在位置社交网络中基于时间分布相对熵的好友推荐方法与流程
本发明属于无线网络技术领域,涉及在线社交网络的好友推荐方法,可应用于基于位置的在线社交网络服务。
背景技术:
基于位置的社交网络帮助用户在线分享他们的实时位置以便于用户可以发现感兴趣的位置并结交朋友。例如,用户可以通过好友分享的位置发现自己感兴趣的地点,或者通过查找与自己分享相似地点的用户来结交新的好友。此外,随着智能手机的普及,其内置的gps模块可以更加精确的探测用户的位置,使得用户可以更加便利的分享各自的位置。因此,这种签到服务吸引了越来越多的用户。如何使用大量的签到信息为用户进行好友推荐需要得到重视。
推荐系统在社交网络和电子商务网站中扮演了重要的角色,在电子商务网站中,现有的推荐系统通常使用用户的购买记录来分析用户的偏好,正如电子商务网站的购买记录,用户在基于位置的社交网络中的签到历史也包含了大量的关于用户偏好的信息。
在使用用户的签到信息进行好友推荐时,由于用户通常只会在数据库中的一小部分地点进行签到行为,因此进行好友推荐的可用数据较为稀疏。为了缓解数据稀疏的问题,现有方案分为如下几种:根据签到地点的密度进行分类,将一些地理位置较为接近的签到地点看作同一个签到地点;使用用户好友的签到数据填充到用户的签到数据中。但是,地理位置接近的地点可能代表了用户不同的兴趣爱好,同样,好友的爱好并不能完全代替用户自身的兴趣爱好,这两种行为都在一定程度上降低了好友推荐的精度。
在考虑时间信息的推荐系统方面,现有系统多用在电子商务网站与电影推荐网站,通过分析用户长期的购买记录与电影的观看记录分析用户的偏好来进行推荐。相比于长期的趋势,用户的签到行为在一天的具体时间可以提供更多反映用户偏好的信息。而在现有社交网络推荐系统中,只通过分析签到地点的时间属性对签到地点进行了分类,并未对用户签到行为的时间分布进行分析来进行好友推荐,因此推荐的准确率不够理想。
技术实现要素:
本发明的目的在于针对上述已有技术的不足,提出一种在位置社交网络中基于时间分布相对熵的好友推荐方法,以提高推荐的准确率。
本发明的技术思路是:通过将拥有相似语义信息的地点归为一类,解决推荐系统中可用数据稀疏的问题,使用词频-逆文档频率平衡热门地点与用户自身的兴趣,并选出用户最感兴趣的地点类别,同时通过计算用户间签到行为随时间分布的相对熵,综合考虑用户感兴趣的地点类别和用户间的签到分布相对熵,实现更加准确的好友推荐。其实现方案包括如下:
(1)建立一个由用户、定位设施和社交网络服务器构成的通信系统,
(2)用户将位置的经纬度与当前的时间信息发送给社交网络服务器,生成签到信息;
(3)社交网络服务器对存储的签到信息进行预处理:
(3a)针对签到信息中的经纬度查找服务器的位置语义数据库,获取与签到地点对应的语义信息,再将每个用户的签到信息按其签到地点的语义信息分类统计签到次数;
(3b)针对签到信息中的时间信息,在步骤(3a)的基础上,统计每个用户在每个地点类别下的签到行为随时间的分布;
(4)根据用户在各地点类别下签到行为随时间的分布,计算两个用户在相同地点类别下签到分布的相对熵d(p||q),其中p和q分别为两个不同用户在相同地点类别的签到次数随时间的概率分布;
(5)根据用户u在各地点类别下的签到次数,分别计算用户u对于地点类别c的词频值tu,c和地点类别c的逆文档频率值ic,得到社交网络服务器计算用户u对于每个地点类别c的词频-逆文档频率分值f:
f=tu,c×ic
(6)根据用户u对于每个地点类别c的词频-逆文档频率分值f,提取该用户u最感兴趣的地点类别:
(6a)对f中的逆文档频率值ic作幂运算,得到新的词频-逆文档频率分值f*=tu,c×icα,其中icα为逆文档频率值ic的α次幂;
(6b)选择f*最高的m个地点类别作为用户u最感兴趣的地点类别,其中m和α由实验确定;
(7)社交网络服务器根据用户最感兴趣的地点类别,选取所有其他用户中在这些地点类别下相对熵较小的n个用户作为推荐结果发送给请求推荐的用户,其中n的数量根据请求推荐的用户所请求的好友推荐数量确定。
本发明与现有技术相比具有如下优点:
1)本发明由于使用了签到地点的语义信息进行分类,在缓解推荐可用数据稀疏性的同时,保持了较高的推荐精度。
2)本发明由于使用了词频-逆文档频率模型提取用户感兴趣的地点类别,平衡了热门签到地点与用户自身的偏好。
3)本发明由于对用户的签到行为随时间的分布进行了分析,并以用户间签到随时间分布的相对熵为好友推荐的主要依据,充分利用了签到信息的地理信息与时间信息,从而保证了较高的推荐准确性。
附图说明
图1是本发明使用的通信系统框架图;
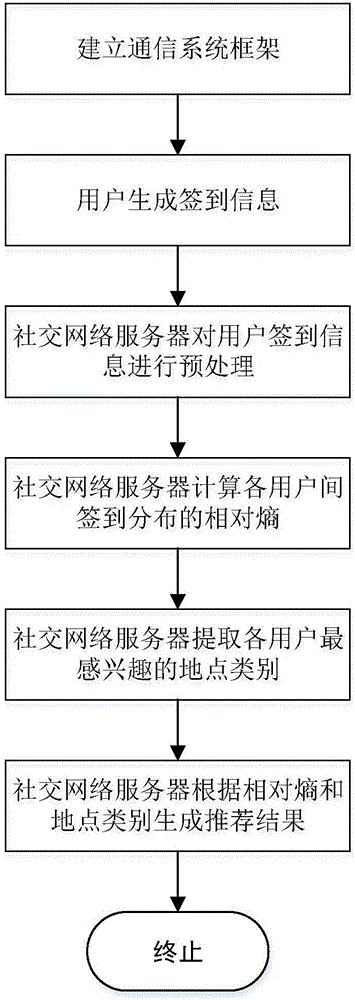
图2是本发明的实现流程图;
图3是本发明所用推荐方案与未考虑时间因素的推荐方案的推荐准确率对比图;
图4是本发明所用推荐方案与未考虑时间因素的推荐方案的推荐召回率对比图。
具体实施方案
本发明的核心思想是在基于位置的社交网络场景下,通过分析用户签到地点的语义信息将签到数据进行分类以缓解可用数据较为稀疏的问题,并综合分析了签到地点的热度,用户个人的偏好以及用户签到行为随时间的分布规律用来对用户进行好友推荐,提高推荐的准确度。
参照图2,本发明实现步骤如下:
步骤1,建立通信系统框架。
参照图1,本步骤建立的通信系统包括:用户、定位设施、社交网络服务器,其中用户与定位设施和社交网络服务器均通过移动蜂窝网或wifi进行双向无线连接;
所述用户,包含应用模块、数据库模块和gps模块三个功能模块;应用模块主要用于生成并发送签到信息给社交网络服务器;gps模块主要用于向定位设施查询位置信息并向应用模块提供用户的地理位置信息;数据库模块主要用于存储和管理用户签到和好友信息;
所述定位设施,主要包含gps模块,该gps模块主要用于对用户的位置查询进行响应并返回用户的地理位置信息;
所述社交网络服务器,包含应用模块和数据库模块两个功能模块;应用模块主要用于对用户的签到信息进行分析整理并为用户的好友推荐请求返回推荐结果,数据库模块主要用于存储用户的签到数据和签到地点的语义信息。
步骤2,采集签到信息。
用户借助定位设施获得自身所在的地理位置信息,并将此地理位置信息与当时的时间信息发送给社交网络服务器生成签到信息。
步骤3,社交网络服务器对存储的大量签到信息进行预处理。
(3a)针对签到信息中的地理位置信息,查找服务器的位置语义数据库获取与签到地点对应的语义信息,然后将每个用户的签到信息按其签到地点的语义信息分类统计签到次数;
(3b)针对签到信息中的时间信息,将一天时间平均分成24个区间,统计用户在地点类别c上每一时间区间上的签到次数vc(i)和用户在该地点类别总的签到次数sc,得到用户在地点类别c每一时间区间的签到频率pc(i)=vc(i)/sc,i=1,2,...,24,分别对应所划分的24个时间区间,由此得到用户在某个地点类别签到行为随时间的分布。
步骤4,根据用户在各地点类别下签到行为随时间的分布,计算两个用户在某地点类别下签到分布的相对熵d(p||q):
其中,pc为用户up在地点类别c下签到数据随时间的概率分布,qc为另一用户uq在地点类别c下签到数据随时间的概率分布;i=1,2,...,24,其分别对应步骤(3b)计算用户签到随时间的概率分布时所划分的24个时间区间。
步骤5,社交网络服务器计算每个用户u对于每个地点类别c的词频-逆文档频率分值f,并在此基础上提取用户最感兴趣的地点类别。
(5a)社交网络服务器计算用户u在地点类别c下签到信息的词频分值tu,c:
其中|cuc|表示用户u在地点类别c下签到的数量,|cu|表示用户u的签到总次数;
(5b)社交网络服务器计算每个地点类别c的逆文档频率分值ic:
其中,|u|表示服务器中所有用户的数量,|uc|表示曾在地点类别c签到的用户的数量;
(5c)社交网络服务器将用户u在地点类别c下的词频分值tu,c与地点类别c的逆文档频率分值ic相乘,得到其在该地点类别下的词频-逆文档频率分值f:
f=tu,c×ic。
步骤6,根据用户u对于每个地点类别c的词频-逆文档频率分值f,提取该用户u最感兴趣的地点类别。
(6a)对f中的逆文档频率值ic作幂运算,得到新的词频-逆文档频率分值f*=tu,c×icα,其中icα为逆文档频率值ic的α次幂;
(6b)选择f*最高的m个地点类别作为用户u最感兴趣的地点类别,其中m和α由实验确定。
步骤7,社交网络服务器根据用户最感兴趣的地点类别,选取所有其他用户中在这些地点类别下相对熵较小的n个用户作为推荐结果发送给请求推荐的用户。
(7a)将用户最感兴趣的地点类别下的用户按相对熵升序排列;
(7b)选取用户最感兴趣的各地点类别下的前1个用户,生成候选队列;
(7c)判断在这些候选队列中同时出现的用户数量:
如果有n个用户同时出现在这些选中的列表中,则将这些用户作为好友推荐的结果;
如果没有n个用户同时出现在这些选中的列表中,则选取用户最感兴趣的各地点类别下的前2个用户,生成新的候选队列,重新判断,直到有n个用户同时出现在这些列表中,其中n的数量根据请求推荐的用户所请求的好友推荐数量确定。
本发明的效果可通过以下仿真实验进一步说明:
1.实验条件设置
条件1,在gowalla获得签到数据集,选取其中纽约市的签到数据组成数据集合,并选取其中签到数量大于100次的用户的58715条签到数据作为实验的源数据。
条件2,在intel(r)corei3-2310mcpu(2.10ghz)处理器,4.00gb内存,windows10家庭版32位操作系统的计算机上测试实验的结果。
2.实验内容与结果
实验1:本发明好友推荐方案与传统好友推荐方案推荐准确率对比实验。
将条件1中实验数据平均分为3份,依次取其中一份作为测试集,其余两份作训练集,首先在训练集上运行本发明的推荐方案,方案提取用户最感兴趣的地点类别数量m为2,得到推荐准确率最高的逆文档频率值ic的指数α,将α用于在测试集上提取用户感兴趣的地点类别,生成好友推荐结果;
在实验数据集上运行未考虑时间因素的传统好友推荐方案,得到相应的好友列表和推荐结果,最后对两种推荐方法的准确率进行计算,计算公式如下:
其中r(u)表示真实数据集中用户u的好友列表,t(u)表示好友推荐系统返回的用户u的推荐结果,u表示数据集中所有的用户;
比较本发明推荐方案与传统好友推荐方案推荐结果的准确率随推荐好友数量增加的变化情况,结果如图3所示,其中本发明的推荐准确率取三次交叉验证的平均值。
从图3可见,本发明所用的好友推荐方案的准确率明显高于未考虑时间因素的传统的好友推荐方案,推荐准确率平均提升约9.1%。
实验2:本发明好友推荐方案与传统好友推荐方案推荐召回率对比实验。
将条件1中实验数据平均分为3份,依次取其中一份作为测试集,其余两份作训练集,首先在训练集上运行本发明的推荐方案,方案提取用户最感兴趣的地点类别数量m为2,得到推荐准确率最高的逆文档频率值ic的指数α,将α用于在测试集上提取用户感兴趣的地点类别,生成好友推荐结果;随后在实验数据集上运行未考虑时间因素的传统好友推荐方案得到相应的好友列表和推荐结果,最后对两种推荐方法的召回率进行计算,计算公式如下:
其中r(u)表示真实数据集中用户u的好友列表,t(u)表示好友推荐系统返回的用户u的推荐结果,u表示数据集中所有的用户。
比较本发明推荐方案与传统好友推荐方案推荐结果的召回率随推荐好友数量增加的变化情况,结果如图4所示,其中本发明的推荐召回率取三次交叉验证的平均值。
从图4可见,本发明所用的方案召回率明显高于未考虑时间的好友推荐方案,推荐召回率平均提升约19.0%。
综上所述,本发明在推荐结果的准确率与召回率方面均优于传统的好友推荐系统,可以为基于位置社交网络的用户提供质量更高的好友推荐服务。
- 还没有人留言评论。精彩留言会获得点赞!