一种基于网络映射的社交网络中异常用户检测方法与流程
本发明涉及网络数据检测的技术领域,尤其涉及到一种基于网络映射的社交网络中异常用户检测方法。
背景技术:
社交网络的便利性、娱乐性、实时性等一系列优良特性吸引了海量的用户,在网络空间中构筑起一个虚拟的社会。同时,社交网络庞大的用户基数吸引了大量的攻击者。攻击者通过创建大量的虚假账号和盗用正常的账户,在社交网络中或散发谣言,或发布广告、钓鱼、色情信息等,或通过这些账号来恶意增加其他账号的信誉,如批量关注、恶意点赞等。这些攻击者统称为异常用户。因此,社交网络中的异常用户检测对个人、企业和国家均具有十分重要的意义。
目前,学术界和工业界提出了大量的检测社交网络中异常用户的方法。这些方法可以被归为四类:基于行为特征的检测方法,基于内容的检测方法,基于图的检测方法,以及基于无监督学习的检测方法。基于行为特征的检测方法将异常用户检测视为一个二分类问题,利用用户的行为特征来区分正常用户和异常用户。基于内容的检测方法与基于行为特征的检测方法类似,其主要利用的是用户发布的内容信息,这些信息反映了用户的兴趣爱好。基于图的检测方法是利用正常用户和异常用户在所形成的社交网络中具有不同的结构性质,将异常用户检测问题转化为网络中的异常节点检测问题,然后利用图挖掘的相关算法来识别出异常用户。基于无监督学习的方法是利用正常用户有相同或者相似的特征,通过特征的聚类来区分正常用户和异常用户。尽管这些检测方法已经被广泛运用到实践当中,但是这些方法只有在特定的应用场景下才能取得良好的效果,泛化能力不强,不具有普适性,因而不能很好的满足实际需要。具体来讲,基于行为特征和基于内容的检测方法虽然准确率较高,但由于是有监督学习方法,需要提前对样本数据进行标记,这需要花费大量的时间和人力成本,而且只能检测已知的异常类型,当异常用户改变其表现形态后就无法准确检测。基于图的检测方法虽然有较强的鲁棒性,但是准确率较低,而且只能检测与其他用户有联系的异常用户,目前尚处于理论研究阶段。基于无监督学习的方法不需要提前对样本数据进行标记,节省了时间和人力成本开销,因而能够较快形成检测系统并且可以检测未知的攻击行为,但是其不容易区分不同类型的异常用户。
鉴于社交网络中海量的用户基数、异常用户的多种表现形态和动态特征,以及已有的办法的缺陷,亟待提出一种时间和人力成本开销低、能够识别各种各样的异常用户类型并且能够识别新的异常用户类型、能够综合考虑用户多维度的属性特征、准确率高的检测方法。
技术实现要素:
本发明的目的在于克服现有技术的不足,提供一种时间和人力成本开销低、能够识别各种各样的异常用户类型并且能够识别新的异常用户类型、能够综合考虑用户多维度的属性特征、准确率高的基于网络映射的社交网络中异常用户检测方法。
为实现上述目的,本发明所提供的技术方案为:其包括以下步骤:
s1、利用网络爬虫技术爬取如腾讯qq、微信、新浪微博、facebook等社交网络平台的用户数据。
s2、对爬取到的用户数据进行预处理,构建用户社交关系网络图g;预处理步骤如下:
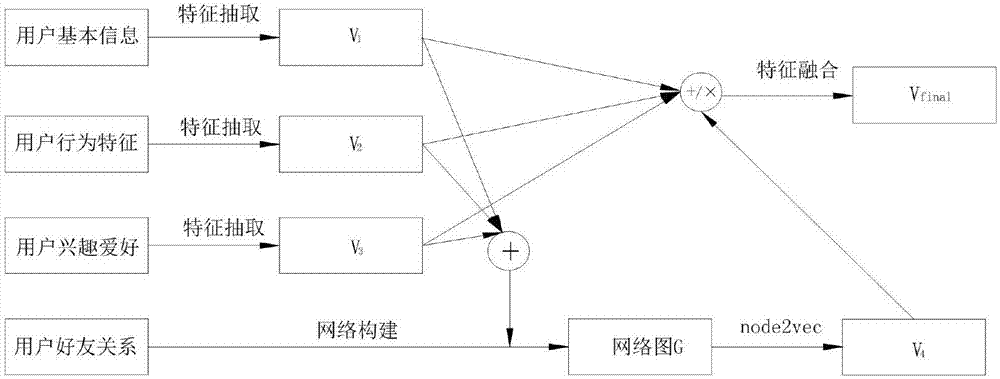
s21、将爬取到的用户数据分为四个维度,分别为用户基本信息、用户行为特征、用户兴趣爱好以及用户好友关系;
s22、将步骤s21中所述用户基本信息、用户行为特征、用户兴趣爱好该三个维度的用户数据分别对应处理成三个含有多维的特征向量;
对于基本信息,用户id作为用户身份的唯一标识,其他的信息用一个向量v1来表示,v1的维数为l1,对于不是数值型的基本信息,将其一一映射到实数空间;如对于性别,用0表示女,用1表示男;对于所在地,先将所有的用户所在地按字符串序排序,然后用某个地址的顺序数来表示该地址;
对于行为特征,采取与基本信息一样的处理方式;行为特征用向量v2来表示,v2的维数为l2。对于发布消息的时间间隔,记录最大的时间间隔、最小的时间间隔和平均时间间隔。
对于用户兴趣爱好,用户兴趣爱好的处理主要依据lda主题模型,即从与用户相关的消息内容中抽取出用户的兴趣爱好,具体步骤如下:
1)分词:
对与用户相关的每一条消息文本d进行分词处理,去掉停用词、标点符号和特殊符号等与主题无关的词,得到该消息的单词序列<w1,w2,w3,…,wn>,其中wi表示第i个单词,设d一共有n个单词;所有的消息内容的集合记为d,即d={d1,d2,d3,…,dm},设总共有m条消息内容;
2)生成每条消息的主题:
lda假设一篇文档的主题分布服从某个概率分布p(t|d),同时也假设在给定某个主题t的前提下,单词也服从某个概率分布p(w|t),一篇文章d包含单词w的概率为:
p(w|d)=∑tp(w|t)*p(t|d),
考虑所有的文档,采用矩阵形式来描述上述关系,即:
其中,d的元素表示词频,t的行向量表示文档的主题分布,w的列向量表示主题的单词分布;
通过统计分析得到p(w|d)的经验分布
其中,第一项表示t和w的乘积应尽可能的与
3)生成用户兴趣爱好的特征向量:
在求得每条消息的主题之后,针对每一个用户u,其兴趣爱好特征向量按下式求解:
其中,h表示与u相关的消息数,tu表示与u相关的消息的主题分布,v3的维度记为l3。
s23、将步骤s22得到的三个特征向量拼接在一起得到v0,v0的维度为l0=l1+l2+l3。
s24、处理用户好友关系的数据,并与步骤s23拼接在一起的特征向量v0配合构建用户社交关系网络图g;具体过程为:基于好友、粉丝和关注情况构造一个有向无权图g0;但这样得到的g0往往十分稀疏,为了解决该问题,本方案在存在联系的用户和其二度好友之间构建一条赋予权值0.5的边,相应地,一度好友之间连边的权值设为1.0,从而得到有权图g0';显然,这样定义的权值比较粗糙,进一步地,对g0'中的任意一条边e=(u,v),按如下方式计算其权值:
wt(e)=wt0*wt1*wt2,
其中,wt0等于0.5或者1,取决于u,v是一度好友还是二度好友;wt1定义为u和v的一度好友的jaccard相似性,即
s3、基于用户社交关系网络图g,利用node2vec将用户的社交关系转化为低维的向量表征;
用户社交关系网络图g经典描述方式为邻接矩阵,邻接矩阵的行向量可作为用户的特征向量,这种方式简单直接,但是不具有可行性。例如,微信用户数超过8亿,那么就需要用一个超过8亿维的向量来表征一个用户,这显然不切实际。因此需要基于用户社交关系网络图g求出一个低维向量来尽可能准确地表征用户在社交关系当中表现出的特征。这即为网络映射(networkembedding)。网络映射形式化定义为:
给定图g=(v,e),其中v是节点集合,e是边的集合,寻找一个映射函数
将网络中的节点映射到低维向量空间rr,转换后的低维向量尽可能保留原网络的特性。
本方案采用node2vec来进行网络映射。node2vec本质上与deepwalk一样。deepwalk借鉴的是word2vec的思想,其将网络中的节点视为一个单词,然后将从某个节点出发得到的长度为s的短距离随机游走节点序列视为一个句子,然后再利用word2vec来求得每个节点的向量表征。node2vec与deepwalk的差别在于其选择的是一种可以调节的2nd度随机游走方式。node2vec的提出基于同质性假设和结构等价假设,同质性假设表明处于同一社区的节点理应由相似的向量表征,结构等价假设表明网络中充当相同或类似角色的节点的向量表征应尽可能相似。这两个假设均符合本方法的需要。因而选择node2vec来做网络映射是合适的选择。node2vec通过两个参数来控制随机游走是倾向于bfs还是dfs,因而具有更大的灵活性,因而本方法也具有很好的灵活性。当node2vec中随机游走倾向于宽度优先bfs时,得到的节点向量表征能够更精确的刻画节点的局部特征;当node2vec中随机游走倾向于深度优先dfs时,得到的节点向量表征能够更精确的刻画节点的全局特征。考虑到社交网络的小世界效应(即经典的六度分隔理论),本方法更倾向于得到节点的局部特征的精确刻画,即bfs所占的比重比dfs大。node2vec采用2nd度随机游走方式相比于deepwalk的一个很大的优势在于得到的节点向量表征的是节点的半局部信息,因而比局部信息更精准,同时又比全局信息更高效。网络映射最终可转化为最优化问题,node2vec的优化目标函数为:
其中,ns(u)表示节点u的通过负采样策略选出的邻居。利用随机梯度下降sgd可以求解该优化问题。通过node2vec得到的用户社交关系表征记为v4,其维度为l4。
s4、融合用户多维度的向量表征得到最终的向量表征;
用户多维度的向量表征的融合方式有两种,一种简易的融合方式为直接将v1,v2,v3,v4拼接在一起得到一个维度为l1+l2+l3+l4的用户最终向量表征vfinal,此种方式的缺陷在于没有考虑v1,v2,v3,v4之间的相关性。另一种融合方式通过借助张量得到
s5、基于用户特征向量vfinal,采取k-means或者dbscan算法对用户进行聚类,然后对得到的类中用户进行抽样验证来判断类中用户是否为正常用户,如果是异常用户,则同时可以确定该类所属的异常类型。k-means为一种基于距离的聚类算法,其将用户分为k个类别,处于同一个类别中的用户相似性大于处于不同类别中用户的相似性。dbscan聚类算法为一种基于高密度连通区域的基于密度的聚类算法,能够将具有足够高密度的用户划分到一起,并且在具有噪声的数据中发现任意大小的用户组。dbscan对于检测异常用户类型能够比k-means取得更好的结果,但是k-means求解比dbscan简单很多,在应用中可结合实际情况做出选择。
与现有技术相比,本方案原理和优点如下:
1.本方案主要分为特征工程和聚类预测两个阶段,采用的是无监督学习策略,相比于有监督学习策略,具有用时少以及人力成本开销低等优势。
2.基于图的检测方法与基于无监督学习的检测方法都是无监督的方法,传统算法将二者分开处理,没有充分利用用户数据包含的信息,因而预测效果不尽如人意;本方案同时考虑用户的社交关系和用户的其他特征,将基于图的检测方法与基于无监督学习的检测方法的优势合二为一,最终得到的用户特征向量能够更准确的刻画用户的真实特征。
附图说明
图1为本发明一种基于网络映射的社交网络中异常用户检测方法的总体框架图;
图2为本发明一种基于网络映射的社交网络中异常用户检测方法中特征工程的流程图;
图3为本发明一种基于网络映射的社交网络中异常用户检测方法的工作流程图。
具体实施方式
下面结合具体实施例对本发明作进一步说明:
参见附图1-3所示,本实施例所述的一种基于网络映射的社交网络中异常用户检测方法,包括以下步骤:
s1、利用网络爬虫技术爬取微信社交网络平台的用户数据,需要爬取的详细数据参见表1。
表1特征类型与对应的用户数据
s2、对爬取到的用户数据进行预处理,构建用户社交关系网络图g;预处理步骤如下:
s21、将爬取到的用户数据分为四个维度,分别为用户基本信息、用户行为特征、用户兴趣爱好以及用户好友关系;
s22、将步骤s21中所述用户基本信息、用户行为特征、用户兴趣爱好该三个维度的用户数据分别对应处理成三个含有多维的特征向量;
对于基本信息,用户id作为用户身份的唯一标识,其他的信息用一个向量v1来表示,v1的维数为l1,对于不是数值型的基本信息,将其一一映射到实数空间;
对于行为特征,采取与基本信息一样的处理方式;行为特征用向量v2来表示,v2的维数为l2。
对于用户兴趣爱好,用户兴趣爱好的处理主要依据lda主题模型,即从与用户相关的消息内容中抽取出用户的兴趣爱好,具体步骤如下:
1)分词:
对与用户相关的每一条消息文本d进行分词处理,去掉停用词、标点符号和特殊符号等与主题无关的词,得到该消息的单词序列<w1,w2,w3,…,wn>,其中wi表示第i个单词,设d一共有n个单词;所有的消息内容的集合记为d,即d={d1,d2,d3,…,dm},设总共有m条消息内容;
2)生成每条消息的主题:
lda假设一篇文档的主题分布服从某个概率分布p(t|d),同时也假设在给定某个主题t的前提下,单词也服从某个概率分布p(w|t),一篇文章d包含单词w的概率为:
p(w|d)=∑tp(w|t)*p(t|d),
考虑所有的文档,采用矩阵形式来描述上述关系,即:
其中,d的元素表示词频,t的行向量表示文档的主题分布,w的列向量表示主题的单词分布;
通过统计分析得到p(w|d)的经验分布
其中,第一项表示t和w的乘积应尽可能的与
3)生成用户兴趣爱好的特征向量:
在求得每条消息的主题之后,针对每一个用户u,其兴趣爱好特征向量按下式求解:
其中,h表示与u相关的消息数,tu表示与u相关的消息的主题分布,v3的维度记为l3。
s23、将步骤s22得到的三个特征向量拼接在一起得到v0,v0的维度为l0=l1+l2+l3。
s24、处理用户好友关系的数据,并与步骤s23拼接在一起的特征向量v0配合构建用户社交关系网络图g,具体步骤如下:
1))基于好友、粉丝和关注情况构造一个有向无权图g0;
2))基于有向无权图g0,在用户和其二度好友之间构建一条赋予权值0.5的边,和一度好友之间连边的权值设为1.0,得到有权图g0';
3))计算有权图g0'中任意一条边e=(u,v)的权值,得出有向边权的用户社交关系网络图g;
权值的计算公式如下:
wt(e)=wt0*wt1*wt2,
其中,wt0反映了u和v是一度好友还是二度好友,wt1反应了u和v的共同好友是多还是少,wt2反映了u和v的兴趣爱好和行为特征等是否相似。
s3、基于用户社交关系网络图g,利用node2vec将用户的社交关系转化为低维的向量表征;
利用node2vec将用户的社交关系转化为低维的向量表征的优化目标函数为:
其中,fg(u)为网络映射函数,
s4、通过直接相加拼接的融合方式融合用户多维度的向量表征得到最终的向量表征;
s5、基于用户的特征向量采用k-means算法对用户进行聚类,预测用户是正常用户,还是异常用户,如果是异常用户,并给出异常类型。
本实施例主要分为特征工程和聚类预测两个阶段,采用的是无监督学习策略,相比于有监督学习策略,具有用时少以及人力成本开销低等优势;另外,本实施例同时考虑用户的社交关系和用户的其他特征,将基于图的检测方法与基于无监督学习的检测方法的优势合二为一,最终得到的用户特征向量能够更准确的刻画用户的真实特征。
以上所述之实施例子只为本发明之较佳实施例,并非以此限制本发明的实施范围,故凡依本发明之形状、原理所作的变化,均应涵盖在本发明的保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!