一种基于AP聚类算法的空间调制系统盲检测方法与流程
本发明属于通信抗干扰技术领域,涉及空间调制(spatialmodulation,sm)技术,盲检测技术(blinddetection),多输入多输出(multipleinputmultipleoutput,mimo)技术,以及ap聚类(affinitypropagation,ap)算法。
背景技术:
空间调制技术作为一种新的mimo技术近来受到广泛关注。在空间调制系统中,每个时隙仅激活一根发送天线传送数据,从而避免了信道间的干扰,对天线间的同步性要求也有所降低,并且在接收端,即使接收天线数小于发送天线数时也可以进行检测。
对于空间调制系统的检测也是一个热门问题,在早期的工作中,有三种典型的空间调制检测算法:最大似然检测,匹配滤波检测和球形译码检测。而这些检测均假设已知完美信道状态信息,而完美信道状态信息在实际中是很难获取的。因此,近年来陆续有人提出了无需知道信道状态信息的盲检测算法,而大部分的盲检测算法均需要发送一些训练符号序列,从而导致资源的浪费。于是近来又有人提出了一种基于k均值聚类算法的盲检测算法,无需知道信道状态信息,也无需用到训练符号,但其仍需事先知道聚类的数目。
技术实现要素:
本发明的目的,就是针对空间调制系统提出一种基于ap聚类算法的盲检测算法。
本发明的技术方案如下:
假设有nt根发送天线,nr根接收天线,调制阶数为m,x=[x1,...,xl]是长度为l的发送信号序列,即取l个时隙的发送信号。xsm是发送信号集合,
ap算法通过观测值之间的相似度进行分类,并且不需知道聚类的数目。相似度矩阵s的元素s(i,j)表示第i个观测值和第j个观测值间的相似度,其对角元素s(i,i)表示参考度,其值越大,则第i个观测值是聚类中心的概率越大。s(i,j)可表示为:
聚类数目受参考度影响很大,所以合适的参考度设置可以提高聚类效果,因此可以首先通过如下方式获得一个集合l:
1)假设l={iyi被选为聚类中心}是被选为聚类中心的观测值的索引的集合,令
2)计算每个观察值之间的欧氏距离矩阵,以得到一个矩阵
3)令
4)将
5)重复步骤4)直至集合l的基数为k。
越晚放入集合的元素,它和之前已被选入集合的元素在同一个类中的可能性越大,所以参考度可设置为:
其中z是i在集合l中的索引,p取矩阵s中除对角元外的所有元素的均值。
此外,定义吸引度矩阵和归属度矩阵如下:
吸引度矩阵r:其元素r(i,j)表示第j个观测值适合作为第i个观测值的聚类中心的程度,可表示为:
其中下标t表示在迭代过程中第t步的值。
归属度矩阵a:其元素a(i,j)表示第i个观测值选择第j个观测值作为它的聚类中心的程度,可表示为:
其中下标t表示在迭代过程中第t步的值。
为了避免震荡,在迭代更新吸引度矩阵和归属度矩阵时引入阻尼系数λ,公式如下:
rt+1(i,j)=(1-λ)rt+1(i,j)+λrt(i,j)(公式5)
at+1(i,j)=(1-λ)at+1(i,j)+λat(i,j)(公式6)
其中0<λ<1,阻尼系数越小,迭代次数越少,但会变得难以收敛,本发明取λ=0.7。
可知吸引度r(i,j)和归属度a(i,j)越高,第j个观测值作为聚类中心的可能性越高。
ap算法把所有观测值当做潜在的聚类中心,通过迭代更新每一个观测值的吸引度和归属度,直到产生m个高质量的聚类中心,并将其余观测值分到相应的类中。
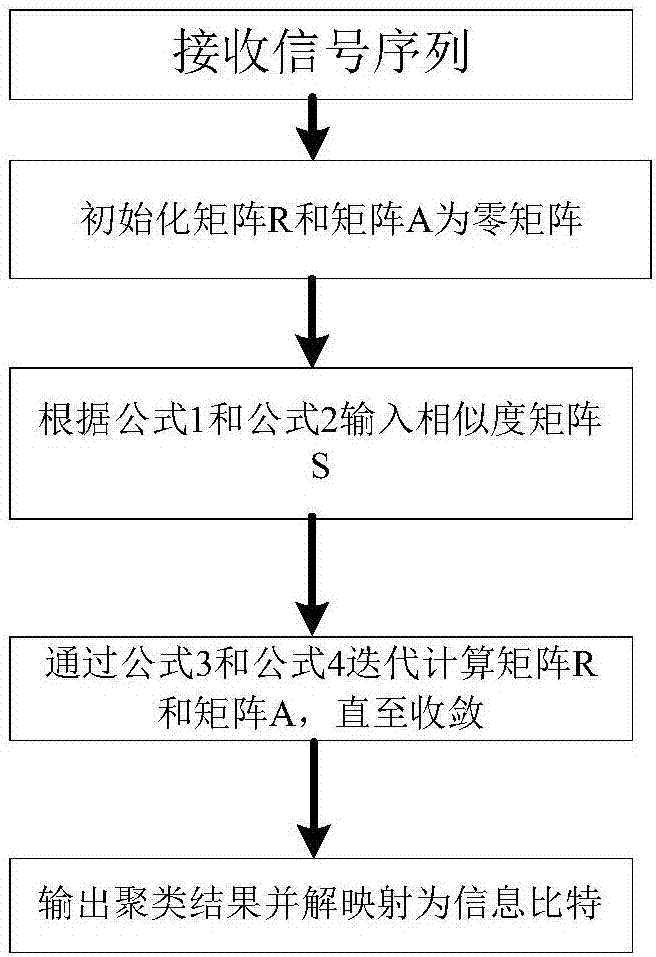
为了实现上述目的,本发明的基于ap聚类算法的空间调制系统检测方法主要包括如下步骤:
1、初始化吸引度矩阵r和归属度矩阵a为零矩阵;
2、根据公式1和公式2输入相似度矩阵s;
3、通过公式3至公式6迭代计算矩阵r和矩阵a,直至它们收敛;
4、输出
5、将聚类结果解映射为比特信息。
本发明的有益效果在于,首先通过最大化最小欧式距离的思想,获得一个更为合适的参考度,从而可避免可能发生的错误平台问题,并在可接受的算法复杂度范围内获得更高的检测性能。
附图说明
图1为空间调制盲检测系统框图;
图2为基于ap聚类算法的盲检测算法流程图;
图3为ap算法迭代收敛过程示意图;
图4为不同检测算法性能比较(4发4收,l=80,bpsk);
图5为不同检测算法性能比较(4发4收,l=800,bpsk);其中,kmc(p)表示用不同的初始聚类中心运行p次,ap(n)表示将所有参考度设为相同的值,ap(y)表示用公式2设置参考度。
具体实施方式
下面将结合附图,给出本发明的具体实施例。需要说明的是:实施例中的参数并不影响本发明的一般性。
下面对该发明提出的一种基于ap聚类算法的盲检测算法进行说明。考虑一个nt×nr的空间调制系统,其中nt是发射天线数,nr是接收天线数,x=[x1,...,xl]是长度为l的发送信号序列,即取l个时隙的发送信号。xsm是发送信号集合,
步骤1:初始化吸引度矩阵r和归属度矩阵a为零矩阵;
步骤2:根据公式1和公式2输入相似度矩阵s,其中获得集合l的具体步骤如下:
a)假设l={iyi被选为聚类中心}是被选为聚类中心的观测值的索引的集合,令
b)计算每个观察值之间的欧氏距离矩阵,以得到一个矩阵
c)令
d)将
e)重复步骤4)直至集合l的基数为k。
步骤3:通过公式3至公式6迭代计算矩阵r和矩阵a,直至它们收敛;
步骤4:输出
步骤5将聚类结果解映射为比特信息。
上述ap聚类检测器的复杂度为ο(l2niter+2l2),传统k均值聚类检测器的复杂度为ο(plntmniter),niter为迭代次数。和传统k均值检测器相比,本发明提出的基于ap聚类的盲检测算法可以获得更好的性能,且具有较低的算法复杂度。
- 还没有人留言评论。精彩留言会获得点赞!