基于k均值的监控视频热度云存储方法与流程
本发明涉及视频监控技术领域,具体涉及一种监控视频的存储方法。
背景技术:
随着数字安防技术的普及,监控技术逐渐往高清化、网络化发展,随之而来的是海量的数据存储问题。海量数据必须拥有能够进行可靠、可保证效率且拥有快速读写以及响应能力的存储。传统的视频监控存储主要分为三个阶段,分别为早期的硬盘录像存储设备、直接连接存储(das)和基于网络的网络附加存储(nas)。为了降低视频监控系统存储设备的成本以及解决大容量存储等问题,构建了hadoop分布式云存储集群,其构架如图1所示。目前云存储技术发展迅猛,比较知名的有亚马逊云存储、谷歌云存储、ibm、百度云、华为网盘等。然而通用化的hadoop平台对有如下一些缺点:
1.无法最大化发挥平台智能化处理性能。视频点播回放热度不一样,用户一般只选择高热度视频进行智能化处理,如视频摘要、全景融合,而视频智能化处理对计算机节点性能要求较高,高热度视频存储在低性能节点会降低智能化分析速度。
2.通用视频云存储架构浪费了存储空间。监控视频绝大部分都是冗余数据,且视频存储时效为一个月。hadoop分布式存储集群备份数固定,对于不同热度的监控视频无差异存储,浪费了存储空间,造成设备利用率低。
3.通用的视频云存储架构对带宽要求高。针对平安城市监控特点,摄像头为几万路、甚至几十万路,分布于城市的各个角落,所有视频流汇聚到一个集群,对网络带宽造成极大压力,甚至会出现网络拥堵,以至于丢失视频数据包。
技术实现要素:
本发明的目的在于通过对基于hadoop的视频存储架构分析,提出一种面向智能化的双hadoop集群存储架构。算法基于k均值预测监控视频热度,并根据平安城市监控特点对视频备份数进行调整,从而可提高设备利用率,加快视频文件检索以及智能化分析速度。
本发明的技术方案如下:
一种基于k均值的监控视频热度云存储方法,其特征在于:根据经典的k-means聚类算法对网络上的视频资源进行视频热度分析,预测城市摄像头热度,并将热度较高的视频存储在性能节点高的集群,将热度较低的视频存储在性能节点低的集群中。
对于高热度监控视频的视频热度分析服务每天分析一次,并根据用户进入视频云存储系统的强度分布,重新发布视频热度索引库时间。
本发明提出了一种面向智能化的双hadoop集群存储架构,将视频监控中使用热度高的视频存放在高性能集群中,以加快视频检索速度和后期智能化处理;同时双hadoop集群针对不同热度的监控视频可以分别设置备份数,从而节省存储空间,提高设备利用率。
附图说明
图1是现有基于hadoop的视频存储架构图;
图2是本发明的hadoop存储架构图;
图3是本发明的k-means算法流程图。
具体实施方式
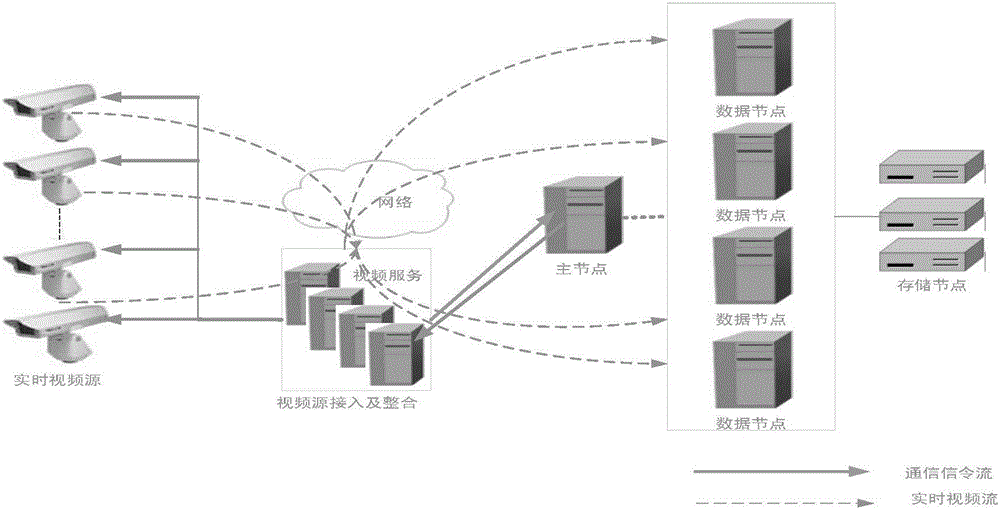
图1是现有的基于hadoop的视频存储架构图。本发明是基于已有的hadoop的视频存储思路,通过hadoop提供的api接口,实现将接收到的视频流文件从本地上传到hdfs中。此过程中,前端摄像机或者编码器源源不断地将视频流转发过来,然后在服务端采集汇聚(相当于流媒体服务或者nvr的视频采集服务),本地进行缓存打包数据,然后实时以流的形式将“缓冲区”与hdfs进行对接,之后通过流的方式将文件上传。
对于视频信息的存储策略,目前有多种,本发明以系统总响应时间最小化、提高设备使用率为目标,以监控视频热度为依据,提出了一种云存储子节点服务存储策略。该存储策略主要是考虑如下三个因素因素:视频使用热度,各节点服务器的处理性能,网络带宽;在视频点播回放行为中,会出现“80%的用户申请20%的视频资源”的现象,甚至在出现大片或热片的情况下出现“90%的用户申请10%的视频资源”的现象。因此存放使用率高的视频服务器肯定会收到比较多的用户请求,使得这些视频服务器的负载相对来说会比较重,造成负载不均衡,因此,优先将高使用率的视频存放到多个高性能的服务器节点上,而将低使用率的视频存放到性能较低的服务器节点上。同时,视频云存储是云计算的基础,高性能节点的集群对于后期视频智能化处理如视频摘要、以图搜图大大加快了其分析处理速度。本发明根据以上分析对现有架构进行改进,如图2所示。
图2所示的架构包含视频热度分析服务,视频查询服务,视频热度索引库,视频接入服务。通过视频热度分析服务预测平安城市摄像头热度,从而将热度较高的视频存储在性能节点高的集群,将热度较低的视频存储在性能节点低的集群中。对于高热度监控视频的预测视频热度分析服务每天分析一次。重新发布视频热度索引库时间,根据用户进入视频云存储系统的强度分布决定,每天凌晨是重分布的最佳时间,而凌晨2点和上午6点也是更新的较好时机。改进的视频存储架构技术的核心是对监控视频进行预测,判断重要性即视频热度。本发明从机器学习出发,根据已有的特征值采用k-means算法预测某一路视频的热度。
本发明基于机器学习中的聚类分析,将监控视频分为高热度与低热度视频。聚类分析又称群分析,它是研究(样品或指标)分类问题的一种统计分析方法。聚类是将数据分类到不同的类或者簇这样的一个过程,所以同一个簇中的对象有很大的相似性,而不同簇间的对象有很大的相异性。聚类分析能够从样本数据出发,自动进行分类。从实际应用的角度看,聚类分析是数据挖掘的主要任务之一。本发明采用最经典的k-means聚类算法,其也称为k-均值算法。它是将各个聚类子集中的所有数据样本的均值作为该聚类的代表点,算法主要思想是通过迭代过程从而把数据集划分为不同的类别,使得评价聚类性能的准则函数达到最优,从而使生成的每个聚类类间独立、类内紧凑。
聚类的输入是一组没有类别标注的数据,事先可以知道这些数据聚成几簇也可以不知道聚成几簇。通过分析这些数据,根据一定的聚类准则,合理划分记录集合,从而使相似的记录被划分到同一个簇中,不相似的数据划分到不同的簇中。假设给定的数据集x={xm|m=1,2,…,total},x中的样本用d个描述属性a1,a2,…,ad(维度)来表示,数据样本xi=(xi1,xi2,…,xid),xj=(xj1,xj2,…,xjd),其中,xi1,xi2,…,xid和xj1,xj2,…,xj3分别是样本xi和xj对应的d个描述属性a1,a2,…,ad的具体取值。样本xi和xj之间的相似度通常用它们之间的距离d(xi,xj)来表示,距离越小,样本xi和xj越相似,差异度越小;距离越大样本xi和xj越不相似,差异度越大。欧式距离公式如下:
k-means聚类算法使用误差平方和准则函数来评价聚类性能。给定数据集x,其中只包含描述属性,不包含类别属性。假设x包含k个聚类子集x1,x2,…,xk,各个聚类子集中的样本数量分别为n1,n2,…,nk,各个聚类子集的均值代表点(也称聚类中心)分别为m1,m2,…,mk。误差平方和准则函数公式为:
算法描述如下:
为中心向量c1,c2,…,ck初始时k个种子;
分组:将样本分配给距离其最近的中心向量,由这些样本构造不相交的聚类;
确定中心:用各个聚类的中心向量作为新的中心;
重复分组和确定中心的步骤,直至算法收敛。
本发明实施例的具体算法流程图如附图3所示,算法的具体过程如下:
1.从数据集{xn}n=1中任意选取k个赋给初始的聚类中心c1,c2,…,ck;
2.对数据集中的每个样本xi,计算其与各个聚类中心cj的欧式距离并获取其类别标号:
label(i)=argmin||xi-cj||,i=1,…,n,j=1,…,k;
3.按下式重新计算k个聚类中心:
重复步骤2和步骤3,直到达到最大迭代次数为止。
本实施例根据平安城市视频监控的特点选取了六个特征值,分别为近三天(前天、昨天、今天)的视频分别回放次数,区域重要性,摄像机属性,视频标记。视频近三天放问次数为分别记录所有摄像头当天的历史调阅总次数;区域重要性为根据用户具体业务需求进行划分,并且可根据需求变动改变区域重要性;摄像机属性为摄像机本身功能属性,摄像头有高清、标清、球机、枪机、夜市、红外之分,根据摄像机所具有的不同属性划分其重要程度;视频标记为从软件使用层面出发,针对具体业务,用户可标记感兴趣的某路视频。图表如下:
表1摄像头特征值
数据标准化(归一化)处理是数据挖掘的一项基础工作,不同评价指标往往具有不同的量纲和量纲单位,这样的情况会影响到数据分析的结果,为了消除指标之间的量纲影响,需要进行数据标准化处理,以解决数据指标之间的可比性。原始数据经过数据标准化处理后,各指标处于同一数量级,适合进行综合对比评价,因此需要对选取的六个特征值进行数据标准化,对原始数据(以列进行)进行线性变换,使结果值映射到[0-1]之间。以第一路的前天访问次数为例,转换如下:
其中max为表格样本数据列中的最大值,min为表格样本数据列的最小值。
- 还没有人留言评论。精彩留言会获得点赞!