一种由单张图像生成立体视觉图像的方法与流程
本发明涉及立体视觉领域,尤其是一种由单张图像生成立体视觉图像的方法。
背景技术:
立体视觉是一种模拟人类眼睛双目视觉效果的技术。该技术通过展示两张具有视差的图像来模拟深度立体感,且广泛应用于三维显示系统,如虚拟现实眼镜和裸眼3d展示等。由单张图像生成双目立体视觉图像的方法主要分为两类,一类是根据图像的深度信息计算另一视角下的图像,另一类则是直接根据当前视角图像生成另一视角下的图像。
第一类方法中深度图像的获取是其中至关重要的一部分。直接获取深度图像需要专业仪器,深度估计则泛用性更高。早期的深度估计方法常常假设场景是平面或圆柱,或通过数据驱动的方法处理部分特定的物体和场景,这类方法在应用场景上具有非常大的局限性。近几年的研究集中在使用卷积神经网络估计单张图像的深度信息,通过模型结构的调整,损失函数的改进或与条件随机场的结合等方法来改善深度估计的准确率,该类方法也只能处理与训练数据相似的图像。
根据深度图可以计算视差得到另一视角下的图像,而图像中的空洞需要进行填补。这类方法通常有沿等照度线的方向进行空洞的插值,通过patch-based方法填补空洞,直接通过卷积神经网络预测缺失的部分,使用生成对抗网络进行修补等。目前尚未看到针对立体视觉图像的修补方法。
第二类方法目前主要给出一个视角的图像,通过训练卷积神经网络直接生成新视角下的图像。这一方法需要大量双目图像数据来进行训练,也同样存在应用场景的局限。
技术实现要素:
针对上述不足,本发明提供一种由单张图像生成立体视觉图像的方法,该方法只需要输入一张彩色图像,即可以生成不同视角下的新的图像,从而用于虚拟现实眼镜、裸眼3d展示等,帮助用户理解三维场景,解决了从单张图像难以构建立体视觉的问题。
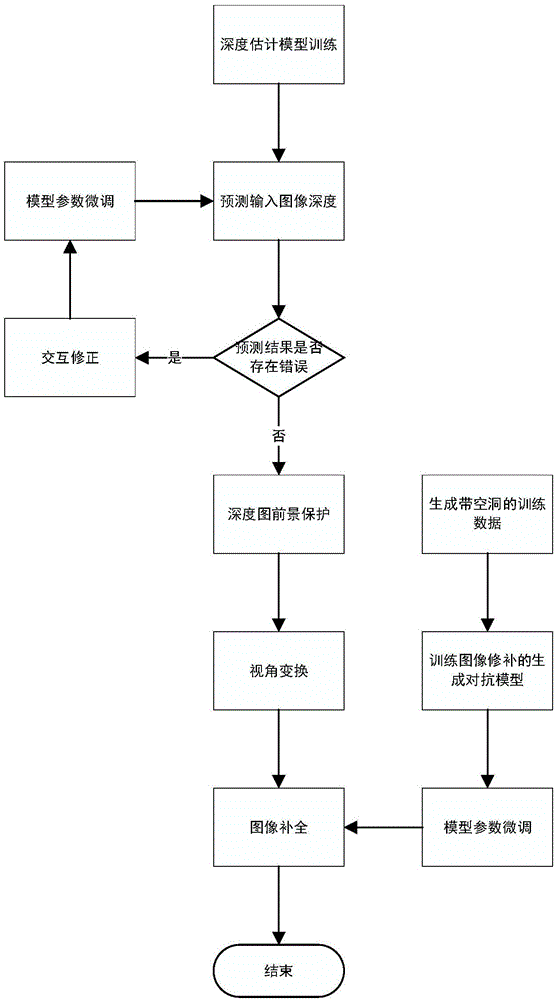
为了实现上述目的,本发明的技术方案是:一种由单张图像生成立体视觉图像的方法,主要包括以下步骤:
(1)使用rgbd图像数据集进行深度估计模型的训练;
(2)对于输入的单张彩色图像,估计其深度信息;
(3)通过交互和模型参数微调修正估计深度中错误的部分;
(4)对估计的深度图进行前景保护操作,从而更好地对齐深度边缘和彩色图像边缘;
(5)根据图像和深度信息,计算视差,得到新视角下的图像;
(6)根据数据集中的深度图,生成与新视角下图像相似的空洞区域;
(7)用新生成的数据训练用于图像修补的生成对抗网络模型;
(8)针对测试图片,对修补模型进行参数微调;
(9)修补新视角下图像的空洞部分,得到生成的立体视觉图像。
进一步的,所述步骤(1)包含以下步骤:
(1.1)进行数据处理,对数据集进行等间隔采样,并进行随机裁剪,水平翻转,颜色抖动的数据增强,并根据深度图采样点来衡量相对深度;
(1.2)模型结构为encoder-decoder结构,通过三个卷积层从彩色图像获得三种不同尺度的特征作为模型的sideinput,用以恢复细节信息;
(1.3)模型损失函数由l1loss,l2loss和rankloss组成;
(1.4)使用随机梯度下降法进行优化,并调节学习率、batchsize、weightdecay的超参数,参数设置完毕后开始训练。
进一步的,所述步骤(3)包含以下步骤:
(3.1)对于估计深度图中的错误区域,在图像上拾取与待修正区域目标颜色灰度值最相近的颜色,并在错误区域上进行涂抹,得到交互图像;
(3.2)对输入图像进行随机裁剪,随机翻转和颜色抖动的数据增强;
(3.3)步骤(3.1)中的数据作为真实深度,步骤(3.2)中的数据作为输入图像,对步骤(1)的模型进行进一步的微调训练;
(3.4)用步骤(3.3)中微调后的模型重新预测输入图像的深度,生成修正之后的深度预测结果。
进一步的,所述步骤(6)包含以下步骤:
(6.1)初始化一张与图像同样大小且全部值为0的掩码矩阵,按行对图像中的像素进行扫描,如某个像素与相邻像素之差大于设定阈值,则将掩码矩阵中对应位置设为1;
(6.2)对于掩码矩阵中值为1的像素,计算其与相邻像素的视差之差,并将图像中从像素点到像素点之前的所有像素点设为0,掩码矩阵对应位置设为1;
(6.3)掩码矩阵中值为0的像素即为空洞区域。
进一步的,所述步骤(7)使用adadelta算法训练图像填补模型。
进一步的,所述步骤(8)包含以下步骤:
(8.1)对于数据集外图像,使用步骤(6)的方法生成空洞区域和掩码矩阵;
(8.2)对输入图像进行随机裁剪,随机翻转和颜色抖动的数据增强;
(8.3)用步骤(8.2)中的数据作为输入图像,无空洞数据作为真实图像,对步骤(7)的模型进行进一步微调训练。
本发明的有益效果是:只需要单张彩色图像即能生成一定范围内视角下的图像;通过对估计的深度图进行编辑,可以修正预测错误的区域;通过模型参数微调,对于数据集外的图像也能够有较好的表现,生成的立体图像能够感受到较为明显的立体效果,从而帮助用户更好地理解三维场景。
附图说明
图1是本发明的流程图;
图2是深度估计模型的结构示意图;
图3是深度预测结果示例图;
图4a是输入彩色图像,图4b是真实深度图,图4c是模型微调前的预测结果,图4d是交互得到的结果,图4e是模型参数微调修正错误之后的预测结果;
图5a-图5f是模拟生成的空洞图像示例图;
图6是微调前后的结果示意图;
图7是立体图像生成结果示意图。
具体实施方式
下面结合附图对本发明作进一步说明:
如图1所示,一种由单张图像生成立体视觉图像的方法,主要包括以下步骤:使用rgbd图像数据集进行深度估计模型的训练;对于输入的单张彩色图像,估计其深度信息;通过交互和模型参数微调修正估计深度中错误的部分;对估计的深度图进行前景保护操作,从而更好地对齐深度边缘和彩色图像边缘;根据图像和深度信息,计算视差,得到新视角下的图像;根据数据集中的深度图,生成与新视角下图像相似的空洞区域;用新生成的数据训练用于图像修补的生成对抗网络模型;针对测试图片,对修补模型进行参数微调;修补新视角下图像的空洞部分,从而生成最终的立体视觉图像。
下面对每个步骤做详细的说明:
(1)使用rgbd图像数据集进行深度估计模型的训练:该步骤提出了一种深度估计模型,以resnet50为基础,构建了一种encoder-decoder结构,模型的输入为彩色图像,输出为单通道深度图。为了补充预测深度图中的细节信息,该模型构建了side-input结构,从输入的彩色图像中分三次加入三种不同尺度的特征。另外,还结合了side-output结构来帮助优化。模型的损失函数结合了l1loss,l2loss和rankloss,其中rankloss可帮助获得非局部的信息。具体步骤如下:
模型结构设计:本发明以(kaiminghe,xiangyuzhang,shaoqingren,andjiansun.2016.deepresiduallearningforimagerecognition.incvpr.ieeecomputersociety,770–778.)中提出的resnet50模型为基础,构建了一种encoder-decoder结构,如图2所示。为了恢复预测深度图中的细节信息,本发明构建了side-input结构,即从输入的彩色图像中通过一个新的卷积层提取特征,并与decoder部分的特征图连接到一起,作为下一个卷积层的输入。整个模型中分三次加入三种不同尺度的特征。另外,还结合了(sainingxieandzhuowentu.2017.holistically-nestededgedetection.internationaljournalofcomputervision125,1-3(2017),3–18.)提出的side-output结构来帮助进行模型的优化。
损失函数设计:本模型的损失函数结合了l1loss,l2loss和rankloss,其中rankloss可帮助获得非局部的信息。具体地,对于数据集中的一组rgbd图像i,预测的深度图像为z。对于一个像素点i,其rgb信息可表示为
类似地,深度的梯度之差gx和gy可以表示为:
l1loss可以被定义为:
l2loss可以被定义为:
另外,(weifengchen,zhaofu,daweiyang,andjiadeng.2016.single-imagedepthperceptioninthewild.innips.730–738.)对于一对随机选择的点对(i,j),根据其深度值定义标签rij={+1,-1,0},其中+1表示zi>zj,-1表示zi<zj,0表示zi=zj。该点对的rankloss可以表示为:
最终,深度估计模型的损失函数定义为:
其中,(k,l)表示第j张训练图片上的点对,k为点对的总数。
模型训练过程:本发明使用室内数据集nyudepthv2(pushmeetkohlinathansilberman,derekhoiemandrobfergus.2012.indoorsegmentationandsupportinferencefromrgbdimages.ineccv.)和室外数据集synthia(germanros,laurasellart,joannamaterzynska,davidvazquez,andantoniom.lopez.2016.thesynthiadataset:alargecollectionofsyntheticimagesforsemanticsegmentationofurbanscenes.intheieeeconferenceoncomputervisionandpatternrecognition(cvpr).)进行训练。
对于nyu数据集,对原始kinect序列帧进行等间隔采样得到四万张rgbd图像,并通过随机水平翻转旋转得到12万张训练集,并统一双线性插值缩小到320*240的分辨率。训练过程中将图像随机裁剪到304*228的大小。另外还在深度图像上随机采样3000对点对并标注其相对关系。
对于synthia数据集,采用seqs-04和seqs-06两个场景,并按照训练集:测试集9:1的比例得到54000张训练集图像和6000张测试集图像,最后缩小到320*190的分辨率进行训练。
模型训练采用随机梯度下降法,batchsize为8,整个训练过程持续13个epochs。开始使用0.001的学习率预热几千次,之后以0.01的学习率开始正式训练,每6个epochs将学习率降为原来的1/10。
(2)对于输入的单张彩色图像,估计其深度信息:测试时,将图像中心裁剪到304*228,且通过指数函数将模型的输出值映射回10米范围,预测结果示例见图3。
(3)通过交互和模型参数微调修正估计深度中错误的部分:直接使用模型估计图像深度时,可能会存在部分错误,如图4c所示。本发明提供交互工具用以帮助修正错误区域。用户可以在图像上拾取与待修正区域目标颜色相近的颜色,并在区域上进行涂抹,得到图4d的交互图像。之后将该交互图像替代真实深度图(图4b),使用图4a的彩色图像对步骤1)中训练好的模型进行finetune,训练过程中对输入图像进行随机裁剪,随机翻转和颜色抖动操作来达到数据增强的目的。最后用微调后的模型重新对图像进行预测可得到图4e修正后的预测结果。其中,模型参数微调指输入一张图片,通过随机裁剪,随机镜像,随机颜色抖动等,将图片增强为一个数据集,前一步中训练好的模型在当前数据集上进行进一步的训练,从而提高对当前图片的处理能力。
(4)对估计的深度图进行前景保护操作,从而更好地对齐深度边缘和彩色图像边缘:模型预测的深度图边缘可能与彩色图边缘并不完全对齐,可以采用(xiaohanlu,fangwei,andfangminchen.2012.foreground-object-protecteddepthmapsmoothingfordibr.in2012ieeeinternationalconferenceonmultimediaandexpo.339–343.)提出的前景物体保护来更好地对齐深度边缘和彩色图像边缘。
(5)根据图像和深度信息,计算视差,得到新视角下的图像:本发明中生成的立体视觉图像视差沿x方向,可以通过以下公式计算:
其中,x'表示输入图像中的像素位置,x表示新的像素位置。b表示视角变换的距离,即基线;f表示相机的焦距,该参数由数据集决定;z表示x'处的深度。通过该公式可以将图像变换到新视角下。视角变换中,被遮挡区域重新显现出来时,会形成空洞区域,1像素宽度的空洞可通过插值直接填补,比较大的空洞可使用生成对抗网络通过后续步骤进行图像填补。
(6)根据数据集中的深度图,生成与新视角下图像相似的空洞区域:由视角变换产生的空洞区域往往靠近物体的边缘且呈现出细长的形状。为了提高生成对抗网络图像填补的效果,本发明提出了一种根据深度图生成带有空洞区域的图像的算法,该算法通过扫描像素与相邻像素之间的深度差,确定该位置是否可能产生空洞区域;另外通过计算某像素与相邻像素之间的视差来确定该位置的空洞区域的大小。通过这一算法能够生成与立体视觉图像中位置和形状相似的空洞区域。具体步骤如下:
(6.1)模拟空洞区域产生的位置:假设生成输入图像的右边视角,空洞区域会出现在前景物体的右边,我们通过以下公式初始化一个掩码图像:
其中z(x,y)表示(x,y)点处的深度值,θ为系统制定的阈值。m(x,y)=1表示在进行视角变化时,该位置可能出现空洞。
(6.2)模拟空洞区域的大小:沿x方向,(x,y)点附近空洞的大小由(x,y)和(x+1,y)两点处的视差决定,公式如下:
从像素点(x+1,y)到像素点(x+1+s(x,y),y)之前的所有像素点都被认为是空洞区域,掩码图像对应位置被设为1,生成的带空洞图像如图5a-图5f所示,白色部分表示空洞区域。
(7)用新生成的数据训练用于图像修补的生成对抗网络模型:模型采用(satoshiiizuka,edgarsimo-serra,andhiroshiishikawa.2017.globallyandlocallyconsistentimagecompletion.acmtrans.graph.36,4(2017),107:1–107:14.)中的结构,分别在560*426分辨率大小的nyu数据集和640*380的synthia数据集上进行训练,输入图像为带有步骤6)中生成的空洞区域的图像和掩码图像,真实图像为原始完整图像。训练使用adadelta算法,持续10个epochs,batchsize为24。
(8)针对测试图片,对修补模型进行参数微调;对于不在数据集内的图片,本发明使用步骤4)中处理后的预测深度图生成空洞区域,且对输入图片进行随机裁剪,水平翻转的数据增强,使用增强后的数据对步骤7)中的模型进行参数微调。微调前后的结果示例见图6。
(9)修补新视角下图像的空洞部分,生成结果如图7所示,图中白框部分为立体视觉效果比较明显的区域。
实施例:
发明人在一台配备两块nvidia1080tigpu和12gb内存的机器上实现了本发明的一个实施示例。深度估计模型的resnet50部分通过在imagenet数据集上预训练好的模型初始化,其他层参数初始化符合均值为0,方差为0.01的高斯分布。深度估计模型对输入图片进行微调时持续1000次迭代,图像修补模型进行微调时持续400次迭代。发明人对本方法进行了评估,在nyu测试集上,深度估计方面,1.25阈值标准内的准确率达到了82.2%,ssim(结构相似度)达到了0.9463,图像修补方面,psnr(峰值信噪比)达到了30.98,ssim达到了0.953。本方法能够生成视觉效果合理且立体视觉明显的立体视觉图像。
除上述实施例外,本发明还可以有其他实施方式。凡采用等同替换或等效变换形成的技术方案,均落在本发明要求的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!