基于多目标遗传算法的车联网云系统资源分配方法与流程
本发明属于云计算技术领域,涉及一种车联网云系统资源分配方法,特别是涉及一种基于多目标遗传算法的车联网云系统资源分配方法。
背景技术:
智能交通系统是未来交通运输体系的重要发展方向之一,车联网作为物联网技术应用于智能交通领域的具体形式,对于我国交通系统建设和国家经济发展有着重要意义。随着全球汽车产业的高速发展,出现了许多新兴车载应用,例如车载多媒体娱乐、车载社交网络以及基于位置的服务等,这些应用需要复杂的计算能力、充足的带宽资源以及大量的存储空间。然而,由于小型化、低成本的硬件系统,单个车辆的资源有限。云计算能够为用户提供所需的资源,使用户能够按需动态获取计算能力、存储空间和信息服务。车联网与云计算的融合形成车联网云系统,包括车辆云、路边云和中心云,车辆云由一组车辆组成,车辆之间能够进行资源共享,路边云具有少量资源,通常作为资源管理者,中心云由服务器集群组成,具有大量资源。车联网云系统能够提高资源利用率,降低基础设施成本,提高驾驶安全性等。
当单个车辆的资源无法满足应用请求时,车联网云系统需要为应用请求分配资源。当应用请求到来时,资源管理者需要根据应用请求的资源需求、响应时间和车辆云中的资源等,决定将车辆云、路边云或中心云的资源分配给应用请求。一个理想的车联网云系统资源分配方法应该能够满足应用请求的资源、响应时间要求和能耗要求,具有快速收敛、低阻塞率、低成本的特点。由于阻塞率受到应用请求资源、车辆资源、车辆之间连接的稳定性和响应时间等因素的影响,而现有的车联网云系统资源分配方法通常只考虑了应用请求的资源和响应时间,因此具有相对较高的阻塞率。
l.hou等人在文献“acontinuous-timemarkovdecisionprocess-basedresourceallocationschemeinvehicularcloudformobilevideoservices”(computercommunications,2018,vol.118,pp.140-147)中,公开了一种基于连续时间马尔可夫模型的车联网云系统资源分配方法,该方法首先建立了连续时间马尔可夫模型,然后采用迭代算法求解提出的连续时间马尔可夫模型,经过多次迭代后,能够得到最终的资源分配结果。该方法在建立连续时间马尔可夫模型时,考虑了车辆资源和社交关系对资源分配结果的影响,在一定程度上降低了应用请求的阻塞率,但是其存在的不足之处是:在建立连续时间马尔可夫模型时,忽略了由车辆移动性导致的车辆之间连接频繁中断对应用请求阻塞率的影响,使得阻塞率仍然较高。
多目标遗传算法是一种基于种群搜索方式的全局优化算法,可以处理各种类型的多目标优化模型,能够有效地处理传统优化算法难以解决的复杂问题,具有较高的鲁棒性、全局优化、并行搜索和快速收敛的特点。在求解多目标优化模型时,首先对种群进行初始化,然后对初始种群进行交叉和变异,通过迭代寻找问题的最优解。
利用多目标遗传算法的全局优化、快速收敛的特点,通过建立合适的多目标优化模型,能够有效地解决车联网云系统资源分配中阻塞率较高的问题。
技术实现要素:
本发明的目的在于克服上述现有技术的不足,提出一种基于多目标遗传算法的车联网云系统资源分配方法,在满足成本要求的情况下,降低应用请求的阻塞率。
为实现上述目的,本发明采取的技术方案,包括如下步骤:
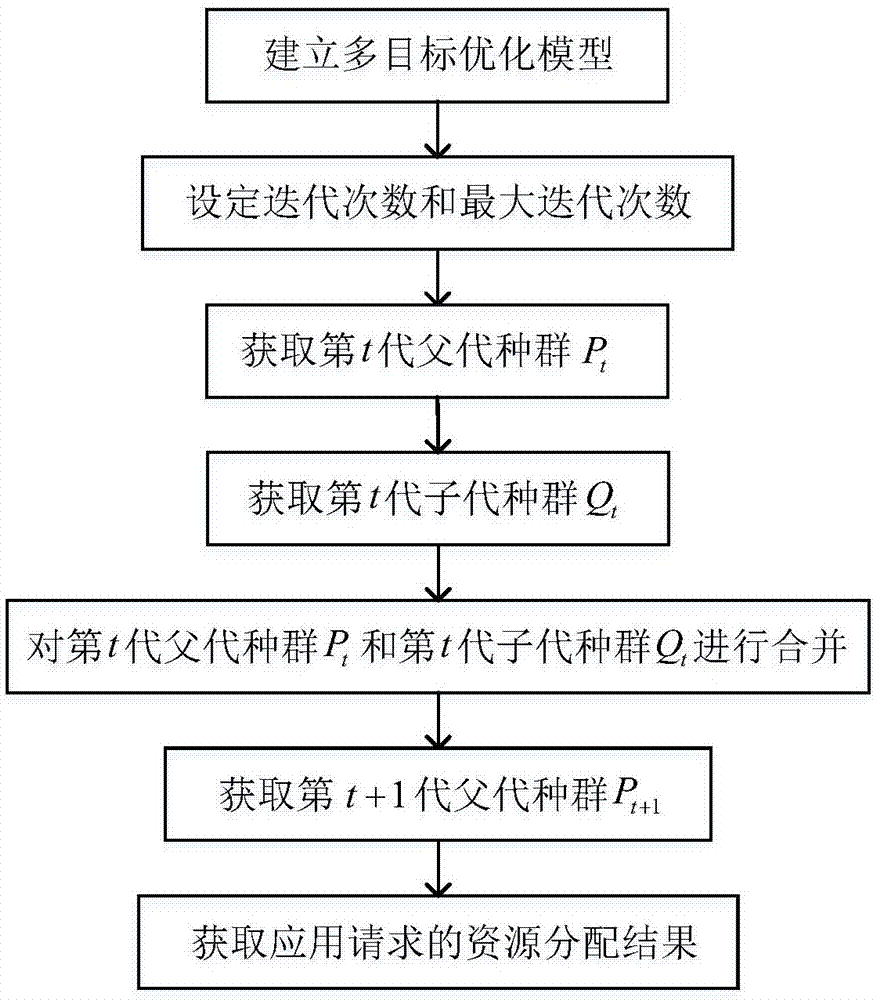
(1)建立多目标优化模型:
建立包括目标函数和约束条件的多目标优化模型,其中目标函数包括最小化阻塞率f1和最小化成本f2,约束条件包括应用请求资源约束g1、每辆车的资源约束g2、车辆云总资源约束g3、车辆之间传输时间约束g4、车辆云处理的响应时间约束g5、中心云处理的响应时间约束g6和资源大小约束g7;
(2)设定迭代次数和最大迭代次数:
设迭代次数为t,并初始化t=0,设最大迭代次数为tmax;
(3)获取第t代父代种群pt:
(3a)设车辆数量为m,m≥2,计算每辆车的匹配因子mf1,…,mfj,…,mfm,mfj表示车辆j的匹配因子:
mfj=γ1ψj+γ2cj+γ3dj
其中,γi为权重系数,
(3b)设应用请求数量为n,n≥2,应用请求的一种车联网云系统资源分配结果用一个染色体表示,第t代父代种群pt中包含的染色体数量为npop,npop∈[40,100]且为偶数,每个染色体有n个基因位e1,…,ei,…,en,ei∈{0,1,…,p,…m},p=0表示将中心云的资源分配给应用请求i,p=1,…,m表示将车辆p的资源分配给应用请求i,通过mfj计算p的概率pp,根据pp确定每个染色体的每个基因位的值,npop个染色体组成第t代父代种群pt,其中,pp的计算公式为:
其中,
(4)获取第t代子代种群qt:
(4a)对第t代父代种群pt的染色体两两组合,得到
(4b)对交叉后的父代种群中每个染色体的每个基因位进行变异,得到第t代子代种群qt;
(5)对第t代父代种群pt和第t代子代种群qt进行合并,得到第t代合并后的种群rt,rt=pt+qt;
(6)获取第t+1代父代种群pt+1:
根据多目标优化模型的约束条件,计算rt中每个染色体的目标函数值,并采用精英策略,通过rt中每个染色体的目标函数值获取第t+1代父代种群pt+1;
(7)获取应用请求的资源分配结果:
判断迭代次数t是否等于最大进化代数tmax,若是,将第t+1代父代种群pt+1中的染色体作为应用请求的资源分配结果,否则,令t=t+1,执行步骤(4)。
本发明与现有技术相比,具有以下优点:
第一,本发明在建立多目标模型的约束条件时,根据车辆的位置信息及速率,预测应用请求发出的车辆与其他车辆之间连接的持续时间,考虑了车辆之间传输时间约束,避免选择持续时间短的车辆作为资源提供者,与现有技术忽略由车辆移动性导致的车辆之间连接频繁中断相比,能够有效地降低应用请求的阻塞率。
第二,本发明在建立多目标模型的目标函数时,将最小化阻塞率和最小化成本作为目标函数,与现有技术考虑单目标相比,在降低阻塞率的同时能够满足成本要求。
第三,本发明在获取应用请求的资源分配结果时,通过计算每辆车的匹配因子获取第0代父代种群p0,即初始父代种群,根据每辆车的匹配因子计算每辆车被选择作为资源提供者的概率,根据计算出的概率获取初始父代种群,与现有技术随机生成初始父代种群相比,能够进一步降低应用请求的阻塞率。
附图说明
图1为本发明的实现总流程图;
图2为本发明采用的染色体的编码示意图。
具体实施方式
以下结合附图和具体实施例,对本发明作进一步详细描述:
参照图1,本发明的实现步骤如下:
步骤1)建立多目标优化模型:
建立包括目标函数和约束条件的多目标优化模型,其中目标函数包括最小化阻塞率f1和最小化成本f2,约束条件包括应用请求资源约束g1、每辆车的资源约束g2、车辆云总资源约束g3、车辆之间传输时间约束g4、车辆云处理的响应时间约束g5、中心云处理的响应时间约束g6和资源大小约束g7,定义分别为:
其中,n为应用请求数量,
应用请求资源约束g1的定义为:
每辆车的资源约束g2的定义为:
车辆云总资源约束g3的定义为:
车辆之间传输时间约束g4的定义为:
车辆云处理的响应时间约束g5的定义为:
中心云处理的响应时间约束g6的定义为:
资源大小约束g7的定义为:
其中,
其中,
步骤2)设定迭代次数和最大迭代次数:
设迭代次数为t,并初始化t=0,设最大迭代次数为tmax。
步骤3)获取第t代父代种群pt:
参照图2,本步骤的具体实现如下:
(3a)设车辆数量为m,m≥2,计算每辆车的匹配因子mf1,…,mfj,…m,fm,mfj表示车辆j的匹配因子:
mfj=γ1ψj+γ2cj+γ3dj
其中,γi为权重系数,
其中,ψj为车辆j的相对平均速率,nsam为车辆速率的样本数量,
其中,δv表示速率门限值,num{·}表示满足条件的车辆的数量。
(3b)设应用请求数量为n,n≥2,应用请求的一种车联网云系统资源分配结果用一个染色体表示,第t代父代种群pt中包含的染色体数量为npop,npop∈[40,100]且为偶数,每个染色体有n个基因位e1,…,ei,…,en,ei∈{0,1,…,p,…m},p=0表示将中心云的资源分配给应用请求i,p=1,…,m表示将车辆p的资源分配给应用请求i,通过mfj计算p的概率pp,根据pp确定每个染色体的每个基因位的值,得到基因位的值确定的染色体,npop个染色体组成第t代父代种群pt,其中,pp的计算公式为:
其中,
对染色体进行编码,其结构如图2所示,染色体有n个基因位e1,…,ei,…,en,其中第一个基因位e1的基因值为2,表示将第2辆车的资源分配给第1个应用请求,第二个基因位e2的基因值为0,表示将中心云的资源分配给第2个应用请求,第i个基因位ei的基因值为4,表示将第4辆车的资源分配给第i个应用请求,第n个基因位en的基因值为3,表示将第3辆车的资源分配给第n个应用请求。
步骤4)获取第t代子代种群qt:
(4a)对第t代父代种群pt的染色体两两组合,得到
(4a1)根据多目标优化模型的约束条件,计算pt中每个染色体的目标函数值,根据每个染色体的目标函数值,计算每个染色体的适应度,其中,染色体i的适应度fitness(i)按如下公式计算:
其中,fitnessk(i)为染色体i的第k个适应度,按如下公式计算:
其中,fk(i)为染色体i的第k个目标函数值。
(4a2)根据每个染色体的适应度,计算每个染色体被选择的概率,其中,染色体i被选择的概率pi按如下公式计算:
(4a3)将pt中所有染色体编号,根据每个染色体被选择的概率,每次从pt中选择两个染色体组成一对,记录对应的编号,采用有放回抽样的方式,选择
(4a4)产生一个(0,1)之间的随机数,若该随机数小于设定的交叉概率pc,随机选择一个基因位ei,将每对染色体中的两个染色体的基因位片段ei,…,en进行交叉,得到交叉后的染色体,否则两个染色体保持不变,交叉后的染色体和保持不变的染色体组成交叉后的父代种群,其中,交叉概率pc按如下公式计算:
其中,a1为0~1的常数,a2为0~1的常数,
(4b)对交叉后的父代种群中每个染色体的每个基因位进行变异,得到第t代子代种群qt:
(4b1)计算pt中所有染色体目标函数值之间的差异程度dg,计算公式为:
其中,
(4b2)对交叉后的父代种群中每条染色体的每个基因位,产生一个(0,1)之间的随机数,若该随机数小于变异概率pm,将该基因位的值变为其他可选值,每个可选值被选择的概率相等,否则基因位的值不变,得到变异后的染色体,组成第t代子代种群qt。
步骤5)对第t代父代种群pt和第t代子代种群qt进行合并,得到第t代合并后的种群rt,rt=pt+qt;
步骤6)获取第t+1代父代种群pt+1:
(6a)对rt中的所有染色体进行非支配排序,得到q个非支配前沿面f1,…,fl,…,fq,fl为第l个非支配前沿面,然后计算非支配前沿面f1,…,fl,…,fq中的染色体数量n1,…,nl,…,nq:
(6a1)根据多目标优化模型的约束条件,计算rt中每个染色体的目标函数值;
(6a2)根据rt中每个染色体的目标函数值,计算每个染色体被支配的染色体的数量,选择被支配的染色体的数量为0的染色体组成非支配前沿面f1,将f1中的所有染色体从rt中除去;
(6a3)令l=2;
(6a4)根据rt中剩下的染色体的目标函数值,对rt中剩下的染色体计算每个染色体被支配的染色体的数量,选择被支配的染色体的数量为0的染色体组成非支配前沿面fl,将fl中的所有染色体从rt中除去;
(6a5)令l=l+1,执行步骤(6a4),直到rt中的染色体数量为0,得到q个非支配前沿面f1,…,fl,…,fq;
(6a6)计算非支配前沿面f1,…,fl,…,fq中的染色体数量n1,…,nl,…,nq;
(6b)令l=1;
(6c)判断nl+…+n1=npop是否成立,若是,将fl中的染色体作为第t+1代父代种群pt+1的染色体,组成第t+1代父代种群pt+1,否则,执行步骤(6d);
(6d)判断nl+…+n1<npop,且nl+1+nl+…+n1>npop是否满足,若是,计算fl+1中每个染色体的拥挤距离
其中,m为目标函数的数量,fk(i)为第i个染色体的第k个目标函数值,fk(i+1)为第i+1个染色体的第k个目标函数值,fk(i-1)为第i-1个染色体的第k个目标函数值,
步骤7)获取应用请求的资源分配结果:
判断迭代次数t是否等于最大进化代数tmax,若是,将第t+1代父代种群pt+1中的染色体作为应用请求的资源分配结果,否则,令t=t+1,执行步骤(4)。
- 还没有人留言评论。精彩留言会获得点赞!