区块链应用中提高数据处理效率的方法与流程
本发明涉及一种区块链应用中提高数据处理效率的方法。
背景技术
区块链技术在数据安全性、去中心化计算、公信度、不可篡改性等相对传统数据处理方法有绝对优势,但是区块链技术的瓶颈在于去中心化所带来的计算速度和效率低下的问题。在实际应用中,商业数据尤其是大数据的应用,高流量高速度是典型标志,目前所有的区块链技术都无法满足商业应用的需求,限制了其在电子币以外的所有应用。区块链提升处理速度是过去几年全世界在努力的方向,然而难度极大,进展迟缓,也导致区块链技术在比特币诞生九年之后仍然没有进展,没有任何落地的商业应用。本方法是一种基于现有的区块链技术,在不触及和改变现有的区块链技术的基础上,配合本地数据服务器,可以在应用层面大幅度提高数据处理速度、容量和效率的方法,同时继承了区块链技术在数据安全性、去中心化计算、公信度、不可篡改性的全部优势。
区块链技术的瓶颈在于去中心化这个核心逻辑所带来的计算速度和效率低下的问题。比特币的处理效率理论是每秒七笔,实际是每秒三到四笔,并且该处理速度由所有用户分享,目前每一笔数据处理通常需要等待十到二十分钟,完全不符合商业使用的需求。而在完全去中心化的基础上对区块链公链进行整体提速,目前没有任何技术可以达成目标。目前常见的方法是通过减少去中心化程度来实现部分提速,比如典型的eos公链,通过将全节点从比特币的超过12000个降低至21个,从而提升处理速度,但是全节点的集中化违反了区块链技术的核心逻辑,让整个公链的公信度大幅度降低,数据被篡改的可能性大增。全节点大幅度降低的区块链系统和传统分布式数据库区别不大,已经无法提供区块链技术所带来的数据优势。区块链技术的发展非常迟缓,因此在商业应用上需要一种独立于区块链技术自身处理速度发展能力的,能在应用层面大幅度提高数据处理速度、容量和效率的方法,同时必须能继承区块链技术全部优势的系统。
技术实现要素:
为解决上述技术问题,本发明设计了一种区块链应用中提高数据处理效率的方法。本方法是一种在区块链或其他类似数据处理系统中在应用层面上提高处理速度、效率和容量的方法。同时采用了不可逆的加密方法确保了主体数据不会公开至公链,公链上的数据也不会被破解或逆向工程解码为原始数据。该方法可以处理已经存储完毕的数据库或者正在存储过程中的数据流。
本发明采用如下技术方案:
一种区块链应用中提高数据处理效率的方法,其包括如下步骤:
一、数据存储过程:
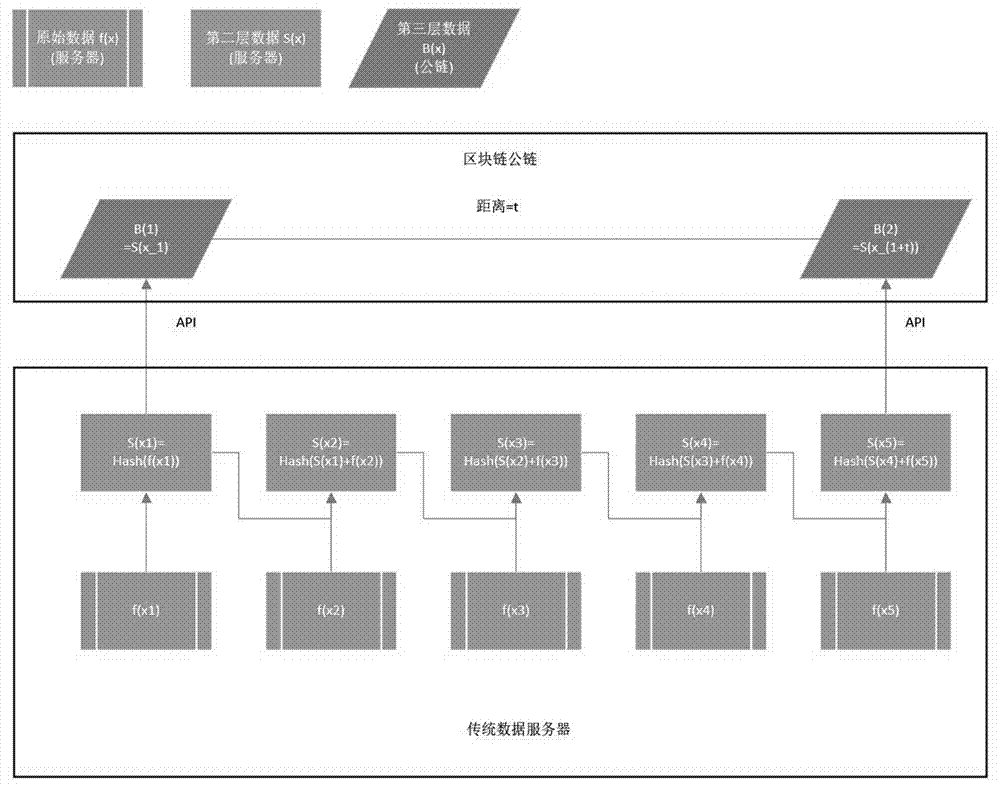
1.首先将原始数据存储按照一定顺序排列,形成f(x1),f(x2),f(x3)…f(xn);
2.然后对原始数据进行处理,处理方式用hash()统一指代;
3.首先对第一条数据f(x1)进行hash()获得s(x1)=hash(f(x1));
4.然后对后续数据进行处理,s(xn)=hash(s(x(n-1))+f(xn));s(x(n-1))+f(xn)指代的是两条数据合并;
5.此时获得数据列s(x1),s(x2),s(x3)…s(xn);
6.针对s(xn)设定一个数据选择规律,选择固定间隔t作为数据挑选方式,则将挑选出数据s(x1),s(x(1+t)),s(x(1+2t))…,将挑选出的数据上传到区块链中;
7.在这个过程中设定数据b(1)=s(x1),b(2)=s(x(1+t)),b(3)=s(x(1+2t))…b(n)=s(x(1+(n-1)t));
二、数据核对过程:
1.需要核对数据f(xn)的真实性时,先找到这条数据对应的s(xn),然后定位离这条数据最近的前后各一条的已经上传的数据为b(x’),b(x’+1);
2.获取其对应的b(x’),b(x’+1)的数值;
3.比对确认s(x’)=b(x’),s(x’+t)=b(x’+1)是否满足;
4.满足的前提下从f(x’)开始,在f(x’+t)停止,在f(x’)…f(xn)…f(x’+t)的区间内重新进行计算s(x’)…s(x’+t),得到数据记为s’(x’)…s’(x’+t);
5.对照s’(x’+t)与b(x’+1)是否一致,如果一致,则f(x’)到f(x’+t)中的数据没有被篡改,真实有效;
6.对照s’(x’+t)与b(x’+1)是否一致,如果不一致,则f(x’)到f(x’+t)中的数据至少有一条被篡改,则进入下一步核对步骤;
7.对照s’(x’+1)是否与s(x’+1)一致,如果一致则对照s’(x’+2)是否与s(x’+2)一致,依此类推直至找到s’(x’+y)不等于s(x’+y),(其中y<=t),此时数据f(x’+y)是数据篡改点,所有位于f(x’+y)到f(x’+t)之间的数据没有公信度;
8.如果f(xn)不位于f(x’+y)到f(x’+t)之间,则f(xn)为可信数据,未被篡改;
9.如果f(xn)位于f(x’+y)到f(x’+t)之间,则f(xn)是不可信数据,不可采用;
10.如果比对确认s(x’)=b(x’),s(x’+t)=b(x’+1)并不满足,则需要扩大数据对比范围,并重复上述步骤,直到定位到首个发生错误的数据点,以及其所影响的数据范围区间;
三、增加链上数据处理速度和容量:
通过扩大上传到区块链中的数据间的t的平均值,减小上传到区块链中的总数据量,在不变动区块链本身属性的情况下,就可以简单的在应用层面增加处理速度和容量。
作为优选,所述数据存储过程的步骤2中,对原始数据进行处理,处理方式可以是哈希算法、其他任意的函数或其他加密算法。
作为优选,所述数据存储过程的步骤4中,两条数据合并的具体方式可以是加法、叠加、减法或任意的数据合并方式,由具体使用中决定。
作为优选,所述数据存储过程的步骤6中,将挑选出的数据上传到区块链中可以通过api或其他方式。
本发明的有益效果是:
1、通过减少上传到区块链或者或其他类似数据处理系统中的数据量来增加应用层面的数据处理速度、效率、容量和记录成本,将部分工作量转入非分布式的服务器本地处理,并可随时通过具体需求来调配数据量的大小;
2、本方法继承了区块链技术在数据安全性、公信度、不可篡改性的优势;
3、本方法在数据核对中只需要对f(x’)到f(x’+t)中的数据进行计算核对,运算量小;
4、本方法可以找到被篡改的数据源头。
说明书附图
图1是本发明的一种流程图;
具体实施方式
下面通过具体实施例,并结合附图,对本发明的技术方案作进一步的具体描述:
实施例:如附图1所示,一种区块链应用中提高数据处理效率的方法,其包括如下步骤:
一、数据存储过程:
1、首先将原始数据存储按照一定顺序排列,形成f(x1),f(x2),f(x3)…f(xn);
2、然后对原始数据进行处理,处理方式用hash()统一指代;
3、首先对第一条数据f(x1)进行hash()获得s(x1)=hash(f(x1));
4、然后对后续数据进行处理,s(xn)=hash(s(x(n-1))+f(xn));s(x(n-1))+f(xn)指代的是两条数据合并;
5、此时获得数据列s(x1),s(x2),s(x3)…s(xn);
6、针对s(xn)设定一个数据选择规律,选择固定间隔t作为数据挑选方式,则将挑选出数据s(x1),s(x(1+t)),s(x(1+2t))…,将挑选出的数据上传到区块链中;
7、在这个过程中设定数据b(1)=s(x1),b(2)=s(x(1+t)),b(3)=s(x(1+2t))…b(n)=s(x(1+(n-1)t));
二、数据核对过程:
1、需要核对数据f(xn)的真实性时,先找到这条数据对应的s(xn),然后定位离这条数据最近的前后各一条的已经上传的数据为b(x’),b(x’+1);
2、获取其对应的b(x’),b(x’+1)的数值;
3、比对确认s(x’)=b(x’),s(x’+t)=b(x’+1)是否满足;
4、满足的前提下从f(x’)开始,在f(x’+t)停止,在f(x’)…f(xn)…f(x’+t)的区间内重新进行计算s(x’)…s(x’+t),得到数据记为s’(x’)…s’(x’+t);
5、对照s’(x’+t)与b(x’+1)是否一致,如果一致,则f(x’)到f(x’+t)中的数据没有被篡改,真实有效;
6、对照s’(x’+t)与b(x’+1)是否一致,如果不一致,则f(x’)到f(x’+t)中的数据至少有一条被篡改,则进入下一步核对步骤;
7、对照s’(x’+1)是否与s(x’+1)一致,如果一致则对照s’(x’+2)是否与s(x’+2)一致,依此类推直至找到s’(x’+y)不等于s(x’+y),(其中y<=t),此时数据f(x’+y)是数据篡改点,所有位于f(x’+y)到f(x’+t)之间的数据没有公信度;
8、如果f(xn)不位于f(x’+y)到f(x’+t)之间,则f(xn)为可信数据,未被篡改;
9、如果f(xn)位于f(x’+y)到f(x’+t)之间,则f(xn)是不可信数据,不可采用;
10、如果比对确认s(x’)=b(x’),s(x’+t)=b(x’+1)并不满足,则需要扩大数据对比范围,并重复上述步骤,直到定位到首个发生错误的数据点,以及其所影响的数据范围区间;
三、增加链上数据处理速度和容量:
通过扩大上传到区块链中的数据间的t的平均值,减小上传到区块链中的总数据量,在不变动区块链本身属性的情况下,就可以简单的在应用层面增加处理速度和容量。比如,采用固定间隔上传的方式,原来t=2,则每隔两个数据上传;如果需要将处理速度翻倍,则t=4,则每隔四个数据上传;上传的数据量减半,在区域链原生处理能力不变的情况下,在应用层面,处理速度提高了一倍。
数据存储过程的步骤2中,对原始数据进行处理,处理方式是哈希算法。
数据存储过程的步骤4中,两条数据合并的具体方式是加法数据合并方式。
数据存储过程的步骤6中,通过api将挑选出的数据上传到区块链中。
以上所述的实施例只是本发明的一种较佳的方案,并非对本发明作任何形式上的限制,在不超出权利要求所记载的技术方案的前提下还有其它的变体及改型。
- 还没有人留言评论。精彩留言会获得点赞!