一种web日志的收集分析系统的制作方法
本发明涉及网络安全技术领域,尤其涉及一种web日志的收集分析系统。
背景技术:
任何一个生产系统在运行过程中都会产生大量的日志,日志往往隐藏了很多有价值的信息。在没有分析方法之前,这些日志存储一段时间后就会被清理。随着技术的发展和分析能力的提高,日志的价值被重新重视起来。web日志的作用主要体现在通过对这些web日志的深度挖掘,对站点用户访问web服务器过程中产生的日志数据进行分析处理,从而发现web用户的访问模式和兴趣爱好等,这些信息对站点建设潜在有用的可理解的未知信息和知识,用于分析站点的被访问情况,辅助站点管理和决策支持等。而在分析这些日志之前,则需要将分散在各个生产系统中的日志收集起来。
技术实现要素:
为了有效利用网络流量,为针对用户访问行为后续分析奠定基础,开发了一种web访问日志的收集分析系统,该系统可将web应用的日志收集起来,该系统运行在linux,利用nginx的日志转发功能,将web应用的日志发送至linux的rsyslog,再通过转发模块将日志转发至kafka存储,分析模块直接读取kafka的日志,加以分析。运行过程中,每个模块都可独立运行,转发模块及分析模块还可启动多进程同时rsyslog+kafka的高速读写,极大地保证了日志的转储效率。除此之外,模块独立运行还使该系统后续可添加更多的分析模块,以挖掘日志的深层价值。
本发明通过以下技术方案来实现上述目的:
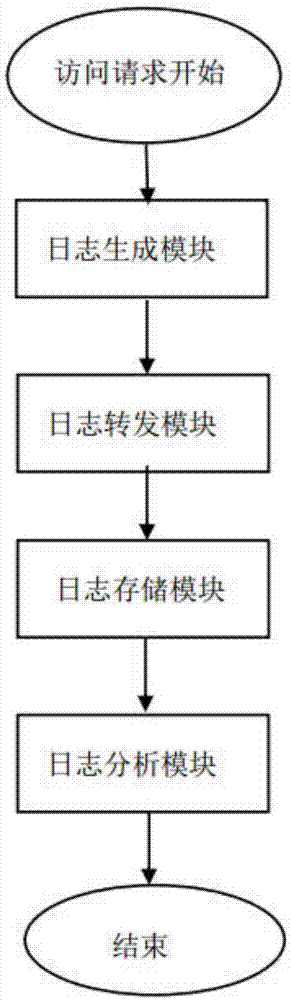
一种web日志的收集分析系统,包括:
日志生成模块,所述日志生成模块由nginx完成,nginx服务端处理用户请求,记录访问日志,通过lua实现nginx日志转发至syslog服务器;
日志转发模块,所述日志转发模块由python实现;
日志存储模块,所述日志存储模块由zookeeper和kafka实现组成,zookeeper是一个高性能分布式应用协调服务,kafka对消息保存时根据topic进行归类,发送消息者成为producer,消息接受者成为consumer,此外kafka集群有多个kafka实例组成,每个实例(server)成为broker,无论是kafka集群,还是producer和consumer都依赖于zookeeper来保证系统可用性集群保存一些meta信息;
日志分析模块,所述日志分析模块可随本系统使用者持续扩展开发、添加功能。
作为进一步优化,所述日志转发模块本质即为kafka的生产者,通过多种对比,选用confulent-kafka作为连接kafka的库,极大地提高了写入kafka的效率。
作为进一步优化,所述日志分析模块的本质即为kafka消费者,可持续扩展的基础源于kafka的消费者可有多个,且可有多个消费者组,同一组内的消费者无法读取kafka同一topic下的同一条日志,但可以同时消费同一topic下的不同日志,提高消费速率。
作为进一步优化,所述日志分析模块由python分析程序+redis或其他数据库组成。
作为进一步优化,所述日志分析模块利用confulent-kafka连接kafka,读取日志,根据日志时间戳,提取时间,进行计数,然后将结果定时入库redis或其他数据库。
作为进一步优化,前述任一模块均运行在docker容器中,且转发模块及日志分析模块均可启动多个容器,同时分布式的架构使得本系统还可使用dockerswarm部署在多台服务器上。
本发明的有益效果在于:
本发明的一种web日志的收集分析系统,可将web应用的日志收集起来,该系统运行在linux,利用nginx的日志转发功能,将web应用的日志发送至linux的rsyslog,再通过转发模块将日志转发至kafka存储,分析模块直接读取kafka的日志,加以分析。运行过程中,每个模块都可独立运行,转发模块及分析模块还可启动多进程同时rsyslog+kafka的高速读写,极大地保证了日志的转储效率。除此之外,模块独立运行还使该系统后续可添加更多的分析模块,以挖掘日志的深层价值。
附图说明
为了更清楚地说明本发明实施例中的技术方案,下面将对实施例或现有技术描述中所需要实用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本实施例的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
图1为本发明提供的一种web日志的收集分析系统的结构示意图。
图2为本发明提供的一种web日志的收集分析系统的构架示意图。
具体实施方式
为使本发明的目的、技术方案和优点更加清楚,下面将对本发明的技术方案进行详细的描述。显然,所描述的实施例仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动的前提下所得到的所有其它实施方式,都属于本发明所保护的范围。
如图1-2所示,本发明的一种web日志的收集分析系统,包括:
日志生成模块由nginx完成,nginx服务端处理用户请求,记录访问日志,通过lua实现nginx日志转发至syslog服务器;
日志转发模块由python实现,该模块本质即为kafka的生产者,通过多种对比,选用confulent-kafka作为连接kafka的库,极大地提高了写入kafka的效率;
日志存储模块由zookeeper和kafka实现组成,zookeeper是一个高性能分布式应用协调服务,kafka对消息保存时根据topic进行归类,发送消息者成为producer,消息接受者成为consumer,此外kafka集群有多个kafka实例组成,每个实例(server)成为broker。无论是kafka集群,还是producer和consumer都依赖于zookeeper来保证系统可用性集群保存一些meta信息;
日志分析模块可随本系统使用者持续扩展开发、添加功能,日志分析模块的本质即为kafka消费者,可持续扩展的基础源于kafka的消费者可有多个,且可有多个消费者组。同一组内的消费者无法读取kafka同一topic下的同一条日志,但可以同时消费同一topic下的不同日志,提高消费速率。因此,对于一个分析程序来说,可启动多个客户端同时消费(即一个消费组内多个消费者),单并不会重复消费,对于多个分析程序来说(即多个消费组),可设置为不同消费者组,保证不同功能的消费程序同时读取到相同日志,同时进行不同维度的分析;
日志分析模块由python分析程序+redis或其他数据库组成。以每小时访问次数统计功能为例,利用confulent-kafka连接kafka,读取日志,根据日志时间戳,提取时间,进行计数,然后将结果定时入库redis或其他数据库。
为了减小程序对操作系统的影响,且方便系统移植、部署、模块添加及扩展、本系统各模块均运行在docker容器中,且转发模块及日志分析模块均可启动多个容器,提高转发效率及分析效率,同时分布式的架构使得本系统还可使用dockerswarm部署在多台服务器上。
以上所述,仅为本发明的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,可轻易想到变化或替换,都应涵盖在本发明的保护范围之内。因此,本发明的保护范围应以所述权利要求的保护范围为准。另外需要说明的是,在上述具体实施方式中所描述的各个具体技术特征,在不矛盾的情况下,可以通过任何合适的方式进行组合,为了避免不必要的重复,本发明对各种可能的组合方式不再另行说明。此外,本发明的各种不同的实施方式之间也可以进行任意组合,只要其不违背本发明的思想,其同样应当视为本发明所公开的内容。
- 还没有人留言评论。精彩留言会获得点赞!