基于媒体内容的自适应系统码FEC编译码方法与流程
本发明涉及多媒体传输技术领域,具体地,涉及基于媒体内容的自适应系统码前向纠错(forwarderrorcorrection,fec)编译码方法。
背景技术:
在异构网络媒体服务系统中,内容通过因特网协议或广播协议分发到终端,因特网中使用ip/tcp或udp报文来传输媒体数据,广播通过mpeg2-ts来传输内容。udp报文在经过多个网络设备后可能会出现丟失,广播ts流可能因为传输环境的影响,产生误码,从而造成终端侧的画面破损或者声音停顿。
fec(forwarderrorcorrection,前向纠错)技术是一种广泛应用于通信系统中的编码技术。通过服务器侧对媒体数据进行纠错编码,加入冗余信息一并发送,终端侧进行反向fec解码,对丟失的报文进行恢复。以典型的分组码为例,其基本原理是:在发送端,通过将kbit信息作为一个分组进行编码,加入(n-k)bit的冗余校验信息,组成长度为nbit的码字。码字经过信道到达接收端之后,如果错误在可纠错范围之内,通过译码即可检查并纠正错误bit,从而抵抗信道带来的干扰,有效降低系统的误码率,提高通信系统的可靠性。但是fec处理,是以冗余开销代价来降低系统的误码率,过度fec编码对系统实时性和网络状态也会造成压力。
不等差错保护(unequalerrorprotection,uep)是联合信源信道编码的一种。其核心思想是,依据码流的各部分数据的重要性不同,对各部分数据采用不同的信道保护机制,即对重要码流进行重点保护。尽管uep降低了非重要码流的抗噪声性能,但有利于系统抗误码总体性能的提升。
作为一种前向纠错编码技术,数字喷泉码(digitalfountaincode)在传输过程中,不需要反馈及自动重发机制,避免了信号往返的延时以及广播应用中的反馈爆炸问题。数字喷泉的基本思想是:发端将原始数据分割成k个数据符号,对这些数据符号进行编码,输出一个任意长度的编码符号码流,接收端只需正确地接收n(n稍大于k)个编码符号就可以很大的概率恢复出所有的k个数据符号。数字喷泉码本身就具有uep性能,可以实现对不同重要性的数据的保护。
技术实现要素:
针对现有技术中的缺陷,本发明的目的是提供一种基于媒体内容的自适应系统码fec编译码方法。
根据本发明提供的基于媒体内容的自适应系统码fec编译码方法,包括:
根据媒体内容的重要程度,将源数据按照优先级划分为n类源数据包;n为大于1的整数;
根据源数据和n类源数据包的优先级,生成n类中间码;
根据所述n类中间码,按照信道状况设定n类源数据的恢复数据,生成n类系统码的编码符号;
接收所述编码符号,根据译码需要对所述编码符号进行整理排序,对所述编码符号进行译码处理;
根据接收到的编码符号情况,优先译出优先级高的中间码,并根据该中间码恢复出相应的源数据包。
可选地,所述根据源数据和n类源数据包的优先级,生成n类中间码,包括:
构建n类源数据包对应的编码矩阵,记为ai,i=1,2,…n;其中:
式中:ai表示第i类源数据包对应的编码矩阵,g_pi表示第i类源数据包对应的由ldpc矩阵和单位矩阵构成的联合矩阵,g_enci表示第i类源数据包对应的lt编码矩阵;
根据n类源数据包对应的编码矩阵构建源数据的编码矩阵a,所述源数据的编码矩阵如下:
则
式中:c1,c2,…,ci…,cn分别对应n类源数据包的中间码,d1,d2,…,di…,dn分别对应n类源数据包的数据,上标-1为逆矩阵运算符;i=1,2,…n。
可选地,所述根据所述n类中间码,按照信道状况设定n类源数据的恢复数据,包括:
式中:r1,r2,…,ri…,rn分别对应n类源数据包的恢复数据,g_enc1i表示与g_enc1具有相同生成规则的lt编码矩阵;g_enci1表示与g_enci具有相同生成规则的lt编码矩阵;i=1,2,…n。
可选地,当n的值取2时,针对不同重要程度的数据可以产生相应的中间码如下:
改变lt编码矩阵的结构,得到g_enc11、g_enc12、g_enc21,其中g_enc12与g_enc1的生成方式相同;g_enc21与g_enc2的生成方式相同;g_enc11表示与g_enc1具有相同生成方式的lt编码矩阵;g_enc21表示与g_enc2具有相同生成方式的lt编码矩阵;g_enc12表示与g_enc1具有相同生成方式的lt编码矩阵;
得到的恢复数据r1只与优先级为1的数据有关,而恢复数据r2与优先级1和2的数据均有关,则得到:
可选地,当n的值取2时,所述接收所述编码符号,对所述编码符号进行译码处理,包括:
在第一阶段解码时,根据恢复矩阵w以及接收到的源数据包得到中间码字;具体的:
式中:rev_g_enc1表示根据接收到的编码符号的丢包情况,去除g_enc1中丢失包所对应的行后的lt编码矩阵;rev_g_enc11表示根据接收到的编码符号的丢包情况,去除g_enc11中丢失包所对应的行后的lt编码矩阵;rev_g_enc12表示根据接收到的编码符号的丢包情况,去除g_enc12中丢失包所对应的行后的lt编码矩阵;rev_g_enc2表示根据接收到的编码符号的丢包情况,去除g_enc2中丢失包所对应的行后的lt编码矩阵;rev_g_enc21表示根据接收到的编码符号的丢包情况,去除g_enc21中丢失包所对应的行后的lt编码矩阵;
令
接收到的编码符号总数小于源数据生成的编码符号的个数,并且
接收到的编码符号总数小于源数据生成的编码符号的个数,且
式中:rev_d1表示接收到的优先级为1的源数据,rev_r1表示接收到的优先级为1源数据的恢复数据;
接收到的编码符号总数大于等于源数据生成的编码符号的个数,且
若
式中:rev_d2表示接收到的优先级为2的源数据,rev_r2表示接收到的优先级为1和2源数据的恢复数据;
接收到的编码符号总数大于等于源数据生成的编码符号的个数,且
使用高斯消元法直接对矩阵rev_a进行求解,即解下列线性方程组:
得到c1、c2。
可选地,由于部分数据发生丢失,需要根据接收到的编码符号,生成恢复矩阵,相当于擦除掉丢失的编码符号对应的矩阵行,形成相应的恢复矩阵,记为rev_g_enc;根据接收的数据包的数目不同,分不同情况生成中间码字;具体的,包括如下步骤:
步骤a1:假设接收到l类优先级的数据包;则得到如下的恢复矩阵方程:
对恢复矩阵方程进行初等行变换,得到:
式中:rev_g_enc1表示根据接收到的编码符号的丢包情况,去除g_enc1中丢失包所对应的行后的lt编码矩阵;rev_g_enc11表示根据接收到的编码符号的丢包情况,去除g_enc11中丢失包所对应的行后的lt编码矩阵;rev_g_enc12表示根据接收到的编码符号的丢包情况,去除g_enc12中丢失包所对应的行后的lt编码矩阵;rev_g_enc2表示根据接收到的编码符号的丢包情况,去除g_enc2中丢失包所对应的行后的lt编码矩阵;rev_g_enc21表示根据接收到的编码符号的丢包情况,去除g_enc21中丢失包所对应的行后的lt编码矩阵;rev_d1表示接收到的优先级为1的源数据,rev_r1表示接收到的优先级为1源数据的恢复数据;rev_d2表示接收到的优先级为2的源数据,rev_r2表示接收到的优先级为1和2源数据的恢复数据;rev_g_enc1l表示根据接收到的编码符号的丢包情况,去除g_enc1l中丢失包所对应的行后的lt编码矩阵,rev_dl表示表示接收到的优先级为l的源数据,rev_rl表示接收到的优先级为1到l的源数据的恢复数据,cl表示生成的第l类中间码;
步骤a2:令
计算每级生成矩阵的秩:
eachrank(i)=min(len(r(i)),sum(l(1:i)));
式中:eachrank(i)表示优先级为i的数据所对应的子矩阵的秩,其中i=2时所对应的子矩阵为
计算累积矩阵的秩:
cumrank(i)=min(cumrank(i-1)+eachrank(i),sum(l(1:i))),
式中:cumrank(i)表示优先级为1到优先级为i所对应的子矩阵秩之和,cumrank(i-1)表示优先级为1到优先级为i-1所对应的子矩阵秩之和;
其中cumrank(1)=eachrank(1);
依次判断cumrank(i)>=sum(l(1:i)):若成立,cumfullrank(i)=1;否则cumfullrank(i)=0;cumfullrank(i)表示优先级为1到优先级为i所对应的子矩阵组成的矩阵满秩;
步骤a3:设置i初始值为l;
步骤a4:根据接收到的每级编码符号数,分情况分别求中间码c1、c2…cl:
若满足cumfullrand(i)==1&&cumfullrank(1:i)>0,使用rfc6330译码方法解出c1~ci,其中:&&表示与运算,cumfullrank(1:i)表示从优先级为1到优先级为i各子矩阵所组成的矩阵满秩;c1表示优先级为1的数据所对应的中间码,ci表示优先级为i的数据所对应的中间码;
设
x1_2=a2-1b1_2a1-1,
式中:rev_aδi表示到优先级为i时所有子矩阵组成的满秩矩阵,b1_2表示子矩阵
令
c1=c1_temp
根据数学归纳法,得到:
求得c1、c2…ci,其中,不能解出ci+1…cl;
若满足cumfullrand(i)==1,且不满足cumfullrank(1:i)>0,使用高斯消元译码方法解出c1~ci
设
通过高斯消元法解线性方程组:
求得c1、c2…ci,其中,不能解出ci+1…cl;
对于任一i值,若不满足cumfullrand(i)==1则相应ci不能解出;直到i==1,也不满足cumfullrank(1:i)>0时,则c1、c2…cl全部不能解出,译码失败;
步骤a5:令i的值自减1,返回执行步骤a4。
与现有技术相比,本发明具有如下的有益效果:
本发明提供的基于媒体内容的自适应系统码fec编译码方法,对目前fec系统中过度编码造成的数据拥塞,通过对媒体内容分级,赋予不同的重要性,采用不等差错保护(uep),最大限度保证媒体内容质量的同时,减少fec造成的数据冗余;提供了基于系统喷泉码的不等差错保护方案,使系统码的编译码更加灵活,可支持不等差错保护;不需要对源数据流进行分流,因此降低了发送端fec编码的复杂度,提高了fec编码的效率;同时,可以根据当前网络状态的变化动态的调整编码方案,因此对时变网络具有更强的适应性。
附图说明
通过阅读参照以下附图对非限制性实施例所作的详细描述,本发明的其它特征、目的和优点将会变得更明显:
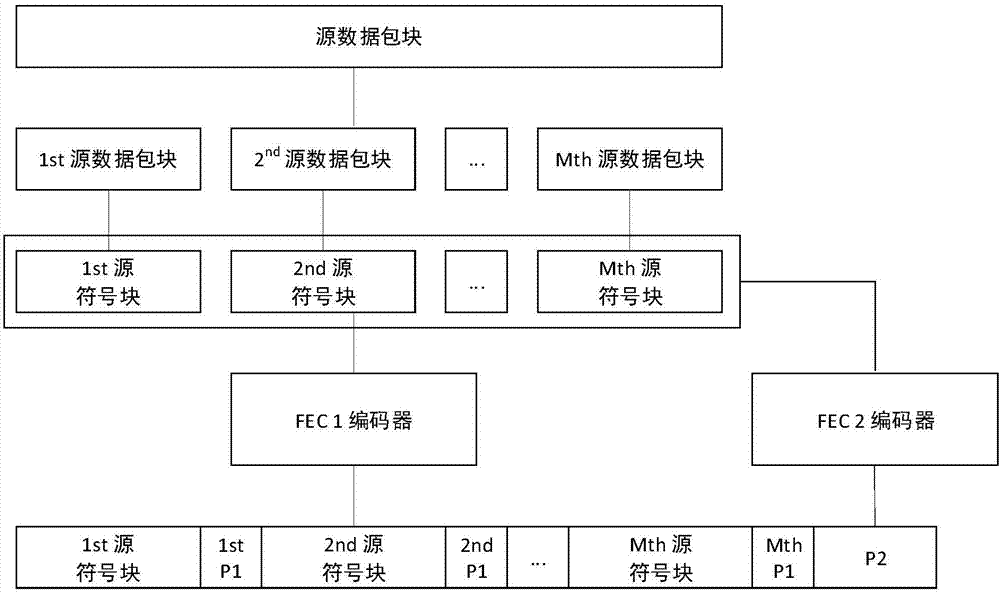
图1为针对媒体资源数据的fec两层结构示意图;
图2(a)、图2(b)为图像组中各帧依赖关系示意图;
图3为喷泉码的不等差错保护编码方案示意图;
图4为喷泉码不等差错保护的系统架构示意图;
图5为系统raptorq码编码矩阵结构示意图;
图6为系统raptorq码不等差错保护的编码矩阵结构示意图;
图7为lt编码矩阵不等差错保护结构示意图;
图8为多优先级不等差错保护系统喷泉码编码流程图;
图9为多优先级不等差错保护系统喷泉码译码流程图。
具体实施方式
下面结合具体实施例对本发明进行详细说明。以下实施例将有助于本领域的技术人员进一步理解本发明,但不以任何形式限制本发明。应当指出的是,对本领域的普通技术人员来说,在不脱离本发明构思的前提下,还可以做出若干变化和改进。这些都属于本发明的保护范围。
如图1所示:针对媒体资源数据的fec两层结构,第一层将源数据包块sourcepacketblock分为较多的小块分别做fec保护,第二层是一个整块做fec保护。第一层划分较细致可以提供较小的时延,第二层保证了恢复性能和较小的冗余,但是这种方式需要进行两次fec编码,降低了编码效率,同时缺乏灵活性。
在一个数据流中可以根据其内容分成不同类型的数据包,不同类型的数据包具有不同的重要程度。例如,数据包中的i、b、p帧的重要程度如图2a图2b所示。一个图像组中各帧依赖关系,说明一个图像组中不同帧的依赖程度和重要性不同,i帧是最重要的,b、p帧的重要程度较低。因此可以根据数据内容重要性进行不等差错保护。具体考虑传输信源数据具有两个重要等级的情况,将信源数据按上述标准进行划分,并将其按照重要程度重新进行排序,通过改变系统喷泉码编码矩阵的结构,达到对不同内容的不等差错保护。其系统的基本架构如图4所示。经过系统喷泉码的不等差错保护编码后产生的数据如图3所示。
实施例1
本实施例以raptorq系统码为例,系统raptorq码的编码矩阵的结构如图5所示。其中,d表示源数据,c表示中间码,g_ldpc表示ldpc矩阵,i_s、i_h表示单位矩阵,g_enc表示lt编码矩阵,则编码矩阵可以如下表示。
在进行fec编码时,由源数据和图5所示的编码矩阵产生中间码。
再根据编码矩阵中的lt矩阵和得到的中间码产生源数据和恢复数据。其中r表示编码后得到的恢复数据,g_enc′是与g_enc相同生成方式产生的lt矩阵。
采用上述方法对源数据进行编码,不能对源数据进行优先级划分并采用不等差错保护编码,因此需要重新设计编码矩阵a以及lt矩阵g_enc的矩阵结构。以源数据中具有两种不同优先级的数据为例,设优先级分别为优先级1和2,将源数据中的不同优先级的数据区开,对其分配不同的冗余,已达到不等差错保护的效果。
编码过程:
其编码矩阵结构如图6所示。其编码矩阵如公式(6)所示,其中g_enc1与g_enc2是由不同规则产生的编码矩阵,为了保证对重要数据的保护可以提高g_enc1矩阵的度分布。
这样,针对不同重要程度的数据可以产生相应的中间码。
为了达到对不同重要程度数据的不等差错保护,还需要改变lt编码矩阵的结构如图7所示,增加对重要数据保护的冗余数据。其中g_enc1′是与g_enc1具有生成方式相同,g_enc2′与g_enc2的生成方式相同。得到的恢复数据r1只与优先级为1的数据有关,而恢复数据r与优先级1和2的数据均有关。由此增加了重要数据的冗余,提高了其保护强度。其中若由于信道条件的限制,数据总的冗余度有限,生成r1和r2的比例由[g_enc1′0]与[g_enc1″g_enc2′]的行数比确定,可以增加[g_enc1′0]的行数进一步提高优先级为1的数据的保护强度。
译码过程:
由于在经过有损信道后,部分数据包发生了丢失,根据接收到的符号isi,生成恢复矩阵,需要擦除掉丢失符号isi对应的矩阵行,例如,对于矩阵rev_g_enc1,根据接收到的rev_d1和发送端的d1可以得到丢失数据的isi,从而删除g_enc1相应的行。与编码过程类似,进行第一阶段解码时,根据恢复矩阵以及接收到的数据包得到中间码字。
对上面矩阵方程进行初等行变换,得到以下形式:
令
接收到的编码符号总数小于源数据编码符号的个数,并且
接收到的编码符号总数小于源数据编码符号的个数,但是
若
但c2不能求出。
接收到的编码符号总数大于源数据编码符号的个数,
若
但若
接收到的编码符号总数大于等于源数据编码符号的个数,
使用高斯消元法直接对矩阵rev_a进行求解,即解下列线性方程组:
易求得c1、c2。
由上述解码过程的第一阶段可以得到,任何情况下都首先保证c1的正确解出,由于中间码字c1和c2作为在解码第二阶段中恢复出源数据的重要数据,提高c1的解码成功率可以进一步提高源数据正确恢复的概率。
根据得到的中间码字,生成系统码编码符号
若第一阶段没有求出c1、c2,则译码失败,无法译出源符号;若只求出c1,则可以保证优先的源码数据d1可以正确译出;若c1、c2都求出,则利用上式可以得出最终的源码d1和d2。
同时,该方案不仅适用于两个优先级的场景,可扩展到多个优先级的源数据上,其具体过程如下。
编码过程:
首先根据源数据以及源数据的优先级,生成中间码。假设源数据划分成l个数据包,得到:
由式(16)可得到中间码字c1,c2,…,cl。
根据得到的中间码字生成源数据和恢复数据。
整个编码流程如图8所示。将源数据和恢复数据由发送端发送给接收端,由于信道的衰减,部分数据可能会发生丢失,接收端接收到数据后,根据接收到的数据情况进行译码恢复出源数据。
译码过程:
由于部分数据发生丢失,需要根据接收到的符号isi,生成恢复矩阵,相当于擦除掉丢失符号isi对应的矩阵行,形成相应的矩阵,记为rev_g_enc。根据接收数据的数目不同,分不同情况生成中间码字。
对上面矩阵方程进行初等行变换,得到以下形式:
设
设r(i)(1≤i≤l)为接收到并经扩展后第i级符号数,l(i)为编码端每级符号长度,对于i=1:l,计算每级生成矩阵的秩eachrank(i)=min(len(r(i)),sum(l(1:i)));再计算累积矩阵的秩cumrank(i)=min(cumrank(i-1)+eachrank(i),sum(l(1:i))),其中cumrank(1)=eachrank(1)。依次判断cumrank(i)>=sum(l(1:i)):若成立,cumfullrank(i)=1;否则cumfullrank(i)=0。以下根据接收到的每级符号数分情况分别求中间码c1、c2…cl,设置i初始值为l:
若满足cumfullrand(i)==1&&cumfullrank(1:i)>0,使用rfc6330译码方法解出c(1)~c(i)
设
并且易知
c1=c1_temp
…(数学归纳法)
求得c1、c2…ci,而其他ci+1…cl不能求得。
若满足cumfullrand(i)==1,但不满足cumfullrank(1:i)>0,使用高斯消元译码方法解出c(1)~c(i)
设
可以通过高斯消元法解线性方程组:
求得c1、c2…ci,而其他ci+1…cl不能求得。
对于某i值,若不满足cumfullrand(i)==1则相应ci不能解出。直到i==1,上述两个条件都不能满足,则c1、c2…cl全部不能解出,译码失败。
令i=i-1继续循环,即i=l:-1:1,重复以上过程。
整个译码流程如图9所示。
本实施例中的方法,能够有效地节省资源,如果在接收端,人为的根据情况舍弃已经接收的数据(例如b帧)则造成了传输资源的浪费,上述方案从源端解决问题,让不想要的包在传输过程中更大概率丢掉,而更大程度的保护了重要的包。
本实施例中的方法,提供个性化的传输方案。可以根据信道状况、用户体验等设计不等差错保护的方案,使得视频传输更加灵活、细致。同时,尽管发送端的编码方式灵活,接收端都可以根据列表信息正确的恢复出原始的数据。
本实施例中的方法,提供更加灵活的编码矩阵的设计。可以根据实际媒体的应用场景,基于媒体内容进行数据的优先级划分,可以根据实际需求更加灵活的设计fec编码矩阵,达到不等差错保护的效果。
本实施例中的方法,提供更加灵活的译码方式。根据接收到的各优先级数据的数目,可以采用不同的译码算法,在有限的带宽资源下,可以最大程度的恢复优先级高的数据,提高对对优先级较高的数据的保护强度。
以上对本发明的具体实施例进行了描述。需要理解的是,本发明并不局限于上述特定实施方式,本领域技术人员可以在权利要求的范围内做出各种变化或修改,这并不影响本发明的实质内容。在不冲突的情况下,本申请的实施例和实施例中的特征可以任意相互组合。
- 还没有人留言评论。精彩留言会获得点赞!