一种基于资源受限条件下的自适应DTN路由算法的制作方法
一、技术领域
本发明涉及容迟网络技术领域,尤其涉及一种基于资源受限条件下的自适应dtn路由算法。
二、
背景技术:
随着信息技术的发展,internet网络的出现极大改变了人类社会的生产生活方式。internet网络节点始终保持着端到端连接路径,且丢包率小、传输时延低。这类网络是以tcp/ip协议簇作为基础的,适用于大部分的网络环境。然而,随着信息技术的不断深入发展,常常需要在一些极端环境中部署网络。由此出现了众多不同于传统网络特征的场景。这些网络具有链接频繁中断、传输时延高、丢包率高、上行和下行数据率不对称等特点。例如,在卫星通信中,由于经济和技术方面的原因导致网络节点数量较少,且卫星时常移动,导致卫星通信网络连接时常中断;海洋、湖泊、山川等极端环境下为了节约节点能量消耗,在节点不工作时,采取待机或者关闭措施,造成网络连接中断。
具有上述连接时常中断、传输时延高等特点的网络称为容迟容断网络(delaytolerantnetwork,dtn)。这类网络特点使得传统的基于tpc/ip协议簇的路由算法不再适用。dtn网络传递信息采用的是“存储-携带-转发”的模式。路由算法作为信息传递的关键,随着dtn网络应用场景越来越多,各类dtn路由算法被相继提出。
基于网络拓扑是否先验,可将路由算法分为确定性路由算法和随机路由算法。确定性路由假设网络拓扑在进行数据传输之前就已经确定。随机路由算法适用于网络拓扑未知的场景。此类算法通常基于网络动态拓扑传递数据,并且记录各节点参量选择下一跳。
根据路由算法制定路由规则依赖的指标不同,可以将dtn路由算法分为基于社交属性的路由算法和非基于社交属性的路由算法。基于社交属性路由算法又可分为基于积极社交属性和基于消极社交属性。积极社交属性主要指网络的中心度、相关度、度分布等指标,消极社交属性主要指网络中节点“自私”程度,即有些节点可能由于能耗、隐私等原因不愿作为中继节点传输数据。典型的基于积极社交属性的路由算法包括multi-simbet,bubblerap,levelrouting等算法;基于消极社交属性的路由算法包括tit-for-tat,smart,mobicent等算法。
根据算法优先于哪个服务指标又可将路由算法分为flood-based,historyandencounter-based,socialbehavior-based,knowledge-based等。其中flood-based算法以泛洪为基础思想,传输成功率较高,典型的flood-based算法有epidemicrouting,sprayandwait,rapid,multi-simbet算法等;historyandencounter-based算法以相遇概率推算为基础思想,性能开销较小,典型的historyandencounter-based算法有prophet,singlerecent,sprayandfocus算法等;socialbehavior-based算法类似于前文提到的基于社交属性的算法,主要通过计算节点社交属性选择下一跳,成功率较高,典型的socialbehavior-based算法有bubble-rap,simbet等算法;knowledge-based算法则与前文提到的确定性路由算法相似,适用于网络拓扑先验的场景。
根据算法路由策略可以将dtn路由算法分为泛洪路由算法和转发路由算法。泛洪路由算法允许网络中包含多个信息副本以便提高网络传输成功率,适用于网络资源较为丰富的场景,典型的泛洪路由算法有epidemic,sprayandwait,sprayandfocus,multi-simbet等;转发路由算法则只允许同一时刻网络中最多存在信息的一个副本,此类算法成功率不如泛洪路由算法,但适用于资源紧缺的场景。典型的转发路由算法有singlerecent,directtransmission,onehopencounterprediction算法。
三、
技术实现要素:
本发明的目的是,针对上述各类典型dtn路由算法存在的优缺点,提出一种基于资源受限条件下的自适应dtn路由算法。该算法能够根据网络实时资源负载消耗情况选择合适的典型dtn路由算法。旨在提高网络吞吐量,达到提高传输成功率的同时降低平均时延的效果。
本发明的技术方案是:一种基于资源受限条件下的自适应dtn(容迟容断网络)路由算法即基于节点负载的自适应路由算法,合理利用泛洪路由算法传输成功率高、转发路由算法资源消耗低的优点,根据节点当前负载选择适用的路由算法。算法分为两个阶段:训练阶段和传输阶段。
1)训练阶段,主要任务为根据所选择的路由算法确定节点负载和网络负载计算参数,并确定各个算法适用的负载区间;
2)传输阶段,主要任务为对未过期的数据根据训练阶段定义的节点负载计算公式计算得到节点负载,判断节点负载所在的负载区间及负载区间对应的路由算法。然后根据这个路由算法进行路由。同时根据这一跳路由情况更新训练阶段定义的节点负载计算所需参数,以及对应负载区间的更新。
通过对路由算法的灵活选择,达到提高网络传输成功率和降低资源消耗的目的。
如附图1所示,训练阶段1)过程具体为:
步骤1.1:根据实际应用场景选取几个典型的dtn路由算法,需要包含转发路由算法和泛洪路由算法;
步骤1.2:根据网络情况按照选取的典型路由算法分别进行路由传输,并统计这段时间算法的传输成功率、网络平均时延、网络平均路由资源消耗、性能资源消耗比随着时间的变化情况。同时统计路由传输过程中每个节点接收到的消息总数按照消息来源上次与当前节点接触时间差的分布情况;
步骤1.3:定义并计算每个节点负载情况以及网络平均负载;
步骤1.4:根据步骤1.3计算得到的负载情况确定各个典型路由算法适用的负载区间;
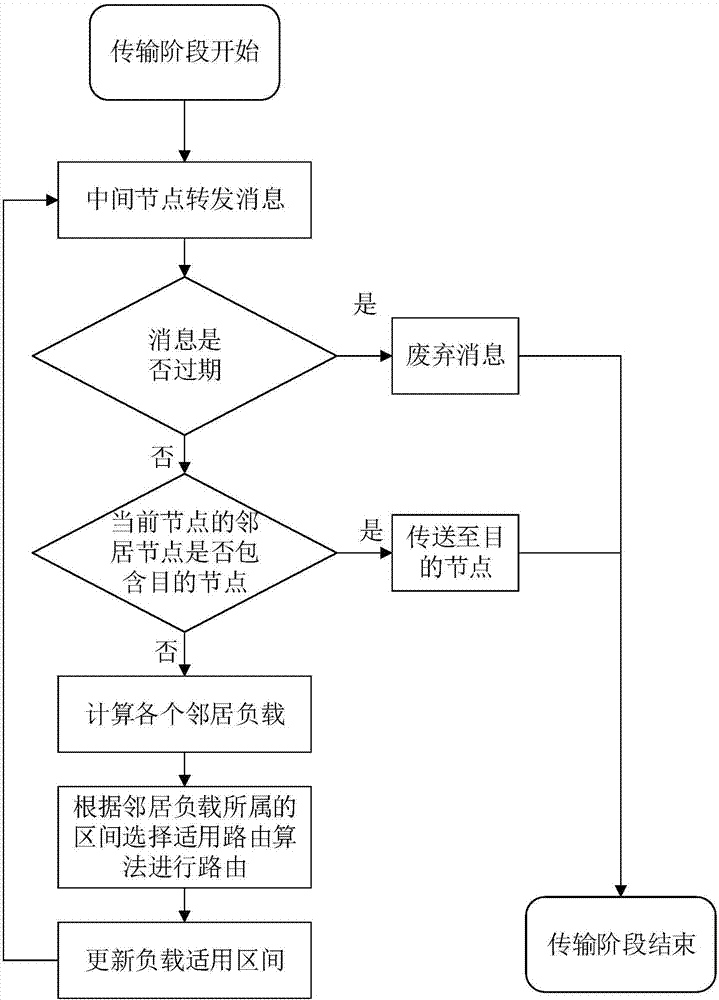
如附图2所示,传输阶段2)具体为:
步骤2.1:当前节点向目的节点发送消息;
步骤2.2:判断消息是否已经过期,如果过期则直接废弃消息;
步骤2.3:查看当前节点所有邻居,首先验证邻居节点中是否有目的节点,如果有,则直接将消息传送到目的节点;
步骤2.4:对于当前节点的每个邻居,根据步骤1.3定义的公式计算每个邻居的节点负载情况;
步骤2.5:判断各个邻居节点适用于哪种典型路由算法,并用此算法进行路由;
步骤2.6:更新步骤1.3节点负载计算公式中的参数以及步骤1.4各个路由算法使用的负载区间;返回步骤2.1。
以上步骤只表述一个数据在网络中的传输情况。多个数据的情况类似。
网络传输成功率计算如下:
其中,n代表网络中总传输数据数量,当信息mk最终成功传输时dk=1,否则dk=0。
网络平均时延计算如下:
其中,n代表网络中成功传输的消息数量,receivetimek以及createtimek代表消息k产生和最终成功传输的时间。
网络传输资源消耗计算如下:
其中,n代表网络传输过程中产生的所有消息数量,ck指消息mk在网络中副本个数。网络平均路由资源消耗代表每传递一份消息,需要伴随多少消息副本散布在网络中。
性能消耗比计算如下:
其中,deliveryratio指网络传输成功率;averageoverhead指网络传输资源消耗。
路由传输过程中每个节点接收到的消息总数按照消息来源上次与当前节点接触时间差的分布情况具体计算方式如下:
对于每个邻居节点,当要接收当前节点传来的消息时,记录下这个邻居节点与当前节点上次相遇时间与当前时间的差值。最后统计整个网络传输过程中,消息接收过程中接收消息总量随着相邻节点上次相遇时间差的分布情况。进行这项统计是为了后续计算节点负载的权重。
节点负载情况计算如下:
其中,
衰减因子q计算如下:
按照每个节点接收到的消息总数按照消息来源上次与当前节点接触时间差的分布情况能够得到如下几个公式:
z=k(t-tij)+b
z=lny
其中y指接收消息数量,t指当前时间,tij指节点i与节点j上次相遇时间。k与b是按照线性回归方程计算得到的。
整理上面两个公式可以得到如下关系:
q=ek
网络负载按照如下公式进行计算:
其中,n是网络中节点数量,
在路由传输过程中,每过一个时间间隔,按照上式计算网络负载。
各个典型算法适用的负载区间计算如下:
步骤1:根据网络负载随时间分布以及传输成功率随时间分布的数据,得到各个路由算法传输成功率差分随网络负载变化的数据;
步骤2:对于每一个网络负载,根据步骤1得到的数据,存在一个算法在这个负载下对成功率增长变化最大。自适应算法在这个负载下将选择此算法进行路由;
步骤3:总结步骤2得到的每个网络负载对应选择的路由算法,得到每个路由算法适用的负载区间。
传输阶段更新权重大小主要是重新统计接收消息数量随着相遇时间差分布情况,同时更新衰减因子q进而更新网络权重,最后达到更新算法适用区间的目的。
本发明的有益效果,本发明自适应算法能够通过少量的训练自适应的根据网络当前负载情况合理选择路由算法进行数据传输。能够根据当前网络环境选择成功率最高的路由算法进行路由,同时避免网络由于过度泛洪而发生拥塞。进而降低网络资源消耗。
四、附图说明
图1是训练阶段算法流程图
图2是传输阶段算法流程图
图3是自适应算法和典型路由算法传输成功率对比
图4是自适应算法和典型路由算法平均路由资源消耗对比
图5是路由传输过程中每个节点接收到的消息总数按照消息来源上次与当前节点接触时间差的分布情况。
图6是训练阶段结束各算法适用区间分布情况。
五、具体实施方式
下面通过具体实施方式结合附图对本发明作进一步详细说明。
首先,本实例是在mit移动用户数据集下选取epidemic、multi-simbet、sprayandwait、singlerecent、directtransmission五个算法作为典型算法进行仿真。其中,mit移动用户数据集包含94个移动用户。这94个用户中,75人为mit数字实验室的学生和工作人员,其余用户为mitsloanbusiness实验室学生。组成数据集的包括这94个用户在2004年9月到2005年3月期间的电话,短信,位置等信息。此数据集符合dtn网络节点动态移动、网络连接断开频繁的特性;在以上五个典型路由算法中,epidemic、multi-simbet、sprayandwait是泛洪路由算法,singlerecent、directtransmission是转发路由算法。
其次,训练阶段测试各个算法性能指标及消息总数分布情况并计算负载区间。图3和图4表明上面五个路由算法进行路由传输并统计传输成功率、平均路由资源消耗。图5表明路由传输过程中每个节点接收到的消息总数按照消息来源上次与当前节点接触时间差的分布情况。根据图5进行线性回归得到衰减因子q。图6给出各个算法根据衰减因子q计算的节点负载对成功率的增加情况。由图6得到epidemic算法适用的负载区间是[0,0.37],multi-simbet算法适用区间是[0.37,0.62],sprayandwait算法适用的负载区间是[0.62,0.75]。
接着进入传输阶段。对于任意一个节点及其邻居,按照如下流程进行路由:
步骤1:如果邻居节点就是目的节点,则直接将消息传送到邻居节点,路由结束;
步骤2:如果此消息已经过期,则直接废弃,路由结束;
步骤3:如果邻居节点负载大于0.75,则使用singlerecent算法进行路由,转到步骤7;
步骤4:如果邻居节点负载小于0.75大于0.62,则使用sprayandwait算法进行路由,转到步骤7;
步骤5:如果邻居节点负载小于0.62大于0.37,则使用multi-simbet算法进行路由,转到步骤7;
步骤6:如果邻居节点负载小于0.37则使用epidemic算法进行路由;
步骤7:确定路由算法之后,更新图5和图6以便进行下一跳路由,转到步骤1。
- 还没有人留言评论。精彩留言会获得点赞!