网络分析工具测试的制作方法
本发明涉及网络分析工具的测试。本发明尤其涉及通过利用网络分析工具分析人工生成的网络数据,来测试网络分析工具的功能。
背景技术:
为测试网络分析工具(例如网络挖掘工具),可以向所述网络分析工具提供表示不同真实或人工网络的图形,并且可以评估分析结果以验证所述工具的功能。在这方面,使用具有类似属性的多个不同图形以获取具有统计意义的结果可能是有益的。
技术实现要素:
根据本发明的第一方面,提供了一种用于测试网络分析工具功能的方法,所述方法包括:接收输入网络数据集,所述输入网络数据集定义第一图形,所述第一图形包括节点和边,所述边表示所述节点之间的连接;将所述节点映射到第一组向量,其中所述映射决定将连接分数分配给向量对的相似度函数;基于所述第一组向量确定第二组向量,其中所述第二组向量中的每个向量代表第二图形的节点;基于所述相似度函数确定连接所述第二图形的节点的边。
在这方面,值得注意的是,本说明书和权利要求书中使用的术语“网络分析工具”同样可以指代软件、硬件或软件和硬件的组合。例如,所述网络分析工具可以是硬件和软件的组合,例如,存储计算机可读指令的计算设备,其接收输入所述网络数据集。
由于所述输入网络数据集描述了网络拓扑(例如计算设备和通信链路),可以分析所述网络拓扑,以推导出能够更深入地了解所述网络拓扑的模式。此外,例如,可以通过随机或系统地修改所述网络拓扑,来分析所述网络拓扑的变更所带来的影响。例如,可以模拟不同变化对所述网络拓扑的影响,或者可以提取关键变更。类似地,可以修改所述网络拓扑,以增加所述网络拓扑对节点或通信链路故障等不利事件的鲁棒性。
然而,本领域技术人员清楚的是,通信网络只是可使用所述网络分析工具进行分析的网络的一个示例。因为原则上,所述网络分析工具可用于分析各种不同的网络。例如,所述网络分析工具可用于分析传输网络、一个或多个链接的网页、生物系统、(自然)语言的语法、零售网络、广告网络或社交网络,且实际上可用于分析任何具有易于通过图形描述的拓扑的网络类型。
此外,本说明书和权利要求书中使用的术语“相似度函数”尤其是指通过连接分数量化节点之间的相似度的函数,其中可以由高连接分数表示的高相似低度可以指示所述节点之间以及连接所述节点的边的高可能性。例如,连接分数可以是实数,其中数字越大表示通过边连接的各个节点的可能性越高。
在所述第一方面的第一种可能的实现方式中,所述方法还包括使用所述网络分析工具来分析包括所述第二图形的节点和边的网络。
因此,所述网络分析工具可以接收所述第二图形作为输入并从所述第二图形推导出一个或多个模式。由于所述第二图形是从所述第一图形推导出的,因此所述第二图形的大小可以与所述第一图形不同,例如,所述第二图形可以包括小于一半、五分之一、十分之一、一百分之一等的所述第一图形节点数量、或者大于两倍、五倍、十倍、一百倍等的所述第一图形节点数量,但仍然具有与所述第一图形相同或类似的属性/模式。例如,可以对所述第一图形的分析结果和所述第二图形的分析结果进行比较,如果所述结果彼此不一致,则可以调整/校正或丢弃所述网络分析工具。可选地,可以执行进一步的测试,以分析所发现偏差的统计意义和或依据。
在所述第一方面的第二种可能的实现方式中,所述第一图形是有向图,确定连接所述第二图形的节点的边包括:对于所述第二图形的每个有序节点对,确定边是否基于第一连接分数将所述节点对的第一节点连接至所述节点对的第二节点;确定所述边是否基于第二连接分数将所述节点对的第二节点连接至所述节点对的第一节点。
因此,所提出的方法可以用于生成具有定向连接的图形,例如,表示数据流量的图形,如表示(无线)通信网络、商品分布等的图形。
在所述第一方面的第三种可能的实现方式中,基于从近似所述第一组向量的多维概率分布中的随机或伪随机绘制向量来确定所述第二组向量中的所有向量。
例如,可以将多维概率分布应用于所述第一组向量。因此,可以保留原始图的结构,同时可以放大或缩小人工图。此外,可能无法从人工图中恢复原始图,从而允许在保持详细网络结构私密性/机密性的同时呈现对公众开放的网络特征。
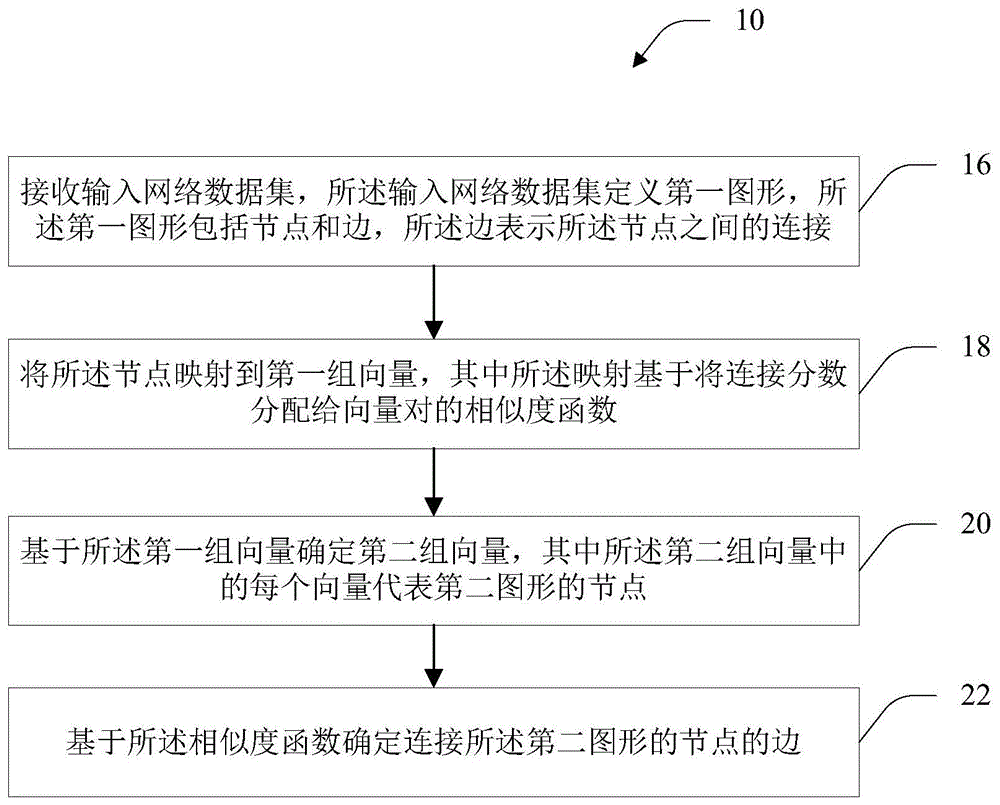
在所述第一方面的第四种可能的实现方式中,通过从所述第一组向量中选择向量来确定所述第二组向量中的所有向量。
例如,所述第二组向量可以包括第一组向量的子集和/或可以复制所述第一组向量以生成具有类似属性的缩小或放大人工图。
在所述第一方面的第五种可能的实现方式中,通过从所述第一组向量中选择向量并将噪声向量添加到所选向量来确定所述第二组向量中的所有向量。
因此,除生成缩小或放大人工图之外,可以随机修改图形属性以提供与所述原始图相比具有类似但随机修改的属性的人工图,从而系统地测试所述网络分析工具结果的重要性。
在所述第一方面的第六种可能的实现方式中,从多维高斯概率分布中随机或伪随机地绘制所述噪声向量。
因此,可以生成多个从统计角度来看类似但不同的人工图,其在原始图周围的区域内提供图形样本。
在所述第一方面的第七种可能的实现方式中,将所述第一图形的节点分配给社区,对应于第一组所选向量的第二图形的节点继承对应于所选向量的节点的相应社区分配。
例如,社区可以表示紧密连接的节点集合,而所述集合彼此更稀疏地连接而不是连接至所述网络的其余部分。
因此,可以生成具有社区的人工图,与所述原始图相比,所述社区具有类似(在统计意义上)但不同的结构。
在所述第一方面的第八种可能的实现方式中,为所述第一图形的边分配权重,连接对应于第一组所选向量的节点的第二图形的边继承连接对应于所选向量的节点的第一图形的边的相应权重。
因此,可以在边权重中对通过所述图形建模的网络的附加特征进行编码并且至少部分保留在所生成的人工图中。例如,所述权重可以对应于通信链路的带宽、传输容量等。
在所述第一方面的第九种可能的实现方式中,如果所述第一图形中未连接对应于所选向量的节点,则在所述第一图形的所有边中为所述第二图形的所述边分配最小权重。
因此,可以保持所述原始图的权重结构,同时生成具有与原始图类似的特征的人工图。
在所述第一方面的第十种可能的实现方式中,基于所述相似度函数确定连接所述第二图形的节点的边还包括将所述第二图形的节点对的连接分数与阈值进行比较。
例如,如果各个节点对的连接分数高于所述阈值,则可以添加所述第二图形的节点之间的边。
在所述第一方面的第十一种可能的实现方式中,确定所述阈值以基于所述相似度函数来区分所述第一图形的顶部e个节点对,所述顶部e个节点对具有来自其余节点对的相对较高的连接分数,其中e是所述第一图形中的边数量。
根据本发明的第二方面,提供了一种计算机可读介质,用于存储指令,当计算机执行所述指令时,使所述计算机执行以下操作:加载输入网络数据集,所述输入网络数据集定义第一图形,所述第一图形包括节点和边,所述边表示所述节点之间的连接;将所述节点映射到第一组向量,其中所述映射基于将连接分数分配给向量对的相似度函数;基于所述第一组向量确定第二组向量,其中所述第二组向量中的每个向量代表第二图形的节点;基于所述相似度函数确定连接所述第二图形的节点的边。
例如,所述计算机可以配备存储所述指令和所述输入网络数据集的存储器,或者所述计算机可以通过网络连接检索所述输入数据集。此外,通过执行存储在所述计算机可读介质上的指令,可以使所述计算机分析网络数据并生成所述输入网络数据集。例如,所述指令可以使所述计算机请求有关计算实体以及网络的计算实体之间的数据连接的数据,并将所述计算实体映射到所述第一图形以及所述第一图形的边的数据连接。
在所述第二方面的第一种可能的实现方式中,所述计算机可读介质还存储指令,当所述计算机执行所述指令时,使所述计算机运行网络分析工具并分析包括所述第二图形的节点和边的网络。
因此,可以从所述第一图形推导出经过修改的第二图形,例如缩小或放大的第二图形,其中推导出的图形具有与所述第一图形类似的属性。因而,可以利用对应于所述第一图形和对应于推导出的第二图形的网络的分析结果比较,来验证所述网络分析工具是否可以在分析具有类似属性的网络时推导出类似的模式。
根据本发明的第二方面,提供了一种网络分析工具测试装置,包括处理器和持久存储指令,当所述处理器执行所述指令时,使所述处理器执行以下操作:加载输入网络数据集,所述输入网络数据集定义第一图形,所述第一图形包括节点和边,所述边表示所述节点之间的连接;将所述节点映射到第一组向量,其中所述映射基于将连接分数分配给向量对的相似度函数;基于所述第一组向量确定第二组向量,其中所述第二组向量中的每个向量代表第二图形的节点;基于所述相似度函数确定连接所述第二图形的节点的边;存储输出网络数据集,所述输出网络数据集定义所述第二图形。
例如,所述装置可以实现根据第一方面所述的方法和所述第一方面的实现方式,并使用所述第二图形来测试所述网络分析工具。
附图说明
图1示出了从输入图生成输出图的过程的流程图;
图2示出了由图1所示的过程使用/生成的示例性输入图和输出图;
图3示出了图1所示的过程在网络挖掘工具中的应用;
图4示出了网络挖掘工具测试装置的框图。
具体实施方式
图1和图2示出了从输入图14生成输出图12的过程10。如步骤16所示,所述过程10从接收定义所述输入图14的输入网络数据集开始。此时,以下表示法用于其余部分:
·g=(n,e)表示包含节点n和边e的图形,
·ni→nj(也称为(ni,nj)∈e)表示节点之间的边ni,nj∈n,
·wij表示边ni→nj的权重。
例如,图2中所示的输入图14可以是具有社区结构的有向加权图g=(n,e),分别如节点(0、1、2、3)和(3、4、5、6、7)周围的圆圈所示。因此,每个节点nj可以具有指定的社区标签ci。但是,需要注意的是,根据所述图形,不能为节点分配社区标签或一组社区标签ci=(ci1,ci2,…)。此外,每条边ni→nj可以具有指定的权重wij。
如步骤18所示,将所述输入图14映射到向量。具体而言,可以通过将所述节点
例如,o.u.ivanov和s.o.bartunov在图像、设计网络和文本分析国际会议上发表并由springer于2015年在《计算机与信息科学通信》系列第542卷第196-207页发表的“有向网络中的学习表示”中提出了专门针对有向图设计的blm,如下所示:
其中,参数
对于softmax近似,可以使用一种称为噪声对比估计(noisecontrastiveestimation,简称nce)的技术,该技术由m.gutmann和a.
此外,样本x来自所述数据分布的后验概率为:
且
如果具有参数集θ的模型pθ(x)旨在应用于所述数据分布,则后验概率成为θ的函数:
然后可以使用逻辑回归来优化数据对噪声的对数似然性:
这近似于pd(x),而没有关于pθ(x)的归一化要求。在blm步骤中,所述归一化常数变为新的函数
考虑到pd对应于所述图形边并选择pn作为pn(i,j)=p(i)pn(j),则新目标变为:
因此,blm中的初始目标可以由可有效优化的nce目标代替。
用于嵌入有向加权图的line方法由j.tang、m.qu、m.wang、m.zhang、j.yan和q.mei于2015年美国计算机协会的《第24届国际万维网会议汇刊》第1067-1077页发表的“line:大规模信息网络嵌入”中提出,该方法基于节点之间所谓的一阶和二阶相似性。所述节点ni和nj的一阶相似性由所述边权重wij表示,并描述所述节点的关系强度:
二阶相似性描述节点nj与其上下文ni之间的关系:
这实际上与blm中的softmax近似一致。
此外,建议分别优化两个相应的目标:
然后可以级联两种模型的嵌入向量
为了降低分母的求和复杂性,可以使用负采样(negativesampling,简称neg)技术,这是一种从语言建模中发现的技术,由t.mikolov、i.sutskever、k.chen、g..s.corrado和j.dean在《2013年神经信息处理系统进展大会汇刊》第3111-3119页发表的“词和短语及其组合性的分布式表征”中进行说明。neg是对nce的简化,它不接近softmax,但仍保留所述嵌入向量的质量。这是通过将术语kpn(x)替换为1并忽略归一化常数来实现的,这将得出:
将其代入
然而,注意,上述相似度函数
继续图2的示例,所述输入图14具有|n|=8个节点和|e|=28条边,其中两条边(0,5)和(2,6)具有权重0.1,所有其它边具有权重10。如上所述,所述输入图14g的重叠社区为a=(0,1,2,3)和b=(3,4,5,6,7),模块度为qg=0.2955(参见m.drobyshevskiy、a.korshunov和d.turdakov于2016年在《系统编程研究所汇刊》第28(6)卷第153-170页发表的“用于具有重叠社区的有向加权图的并行模块度计算”)。可以使用具有以下参数的blm嵌入具有n={0,1,,52,,、e={(0,1),(1,0),(0,2),,(7,6)}、权重标签{w01=10,w10=10,...,w05=0.1,...,w76=10}和社区标签
·epochs=600-时期数,
·vectorsize=30-每个
·nu=25-nce目标中的k,
·numberofthreads=8-用于并行计算,
·eta=0.01-学习率,
·gamma=0.0001-正则化参数。
这可能会产生两个向量
·
z0=2,952403069
·……
·
z7=3,402140617
然后,可以按相似度分数对所述节点对(i,j)∈n×n进行排序。如果嵌入成功,(几乎)所有边(i,j)∈e的分数应该比非边对
继续上述示例,使用根据
·s74=2.35802659085
·s76=2.2996037655
·s12=2.06799817654
·……
·s30=0.639097846078
·……
·s04=-3.12879933734
·s66=-3.16287283326
因此,具有等级|e|的sij中的阈值tg可以计算为tg=0.639097846078。此外,将所述向量
·
·……
·
如步骤20所示,所述嵌入向量
·可以对所述向量
·可以将(高斯)噪声添加到所述向量
·可以将多维概率分布应用于所述向量
由于表示所述输出图12的向量数量对应于所述输出图12h=(m,f)的大小m=|m|,因此可以相对于图2的示例对16个向量进行采样/绘制。
例如,可以从嵌入向量集
继续上述示例,可以从向量集
然后,可以将所选的向量
·
·
·……
·
其中,m={m1,m2,...,m15}。对于每个节点mi∈m,可以将所述向量
·
·……
·
在这方面,应当注意的是,可以基于向量集合进行选择和分配而不是对向量进行级联和解级联,其中每个集合包含与出口边相关的第一向量以及与入口边相关的第二向量。
如步骤22所示,然后可以通过连接按所述相似度函数排序的顶部|f|个节点对,基于所述相似度函数确定所述输出图12h=(m,·)的节点之间的边。例如,可以将所有节点对(i,j)∈m×m的相似度分数计算为softmax
继续上述示例,所述相似度分数zij可以是:
·z00=-1.66303074445
·z01=-1.08735119304
·……
·z15,14=1.49124747694
·z15,15=-1.66303074445
对于具有分数zij≥tg的节点对(i,j)∈m×m,可以通过以下相似度分数将节点mi连接到节点mj:
·z00=-1.66303074445<tg-未连接,
·z01=-1.08735119304<tg-未连接,
·……
·z1514=1.49124747694≥tg-将边15→14添加到f:f=f∪(15,14),
·z1515=-1.66303074445<tg-未连接。
因此,可以确定所述输出图12的节点mi和mj之间的边f={(0,2),(0,4),,(15,14)}。
此外,如果所述输入图14g具有不同的边权重,则可以通过继承所述输入图14g的相应边的边权重,来将权重分配给所述输出图12h的|f|条边中的每一个。另外,对于所述输入图14g中没有相应边的输出图12h的边,可以分配最小边权重,例如,所述输入图14g的所有边的最小权重。即,对于每条边(k,l)∈f,如果相应的节点向量
继续上述示例:
·当
·当
·……
·当
此外,如果所述输入图14g具有社区结构,即社区标签ci,则可以通过继承所述输入图14g的相应社区标签来将社区标签分配给图形h的|m|个节点中的每一个。即,对于每个节点mj∈m,如果相应的节点向量
继续上述示例:
·当
·当
·……
·当
·当
因此,确定了具有|m|=16个节点、|f|=99条边以及两个重叠社区a=(0,5,6,14,15)和b=(1,2,3,4,7,8,9,10,11,12,13,14)的输出图12h=(m,f),其中所述社区内的边权重较高,而所述社区之间的边权重较低。此外,所述输出图12h=(m,f)具有类似的度分布和子图分布,其中3个节点作为所述输入图14g=(n,e)且所述社区具有相对较高的模块度(qh=0.2374)。
总之,生成具有与给定输入图14类似的属性的随机输出图12的上述过程10提供了以下益处:
·从给定图形中自动学习度分布、子图分布和社区结构,并在合成图中再现它们,
·实现任意大小的合成图,
·支持具有社区的有向加权图。
然而,技术人员清楚的是,上述过程10不限于具有社区的定向加权图,而是过程10也可以应用于非定向的图形、具有无权重的边的图形和/或没有社区结构的图形。此外,(定向的)(加权)输入图14(具有社区)原则上可以来自任何图域(社交、移动、生物等)。
如图3所示,所述输出图12可以用于网络挖掘工具的开发和重要性测试,例如,考虑到社区检测。此外,由于所述输出图12可以采用任意大小,因此可以通过测试具有不同大小的多个输出图12的网络挖掘工具来评估网络挖掘工具的可扩展性,这些输出图12都是从相同的输入图14生成的但是大小不同。例如,可以使用输出图12来测试所述网络挖掘工具,所述输出图12具有一半、五分之一、十分之一、一百分之一等的所述输入图14的节点数量、或者两倍、五倍、十倍、一百倍等的所述第一图形所述输入图14的节点数量。可以对通过分析此类输出图12获得的分析结果进行比较,如果所述结果彼此一致(对于数量足够大的输出图12),则可以验证所述网络挖掘工具的可扩展性。
此外,可以实现数据匿名化,这使得可以公开网络特征而不会公开所述网络的确切结构。最后,如果出于规模原因难以分析大型网络,则可以应用所述过程10来创建具有类似属性的此类网络的代表性样本,即尺寸较小的输出图12。
图4示出了网络挖掘工具测试装置24的框图。所述装置24包括处理器26和计算机可读介质28,所述计算机可读介质28用于持久存储指令,当所述处理器26执行所述指令时,将实现上述过程10的部分或所有步骤。
- 还没有人留言评论。精彩留言会获得点赞!