一种基于FPGA的RoCE网卡数据传输方法及网卡与流程
本发明涉及,更具体地说,涉及一种基于fpga的roce网卡数据传输方法、roce网卡及内存系统。
背景技术
rdma(remotedirectmemoryaccess,远程直接数据存取)是一种新的内存访问技术,允许在两台服务器的内存之间直接转移数据,而无需任何一台服务器的cpu参与,因此可实现更高效的通信。rdma传输会避开系统内核的tcp/ip堆栈以及网卡驱动,直接将数据传送到目标服务器上的进程工作内存中。由于无需将数据在接收和发送服务器的内存中反复拷贝,并且将原本由软件实现的传输协议栈用网卡的硬件实现,大大降低了服务器的cpu、i/o工作负载,有效减少了数据通信延时。
ibta组织于2000年推出了infiniband网络协议,率先实现了对rdma功能的支持。2010年ibta组织在infiniband协议的基础上推出了初始的roce规范,即rdmaoverconvergedethernet,可以利用现有的以太网实现rdma功能。但它在链路层之上采用的仍旧是infiniband协议规范,无法通过基于ip的路由器进行路由,将该协议的应用范围限制在了单个子网内。随着虚拟化、云计算和分散式大数据存储库的发展,网络通信的带宽和延时瓶颈不再局限于单个子网络,而是扩展到整个数据中心。为了适应这一技术发展趋势,ibta于2014年推出了增强版的roce规范,即rocev2。rocev2规范用ip报头和udp报头替代了rocev1中的infiniband网络层。这样,就可以在基于ip的传统路由器之间路由roce报文,大大扩展了roce的应用规模。
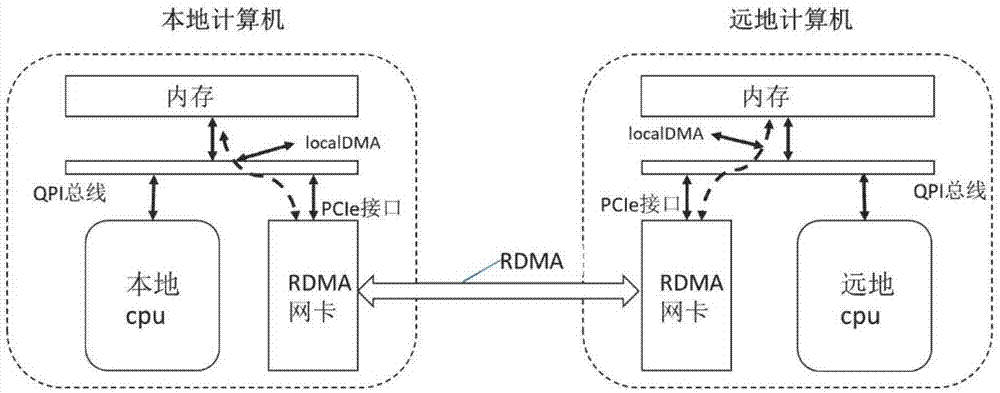
参见图1,为现有技术中的本地计算机与远地计算机数据传输示意图,从该图中可以看出,目前支持roce的网卡均采用pcie接口接入内存系统,在网卡和主机通信时采用直接内存访问(localdma)的方式。这种采用pcie总线接口将网卡接入系统,报文需要从pcie总线转换至其它前端总线类型,如intel的qpi/upi总线,转换后后才能进入内存系统,报文传输延时较大。
因此,如何减少数据在本地cpu和网卡之间的传输延时,是本领域技术人员需要解决的问题。
技术实现要素:
本发明的目的在于提供一种基于fpga的roce网卡数据传输方法、roce网卡及内存系统,以实现减少数据在本地cpu和网卡之间的传输延时。
为实现上述目的,本发明实施例提供了如下技术方案:
一种基于fpga的roce网卡数据传输方法,所述roce网卡具有qpi接口;所述数据传输方法包括:
本地roce网卡将本地cpu发送的qpi协议的第一信息,转换为ib协议的第一信息,并发送至远地roce网卡;
将远地roce网卡发送的ib协议的第二信息转换为qpi协议的第二信息,并发送至本地cpu。
其中,在数据传输过程中,将本地内存数据及数据状态保存在本地roce网卡的本地cache中,或者保存在远地roce网卡的远地cache中,本地roce网卡与远端roce网卡之间通过cache一致性协议进行数据传输。
其中,所述将本地内存数据及数据状态保存在本地roce网卡的本地cache中,或者保存在远地roce网卡的远地cache,包括:
判断本地计算机对本地cache的访问频率是否大于远地计算机对远地cache的访问频率;
若是,则将本地内存数据及数据状态保存在本地roce网卡的本地cache中;若否,则将本地内存数据及数据状态保存在远地roce网卡的远地cache。
一种基于fpga的roce网卡,包括协议转换模块;
所述协议转换模块,用于将本地cpu通过qpi接口发送的qpi协议的第一信息,转换为ib协议的第一信息,并发送至远地roce网卡;将远地roce网卡发送的ib协议的第二信息转换为qpi协议的第二信息,并发送至本地cpu。
其中,本方案还包括:本地cache和远地cache;
其中,在数据传输过程中,将本地内存数据及数据状态保存在本地roce网卡的本地cache中,或者保存在远地roce网卡的远地cache中,本地roce网卡与远端roce网卡之间通过cache一致性协议进行数据传输。
其中,本方案还包括:
qpi物理层,qpi链路层,qpi协议层,infiniband传输协议模块,网络层模块和以太网链路层和物理层模块。
其中,若所述roce网卡采用rocev2规范,所述网络层模块实现udp和ip逻辑;若所述roce网卡采用rocev1规范,则所述网络层模块实现ib网络层逻辑。
一种基于fpga的roce网卡的内存系统,包括:
内存,本地cpu和本地roce网卡;其中,所述roce网卡具有qpi接口,通过qpi总线与所述本地cpu和所述内存相连;
所述本地roce网卡,用于将本地cpu发送的qpi协议的第一信息,转换为ib协议的第一信息,并发送至远地roce网卡;将远地roce网卡发送的ib协议的第二信息转换为qpi协议的第二信息,并发送至本地cpu。
其中,所述本地roce网卡包括:本地cache和远地cache;在数据传输过程中,将本地内存数据及数据状态保存在本地roce网卡的本地cache中,或者保存在远地roce网卡的远地cache中,本地roce网卡与远端roce网卡之间通过cache一致性协议进行数据传输。
其中,所述本地cpu还用于:判断本地计算机对本地cache的访问频率是否大于远地计算机对远地cache的访问频率;若是,则将本地内存数据及数据状态保存在本地roce网卡的本地cache中;若否,则将本地内存数据及数据状态保存在远地roce网卡的远地cache。
通过以上方案可知,本发明实施例提供的一种基于fpga的roce网卡数据传输方法,所述roce网卡具有qpi接口;所述数据传输方法包括:本地roce网卡将本地cpu发送的qpi协议的第一信息,转换为ib协议的第一信息,并发送至远地roce网卡;将远地roce网卡发送的ib协议的第二信息转换为qpi协议的第二信息,并发送至本地cpu。
可见,由于本方案中的这种基于fpga的roce网卡,具有qpi接口,便可通过该接口获取本地cpu发送的qpi协议的信息,转换为ib协议的信息之后便可直接发送至远地roce网卡;同样的,再接收到远地roce网卡发送的ib协议的信息之后便直接转换为qpi协议的信息并发送至本地cpu,从而使得roce网卡和本地cpu之间的传输延时大大缩短,提升传输效率。
本发明还公开了一种基于fpga的roce网卡及内存系统,同样能实现上述技术效果。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
图1为现有技术中的本地计算机与远地计算机数据传输示意图;
图2为现有技术中的roce网卡具体结构示意图;
图3为本发明实施例公开的一种基于fpga的roce网卡结构示意图;
图4为本发明实施例公开的本地计算机与远地计算机数据传输示意图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
本发明实施例公开了一种基于fpga的roce网卡数据传输方法、roce网卡及内存系统,以实现减少数据在本地cpu和网卡之间的传输延时。
本发明实施例提供一种基于fpga的roce网卡,该roce网卡具体包括:协议转换模块;
所述协议转换模块,用于将本地cpu通过qpi接口发送的qpi协议的第一信息,转换为ib协议的第一信息,并发送至远地roce网卡;将远地roce网卡发送的ib协议的第二信息转换为qpi协议的第二信息,并发送至本地cpu。
具体的,在本实施例中,roce网卡为使用现场可编程门阵列fpga实现带qpi接口的roce网卡,并且roce网卡和cpu之间通过qpi进行通信;roce网卡中的协议转换模块用于实现infiniband协议和qpi总线协议的转换,具体来说,协议转换模块主要将本地cpu通过发送的qpi协议的信息,转换为ib协议的信息发送至远地roce网卡;将远地roce网卡发送的ib协议的信息转换为qpi协议的信息,发送至本地cpu。这种传输方法与现有技术相比,避免了将ib协议的信息转换为pcie协议的信息的过程,从而减少了传输延时。
参见图2,为现有技术中的roce网卡具体结构示意图,可以看出,该roce网卡中是通过pcie总线与cpu通信;参见图3,本实施例提供的一种roce网卡具体结构示意图,可以理解的是,该roce网卡处理包括进行协议转换的协议转换模块100之外,还包括实现qpi总线协议模块和roce功能模块,具体包括:
qpi物理层01,qpi链路层02,qpi协议层03,协议转换模块04,本地cache05,远地cache06,infiniband传输协议模块07,网络层模块08和以太网链路层和物理层模块09,其每个模块所实现的功能如下所示:
qpi物理层01,该模块按照qpi总线协议实现qpi总线的物理层逻辑和电气特性。
qpi链路层02,该模块实现qpi总线的链路层逻辑。
qpi协议层03,该模块实现cache一致性和非cache一致性协议,根据rdma的应用场景可做适当裁剪。
协议转换模块04,该模块用于infiniband协议和qpi总线协议的转换。
本地cache05,该模块为本地计算机cache数据副本的存储空间,保存本地计算机特定内存空间的cache数据和数据状态,在系统中具有和本地cpucache同等的地位。
远地cache06,该模块为远地计算机cache数据副本的存储空间,保存远地计算机特定内存空间的cache数据和数据状态,在系统中具有和远地cpucache同等的地位。
infiniband传输协议模块07,该模块是实现rdma技术的基础协议层逻辑。
网络层模块08,当采用rocev2时,该模块实现udp和ip逻辑,如果采用rocev1则实现ib网络层逻辑。
以太网链路层和物理层模块09,该模块实现以太网链路层和物理层逻辑。
其中,若roce网卡采用rocev2规范,网络层模块实现udp和ip逻辑;若roce网卡采用rocev1规范,则网络层模块实现ib网络层逻辑。具体来说,根据it系统搭建决策,来决定fpga实现哪种版本,从而通过fpga烧录不同的逻辑实现rocev1或rocev2。
基于上述任意实施例,在数据传输过程中,将本地内存数据及数据状态保存在本地roce网卡的本地cache中,或者保存在远地roce网卡的远地cache中,本地roce网卡与远端roce网卡之间通过cache一致性协议进行数据传输。
具体的,现有技术中的pcie协议本身不能保证系统cache一致性,远程计算机与本地计算机只能进行基于非cache一致性的内存数据交互。而由于fpga内部具有维护系统cache一致性的功能,本地计算机和远地计算机可进行基于cache的数据交换,提升了通信效率,提升系统灵活性。参见图4,为本实施例提供的本地计算机与远地计算机数据传输示意图;可以看出,cpu和网卡之间通过qpi总线直接通信,同时远地计算机可以和本地计算机实现基于cache一致性的数据交互。需要说明的是,如果远地计算机和本地计算机需要进行基于cache的交互,首先需要远地计算机在本地计算机中注册一个特殊内存区域,该内存区在本地或者远地fpga中保存一个cache副本和数据使用状态记录。数据保存在本地还是远地由软件配置,适用于不同的使用模型。
需要说明的是,通过cache一致性协议进行数据传输的具体传输方式并不具体限定,在本实施例中仅列举一种实现方式。在本实施例中,若本地计算机对本地cache的访问频率高于远地计算机对远地cache的访问频率,则将本地内存数据及数据状态保存在本地roce网卡的本地cache中,否则,保存在远地roce网卡的远地cache中。本实施例中的本地内存数据是指本地计算机和远地计算机的数据处理对象,本地内存数据的数据状态可以包括:独占态e,此时数据只有当前一个副本;共享态s,此时数据可能有多于一个副本在不同cache中;脏态m,此时数据只有当前一个副本且和内存中的数据不一致;无效态i,当前数据副本无效。
可以理解的是,本地计算机与远地计算机进行数据交互时,本地计算机中的本地cpu发往本地roce网卡的信息,均为qpi协议的信息,均需要通过本地roce网卡中的qpi物理层、qpi链路层、qpi协议层到达协议转换模块,通过协议转换模块转换为ib协议,之后在通过ib传输协议模块、网络层模块、以太网链路层和物理层模块发送到以太网,路由至远地计算机,远地计算机中的远地roce网卡接收到ib协议的信息后,再通过以太网链路层和物理层模块、网络层模块、ib传输协议模块传输至远地roce网卡的协议转换模块,经过协议转换后在通过qpi协议层、qpi链路层和qpi物理层之后发送至远地cpu,所有的数据交互均为上述过程,因此在描述基于cache一致性协议进行数据传输时,便不具体说明。
一、基于cache一致性协议进行数据传输时,本地内存数据及数据状态保存在本地roce网卡的本地cache中:
特殊内存注册完成后,远地cpu发送针对该内存地址的qpi请求(非cache一致性请求)到远地fpga,远地fpga将qpi请求转换为ib协议后发送至本地fpga,本地fpga通过协议转换模块将远地计算机发送的数据请求转换为qpi协议(cache一致性请求),并发往本地cpu。
本地cpu接收到数据请求后回传响应报文,协议层解析出响应报文中包含的数据并发往本地cache模块,本地fpga的本地cache模块将保存该数据副本及数据状态,该数据状态根据远地计算机的cpu发出的请求类型决定,如果远地fpga请求独占该数据副本,此时本地cache中的数据为独占态;远地请求共享该数据副本,对应的数据状态为共享态。
进而,如果远地计算机的请求是读操作,本地fpga的协议转换模块将从本地cache模块中读出数据并以ib协议发往远地fpga。对于写操作,本地fpga完成数据操作后只以ib报文的形式发送写完成响应到远地fpga。远地fpga接收到该ib响应报文后交由协议转换模块转换为qpi报文,并返回给远地cpu。
之后,远地计算机的数据请求都遵循这一路径,从远地fpga发送往本地fpga。本地fpga的协议转换模块接收到远地的ib协议请求后,首先判断本地fpga中的本地cache数据是否有效。如果数据处于独占态或脏态,则可以对数据进行读或写操作。处于独占态时写操作完成后本地fpga协议转换模块需要向本地fpga的qpi协议层模块发送qpi消息报文通知本地cpu并将数据状态改为脏态。如果通过查询发现本地cache数据为共享态,则只能读数据。如果本地cache数据为无效状态,则本地fpga的协议转换模块需要通过qpi协议层向本地cpu发起数据请求重新获得数据,之后再根据缓存的远地请求完成数据操作。
本地协议转换模块完成数据读写操作后都需要向远地fpga发送ib响应报文。当本地cpu要改变cache数据状态时,会发送qpi协议通知本地fpga,本地fpga的qpi协议层模块负责返回qpi响应报文并更改cache数据状态。该模型适合于本地计算机对该cache空间读写较频繁的情景。
二、基于cache一致性协议进行数据传输时,本地内存数据及数据状态保存在远地roce网卡的远地cache中:
特殊内存注册完成后远地cpu发送针对该内存地址的qpi请求(非cache一致性请求)到远地fpga,转换为ib协议后通过以太网路由至本地fpga,本地fpga通过协议转换模块将远地计算机发送的数据请求转换为qpi协议(cache一致性请求),并发往本地cpu。
本地cpu回传响应报文,本地fpga的qpi协议层解析报文后直接将报文发送至协议转换模块,将qpi报文转换为ib报文,连同响应数据也通过ib报文的形式直接发往远地fpga。远地计算机将报文中包含的响应数据,保存在远地fpga的远地cache模块,数据状态与上文中保存在本地roce网卡的本地cache中情况相同。
远地fpga的协议转换模块根据远地cpu的初始请求对远地cache数据进行操作,并将操作结果以qpi响应报文的形式发往qpi协议层模块,qpi协议层模块遵循qpi协议响应远地cpu的初始qpi请求。此后,远地计算机的qpi数据请求被远地fpga的qpi协议层接收后,首先由协议转换模块判断远地fpga中的远地cache数据是否有效。如果数据处于独占态或脏态,则远地fpga的协议转换模块可以对数据进行读或写操作,并发送qpi完成报文到远地fpga的qpi协议层。处于独占态时写操作完成后协议转换模块需发送ib消息报文通知本地cpu并将数据状态改为脏态。
如果通过查询发现远地cache数据为共享态,则只能读数据。如果远地cache数据为无效状态,则需要远地协议转换模块发送ib报文向本地cpu请求重新获得数据。本地fpga接收到本地cpu的qpi响应报文后将其转换为ib报文发往远地fpga,远地fpga的协议转换模块接收到该ib响应报文后重新载入数据,完成相应操作并通知qpi协议层。
当本地cpu要改变cache数据状态时会发送qpi协议报文通知本地fpga,本地fpga将该qpi协议转换为ib协议发往远端,通知远地计算机cache状态改变。远地fpga的协议转换模块接收到该通知后更改数据状态并以ib报文的形式返回响应报文给本地fpga。本地fpga最终将该响应返回至本地cpu。该模型适合于远地计算机对该cache空间读写较频繁的情景。
可以理解的是,在上述两种情况中,修改fpga内部cache的数据状态,同时cpu内部cache数据状态也会有相应改变,状态转移策略遵循qpi协议。
综上可以看出,本方案通过fpga实现基于qpi接口的roce网卡,使得网卡和本地系统内存数据交换延时大大缩短,同时维持两个cache空间,便于进程在不同处理器间的交互访问。
下面对本发明实施例提供的内存系统进行介绍,下文描述的内存系统与上文描述的roce网卡可以相互参照。
本发明实施例提供一种基于fpga的roce网卡的内存系统,包括:
内存,本地cpu和本地roce网卡;其中,所述roce网卡具有qpi接口,通过qpi总线与所述本地cpu和所述内存相连;
所述本地roce网卡,用于将本地cpu发送的qpi协议的第一信息,转换为ib协议的第一信息,并发送至远地roce网卡;将远地roce网卡发送的ib协议的第二信息转换为qpi协议的第二信息,并发送至本地cpu。
其中,所述本地roce网卡包括:本地cache和远地cache;在数据传输过程中,将本地内存数据及数据状态保存在本地roce网卡的本地cache中,或者保存在远地roce网卡的远地cache中,本地roce网卡与远端roce网卡之间通过cache一致性协议进行数据传输。
其中,所述本地cpu还用于:判断本地计算机对本地cache的访问频率是否大于远地计算机对远地cache的访问频率;若是,则将本地内存数据及数据状态保存在本地roce网卡的本地cache中;若否,则将本地内存数据及数据状态保存在远地roce网卡的远地cache。
下面对本发明实施例提供的roce网卡数据传输方法进行介绍,下文描述的roce网卡数据传输方法与上文描述的roce网卡可以相互参照。
本发明实施例提供一种基于fpga的roce网卡数据传输方法,所述roce网卡具有qpi接口;所述数据传输方法包括:
本地roce网卡将本地cpu发送的qpi协议的第一信息,转换为ib协议的第一信息,并发送至远地roce网卡;
将远地roce网卡发送的ib协议的第二信息转换为qpi协议的第二信息,并发送至本地cpu。
可以理解的是,本方案中的数据传输方法,并不具体限定本地roce网卡的执行顺序,也就是说,本地roce网卡将qpi协议的第一信息转换为ib协议的第一信息发送至远地roce网卡,与本地roce网卡将ib协议的第二信息转换为qpi协议的第二信息发送至本地cpu的执行顺序,并不具体限定,可以先执行前者再执行后者,或者先执行后者,在执行前者。
其中,在数据传输过程中,将本地内存数据及数据状态保存在本地roce网卡的本地cache中,或者保存在远地roce网卡的远地cache中,本地roce网卡与远端roce网卡之间通过cache一致性协议进行数据传输。
其中,所述将本地内存数据及数据状态保存在本地roce网卡的本地cache中,或者保存在远地roce网卡的远地cache,包括:
判断本地计算机对本地cache的访问频率是否大于远地计算机对远地cache的访问频率;
若是,则将本地内存数据及数据状态保存在本地roce网卡的本地cache中;若否,则将本地内存数据及数据状态保存在远地roce网卡的远地cache。
综上可以看出,本方案通过在fpga中实现qpi总线协议模块和roce功能模块,构成一个基于qpi总线接口的rdma网卡,使得网卡和内存系统的通信延时大大降低。且由于fpga内部具有维护系统cache一致性的功能,本地计算机和远地计算机可进行基于cache的数据交换,提升了通信效率。
本说明书中各个实施例采用递进的方式描述,每个实施例重点说明的都是与其他实施例的不同之处,各个实施例之间相同相似部分互相参见即可。
对所公开的实施例的上述说明,使本领域专业技术人员能够实现或使用本发明。对这些实施例的多种修改对本领域的专业技术人员来说将是显而易见的,本文中所定义的一般原理可以在不脱离本发明的精神或范围的情况下,在其它实施例中实现。因此,本发明将不会被限制于本文所示的这些实施例,而是要符合与本文所公开的原理和新颖特点相一致的最宽的范围。
- 还没有人留言评论。精彩留言会获得点赞!