等。
基于域名字符串词法特征进行检测的方法主要是指通过提取域名的词法特征使用机器学习的方法实现算法生成域名的检测。比如:通过统计url长度、主机名长度、点的数目来检测钓鱼网站和邮件广告使用的恶意url;通过字频分布特征以及二元组的频率分布特征借助kullback-leibler差异(kullback-leiblerdivergence,kl距离)等距离测度算法进行检测;通过扩展语言学特征识别算法生成域名等。
当前针对算法生成域名的检测方法,根据实时或准实时的dpi检测方法,大部分针对特定攻击或特定环境其通用性较差;根据域名字符串词法特征进行检测的方法,部分是针对特定域名生成算法,其检测精度较低,部分检测方法需要依赖于庞大的语料库,具有较高的空间开销和计算复杂度。然而随着网络及应用环境日趋复杂,原有策略难以适应现有海量数据环境下层出不穷的恶意域名生成算法,因此提高生成域名检测方法的通用性和准确度以满足现有环境要求是亟待解决的问题。
技术实现要素:
本发明所要解决的技术问题是提供一种基于类自然语言特征的算法生成域名检测方法,解决针对特定攻击或特定环境其通用性较差的问题,可以检测出层出不穷的新型算法生成域名,对域名进行分级分别对每级域名进行特征提取,提高检测的精确度。
为解决上述技术问题,本发明采用的技术方案是:
一种基于类自然语言特征的算法生成域名检测方法,包括以下步骤:
步骤1:选取域名语料库,并针对域名语料库使用特征提取模块进行特征提取;
步骤2:针对域名语料库进行参数学习,得到各项特征的系统参数,获得基于语料库的检测模型;
步骤3:通过数据包嗅探模块获取dns服务器的请求域名信息;
步骤4:根据请求域名信息使用特征提取模块进行特征提取;
步骤5:在真实环境中根据检测模型对域名进行检测。
进一步的,所述特征提取模块计算过程为:
1)对域名按字符“.”进行分级,确定域名级数dlevel,对每级域名进行统计;
2)计算每级域名的长度length,即每级域名的字符个数;
3)计算每级域名中数字占比numratio,即每级域名中数字字符所占的比例;
4)计算每级域名的字符混淆度,域名中所含字符集为a={a1,a2,...,an},mai为字符ai出现的频次,则每级域名的字符混淆度h(domain):
5)计算每级域名的2-gram至n-gram马尔科夫转移概率,设域名为b=b1b2...bn,n-gram(k)表示相差k距离的两字符组成的序列其先验概率为pn-gram(k),则域名k阶马尔科夫转移概率markov(domain):
6)得到特征向量。
进一步的,所述域名语料库选择alexatop一百万域名及padcrypt、qadars、locky域名生成算法生成域名。
进一步的,所述检测模型采用支持向量机(supportvectormachine,svm)模型。
进一步的,所述真实检测环境采用spark平台。
与现有技术相比,本发明的有益效果是:1)本发明基于类自然语言特征对算法生成域名进行检测,提高了检测精确度,降低了检测误报率;2)本发明针对域名词法特征提出,不针对单一域名生成算法,具有较强的通用性;3)本发明构建类自然语言特征,充分考虑域名的自然语言特征。
附图说明
图1为本发明检测流程示意图。
图2为发明中算法生成域名示例图。
图3为本发明中alexatop一百万域名级数统计图。
图4为本发明中域名字符集。
图5为本发明中alexatop一百万域名字符长度统计图。
图6为本发明中召回率及误报率示意图。
图7为本发明的检测环境。
具体实施方式
下面结合附图和具体实施例对本发明作进一步详细的说明。本发明方法包括以下步骤:1)选取域名语料库,并针对域名语料库使用特征提取模块进行特征提取;2)针对域名语料库进行参数学习,得到各项特征的系统参数获得基于语料库的检测模型;3)通过数据包嗅探模块获取dns服务器的请求域名信息;4)根据请求域名信息使用特征提取模块进行特征提取,并且根据检测模型对域名进行检测。
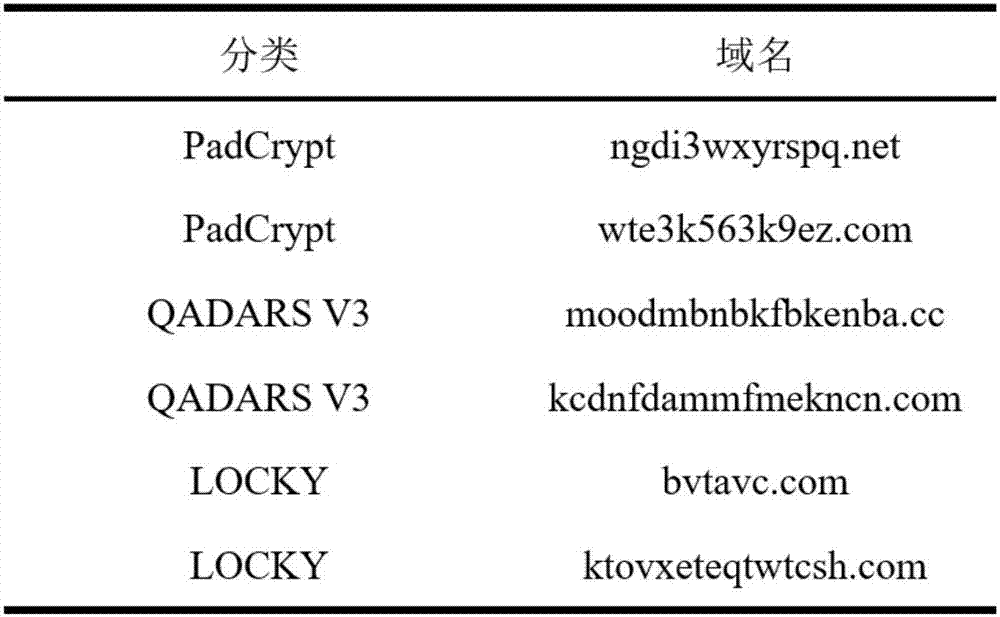
所述域名语料库选择alexatop一百万域名及padcrypt、qadars、locky域名生成算法生成域名。alexa是当前拥有url数量最庞大,排名信息发布最详尽的网站。在本发明中alexa全球top一百万域名被标记为正常域名。本发明中采用的是通过逆向工程获取的padcrypt、qadarsv3和locky域名生成算法生成的域名,这三类域名示例如图2所示,在本发明使用的数据集中标记为算法生成域名。
所述特征提取模块计算过程如下:
a、对域名按字符“.”进行分级,确定域名级数dlevel,对每级域名进行统计;
b、计算每级域名的长度length,即每级域名的字符个数;
c、计算每级域名中数字占比numratio,即每级域名中数字字符(0-9)所占的比例;
d、计算每级域名的字符混淆度,域名中所含字符集为a={a1,a2,...,an},
e、计算每级域名的2-gram至n-gram马尔科夫转移概率,设域名为b=b1b2...bn,n-gram(k)表示相差k距离的两字符组成的序列其先验概率为pn-gram(k),则域名k阶马尔科夫转移概率markov(domain):
f、得到特征向量。
所述步骤a中针对alexatop一百万域名级数进行了统计,结果如图3所示。根据统计结果域名一般不会超过四级,由此确定了需要提取特征的域名级数dlevel=4。
所述步骤e中先验概率通过alexatop一百万域名以及英英字典计算获得。首先对alexatop一百万域名以及英英字典进行切词形成wrod,针对每个word按图4所示字符集统计其n-gram概率,形成n-gram概率转移矩阵。
所述步骤e,根据alexatop一百万域名字符长度统计结果,如图5所示,绝大多数域名的一级长度不会超过20,即n-gram级数需求一般不会超过20阶,因此确定n-gram上限为20阶,即只需计算域名2-20阶马尔科夫转移概率。
所述检测模型采用svm模型。本发明基于svm模型在域名语料库中进行了检测实验,根据交叉检验方法获得了检测模型的召回率和误报率,如图6所示。实验环境中,不同组别的实验其实验数据集中加入算法生成域名数目不同,占比从10%到50%不等。从实验结果分析得到,加入的算法生成域名数目对实验结果的影响是较小的,实验召回率均在95%以上,误报率均小于2%。
所述系统在spark平台上进行了真实环境的检测,如图7所示。发明中所使用的检测域名采集于某校园dns服务器,通过镜像的方式对数据进行采集和还原。将还原后的数据存放于数据存储平台上,并在数据处理平台上进行数据处理和相关操作。采集服务器共两台。数据存储平台共计17台服务器,数据存放于hdfs中。处理平台共计15台服务器,已搭建完成spark平台。本发明使用spark平台对测试集中的域名进行处理和分析。
本发明方法提取了域名的字符混淆度、马尔科夫字符状态转移概率等域名统计与分布特征,采用svm算法对域名进行识别,并最终实现了对算法生成域名的检测。检测实验结果表明,该方法检测精确度达到95%以上,且具有较好的通用性。
- 还没有人留言评论。精彩留言会获得点赞!