一种加权投票聚类集成方法与流程
本发明涉及集成学习技术领域,特别涉及一种加权投票聚类集成方法。
背景技术:
集成学习一般是综合多个学习器的学习结果解决同一个问题,最终得出一个更为优化的结果。聚类集成是集成学习中的一个分支,它是为了解决无监督的聚类分析中可能因为样本的特殊数据分布与聚类假设不匹配,导致聚类结果不理想的问题。聚类集成的宗旨是合并某个数据集的多重单一聚类结果,将其转化成一个统一的、综合的聚类结果,最终使得集成后的聚类结果在聚类质量、鲁棒性等方面优于单一聚类算法的结果。近几年,聚类集成得到了很多学者的关注,其中研究的重点主要是关于怎样生成更好的聚类集体及怎样更好地集成聚类集体中的成员得到最终的聚类划分结果两个方面。
公开号为cn107169511a的专利《基于混合聚类集成选择策略的聚类集成方法》公开了一种基于混合聚类集成选择策略的聚类集成方法,步骤包括:输入测试数据集样本矩阵x;对数据集样本矩阵x进行聚类操作,生成基础聚类结果集合;将基础聚类结果集合转换到新特征空间,且基础聚类结果集合中的每一个聚类结果作为新特征空间的每一个特征;使用特征选择技术对特征进行聚类集成选择,得到聚类结果子集;对聚类结果子集使用赋权函数获得最终聚类结果子集;集成最终聚类结果子集,得到最终聚类结果。该发明将聚类集成选择问题转化为特征选择问题,具有创新性;从多角度生成基础聚类结果,更具多样性;利用特征选择算法进行优化,避免人为因素及冗余度问题;考虑了局部和全局权重,有机结合各聚类结果子集,提升聚类准确性。公开号为cn103995821a的专利《一种基于谱聚类算法的选择性聚类集成方法》公开了一种基于谱聚类算法的选择性聚类集成方法,包括以下步骤:基聚类生成;基于谱聚类算法选择代表成员;对代表成员进行集成;结束。该发明的显著优点是:实现简单且可以有效提升聚类集成的效果。公开号为cn105139414a的专利《用于x光片图像数据的聚类集成方法》公开了一种用于x光片图像数据的聚类集成方法,包括以下步骤:s01:对x光片图像预处理后,从图像中获取数据;s02:获得图像中每一个点的灰度值gi,j存储在灰度值矩阵g中,gi,j表示图像中第i行,第j列点的灰度值;s03:用基于k均值改进算法的聚类集成算法或者基于层次聚类改进算法对灰度值矩阵g进行聚类分析处理;s04:使用hgpa算法进行集成运算。基于k均值改进算法的聚类集成算法改进了k个初始簇中心的选取,改进后的层次聚类算法在数据预处理过程中将数据进行了简化,将灰度值相同的点先划分在了同一个簇中,初始簇数量最多只有256个。可以降低x光片的观察难度甚至能够找出外源性异物,从而辅助医生的诊断。
聚类集成能够提高聚类结果的质量和鲁棒性,在处理具有多重视角的数据集聚类任务时更具优势,但聚类集成也面临三个难点:首先,不同的基聚类算法可能会产生不同数目、不同结果的簇,难以直接整合成一个统一结果。第二、聚类集成结果中包含的簇的数目事先无法获知,而且该数目还有可能取决于样本的规模。第三,簇的标签是一种符号化表示形式,因此需要校准不同基聚类结果之间的簇标签,使得不同基聚类结果之间的簇标签是一致的。
技术实现要素:
本发明要解决的技术问题是:设计一种聚类集成方法,能够自动确定最终聚类集成结果中的簇数目,利用基聚类中不同数目、不同结果以及不同标签的簇生成一个具有较高鲁棒性和可靠性的聚类集成结果。
本发明利用信息熵表示数据描述的不确定性,将数据集的数值描述和聚类划分分别视为数据集在特征空间和符号空间中的两种表示方法,首先通过计算数据集的这两种数据表示方法之间的一致性对不同基聚类中簇之间的划分相似性进行度量,同时利用该一致性计算每个基聚类的集成权重;接着依据簇的相似性利用谱聚类方法对所有基聚类的簇进行图最小分割以实现基聚类之间的标签对齐;最后,利用加权投票法对基聚类进行一致性集成,生成聚类集成结果,并进行结果输出。
本发明提出的方法可用于处理各类数值型数据集的聚类分析任务,例如:该方法可用于识别基因表达数据中的相似模式以及拥有相同生物意义的基因集和样本集,进而在聚类分析基础上寻找相关的基因、分析基因的功能以及转录调控;该方法也可用于发现复杂网络数据集内部节点之间的结构与功能的关联特征,进行网络社区结构的划分,进而理解复杂网络的功能,探求网络中隐藏的规律并预测复杂网络的行为;该方法还可以用于处理复杂图像数据集,根据视觉特征、凸目标和背景场景等将图像划分为若干个互不重叠的区域,实现图像分割。
本发明所采用的技术方案是:一种加权投票聚类集成方法,对于一个样本数量为n的数据集
s10、计算基聚类集合
s20、计算基聚类集合
s30、构建基聚类集合的簇划分相似性矩阵,将基聚类集合中簇的标签对齐任务转换为图最小分割问题;
s40、利用谱聚类方法对基聚类中的所有簇构成的集合ω进行图最小分割处理,实现对基聚类集合中簇的标签对齐;
s50、利用高斯核函数
s60、计算每个基聚类在特征空间中数据描述的一致性:首先,计算标准化数据集ψ关于数据集x的条件信息熵,用于表示利用数据集x在特征空间中数据描述的不确定性;接着,计算标准化数据集ψ关于某个基聚类的条件信息熵,用于表示该基聚类在特征空间中数据描述的不确定性;计算标准化数据集ψ的以上两个条件信息熵的差值作为该基聚类在特征空间中数据描述的一致性,以此类推计算每个基聚类在特征空间中数据描述的一致性;
s70、利用步骤s50获得的每个基聚类在特征空间中数据描述的一致性计算各基聚类的聚类集成权重;
s80、对步骤s30获得的标签对齐后的基聚类集合进行加权投票集成,生成最终的聚类集成结果,并将结果输出。
进一步,所述步骤s10包含:
s11、利用式(1)计算聚类符号向量集合φ关于数据集x的条件信息熵,用于表示利用数据集x在符号空间中数据描述的不确定性:
其中,h(λt|x)为第t个基聚类ct的聚类符号向量λt关于数据集x的条件信息熵,可由式(2)计算:
式中,p(λt,k|x)表示聚类符号向量λt关于数据集x的条件概率,可由式(3)计算:
式中xi(λt)表示样本xi在第t个聚类符号向量上的取值,即样本xi在第t个基聚类中对应的簇标签;
s12、对于基聚类集合
其中,{cp,q,cm,n}为cp,q和cm,n构成的集合,h(λt|{cp,q,cm,n})为第t个基聚类ct的聚类符号向量λt关于集合{cp,q,cm,n}的条件信息熵,可由式(5)计算:
其中,p(λt,k|{cp,q,cm,n})表示聚类符号向量λt关于集合{cp,q,cm,n}的条件概率,可由式(6)计算:
式中xa(λt)表示集合{cp,q,cm,n}中的样本xa在第t个聚类符号向量上的取值,即样本xa在第t个基聚类中对应的簇标签;
s13、计算聚类符号向量集合φ关于数据集x的条件信息熵与关于集合{cp,q,cm,n}的信息熵的差值作为簇cp,q和cm,n在符号空间中数据描述的一致性,如式(7)所示:
i(φ|{cp,q,cm,n})=h(φ|x)-h(φ|{cp,q,cm,n})(7)
s14、利用步骤s11~s13的方法,计算基聚类集合
进一步,该方法所述步骤s20中计算不同基聚类中任意两个簇之间的簇划分相似性的方法如式(8)所示:
其中,θ(cp,q,cm,n)表示簇cp,q和cm,n之间的划分相似性,参数α的取值设为i(φ|{cp,q,cm,n})的标准差。
进一步,所述步骤s30包含:
s31、以不同基聚类中任意两个簇之间的簇划分相似性为元素,构建基聚类集合的簇划分相似性矩阵θ=[θ(cp,q,cm,n)]k×k,其中k为θ的维数;
s32、将基聚类集合中簇的标签对齐任务转换为图最小分割问题,构建目标函数如式(9)所示:
其中,
进一步,所述步骤s40包含:
s41、利用簇划分相似性矩阵θ每一列上元素之和构建一个k维对角矩阵,记为d,并定义矩阵λ=d-θ;
s42、求出矩阵λ按从小到大顺序排列的前r个特征值
s43、将步骤s42得到的r个特征向量排列在一起组成一个k×r的矩阵,将其中每一行看作r维空间中的一个向量,并使用k-means算法进行聚类,得到式(9)的最优解,即对于簇集合ω的最优划分
s44、利用对于簇集合ω的最优划分进行基聚类集合中簇的标签对齐,对于数据集x中的样本xi,其在第t个基聚类中的标签可利用式(10)进行对其:
式中,xi(λt)表示样本xi在第t个基聚类中的标签,
进一步,该方法所述步骤s50中高斯核函数
其中,参数β的取值设为||xi-xo||2的标准差,xo为数据集x中不同于xi的另一样本,ψo表示xo映射得到的标准数据样本。
进一步,所述步骤s60包含:
s61、利用式(12)计算标准化数据集ψ关于数据集x的条件信息熵,用于表示数据集x
在特征空间中数据描述的不确定性
其中,h(ψ|x)为标准化数据集ψ关于数据集x的条件信息熵,
其中,μψ为标准化数据集ψ的期望,满足式(14):
xa、xb以及xc分别表示数据集x中三个不同于xi的样本;
s62、计算标准化数据集ψ关于每个基聚类的条件信息熵,用于描述各基聚类在特征空间中数据描述的一致性,其中ψ关于第t个基聚类ct的条件信息熵可由式(15)计算:
其中,h(ψ|ct)为标准化数据集ψ关于第t个基聚类ct的条件信息熵,
其中,ψe为标准化数据集ψ中的第e个样本,
xe、xf、xg以及xh分别表示数据集x中的第e、f、g和h个样本;
s63、对步骤s61和s62获得的标准化数据集ψ的两个条件信息熵计算差值,作为基聚类在特征空间中数据描述的一致性,其中第t个基聚类ct在ψ上的一致性由式(18)计算:
i(ψ|ct)=h(ψ|x)-h(ψ|ct)(18)
其中,i(ψ|ct)表示ct在ψ上的一致性度量;
s64、利用步骤s61~s63的方法,逐个计算每个基聚类在特征空间中数据描述的一致性。
进一步,所述步骤s70中依据每个基聚类在特征空间数据描述的一致性计算每个基聚类的集成权重的方法如式(19)所示:
其中,ωt表示聚类成员ct的聚类集成权重。
进一步,所述步骤s80包含:
s81、依据步骤s40获得的对齐后的基聚类簇标签和步骤s70获得的各基聚类的集成权重建立如式(20)所示的聚类集成目标优化函数:
其中x(λ*)表示数据集x的聚类集成结果中所有样本的簇标签,δ(xi(λt),xi(λ**))由式(21)定义
xi(λ*)表示聚类集成结果中样本xi的簇标签;
s82、利用加权投票法对式(20)的目标优化函数求解获得每个样本的最终簇标签,如式(22)所示:
其中δ(xi(λt),λ*l)由式(21)定义
s83、将数据集x中的所有样本按照步骤s82求得的簇标签进行划分,形成聚类集成结果
本发明的有益效果在于:利用信息熵对基聚类集合中簇之间的相似性进行有效度量,将簇标签对齐问题转换为相似性矩阵的图最小分割问题,并且为每个基聚类分配聚类集成权重,这一权重能够充分有效反映基聚类质量及可靠性,减小低质量基聚类对聚类集成结果的不良影响,最后通过加权投票方法生成聚类集成结果,能有效提高聚类集成结果的准确性和鲁棒性。
附图说明
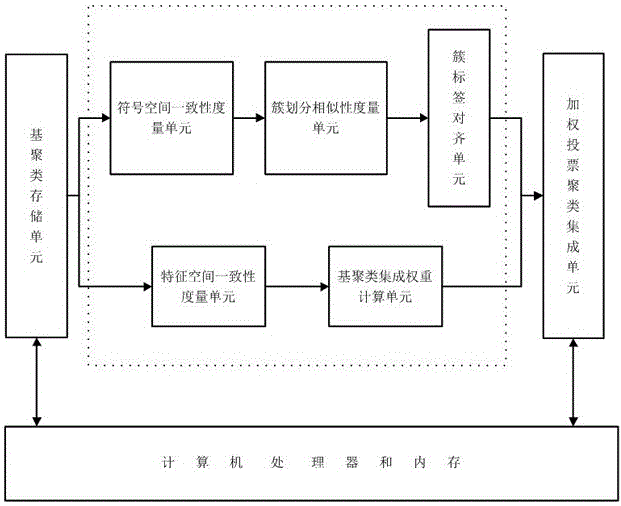
图1为本发明所述加权投票聚类集成方法的计算机实现系统结构图;
图2为本发明所述加权投票聚类集成方法的流程图。
具体实施方式
下面结合附图对本发明的具体实施方式进行详细说明。
本发明所述的加权投票聚类集成方法通过计算机程序实施,图1所示是计算机实现的系统结构图。在此结构图中,基聚类存储单元用于存放输入系统的一系列基聚类,符号空间一致性度量单元用于度量不同基聚类中的两个簇在符号空间中数据描述的一致性,簇划分相似性度量单元用于度量基聚类集合中两个簇分布结构的相似性,簇标签对齐单元用于将不同基聚类中的簇标签统一到同一符号向量下,特征空间一致性度量单元用于度量基聚类在特征空间中数据描述的一致性,基聚类集成权重计算单元用于计算每个基聚类的聚类集成权重,加权投票聚类集成单元利用加权投票法将一系列基聚类集成为一个统一的聚类集成结果。
下面将本发明提出的技术方案用于处理基因表达数据集,进行基因表达数据中的相似模式的发现,按照如图2所示的流程进行详述。将每个基因作为一个样本,数量为n的样本构成基因表达数据数据集
步骤1、计算基聚类集合
步骤1-1、利用式(1)计算聚类符号向量集合φ关于数据集x的条件信息熵,用于表示利用数据集x在符号空间中数据描述的不确定性:
其中,h(λt|x)为第t个基聚类ct的聚类符号向量λt关于数据集x的条件信息熵,可由式(2)计算:
式中,p(λt,k|x)表示聚类符号向量λt关于数据集x的条件概率,可由式(3)计算:
式中xi(λt)表示样本xi在第t个聚类符号向量上的取值,即样本xi在第t个基聚类中对应的簇标签;
步骤1-2、对于基聚类集合
其中,{cp,q,cm,n}为cp,q和cm,n构成的集合,h(λt|{cp,q,cm,n})为第t个基聚类ct的聚类符号向量(λt关于集合{cp,q,cm,n}的条件信息熵,可由式(5)计算:
其中,p(λt,k|{cp,q,cm,n})表示聚类符号向量λt关于集合{cp,q,cm,n}的条件概率,可由式(6)计算:
式中xa(λt)表示集合{cp,q,cm,n}中的样本xa在第t个聚类符号向量上的取值,即样本xa在第t个基聚类中对应的簇标签;
步骤1-3、计算聚类符号向量集合φ关于数据集x的条件信息熵与关于集合{cp,q,cm,n}的信息熵的差值作为簇cp,q和cm,n在符号空间中数据描述的一致性,如式(7)所示:
i(φ|{cp,q,cm,n})=h(φ|x)-h(φ|{cp,q,cm,n})(7)
步骤1-4、利用步骤1-1~步骤1-3的方法,计算基聚类集合
步骤2、计算基聚类集合
其中,θ(cp,q,cm,n)表示簇cp,q和cm,n之间的划分相似性,参数α的取值设为i(φ|{cp,q,cm,n})的标准差。
步骤3、构建基聚类集合的簇划分相似性矩阵,将基聚类集合中簇的标签对齐任务转换为图最小分割问题,具体包含以下步骤:
步骤3-1、以不同基聚类中任意两个簇之间的簇划分相似性为元素,构建基聚类集合的簇划分相似性矩阵θ=[θ(cp,q,cm,n)]k×k,其中k为θ的维数;
步骤3-2、将基聚类集合中簇的标签对齐任务转换为图最小分割问题,构建目标函数如式(9)所示:
其中,
步骤4、利用谱聚类方法对基聚类中的所有簇构成的集合ω进行图最小分割处理,实现对基聚类集合中簇的标签对齐,具体包含以下步骤:
步骤4-1、利用簇划分相似性矩阵θ每一列上元素之和构建一个k维对角矩阵,记为d,并定义矩阵λ=d-θ;
步骤4-2、求出矩阵λ按从小到大顺序排列的前r个特征值
步骤4-3、将步骤步骤4-2得到的r个特征向量排列在一起组成一个k×r的矩阵,将其中每一行看作r维空间中的一个向量,并使用k-means算法进行聚类,得到式(9)的最优解,即对于簇集合ω的最优划分
步骤4-4、利用对于簇集合ω的最优划分进行基聚类集合中簇的标签对齐,对于数据集x中的样本xi,其在第t个基聚类中的标签可利用式(10)进行对其:
式中,xi(λt)表示样本xi在第t个基聚类中的标签,
步骤5、利用如式(11)所示的高斯核函数
其中,参数β的取值设为||xi-xo||2的标准差,xo为数据集x中不同于xi的另一样本,ψo表示xo映射得到的标准数据样本。
步骤6、计算每个基聚类在特征空间中数据描述的一致性:首先,计算标准化数据集ψ关于数据集x的条件信息熵,用于表示利用数据集x在特征空间中数据描述的不确定性;接着,计算标准化数据集ψ关于某个基聚类的条件信息熵,用于表示该基聚类在特征空间中数据描述的不确定性;计算标准化数据集ψ的以上两个条件信息熵的差值作为该基聚类在特征空间中数据描述的一致性,以此类推计算每个基聚类在特征空间中数据描述的一致性,具体包含以下步骤:
步骤6-1、利用式(12)计算标准化数据集ψ关于数据集x的条件信息熵,用于表示数据集x在特征空间中数据描述的不确定性
其中,h(ψ|x)为标准化数据集ψ关于数据集x的条件信息熵,
其中,μψ为标准化数据集ψ的期望,满足式(14):
xa、xb以及xc分别表示数据集x中三个不同于xi的样本。
步骤6-2、计算标准化数据集ψ关于每个基聚类的条件信息熵,用于描述各基聚类在特征空间中数据描述的一致性,其中ψ关于第t个基聚类ct的条件信息熵可由式(15)计算:
其中,h(ψ|ct)为标准化数据集ψ关于第t个基聚类ct的条件信息熵,
其中,ψe为标准化数据集ψ中的第e个样本,
xe、xf、xg以及xh分别表示数据集x中的第e、f、g和h个样本;
步骤6-3、对步骤6-1和步骤6-2获得的标准化数据集ψ的两个条件信息熵计算差值,作为基聚类在特征空间中数据描述的一致性,其中第t个基聚类ct在ψ上的一致性由式(18)计算:
i(ψ|ct)=h(ψ|x)-h(ψ|ct)(18)
其中,i(ψ|ct)表示ct在ψ上的一致性度量;
步骤6-4、利用步骤6-1~步骤6-3的方法,逐个计算每个基聚类在特征空间中数据描述的一致性。
步骤7、利用步骤5获得的每个基聚类在特征空间中数据描述的一致性计算各基聚类的聚类集成权重,如式(19)所示:
其中,ωt表示聚类成员ct的聚类集成权重。
步骤8、对步骤3获得的标签对齐后的基聚类集合进行加权投票集成,生成最终的聚类集成结果,并将结果输出,具体包括以下步骤:
步骤8-1、依据步骤4获得的对齐后的基聚类簇标签和步骤7获得的各基聚类的集成权重建立如式(20)所示的聚类集成目标优化函数:
其中x(λ*)表示数据集x的聚类集成结果中所有样本的簇标签,δ(xi(λt),xi(λ*))由式(21)定义
xi(λ*)表示聚类集成结果中样本xi的簇标签;
步骤8-2、利用加权投票法对式(20)的目标优化函数求解获得每个样本的最终簇标签,如式(22)所示:
其中δ(xi(λt),λ*l)由式(21)定义
步骤8-3、将数据集x中的所有样本按照步骤步骤8-2求得的簇标签进行划分,形成聚类集成结果
本发明针对聚类集成过程中的基聚类产生的簇在数量、质量以及标签等方面难以统一的问题,提出了一种加权投票聚类集成方法,首先计算基聚类集合
尽管已经参照其示例性实施例具体显示和描述了本发明,但是本领域的技术人员应该理解,在不脱离权利要求所限定的本发明的精神和范围的情况下,可以对其进行形式和细节上的各种改变。
- 还没有人留言评论。精彩留言会获得点赞!