使用相位响应特征来双耳渲染的音频信号处理方法和装置与流程
本公开涉及一种用于有效地再现音频信号的信号处理方法和设备,并且更具体地说,涉及一种用于在头戴式显示器(hmd)中提供交互式和沉浸式三维音频信号的信号处理方法和设备。
背景技术:
双耳渲染技术基本上是在头戴式显示器(hmd)设备中提供沉浸式和交互式音频所必需的。双耳渲染表示对3d音频进行建模,这提供将给出存在于三维空间中的感觉的声音提供到要递送给人类的耳朵的信号中。收听者可以通过头戴式耳机、耳机等从双耳渲染的2声道音频输出信号体验到三个维度的感觉。双耳渲染的具体原理被描述如下。人类通过两只耳朵收听声音,并且根据声音辨识声源的位置和方向。因此,如果可以将3d音频建模到要递送给人类的两只耳朵的音频信号中,则可以在没有大量扬声器的情况下通过2声道音频输出来再现3d音频的三个维度。
这里,当在要双耳渲染的音频信号中包括的声道的数目或目标增加时,可以增加对双耳渲染需要的计算的量和功耗。因此,在计算量和功耗方面限制的移动设备中要求用于对输入音频信号有效地执行双耳渲染的技术。
此外,由于有限的存储器容量和测量过程中的约束,可以由音频信号处理设备获得的头部相关传输函数(hrtf)的数目可以是有限的。这可能引起音频信号处理设备的声音定位性能的劣化。因此,可能要求音频信号处理设备针对输入hrtf的附加处理,以增加正在三维空间上再现的音频信号的通信分辨率。此外,虚拟现实中的双耳渲染的音频信号可以与附加信号组合以改进可再现性。在这种情况下,当音频信号处理设备在时域中合成经双耳渲染的音频信号和附加信号时,输出音频信号的声音质量可以由于梳状滤波效果而劣化。这是因为音色可能由于双耳渲染和附加信号的不同延迟而失真。另外,当音频信号处理设备在频域中合成双耳渲染的音频信号和附加信号时,如与仅使用双耳渲染的情况相比较,要求附加的计算量。因此需要用于保存输入音频信号的音色同时减少进一步处理和合成中的计算量的技术。
技术实现要素:
技术问题
本公开的实施例的目的是为了在通过基于多个滤波器双耳渲染输入音频信号来生成输出音频信号时减少由于梳状滤波效果而导致的音色的失真。
技术方案
根据本公开的实施例的音频信号处理设备包括用于输出基于输入音频信号而生成的输出音频信号的处理器。处理器可以基于与输入音频信号相对应的虚拟声源的位置,从包括与相对于收听者的每个具体位置相对应的头部相关传递函数(hrtf)的传递函数的第一集合获得包括第一同侧hrtf和第一对侧hrtf的第一hrtf对,以及通过执行基于该第一hrtf对来双耳渲染输入音频信号,从而生成输出音频信号,并且其中,不管多个同侧hrtf中的每个的位置如何,在传递函数的第一集合中包括的多个同侧hrtf中的每个在频域中的相位响应都可以是相同的。第一同侧hrtf的相位响应可以是线性相位响应。
可以基于与第一同侧hrtf的经修改的相位响应相对应的同侧组延迟来确定与第一对侧hrtf的相位响应相对应的对侧组延迟,并且第一对侧hrtf的相位响应可以是线性相位响应。
对侧组延迟可以是通过使用相对于同侧组延迟的耳间时间差(itd)信息确定的值。
itd信息可以是基于所测量的hrtf对而获得的值,并且所测量的hrtf对与虚拟声源相对于收听者的位置相对应。
对侧组延迟可以是相对于同侧组延迟通过使用收听者的头部建模信息确定的值。
同侧组延迟和对侧组延迟是根据时域中的采样频率的样本的整数倍。
处理器可以被配置为在时域中通过分别基于对侧组延迟和同侧组延迟使输入音频信号延迟来生成输出音频信号。
处理器可以被配置为在时域中基于相位响应修改的第一hrtf对和附加音频信号生成最终输出音频信号,并且输出最终输出音频信号。附加音频信号的同侧组延迟可以与第一同侧hrtf组延迟的同侧组延迟相同并且附加音频信号的对侧组延迟可以与第一对侧hrtf的对侧组延迟相同。
处理器可以被配置为根据虚拟声源相对于收听者的位置来获得平移增益,基于该平移增益对输入音频信号进行滤波,并且基于第一同侧组延迟的同侧组延迟和第一对侧组延迟的对侧组延迟使经滤波的输入音频信号延迟,以生成附加音频信号。
处理器可以被配置为通过基于第一hrtf对来双耳渲染输入音频信号,从而生成输出信号,通过基于包括同侧附加滤波器和对侧附加滤波器的附加滤波器对来对输入音频信号进行滤波,从而生成附加音频信号,并且通过在时域中混合输出音频信号和附加音频信号来生成最终输出音频信号。同侧附加滤波器的相位响应可以与第一同侧hrtf的相位响应相同,并且对侧附加滤波器的相位响应可以与第一对侧hrtf的相位响应相同。
附加滤波器对可以是基于根据虚拟声源相对于收听者的位置的平移增益而生成的滤波器,并且同侧附加滤波器和对侧附加滤波器中的每个的频率响应的幅度分量可以是恒定的。
附加滤波器对可以是基于由虚拟声源建模的目标的大小和从收听者到虚拟声源的距离而生成的滤波器。
不管与多个hrtf中的每个相对应的位置如何,在传递函数的第一集合中包括的多个hrtf中的每个在频域中的相位响应都可以是彼此相同的。处理器可以被配置为在虚拟声源的位置可以是除与多个hrtf中的每个相对应的位置以外的位置时基于至少两个hrtf对获得第一hrtf对。该至少两个hrtf对可以基于虚拟声源的位置从传递函数的第一集合获得。
处理器可以被配置为通过在时域中内插至少两个hrtf对来获得第一hrtf对。
处理器可以被配置成基于虚拟声源的位置从除传递函数的第一集合以外的传递函数的第二集合获得包括第二同侧hrtf和第二对侧hrtf的第二hrtf对,并且基于第一hrtf对和第二hrtf对生成输出音频信号。第二同侧hrtf的相位响应可以与第一同侧hrtf的相位响应相同,并且第二对侧hrtf的相位响应可以与第一对侧hrtf的相位响应相同。
一种用于音频信号处理设备输出基于输入音频信号而生成的输出音频信号的操作方法包括以下步骤:基于与输入音频信号相对应的虚拟声源的位置,从包括与相对于收听者的每个具体位置相对应的头部相关传递函数(hrtf)的传递函数的集合获得包括同侧hrtf和对侧hrtf的hrtf对;以及通过执行基于该hrtf对双耳渲染输入音频信号来生成输出音频信号。不管多个同侧hrtf中的每个的位置如何,在传递函数的集合中包括的多个同侧hrtf中的每个在频域中的相位响应都可以是相同的。
根据本公开的实施例的音频信号处理设备包括用于输出基于输入音频信号而生成的输出音频信号的处理器。处理器可以被配置为基于与输入音频信号相对应的虚拟声源的位置从包括与相对于收听者的每个具体位置相对应的头部相关传递函数(hrtf)的传递函数的第一集合获得包括第一同侧hrtf和第一对侧hrtf的第一hrtf对,不管虚拟声源的位置如何,将第一同侧hrtf在频域中的相位响应修改为可以都是相同的具体相位响应,并且通过执行基于可以修改第一同侧hrtf的相位响应的第一hrtf对来双耳渲染输入音频信号,从而生成输出音频信号。
处理器可以被配置为基于与第一同侧hrtf在时域中的经修改的相位响应相对应的同侧组延迟确定对侧组延迟,基于对侧组延迟修改第一对侧hrtf的相位响应,并且通过基于第一同侧hrtf和第一对侧的相位响应被修改的相位响应修改的第一hrtf对来双耳渲染输入音频信号,从而生成输出音频信号,并且其中,第一对侧hrtf的经修改的相位响应可以是线性相位响应。
处理器可以被配置为基于收听者的头部建模信息确定对侧组延迟。
处理器可以被配置为基于从传递函数的第一集合获得的第一hrtf对来获得耳间时间差(itd)信息,并且基于itd信息确定对侧组延迟。
同侧组延迟和对侧组延迟是根据时域中的采样频率的样本的整数倍。
处理器可以被配置为在时域中,通过分别基于对侧组延迟和同侧组延迟使输入音频信号延迟来生成输出音频信号。
处理器可以被配置为在时域中基于修改第一hrtf对的相位响应和附加音频信号生成最终输出音频信号,并且其中,附加音频信号的同侧和对侧的每个组延迟可以分别与同侧组延迟和对侧组延迟中的每个相同。
处理器可以被配置为基于虚拟声源相对于收听者的位置确定平移增益,基于该平移增益对输入音频信号进行滤波,并且基于同侧组延迟和对侧组延迟使经滤波的输入音频信号延迟,以生成附加音频信号。
处理器可以被配置成通过基于相位响应修改的第一hrtf对双耳渲染输入音频信号来生成输出信号,通过基于包括同侧附加滤波器和对侧附加滤波器的附加滤波器对来对输入音频信号进行滤波,从而生成附加音频信号,并且通过使输出音频信号与附加音频信号相混合来生成最终输出音频信号。同侧附加滤波器的相位响应可以与第一同侧hrtf的经修改的相位响应相同,并且对侧附加滤波器的相位响应可以与第一对侧hrtf的经修改的相位响应相同。
同侧附加滤波器和对侧附加滤波器中的每个的频率响应的幅度分量可以是恒定的。处理器可以被配置为基于虚拟声源相对于收听者的位置确定平移增益,在将平移增益设定为恒定幅度响应情况下生成附加滤波器对,并且通过基于附加滤波器对来对输入音频信号进行滤波从而生成附加音频信号。
处理器可以被配置为基于由虚拟声源建模的目标的大小和从收听者到虚拟声源的距离生成附加滤波器对,并且通过基于附加滤波器对来对输入音频信号进行滤波,从而生成附加音频信号。
不管多个hrtf的位置如何,在传递函数的第一集合中包括的多个hrtf中的每个的相位响应都可以是彼此相同的。处理器可以被配置为在虚拟声源的位置可以是除与多个hrtf中的每个相对应的位置以外的位置时,基于虚拟声源的位置在传递函数的第一集合当中获得至少两个hrtf对,并且通过在时域中内插该至少两个hrtf对来获得第一hrtf对。
处理器可以被配置为基于虚拟声源的位置从除传递函数的第一集合以外的传递函数的第二集合获得包括第二同侧hrtf和第二对侧hrtf的第二hrtf对,将第二同侧hrtf的相位响应修改为第一同侧hrtf的经修改的相位响应,将第二对侧hrtf的相位响应修改成为第一对侧hrtf的经修改的相位响应,并且基于相位响应修改的第一传递函数对和相位响应修改的第二传递函数对生成输出音频信号。
有益效果
根据本公开的实施例的音频信号处理设备和方法可以减少由于在双耳渲染过程中发生的梳状滤波效果而导致的声音质量劣化。此外,该音频信号处理设备和方法可以减少在基于多个滤波器双耳渲染输入音频信号以生成输出音频信号的过程中发生的音色的失真。
附图说明
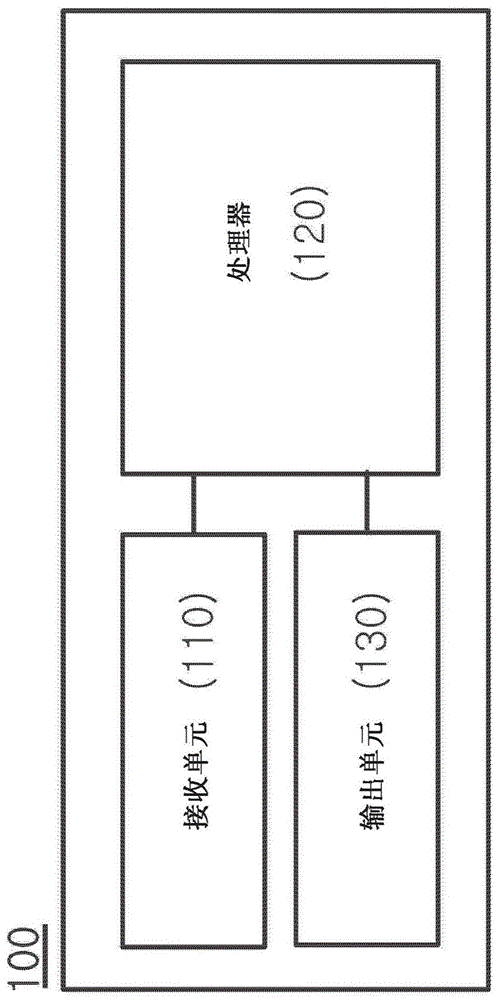
图1是图示根据本公开的实施例的音频信号处理设备的配置的框图。
图2是图示根据本公开的实施例的音频信号处理设备的操作的框图。
图3是具体地图示用于根据本公开的实施例的音频信号处理设备修改原始hrtf对的相位响应的方法的图。
图4是图示hrtf的原始相位响应和从相对应的原始相位响应线性化的相位响应的图。
图5示出在hrtf对中包括的左侧hrtf和右侧hrtf中的每个的线性化相位响应。
图6和图7是图示根据本公开的实施例的用于音频信号处理设备针对耳间极坐标(ipc)系统中的方位角来获得itd的方法的图。
图8是图示根据本公开的实施例的用于音频信号处理设备以通过使用收听者的头部建模信息来获得itd的方法的图。
图9是图示根据本公开的另一实施例的用于音频信号处理设备以通过使用收听者的头部建模信息来获得itd的方法的图。
图10是图示根据本公开的实施例的用于音频信号以增强空间分辨率的方法的图。
图11是图示用于根据本公开的实施例的音频信号处理设备以从原始的hrir集合生成扩展的hrir集合的方法的图。
图12是图示用于根据本公开的实施例的音频信号处理设备以线性地组合基于多个hrtf集合双耳渲染的输出音频信号以生成最终输出音频信号的方法的图。
图13是图示根据本公开的实施例的用于音频信号处理设备以基于通过线性地组合多个hrtf生成的hrtf而生成输出音频信号的方法的图。
图14是图示用于根据本公开的另一实施例的音频信号处理设备以校正hrtf对中的测量误差的方法的图。
图15是图示根据本公开的实施例的音频信号处理设备在时域中基于多个滤波器生成输出音频信号的操作的框图。
图16是图示用于根据本公开的实施例的音频信号处理设备以通过使用平移增益来调整双耳效果强度的方法的图。
图17是示出左侧和右侧分别根据相对于收听者的方位角的平移增益的图。
图18是图示根据本公开的实施例的音频信号处理设备的以在频域中基于第一滤波器和第二滤波器生成输出音频信号的操作的框图。
图19是示出在时域中通过图17和图18获得的输出音频信号的曲线图。
图20是示出由根据本公开的实施例的音频信号处理设备基于在同侧和在对侧匹配的相位响应来生成输出音频信号的方法的框图。
图21是图示用于根据本公开的实施例的音频信号处理设备以基于hrtf和附加滤波器生成输出音频信号的方法的框图。
图22图示通过空间滤波器的声音效果的示例。
图23是图示用于根据本公开的实施例的音频信号处理设备以基于多个滤波器生成输出音频信号的方法的图。
图24是图示由于梳状滤波效果而导致的声音质量劣化的图。
图25是图示用于根据本公开的实施例的音频信号处理设备以通过组合多个滤波器来生成组合滤波器的方法的图。
图26是图示在根据本公开的实施例的音频信号处理设备中通过在频域中内插多个滤波器而生成的组合滤波器的图。
图27是根据本公开的实施例的空间滤波器的频率响应的图示。
图28是图示用于根据本公开的实施例的音频信号处理设备基于上述的hrtf、平移滤波器、和空间滤波器生成最终输出音频信号的方法的图。
图29和图30是图示针对与多个虚拟声源相对应的多个hrtf中的每个的相位响应彼此不匹配或者匹配的情况中的每一种的输出音频信号的频率响应的幅度分量的示例的图。
具体实施方式
在下文中,将参考附图详细地描述本公开的实施例,使得本公开的实施例能够由本领域的技术人员容易地执行。然而,本公开可以以许多不同的形式被实现,而不限于本文中描述的实施例。在附图中未图示与描述无关的实施例的一些部分,以清楚地描述本公开的实施例。在整个说明书中相似的附图标记指代相似的元件。
当提到了某个部分“包含”或者“包括”某些元件时,除非另外指定,否则该部分还可以包括其它元件。当提到了某个部分“包含”或者“包括”某些元件时,除非另外指定,否则该部分还可以包括其它元件。
本公开涉及一种用于双耳渲染输入音频信号以生成输出音频信号的方法。根据本公开的实施例的音频信号处理设备可以基于其相位响应已发生改变的双耳传递函数对来生成输出音频信号。相位响应表示频率响应的相位分量。另外,音频信号处理设备可以改变与输入音频信号相对应的初始双耳传递函数对的相位响应。根据本公开的实施例的用于处理音频信号的设备可以通过使用具有调整后的相位响应的传递函数来减轻在双耳渲染过程中生成的梳状滤波效果。此外,音频信号处理设备可以在维持输入音频信号的声像定位性能的同时减轻音色失真。在本公开中,传递函数可以包括头部相关传递函数(hrtf)。
在下文中,将参考附图详细地描述本公开。
图1是图示根据本公开的实施例的音频信号处理设备100的配置的框图。根据实施例,音频信号处理设备100可以包括接收单元110、处理器120、和输出单元130。然而,并非图1中图示的所有元件都是音频信号处理设备的必要元件。音频信号处理设备100可以附加地包括图1中未图示的元件。此外,可以省略图1中图示的音频信号处理设备100的元件中的至少一些。
接收单元110可以接收音频信号。接收单元110可以接收输入到音频信号处理设备100的输入音频信号。接收单元110可以接收要由处理器120双耳渲染的输入音频信号。这里,输入音频信号可以包括多声道模拟立体声(ambisonics)信号、目标信号或声道信号中的至少一个。这里,输入音频信号可以是一个目标信号或单声道信号。输入音频信号可以是多目标或多声道信号。根据实施例,当音频信号处理设备100包括单独的解码器时,音频信号处理设备100可以接收输入音频信号的经编码的比特流。
根据实施例,接收单元110可以被配备有用于接收输入音频信号的接收装置。例如,接收单元110可以包括用于接收通过电线发送的输入音频信号的音频信号输入端口。可替选地,接收单元110可以包括用于接收以无线方式发送的音频信号的无线音频接收模块。在这种情况下,接收单元110可以通过使用蓝牙或wi-fi通信方法来接收以无线方式发送的音频信号。
处理器120可以控制音频信号处理设备100的整体操作。处理器120可以控制音频信号处理装置100的每个组件。处理器120可以针对各种数据和信号执行操作和过程。处理器120可以以半导体芯片或电子电路的形式作为硬件被实现,或者可以作为控制硬件的软件被实现。处理器120可以作为硬件和软件的组合被实现。例如,处理器120可以通过执行至少一个程序来控制接收单元110和输出单元130的操作。此外,处理器120可以执行至少一个程序来执行在下面参考图2至图30所描述的音频信号处理设备100的操作。
例如,处理器120可以生成输出音频信号。处理器120可以通过双耳渲染通过接收单元110接收到的输入音频信号来生成输出音频信号。处理器120可以通过将稍后描述的输出单元130来输出输出音频信号。根据实施例,输出音频信号可以是双耳音频信号。例如,输出音频信号可以是将输入音频信号表示为位于三维空间中的虚拟声源的2声道音频信号。处理器120可以基于将稍后描述的传递函数对来执行双耳渲染。处理器120可以在时域或频域中执行双耳渲染。
根据实施例,处理器120可以通过双耳渲染输入音频信号来生成2声道输出音频信号。例如,处理器120可以生成分别与收听者的两只耳朵相对应的2声道输出音频信号。这里,该2声道输出音频信号可以是双道立体声2声道输出音频信号。处理器120可以通过双耳渲染上面提到的输入音频信号来生成在三个维度上表示的音频耳机信号。
根据实施例,处理器120可以通过基于传递函数对进行双耳渲染输入音频信号来生成输出音频信号。传递函数对可以包括至少一个传递函数。例如,传递函数对可以包括与收听者的两只耳朵相对应的一对传递函数。传递函数对可以包括同侧传递函数和对侧传递函数。详细地,传递函数对可以包括与用于同侧耳朵的声道相对应的同侧头部相关传递函数(hrtf)和与用于对侧耳朵的声道相对应的对侧hrft。在下文中,为了说明的方便,如果没有特殊描述,则传递函数(或hrtf)被用作指示传递函数(或hrtf)对中包括的至少一个传递函数的术语。
根据一个实施例,处理器120可以基于与输入音频信号相对应的虚拟声源的位置确定传递函数对。在这种情况下,处理器120可以从除音频信号处理设备100以外的另一装置(未图示)获得传递函数对。例如,处理器120可以从包括多个传递函数的数据库接收至少一个传递函数。数据库可以是存储包括多个传递函数对的传递函数的集合的外部设备。在这种情况下,音频信号处理设备100可以包括用于向数据库请求传递函数并且从数据库接收关于传递函数的信息的单独的通信单元(未示出)。处理器120可以基于音频信号处理设备100中存储的传递函数的集合来获得与输入音频信号相对应的传递函数对。处理器120可以基于所获取的传递函数对来双耳地渲染输入音频信号,以生成输出音频信号。
根据实施例,可以对处理器120的输出音频信号附加地执行后处理。后处理可以包括串扰消除、动态范围控制(drc)、声音音量正规化、峰值限制等。此外,后处理可以包括用于处理器120的输出音频信号的频域/时域转换。音频信号处理设备100可以包括用于执行后处理的单独的后处理单元,并且根据另一实施例,后处理单元可以被包括在处理器120中。
输出单元130可以输出输出音频信号。输出单元130可以输出由处理器120生成的输出音频信号。输出单元130可以包括至少一个输出声道。这里,输出音频信号可以是分别与收听者的两只耳朵相对应的2声道输出音频信号。输出音频信号可以是双耳的2声道输出音频信号。输出单元130可以输出由处理器120生成的3d音频耳机信号。
根据实施例,输出单元130可以被配备有用于输出输出音频信号的输出装置。例如,输出单元130可以包括用于外部地输出输出音频信号的输出端口。这里,音频信号处理设备100可以将输出音频信号输出到连接到输出端口的外部设备。输出单元130可以包括用于外部地输出输出音频信号的无线音频发送模块。在这种情况下,输出单元130可以通过使用诸如蓝牙或wi-fi的无线通信方法来将输出音频信号输出到外部设备。输出单元130可以包括扬声器。这里,音频信号处理设备100可以通过扬声器来输出输出音频信号。此外,输出单元130可以附加地包括用于将数字音频信号转换为模拟音频信号的转换器(例如,数模转换器dac)。
虚拟现实中的双耳渲染的音频信号可以与附加信号组合以增加可再现性。因此,音频信号处理设备可以生成基于多个滤波器来双耳渲染输入音频信号的双耳滤波器。此外,音频信号处理设备可以基于多个滤波器合成经滤波的音频信号。在这种情况下,最终输出音频信号的质量可能由于多个滤波器的频率响应的相位特性之间的差异(即,时域中的时间延迟差异)而劣化。这是因为输出音频信号的音色可能由于梳状滤波效果而失真。
因此,音频信号处理设备可以修改与相对于收听者的每个具体位置相对应的位置特定的hrtf的相位响应。例如,位置特定的hrtf可以包括与在单位球体上的相对于收听者的每个位置相对应的hrtf。根据本公开的实施例,音频信号处理设备可以通过使用同侧hrtf的相位响应被修改为彼此一致的传递函数的集合来双耳渲染输入音频信号。音频信号处理设备可以使同侧hrtf的针对每个位置的相位响应中的每个同步以具有相同的线性相位响应。此外,音频信号处理设备可以使位置特定的对侧hrtf的相位响应中的每个线性化。
在下文中,将参考图2描述根据本公开的实施例的音频信号处理设备的操作方法。图2是示出根据本公开的实施例的音频信号处理设备的操作的框图。根据实施例,音频信号处理设备可以双耳渲染输入音频信号(s101)以生成输出音频信号。音频信号处理设备可以基于从传递函数的集合来获得的hrtf对来双耳渲染输入音频信号。具体地,音频信号处理设备可以获得包括与相对于收听者的每个具体位置相对应的多个hrtf的hrtf集合。音频信号处理设备可以获得由音频信号处理设备或外部装置测量的hrtf集合。在本公开中,“头部相关传递函数(hrtf)”可以用于指代用于双耳渲染输入音频信号的双耳传递函数。双耳传递函数可以包括耳间传递函数(itf)、修改itf(mitf)、双耳房间传递函数(brtf)、房间脉冲响应(rir)、双耳房间脉冲响应(brir)、头部相关脉冲响应(hrir)或其修改/编辑数据中的至少一种,但是本公开不限于此。例如,双耳传递函数可以包括通过线性地组合多个双耳传递函数而获得的二次双耳传递函数。hrtf可以是hrir的快速傅立叶变换(fft),但是转换方法不限于此。
可以在消声房间中测量hrtf。hrtf还可以包括关于通过模拟估计的hrtf的信息。用于估计hrtf的模拟方法可以是球形头部模型(shm)、雪人模型、有限差时域法(fdtdm)、或边界元素法(bem)中的至少一种。在这种情况下,球形头部模型表示其中人类头部被假定为球形的模拟技术。此外,雪人模型表示其中头部和身体被假定为球形的模拟技术。
此外,该hrtf集合可以包括hrtf对,该hrtf对被限定为与预定角间隔的角度相对应。例如,预定角间隔可以是1度或10度,但是本公开不限于此。在本公开中,角度可以包括方位角、仰角、及其组合。例如,该hrtf集合可以包括与相对于球体(具有预定值作为球体的半径)的中心的方位角和仰角的每个组合相对应的头部传递函数。此外,在本公开中,定义方位角和仰角的任何坐标系统可以是垂直极坐标系统(vpc)或耳间极坐标系统(ipc)。另外,音频信号处理设备可以使用针对每个预定角间隔而定义的hrtf对来获得与预定角间隔之间的角度相对应的一对hrtf。将稍后参考图10和图11对此进行描述。
根据实施例,音频信号处理设备可以获得其相位响应被修改的传递函数的集合(hrtf'集合)。例如,音频信号处理设备可以从获得的传递函数的集合(hrtf集合)生成其相位响应被修改的传输函数的集合(hrtf'集合)。音频信号处理设备可以从外部设备获得其相位响应被修改的传递函数的集合(hrtf'集合)或一对hrtf。此外,音频信号处理设备可以基于其相位响应被修改的传递函数的集合(hrtf'集合)双耳渲染输入音频信号。
例如,音频信号处理设备可以获得其相位响应已被修改的hrtf'(s102)。具体地,音频信号处理设备可以从传递函数的集合获得与输入音频信号相对应的hrtf对。例如,音频信号处理设备可以获得基于与输入音频信号相对应的虚拟声源的相对于收听者的位置来模拟输入音频信号的至少一个hrtf对。当存在与输入音频信号相对应的多个虚拟声源时,可以提供与输入音频信号相对应的多个hrtf对。另外,音频信号处理设备可以基于虚拟声源的位置获得多个hrtf对。例如,当由虚拟声源模拟的目标的大小等于或大于预定大小时,音频信号处理设备可以基于多个hrtf对获得输出音频信号。另外,该hrtf对可以是由与不同位置相对应的同侧hrtf和对侧hrtf组成的对。例如,音频信号处理设备可以基于与输入音频信号相对应的虚拟声源的位置来获得与不同位置相对应的同侧hrtf和对侧hrtf。
接下来,音频信号处理设备可以修改hrtf对的相位响应。此外,音频信号处理设备可以从外部设备接收其相位响应已被修改的hrtf'集合。在这种情况下,音频信号处理设备可以从经修改的hrtf'集合获得其相位响应已被修改的hrtf'对。接下来,音频信号处理设备可以基于其相位响应已被修改的hrtf'对来双耳渲染输入音频信号。参考图3至图30所描述的音频信号处理设备的操作中的至少一些可以由另一设备执行。例如,可以通过外部设备来执行针对在下面描述的传递函数中的每个修改相位响应。在这种情况下,音频信号处理设备可以从外部装置接收具有经修改的相位特性的传递函数。另外,音频信号处理设备可以基于具有经修改的相位特性的传递函数生成输出音频信号。
在下文中,将参考图3至图9描述根据本公开的实施例的用于修改在获得的hrtf集合中包括的多个hrtf中的每个的相位响应的方法。为了方便,针对包括在所获得的hrtf集合中的多个hrtf对当中的一对的处理方法将作为示例被描述。在下面描述的音频信号处理设备的操作方法可以被应用于在hrtf集合中包括的全部hrtf对。
图3是具体地图示用于根据本公开的实施例的音频信号处理设备修改原始hrtf对的相位响应的方法的图。在这种情况下,原始hrtf对可以表示测量的hrtf。根据实施例,音频信号处理设备可以分析所获得的原始hrtf对。音频信号处理设备可以基于与来自前述hrtf集合的输入音频信号相对应的虚拟声源的位置获得原始hrtf对。在这种情况下,该组hrtf集合可以包括与相对于收听者的每个具体位置相对应的hrtf对。另外,hrtf对可以包括同侧hrtf和对侧hrtf。在下文中,为了方便,不限于在同侧或对侧的hrtf可以表示同侧hrtf和对侧hrtf中的任何一个。参考图3,音频信号处理设备可以分别处理同侧hrtf和对侧hrtf中的每个的幅度响应(a)和相位响应(phi)。幅度响应表示频率响应的幅度分量。相位响应表示频率响应的相位分量。
接下来,音频信号处理设备可以通过修改原始hrtf的相位响应来获得最终hrtf对。在本公开中对相位响应的修改可以包括对相位响应的与某些频率区间(bin)相对应的相位值的替换、取代或校正。可替选地,可以维持针对hrtf集合中包括的多个hrtf中的一些的相位响应。具体地,音频信号处理设备可以通过将原始同侧hrtf的相位响应设定为公共同侧相位响应来获得最终同侧hrtf。这里,公共同侧相位响应可以是针对在hrtf集合中包括的多个同侧hrtf的单相响应。
例如,音频信号处理设备可以将同侧hrtf根据相对于收听者的每个具体位置的相位响应中的每个设定为不管与同侧hrtf中的每个相对应的位置都是相同的具体相位响应。音频信号处理设备可以使最终同侧hrtf的相位响应与不管与输入音频信号相对应的虚拟声源的位置都是相同的公共同侧相位响应相匹配。在人类听觉的情景的情况下,可以基于人类的两只耳朵之间的声音音量差和到达时间差来辨识声源的位置。因此,音频信号处理设备可以固定与位置无关的响应中的同侧或对侧的相位响应。以这种方式,音频信号处理设备可以减少要存储的数据量。例如,音频信号处理设备可以固定同侧hrtf的相位响应。因为音频信号的能量在同侧比在对侧大。另外,音频信号处理设备可以基于hrtf对中包括的同侧hrtf和对侧hrtf的针对每个位置的相位响应之间的差异,来设定非固定侧的相位响应。根据实施例,公共同侧相位响应可以是具有线性特性的线性响应。将稍后参考图4和图5对此进行描述。
另外,音频信号处理设备可以修改原始对侧hrtf的相位响应以获得最终对侧hrtf。音频信号处理设备可以基于表示同侧与对侧之间的相位差的耳间相位差(ipd)来获得针对最终对侧hrtf的对侧相位响应。例如,音频信号处理设备可以基于最终同侧hrtf的相位响应确定对侧相位响应。
具体地,音频信号处理设备可以基于相对于收听者的每个具体位置的ipd获得与输入音频信号相对应的ipd。音频信号处理设备可以计算原始同侧hrtf与原始对侧hrtf之间的相位差,以获得与输入音频信号相对应的ipd。音频信号处理设备可以基于同侧hrtf和对侧hrtf的针对每个频率区间的相位响应之间的差异获得对侧相位响应。同时,可以在时域中执行hrtf的相位响应变形。例如,音频信号处理设备可以对从hrtf转换的hrir应用组延迟。将稍后参考图6至图9对此进行描述。接下来,音频信号处理设备可以基于彼此单独地处理的幅度响应a和经修改的相位响应phi'来生成最终hrtf对(hrtf'对)。在这种情况下,可以以复数(a*exp(j*phi_i),a*exp(j*phi_c))的形式表达最终hrtf对。
同时,在原始hrtf集合中包括的原始同侧hrtf的相位响应的斜率对每个频率来说可以不是恒定的。因为测量误差或对目标的过拟合,原始hrtf的相位响应不太可能是理想线性相位响应。在这种情况下,hrtf的针对每个频率区间的时间延迟由于针对每个频率区间的相位值之间的差异而在时域中变化,使得可以发生音色的附加失真。根据实施例,音频信号处理设备可以基于其相位特征在频域中被线性化的同侧hrtf生成输出音频信号。在上面参考图3所描述的实施例中,音频信号处理设备可以使针对多个同侧hrtf的公共同侧相位响应线性化。也就是说,音频信号处理设备可以匹配hrtf的频率区间的时间延迟。因此,音频信号处理设备可以减少通过针对每个频率分量的不同时间延迟所引起的音色失真。在下文中,将参考图4和图5来描述使hrtf的相位响应线性化的方法。
图4是图示hrtf的原始相位响应和从相对应的原始相位响应线性化的相位响应的图。在图4中,hrtf的原始相位响应被以展开相位响应的形式示出。音频信号处理设备可以通过使用展开相位响应来使hrtf的相位响应线性化。参考图4,音频信号处理设备可以通过连接hrtf的与dc(直流)频率区间相对应的相位值和hrtf的与奈奎斯特(nyquist)频率区间相对应的相位值来将hrtf的相位响应近似为线性相位响应。具体地,音频信号处理设备可以像公式1中所示的那样使hrtf的相位响应线性化。
[公式1]
phi_unwrap,lin[k]=(phi_unwrap[hn]-phi_unwrap[0])/hn*k+phi_unwrap[0],其中k是整数且0≤k≤hn。
在公式1中,k指示频率区间的索引。另外,hn指示奈奎斯特频率区间,并且phi_unwrap[hn]指示奈奎斯特频率区间处的展开相位值。phi_unwrap[0]指示与频率区间dc相对应的展开相位值,并且phi_unwrap,lin[k]表示与频率区间k相对应的线性化展开相位值。如在公式1中一样,音频信号处理设备可以通过使用相位响应的线性近似斜率来获得用于每个频率区间的相位值。音频信号处理设备可以卷绕展开相位响应,以便成为相位轴中的(-π,π)之间的值以获得卷绕相位响应。此外,如在图3中一样,音频信号处理设备可以基于单独地处理的幅度响应和卷绕相位响应获得最终hrtf。
图5示出在hrtf对中包括的左侧hrtf和右侧hrtf中的每个的线性化相位响应。左侧hrtf可以是同侧hrtf,而右侧hrtf可以是对侧hrtf。同侧音频信号的组延迟较短,并且因此同侧hrtf的相位响应的斜率的绝对值可以小于对侧hrtf的相位响应的斜率的绝对值。在图5中,用于左侧hrtf与右侧hrtf之间的每个频率区间(k)的相位值的差(ipd[k])可以通过公式2进行指示。公式2指示当左侧hrtf和右侧hrtf的相位响应被线性化时的ipd。在公式2中,phi_unwrap,lin,left[k]和phi_unwrap,lin,right[k]分别表示左侧hrtf和右侧hrtf针对每个频率区间k的展开相位值。
[公式2]
ipd[k]=phi_unwrap,lin,left[k]–phi_unwrap,lin,right[k]
在图5中,可以将左侧hrtf的相位响应与右侧hrtf的相位响应之间的斜率差表示为时域中的组延迟差。例如,同侧hrtf和对侧hrtf的相位响应之间的斜率差异越大,同侧组延迟与对侧组延迟之间的差越大。另外,当音频信号处理设备将组延迟应用于hrir时,相对应的hrtf的相位响应可以是线性相位响应。这里,组延迟可以表示在时域中通常使hrir中包括的滤波器系数延迟的延迟时间。另外,当hrtf的相位响应是零相位响应时,音频信号处理设备可以在不需要任何修改的情况下将所确定的组延迟应用于hrir。在下文中,将描述用于获得与线性化对侧相位响应相对应的对侧组延迟的方法。
如上所述,根据本公开的实施例的音频信号处理设备可以执行在时域中修改hrtf的相位响应的过程的至少一部分。例如,音频信号处理设备可以将hrtf转换为hrir,所述hrir是时域中的响应。在这种情况下,hrtf的相位响应可以是零相位响应。在零相位响应的情况下,可以像稍后所描述的那样减少对音频信号处理需要的计算量。音频信号处理设备可以对hrtf执行快速傅里叶逆变换(ifft)以获得hrir。接下来,音频信号处理设备可以通过分别基于组延迟使同侧hrir和对侧hrir时间延迟来修改hrtf的相位响应。另外,当将应用hrir的组延迟转换为应于hrtf(其是频域响应)的组延迟时,hrtf的相位响应可以是上述的线性相位响应。
具体地,音频信号处理设备可以通过基于时域中的同侧组延迟使同侧hrir延迟来生成最终同侧hrir。在这种情况下,同侧组延迟可以是与由hrtf模拟的虚拟声源的位置无关的值。例如,同侧组延迟可以是基于输入音频信号的帧大小而设定的值。另外,帧大小可以指示一个帧中包括的样本的数目。因此,音频信号处理设备可以基于时间‘0’来防止hrir的滤波器系数超出帧大小。音频信号处理设备可以将相同的同侧组延迟应用于hrir集合中包括的多个同侧hrir。音频信号处理设备可以通过基于同侧组延迟使同侧hrir延迟来获得最终同侧hrir。另外,音频信号处理设备可以将应用了同侧组延迟的hrir转换为频域的响应以获得最终同侧hrtf。
另外,音频信号处理设备可以通过基于时域中的对侧组延迟使对侧hrir延迟来生成最终对侧hrir。在这种情况下,与同侧组延迟不同的是,对侧组延迟可以是基于由对侧hrtf模拟的虚拟声源的位置而设定的值。这是因为耳间时间差(itd)可以根据与输入音频信号相对应的虚拟声源的相对于收听者的位置而变化,这指示音频信号在同侧与对侧之间的到达时间差。音频信号处理设备可以基于针对相对于收听者的每个具体位置的itd确定用于应用于对侧hrir的对侧组延迟。在这种情况下,对侧组延迟可以是添加到同侧组延迟时间的、针对与输入音频信号相对应的虚拟声源的相对于收听者的位置的itd时间。
另外,音频信号处理设备可以将应用了对侧组延迟的hrir转换为频域的响应以获得最终对侧hrtf。在这种情况下,随着对侧hrtf的相位响应的斜率增加,对侧组延迟值增加。另外,音频信号处理设备可以基于同侧hrir和itd的组延迟确定针对相对于收听者的每个具体位置的不同对侧组延迟。在下文中,将参考图6至图9详细地描述由根据本公开的实施例的音频信号处理设备获得itd的方法。
根据实施例,音频信号处理设备可以基于同侧hrir(或hrtf)与对侧hrir(或hrtf)之间的相关性来获得itd(或ipd)。在这种情况下,hrir可以是个性化hrir。这是因为同侧hrir与对侧hrir(或hrtf)之间的交叉相关可以根据收听者的头部模型而变化。音频信号处理设备还可以通过使用作为基于收听者的头部模型的测量响应的个性化hrir来获得itd。音频信号处理设备可以像下面的公式3中所示的那样基于同侧hrir与对侧hrir之间的交叉相关来计算itd。
[公式3]
maxdelay=xcorr(hrir_cont,hrir_ipsil),
itd=abs(maxdelay-hrir_length)
在公式3中,xcorr(x,y)是输出与针对每个延迟时间的x和y之间的交叉相关当中的最高交叉相关相对应的延迟时间(maxdelay)的索引的函数。在公式3中,hrir_cont和hrir_ipsil分别指示对侧hrir和同侧hrir,并且hrir_length指示时域中的hrir滤波器的长度。
图6和图7是图示根据本公开的实施例的用于音频信号处理设备以针对耳间极坐标(ipc)系统中的方位角来获得itd的方法的图。根据实施例,音频信号处理设备可以针对ipc中的方位角来获得与矢状平面(恒定方位角平面)610相对应的itd。在这种情况下,矢状平面可以是平行于中间平面的平面。另外,中间平面可以是垂直于水平面620并且具有与水平面相同的中心的平面。
具体地,音频信号处理设备包括针对与多个点601、602、603和604中的每个相对应的仰角的itd,其中可以获得与第一方位角角度630相对应的矢状平面以及以满足收听者为中心的单位球体。在这种情况下,多个点601、602、603和604可以在ipc中具有相同的方位角和不同的仰角。另外,音频信号处理设备可以基于针对每个仰角的itd获得与第一方位角630相对应的公共itd。例如,音频信号处理设备可以使用针对每个仰角的itd的平均值、中值、和模式值中的任何一个作为与第一方位角角度630相对应的组itd。在这种情况下,音频信号处理设备可以基于该组itd确定同样地适用于与第一方位角角度630相对应的并且具有不同的仰角角度的多个对侧hrtf的对侧组延迟。
公式4表示音频信号处理设备的在音频信号处理设备使用针对每个仰角的itd的中值作为组itd时的操作过程。
[公式4]
t_cont=median{argmax_t(xcorr(hrir_cont(n,a,e),hrir_ipsil(n,a,e)))-hrir_length}+t_pers+t_ipsil
在公式4中,xcorr(x,y)是输出与针对每个延迟时间的x和y之间的交叉相关当中的最高交叉相关相对应的延迟时间(maxdelay)的索引的函数。在公式4中,hrir_cont和hrir_ipsil分别指示对侧hrir和同侧hrir,并且hrir_length指示时域中的hrir滤波器的长度。t_pers指示针对每个收听者的个性化的附加延迟,‘a’指示方位角索引,‘e’指示仰角索引,以及t_ipsil指示同侧组延迟。图7是示出根据方位角的、根据公式4应用于左侧hrtf和右侧hrtf中的每个的组延迟的示例。在图7中,当虚拟声源的位置是从0度到180度的方位角时,收听者的左侧与对侧相对应,并且收听者的右侧与同侧相对应。当虚拟声源的位置是从180度到360度时,收听者的左侧与同侧相对应并且收听者的右侧与对侧相对应。
根据实施例,音频信号处理设备可以基于收听者的头部建模信息获得对侧相位响应。这是因为itd可以根据收听者的头部形状而变化。音频信号处理设备可以使用收听者的头部建模信息来确定个性化对侧组延迟。例如,音频信号处理设备可以基于收听者的头部建模信息和与输入音频信号相对应的虚拟声源的相对于收听者的位置来确定对侧组延迟。
图8是图示根据本公开的实施例的用于音频信号处理设备以通过使用收听者的头部建模信息来获得itd的方法的图。头部建模信息可以包括基于收听者的头部的近似球体的半径(即,头部大小信息)和收听者的两只耳朵的位置中的至少一种,但是本公开不限于此。音频信号处理设备可以基于收听者的头部大小信息、基于收听者的头部方向的虚拟声源的位置、以及收听者与虚拟声源之间的距离中的至少一个来获得itd。这里,收听者与虚拟声源之间的距离可以是从收听者的中心到声源的距离,或从收听者的同侧耳朵/对侧耳朵到声源的距离。具体地,可以将声音分别从虚拟声源到达收听者的同侧耳朵和对侧耳朵处的时间(tau_ipsil、tau_cont)表示为公式5。
[公式5]
d_cont=sqrt((1m)^2+r^2-2*r*cos(90+abs(theta)))
tau_cont=d_cont/c
d_ipsil=sqrt((1m)^2+r^2-2*r*cos(90-abs(theta)))
tau_ipsil=d_ipsil/c,
其中c是声速(343m/s),并且-90<theta<90。
在公式5中,‘r’可以是基于收听者的头部的近似球体的半径。可替选地,‘r’可以是从收听者的头部中心到两只耳朵的距离。在这种情况下,从收听者的头部中心到同侧耳朵和到对侧耳朵的距离可以是彼此不同的(例如,r1和r2)。另外,‘1m’指示从收听者的头部中心到与输入音频信号相对应的虚拟声源的距离。d_cont指示从收听者的对侧耳朵到虚拟声源的距离,以及d_ipsil指示从收听者的同侧耳朵到虚拟声源的距离。音频信号处理设备可以基于针对相对于收听者的每个具体位置而测量的个性化itd来确定对侧组延迟。
图9是图示根据本公开的另一实施例的用于音频信号处理设备以通过使用收听者的头部建模信息来获得itd的方法的图。参考图9,此时声音到达收听者的与对侧相对应的左侧的时间t_l与左侧hrtf的相位响应phi_l之间的关系,以及此时声音到达收听者的与同侧相对应的右侧的时间t_r与右侧hrtf的相位响应phi_r之间的关系分别可以如公式6中所示。
[公式6]
phi_l=-w·t_l
phi_r=-w·t_r
在公式6中,‘w’指示角频率。phi_l和phi_r相对于‘w’的导数值分别恒定为-t_l和-t_r。因此,左侧和右侧中的每个的组延迟分别可以在整个频域中相同。音频信号处理设备可以基于虚拟声源的位置和头部大小信息获得t_l和t_r。例如,音频信号处理设备可以通过像公式7中所示的那样基于虚拟声源与右耳之间的距离d以及基于收听者的头部的近似球体的半径r进行计算来获得t_l和t_r。
[公式7]
t_r=d/c
其中,t_l=t_r+(r+pi*r/2)/c,并且pi是圆周率。
另外,根据实施例,音频信号处理设备可以通过除了添加所获得的itd之外还添加附加延迟来计算经修改的itd'。例如,音频信号处理设备可以通过根据收听者与声源之间的角度添加不同的附加延迟(delay_add)来计算经修改的itd'。公式8示出通过相对于通过收听者和声源的位置确定的方位角来划分截面,从而添加附加延迟(delay_add)的方法。在公式8中,对每个方位角截面来说,“斜率”可以指示基于用户输入而设定的相位响应的斜率。另外,round(x)指示用于输出四舍舍入x值的结果的函数。并且d1和d2指示用于针对每个方位角截面确定相位响应的斜率的参数。例如,音频信号处理设备可以分别基于用户输入来设定d1和d2的值。
[公式8]
itds’=itds+delay_add
delay_add=round(slope*azimuth),
其中,if0<=azimuth<=45,thenslope=1/d1(0<d1并且d1是整数),并且if45<azimuth<=90,thenslope=1/d2(0<d2并且d2是整数)
另外,根据实施例,组延迟可以是与基于采样频率的整数个样本相对应的延迟时间。在这种情况下,可以增加其特性已被修改的音频信号的附加利用。音频信号处理设备可以设定为样本的整数倍的同侧组延迟和对侧组延迟。另外,当发生超出帧大小的样本时,音频信号处理设备可以基于来自hrir样本的前面的峰值点截断与超出帧大小的样本对称的区域。因此,音频信号处理设备可以减少通过超出帧大小的样本所引起的声音质量劣化。
同时,为了执行覆盖收听者周围的虚拟三维空间上的所有点的双耳渲染,音频信号处理设备需要获得与所有点相对应的hrtf。然而,因为测量过程中的约束和可存储数据的容量是有限的,所以可能要求附加处理来获得与虚拟三维空间中的所有点相对应的hrtf。此外,在基于测量的hrtf的情况下,由于在测量过程期间发生的幅度响应和相位响应中的误差而可能要求附加处理。
因此,通过使用先前获得的多个hrtf,音频信号处理设备可以生成与除多个获得的hrtf中的每个hrtf的位置以外的位置相对应的hrtf。因此,音频信号处理设备可以增强在虚拟三维空间中模拟的音频信号的空间分辨率,并且校正幅度响应和相位响应中的误差。在下文中,将参考图10至图14描述用于由根据本公开的实施例的音频信号处理设备获得对应于除与在hrtf集合中包括的多个hrtf相对应的位置以外的位置的hrtf的方法。
图10是图示根据本公开的实施例的用于音频信号以增强空间分辨率的方法的图。根据实施例,音频信号处理设备可以获得包含与m个位置中的每个相对应的原始hrtf对的原始的hrtf集合。音频信号处理设备可以基于原始的hrtf集合来获得包括与n个位置中的每个相对应的hrtf对的扩展的hrtf集合。在这种情况下,n可以是大于m的整数。此外,扩展的hrtf集合除了包括原始的hrtf集合之外还可以包括(n-m)个附加hrtf对。在这种情况下,音频信号处理设备可以通过修改在原始的hrtf集合中包括的m个hrtf对中的每一对的相位响应来配置所扩展的hrtf集合。在这种情况下,音频信号处理设备可以通过上述的图2至图9中描述的方法来修改在原始hrtf集合中包括的hrtf中的每个的相位响应。
此外,音频信号处理设备可以在处理原始hrtf对时接收到要添加的(n-m)个hrtf中的至少一个的输入、要添加的hrtf的位置、或组延迟。具体地,原始的hrtf集合可以包括用于根据预定角间距的每个角度的hrtf。其中角度可以是以收听者为中心的单位球体上的方位角或仰角中的至少一个。此外,预定角间距可以包括仰角方向上的角间距和方位角方向上的角间距。在这种情况下,可以将用于仰角方向和方位角方向的角间距设定为彼此不同。
例如,音频信号处理设备可以根据预定角间隔来获得与第一角度和第二角度之间的位置相对应的hrtf。具体地,第一角度和第二角度可以具有相同的方位角值和相隔预定角度间隔的不同的仰角值。在这种情况下,音频信号处理设备可以内插与第一角度相对应的第一hrtf和与第二角度相对应的第二hrtf以生成与第一角度和第二角度之间的不同的仰角的相对应的第三hrtf。在上述方法中,音频信号处理设备可以生成与位于第一角度和第二角度之间的多个位置中的每个相对应的多个hrtf。这里,要经受内插的hrtf的数目被描述为两个,但是这仅仅是示例,并且本公开不限于此。可以内插与具体位置相邻的多个hrtf以获得与该具体位置相对应的hrtf。
在这种情况下,如上所述,当音频信号处理设备在频域中内插多个hrtf时,用于在音频信号处理设备中处理的傅里叶变换和逆傅立叶变换的计算量可以增加。因此,根据本公开的实施例的音频信号处理设备可以修改原始的hrtf集合中包括的多个原始hrtf中的每个的相位响应。此外,音频信号处理设备可以通过在时域中内插其相位响应被修改的多个hrtf来生成扩展的hrir集合。因此,音频信号处理设备可以减少不必要的计算量。在下文中,将参考图11详细地描述用于由音频信号处理设备增加音频信号的空间分辨率的方法。
图11是图示用于根据本公开的实施例的音频信号处理设备从原始的hrir集合生成扩展的hrir集合的方法的图。在步骤s1102中,音频信号处理设备可以初始化原始的hrtf集合中包括的多个原始hrtf中的每个的相位响应。音频信号处理设备可以将多个原始的hrtf中的每个的相位响应修改成使彼此具有相同的相位响应。音频信号处理设备可以匹配与声源的相对于收听者的位置相对应的原始的hrtf中的每个的相位响应,以便在不管声源的位置如何情况下具有相同的相位响应。在这种情况下,在时域中,多个hrir在相同的采样时间处具有峰值。因此,当音频信号处理设备在时域中线性地组合与多个不同的声源的位置相对应的hrtf时,音频信号处理设备可以生成在相同的采样时间处具有峰值的双耳滤波器。此外,即使音频信号处理设备将在频域中具有相同的相位特性的hrtf与另一传递函数线性地组合,音频信号处理设备也可以生成在相同的采样时间处具有峰值的双耳滤波器。
例如,相同的相位响应可以是零相位响应。在零相位响应的情况下,可以促进对基于hrtf的双耳渲染需要的计算过程。如果hrtf是零相位响应,则时域中的hrir可以在时间‘0’处具有峰值。因此,根据本公开的实施例的音频信号处理设备可以针对时域中的多个hrir执行内插以减少用于生成输出音频信号的计算量。同时,音频信号处理设备可以减少由于上述的梳状滤波而导致的音色失真。
根据实施例,音频信号处理设备可以以hrir的形式获得hrtf集合,所述hrir是时域中的响应。在这种情况下,在步骤s1101中,音频信号处理设备可以将所获得的hrtf集合中包括的原始的hrir转换为频域中的响应。例如,音频信号处理设备可以对原始的hrir执行fft以获得频域中的原始的hrtf。另外,音频信号处理设备可以对变换成频域中的响应的原始hrtf执行上述相位响应初始化以获得相位响应被初始化的hrtf。
在步骤s1104中,音频信号处理设备可以将其相位响应已被初始化的hrtf转换为时域中的响应,以获得其相位响应被初始化的hrir。音频信号处理设备可以对其相位响应被初始化的hrtf执行ifft以获得其相位响应被初始化的hrir。在步骤s1106中,音频信号处理设备可以通过在时域中内插每个hrir的相位响应被初始化的至少两个hrir来生成对应于除与原始的hrtf相对应的位置以外的位置的hrir。这是因为如上所述,与其相位响应被初始化的多个hrtf中的每个相对应的多个hrir的峰值的时间位置是彼此一致的。在这种情况下,音频信号处理设备可以基于要添加的hrtf的位置生成要添加的hrir的数目(n-m)。在下文中,包括其相位响应被初始化的hrir和附加地生成的hrir的hrir集合被称为hrir的第一集合。
在步骤s1108中,音频信号处理设备可以将组延迟应用于第一hrir集合中包括的多个第一hrir中的每个以生成扩展的hrir集合。如果hrir的峰值位于时间‘0’处(即,hrtf的相位响应是零相位响应),则在不需要附加编辑的情况下,音频信号处理设备可以将所设定的组延迟应用于在步骤s1106中获得的多个第一hrir中的每个。音频信号处理设备可以基于参考图所描述的用于针对每个同侧和对侧获得组延迟的方法获得应用于多个第一hrir中的每个的组延迟。
例如,音频信号处理可以基于不管声源的位置都为相同值的同侧组延迟使第一hrir集合中包括的多个同侧hrir中的每个时间延迟。在这种情况下,同侧组延迟可以是基于帧大小而设定的值。另外,音频信号处理设备可以基于上述的itd确定应用于第一hrir集合中包括的多个对侧hrir的对侧组延迟。在这种情况下,对侧组延迟可以是添加到同侧组延迟的、根据与输入音频信号相对应的虚拟声源的相对于收听者的位置的itd时间。因此,音频信号处理设备可以基于原始的hrtf集合生成包括比原始的hrtf集合更大数目的hrtf的扩展的hrtf集合。另外,音频信号处理设备可以在计算量和音色失真方面高效地增加收听者周围的虚拟三维空间中的音频信号的空间分辨率。音频信号处理设备可以增加音频信号的空间分辨率以增强声像定位性能。
同时,在图11中,可以省略相位响应初始化过程。例如,音频信号处理设备可以获得其中多个hrtf中的每个的相位响应被初始化的hrtf集合。音频信号处理设备可以获得包括相位响应彼此相同的、与声源的相对于收听者的位置中的每个相对应的多个hrtf的hrtf集合。音频信号处理设备可以从通过图1所描述的存储hrtf集合的数据库获得相位响应被初始化的hrtf集合。另外,音频信号处理设备可以使用被存储在音频信号处理设备中的hrtf集合并且相位响应被初始化。
在下文中,将描述用于根据本公开的实施例的音频信号处理设备基于多个hrtf集合生成最终输出音频信号的方法。以这种方式,音频信号处理设备可以校正通过测量所获得的hrtf的大小响应和相位响应中的误差。图12是图示用于根据本公开的实施例的音频信号处理设备以便线性地组合基于多个hrtf集合而双耳渲染的输出音频信号以生成最终输出音频信号的方法的图。
根据实施例,音频信号处理设备可以获得与第一hrtf集合不同的第二hrtf集合。在这种情况下,第一hrtf集合可以包括多个hrtf,其中作为图11的过程多个hrtf的相位响应被修改。另外,第一hrtf集合和第二hrtf集合可以是以不同方式获得的hrtf集合。例如,第一hrtf集合和第二hrtf集合可以是通过使用不同类型的头部模型测量的hrir集合。如在图12中一样,当音频信号处理设备获得第一hrir集合和第二hrir集合时,音频信号处理设备针对在第一hrir集合和第二hrir集合中包括的多个hrir中的每个执行fft以获得第一hrtf集合和第二hrtf集合。
接下来,音频信号处理设备可以基于相位信息将第二hrtf集合中包括的多个第二hrtf对中的每个的相位响应设定为第一hrtf集合中包括的多个第一hrtf对中的每个的相位响应。例如,音频信号处理设备可以使第二hrtf对中的每个的相位响应与针对每个位置的第一hrtf对的相位响应相匹配。音频信号处理设备可以基于与第一hrtf对和第二hrtf对中的每个相对应的位置匹配多个第一hrtf对和多个第二hrtf对。例如,多个第一hrtf对当中的、与第一位置相对应的第一hrtf对以及多个第二hrtf对当中的、与第一位置相对应的第二hrtf对可以彼此匹配。音频信号处理设备可以基于相位信息将多个第二hrtf对中的每个的相位响应设定为多个已匹配的第一hrtf对中的每个的相位响应。这里,相位信息可以是音频信号处理设备或外部设备中存储的、针对每个位置的第一hrtf对中的每个的相位响应信息。可以将相位信息存储为查找表格形式。
第一hrtf对可以包括第一同侧hrtf和第一同侧hrtf。第二hrtf对还可以包括第二同侧hrtf和第二同侧hrtf。另外,第一hrtf对和第二hrtf对分别可以是与第一位置相对应的hrtf对。例如,音频信号处理设备可以匹配第一同侧hrtf和第二同侧hrtf的相位响应。另外,音频信号处理设备可以匹配第一对侧hrtf和第二对侧hrtf的相位响应。音频信号处理设备可以将第二hrtf对中的每个的相位响应设定为第一hrtf对中的每个的相位响应以生成具有匹配的相位响应的第二hrtf'对。
接下来,音频信号处理设备可以基于多个第一hrtf对中的任何一个双耳渲染输入音频信号以生成第一输出音频信号(图12中的渲染1)。此外,音频信号处理设备可以基于多个第二hrtf'对中的任何一个双耳渲染输入音频信号以生成第二输出音频信号(图12的渲染2)。在这种情况下,如果输入音频信号是时域中的样本,则音频信号处理设备可以附加地执行用于将输入音频信号转换成频域信号的fft过程。接下来,音频信号处理设备可以合成第一输出音频信号和第二输出音频信号以生成最终输出音频信号。此外,音频信号处理设备可以对频域中的最终输出音频信号执行ifft以将它转换成时域中的最终输出音频信号。
同时,除了合成通过单独渲染生成的音频信号的方法之外,还可以线性地组合多个hrtf以生成组合hrtf。在这种情况下,与合成音频信号的方法相比较可以减少对渲染需要的计算量。图13是图示根据本公开的实施例的用于音频信号处理设备以基于通过线性地组合多个hrtf生成的hrtf来生成输出音频信号的方法的图。
根据实施例,音频信号处理设备可以线性地组合如上所述匹配相位响应的第一hrtf对和第二hrtf'对,以生成组合hrtf。这里,线性组合可以意旨中值或平均值。例如,音频信号处理设备可以通过针对每个频率区间基于第一同侧(对侧)hrtf和第二同侧(对侧)hrtf'的幅度响应进行计算来获得组合同侧(对侧)hrtf。因为第一hrtf对和第二hrtf'对的相位响应被匹配,所以不要求单独的线性组合操作。接下来,音频信号处理设备可以基于组合hrtf双耳渲染输入音频信号以生成频域中的最终输出音频信号。此外,音频信号处理设备可以对频域中的最终输出音频信号执行ifft以生成时域中的最终输出音频信号。
图14是图示用于根据本公开的另一实施例的音频信号处理设备以校正hrtf对中的测量误差的方法的图。参考图14中的(a),可以发生其中对侧hrtf的频率响应的幅度可以大于同侧hrtf的频率响应的幅度的反向部分1401。因为收听者从与输入音频信号相对应的虚拟声源起的对侧可能相对远离收听者的同侧,所以反向部分1401可以与测量错误相对应。因此,根据本公开的实施例的音频信号处理设备可以将与反向部分1401中包括的频率区间相对应的对侧hrtf的幅度值修改为预定值。例如,预定值可以是与其处幅度响应的反向开始到停止的频率区间相对应的幅度值。参考图14中的(b),音频信号处理设备可以将与反向部分1401中包括的频率区间相对应的同侧hrtf的幅度值修改为大于或等于对侧hrtf的幅度值的值。因此,音频信号处理设备可以防止与一些频率相对应的声音在收听者的对侧比在收听者的同侧被听到更大声,从而向收听者提供更准确感测方向性。
同时,音频信号处理设备可以使双耳渲染音频信号与附加信号合成以增强双耳渲染音频信号的表现力。此外,音频信号处理设备可以基于通过将hrtf与附加滤波器组合获得的滤波器来双耳渲染音频信号,用于增强输出音频信号的表现力。在本公开中,附加信号可以是基于附加滤波器而生成的音频信号。例如,音频信号处理设备除了使用根据与目标音频信号相对应的虚拟声源的位置的hrtf之外还可以使用一个或多个滤波器来生成输出音频信号。在这种情况下,如果附加滤波器和hrtf的相位响应不匹配,则声音质量可以由于梳状滤波效果而劣化。
图15是图示根据本公开的实施例的音频信号处理设备以在时域中基于多个滤波器生成输出音频信号的操作的框图。在下文中,在与图15至图28有关的实施例中,第一滤波器可以指代如上所述的hrtf或hrir。另外,第二至第n滤波器可以指代附加滤波器。根据实施例,音频信号处理设备可以获得配置有一对增益和一对相位响应的附加滤波器,包括用于输入音频信号的同侧和对侧。另外,音频信号处理设备可以通过使用多个附加滤波器来生成输出音频信号。
在这种情况下,音频信号处理设备可以获得其相位响应已在上面参考图3至图9所描述的方法中被修改的第一滤波器。例如,音频信号处理设备可以使所获得的同侧hrtf和对侧hrtf中的每个的相位响应线性化以生成第一同侧滤波器和第一对侧滤波器。另外,音频信号处理设备可以使多个附加滤波器中的每个的相位响应与第一滤波器的相位响应相匹配。因此,音频信号处理设备可以混合在时域中基于多个滤波器而滤波的音频信号,而不会使音色失真。参考图15,音频信号处理设备可以通过使用第一个至第n个滤波器来生成多个双耳输出音频信号。接下来,音频信号处理设备可以混合多个双耳输出音频信号,以生成最终输出音频信号。在这种情况下,音频信号处理设备可以基于指示此处混合多个双耳输出音频信号中的每个的比率的混合增益来混合多个双耳输出音频信号。同时,在要稍后描述的滤波器组合过程中,可以以在组合滤波器中反应多个滤波器的比率来使用混合增益。
此外,多个附加滤波器中的每个可以是用于不同效果的滤波器。例如,多个附加滤波器可以包括像上面参考图12和图13所描述的那样以不同方式获得的多个hrtf(hrir)。多个附加滤波器可以包括除hrtf以外的滤波器。例如,多个附加滤波器可以包括调整双耳效果强度(bes)的平移滤波器。多个附加滤波器可以包括模拟与输入音频信号相对应的虚拟声源的大小以及从收听者到虚拟声源的距离的滤波器。在下文中,将参考图16至图21描述由音频信号处理设备的、通过使用hrtf和平移滤波器来生成输出音频信号的方法。
图16是图示用于根据本公开的实施例的音频信号处理设备以通过使用平移增益来调整双耳效果强度的方法的图。根据实施例,音频信号处理设备可以使用附加滤波器来调整基于hrtf而双耳渲染的音频信号的双耳效果强度。在这种情况下,附加滤波器可以是与同侧和对侧中的每个相对应的平坦响应。这里,平坦响应可以是在频域中具有恒定幅度的滤波器响应。例如,音频信号处理设备可以通过使用平移增益来获得与同侧和对侧中的每个相对应的平坦响应。
在图16中,音频信号处理设备可以基于第一滤波器(hrir)双耳渲染输入音频信号以生成第一输出音频信号hrir_l、hrir_r。另外,音频信号处理设备可以基于平移增益(交互式平移增益
[公式9]
output_l,r=g_h·s(n)*h_l,r(n)+g_i·s(n)·p_l,r,
在公式9中,g_h可以是第一输出音频信号hrir_l和hrir_r的混合增益。另外,g_i可以是第二输出音频信号p_l、p_r的混合增益。p_l,r指示左声道平移增益或右声道平移增益,并且h_l,r指示左hrir或右hrir。n是大于0且小于样本的总数的整数,并且s(n)表示第n个样本处的输入音频信号。此外,*指示卷积。在这种情况下,音频信号处理设备可以经由傅立叶变换和傅里叶逆变换通过快速卷积方法来对输入音频信号进行滤波。图17是示出左侧和右侧分别根据相对于收听者的方位角的平移增益的图。
根据实施例,音频信号处理设备可以针对同侧增益和对侧增益生成能量补偿的平坦响应。可以根据平坦响应的能量水平变化使输出音频信号的能量水平相对于输入音频信号的能量水平过度地变形。例如,音频信号处理设备可以基于与输入音频信号的虚拟声源相对应的同侧hrtf和对侧hrtf的幅度响应生成平移增益。音频信号处理设备可以计算分别与左侧和右侧相对应的平移增益p_l和p_r,如公式10中所示。例如,音频信号处理设备可以通过使用线性平移方法或恒定功率平移方法来确定平移增益g1和g2。在公式10中,音频信号处理设备可以将与耳朵中的每只相对应的平移增益的和设定为1,以维持输入音频信号的听觉能量。在公式10中,h_meanl表示左侧hrtf的针对每个频率区间的幅度响应的均值,并且h_meanr表示右侧hrtf针对每个频率区间的幅度响应的均值。在这种情况下,a表示ipc(耳间极坐标)中的方位角索引,并且k表示频率区间的索引。
[公式10]
p_l+p_r=1,
p_l=h_meanl(a)/(h_meanl(a)+h_meanr(a)),
p_r=h_meanr(a)/(h_meanl(a)+h_meanr(a)),
其中h_meanl(a)=mean(abs(h_l(k))),并且h_meanr(a)=mean(abs(h_r(k)))
图18是图示根据本公开的实施例的音频信号处理设备在频域中基于第一滤波器和第二滤波器生成输出音频信号的操作的框图。音频信号处理设备可以将输入音频信号转换成频域信号。音频信号处理设备可以基于上述第一滤波器对经转换的信号进行滤波以生成第一输出音频信号。另外,音频信号处理设备可以将向其施加上述平移增益的输入音频信号转换成频域信号,以生成第二输出音频信号。接下来,音频信号处理设备可以基于g_h和g_i混合第一输出音频信号和第二输出音频信号,以生成频域中的最终输出音频信号。音频信号处理设备可以将经混合的最终输出音频信号转换成时域信号。在图18中,可以像公式11中所示的那样表达通过其音频信号处理设备生成最终输出音频信号out_hat的方法。
[公式11]
out_hat=ifft[g_h·mag{s(k)}·mag{h_l,r(k)}·pha{s(k)+h_l,r(k)}+g_i·mag{s(k)}·mag{p_l,r(k)}·pha{s(k)+p_l,r(k)}
在公式11中,h_l,r(k)、p_l,r(k)和s(k)分别指示时域中的h_l,r(n)、p_l,r(n)和s(n)的频率响应。此外,k表示频率区间的索引,并且mag{x}和pha{x}分别表示频率响应‘x’的幅度分量和相位分量。
图19是示出通过图17和图18获得的时域输出音频信号的曲线图。参考图19中的实线,当音频信号处理设备在时域中混合第一输出音频信号和第二输出音频信号时,发生梳状滤波效果。另一方面,参考图19中的虚线,当音频信号处理设备在频域中混合第一输出音频信号和第二输出音频信号时,未发生梳状滤波效果。这是因为音频信号处理设备可以在频域中单独地内插多个音频信号的幅度分量和相位分量。然而,如图18中所示,当音频信号处理设备在频域中使音频信号的幅度分量和相位分量的过程分离时,可以增加计算量。由于计算的这种增加,可能难以在诸如对计算量有限制的移动设备的设备中线性地组合音频信号。因此,根据本公开的实施例的音频信号处理设备可以匹配在同侧和在对侧(或左侧和右侧)的多个滤波器中的每个的相位响应。因此,音频信号处理设备可以减少对内插需要的计算量。
图20是示出由根据本公开的实施例的音频信号处理设备基于在同侧上和在对侧上匹配的相位响应来生成输出音频信号的方法的框图。根据实施例,音频信号处理设备可以基于与输入音频信号相对应的虚拟声源的位置获得hrtf对。另外,音频信号处理设备可以通过上面参考图3至图9所描述的方法来修改hrtf对中包括的同侧hrtf和对侧hrtf中的每个的相位响应。在这种情况下,在不管包括用于hrtf集合中包括的多个同侧hrtf中的每个的声源的位置如何的情况下,音频信号处理设备可以将同侧hrtf的相位响应修改为相同的公共相位响应。此外,经修改的同侧hrtf和对侧hrtf中的每个的相位响应可以是线性相位响应。接下来,音频信号处理设备可以使基于平移增益而生成的同侧平移滤波器和对侧平移滤波器的相位响应与同侧hrtf和对侧hrtf中的每个的相位响应相匹配。音频信号处理设备可以基于混合增益g_h和g_i混合应用了hrtf的第一输出音频信号和应用了平移滤波器的第二输出音频信号。基于已匹配相位h_lin(k)而生成的最终输出音频信号out_hat_lin可以通过公式12来表达。
[公式12]
out_hat_lin=ifft[g_h·mag{h_lin(k)}·mag{s(k)}·pha{h_lin(k)+s(k)}+g_i·mag{p_l,r(k)}·mag{s(k)}·pha{h_lin(k)+s(k)}]
此外,音频信号处理设备可以省略傅里叶变换操作的至少一部分以减少对生成最终输出音频信号需要的计算量。图21是图示用于根据本公开的实施例的音频信号处理设备基于hrtf和附加滤波器来生成输出音频信号的方法的框图。根据实施例,音频信号处理设备可以在时域中将平移增益应用于输入音频信号的幅度响应。另外,音频信号处理设备可以基于组延迟通过使向其施加平移增益的输入音频信号时间延迟来生成第二输出音频信号。在这种情况下,同侧组延迟和对侧组延迟中的每个均可以是与同侧hrtf和对侧hrtf中的每个的相位响应相对应的组延迟。另外,同侧hrtf和对侧hrtf中的每个的相位响应可以是线性相位响应。音频信号处理设备可以通过如在公式13中一样的操作像在公式12中那样生成最终输出音频信号out_hat_lin。在公式13中,t_cont,ipsil表示个性化相对侧或同侧组延迟。
[公式13]
out_hat_lin=ifft[g_h·mag{h_lin(k)}·mag{s(k)}·pha{h_lin(k)+s(k)}]+g_i·p_l,r·s(n-t_cont,ipsil)
同时,如上所述,附加滤波器可以包括用于模拟与输入音频信号相对应的虚拟声源的空间特性的空间滤波器。在这种情况下,空间特性可以包括扩散、体积化、模糊、或宽度控制效果中的至少一种。通过使用hrtf进行声音定位的声源的特征是点状的。因此,用户可以体验到声音效果,使得从与三维空间上的虚拟声源相对应的位置听到输入音频信号。
然而,在逼真的三维空间声音中,声音的几何特征可以根据与声音相对应的声源的大小和从收听者到声源的距离而改变。例如,波浪或雷的声音可以是具有区域特征的声音而不是从具体点听到的声音。同时,用于在除点以外的声源上再现效果的双耳滤波器可能难以通过测量来生成。此外,为了在除点以外的声源上再现效果,可能难以构建用于存储与各种声源环境相对应的数据的系统容量。
因此,音频信号处理设备可以基于所获得的hrtf生成空间滤波器。此外,音频信号处理设备可以基于所获得的hrtf和空间滤波器生成输出音频信号。在下文中,将参考图22至图28描述通过其音频信号处理设备通过使用另一附加滤波器来生成输出音频信号的方法。图22示出由空间滤波器进行的声音效果的示例。在图22中,收听者2210可以分别区分具有点特征的虚拟声源2201以及分别具有不同大小的区域的第一扩散声源2202和第二扩散声源2203。这在声学上是基于表现源宽度(asw)认知效果。
图23是图示用于根据本公开的实施例的音频信号处理设备以基于多个滤波器生成输出音频信号的方法的图。根据实施例,音频信号处理设备可以基于通过与输入音频信号相对应的虚拟声源建模的目标的大小以及从收听者到虚拟声源的距离来生成空间滤波器。音频信号处理设备可以基于空间滤波器生成第二输出音频信号。音频信号处理设备可以混合上述的第一输出音频信号和基于空间滤波器而生成的第二输出音频信号,以生成最终输出音频信号。在图23中,音频信号处理设备可以像公式14中所示的那样生成左侧输出音频信号y_l和右侧输出音频信号y_r。
[公式14]
y_l=g_h·h_l*s+g_d·d_l*s
y_r=g_h·h_r*s+g_d·d_r*s
在公式14中,‘s’指示输入音频信号,并且h_l和h_r分别指示左侧hrtf滤波器和右侧hrtf滤波器(第一滤波器)。另外,d_l和d_r分别指示左侧空间滤波器和右空间滤波器(第二滤波器)。g_h和g_d分别表示应用于第一滤波器和第二滤波器的混合增益。此外,*指示卷积。在这种情况下,音频信号处理设备可以经由傅立叶变换和傅里叶逆变换通过快速卷积方法来对输入音频信号进行滤波。同时,图23的方法除了要求通过使用现有hrtf进行双耳渲染之外还要求对相同的输入音频信号进行附加滤波操作,使得可以增加计算量。
此外,在混合过程期间由于第一滤波器与第二滤波器之间的相位响应中的差异可能发生声音质量劣化。图24是图示由梳状滤波效果而导致的声音质量劣化的图。音频信号处理设备可以混合基于相位响应不匹配的多个滤波器而滤波的音频信号。在这种情况下,混合信号的频率响应可以与基于hrtf的渲染音频信号的频率响应不同,从而导致音色失真。
图25是图示用于根据本公开的实施例的音频信号处理设备以通过组合多个滤波器来生成组合滤波器的方法的图。根据实施例,音频信号处理设备可以组合上述的第一滤波器和多个附加滤波器,以生成单个组合滤波器。因此,音频信号处理设备可以减少通过使用附加滤波器进行单独的双耳渲染添加的计算量。参考图25,音频信号处理设备可以从存储多个hrtf的hrtf数据库获得第一滤波器(hrtf)。另外,音频信号处理设备可以基于通过与输入音频信号相对应的虚拟声源建模的目标的大小以及从收听者到虚拟声源的距离生成第二滤波器。在这种情况下,音频信号处理设备可以从hrtf数据库获得第一滤波器或与不同于第一滤波器的位置相对应的hrtf中的至少一个。另外,音频信号处理设备可以通过使用第一滤波器或与不同于该第一滤波器的位置相对应的hrtf中的至少一个来生成第二滤波器。
接下来,音频信号处理设备可以通过内插第一滤波器和第二滤波器来生成包括h_l_new和h_r_new的组合滤波器。在这种情况下,音频信号处理设备可以通过将上述混合增益应用于第一滤波器和第二滤波器中的每个的幅度响应来生成h_l_new和h_r_new。音频信号处理设备可以通过使用混合增益来调整每个滤波器的效果的强度。
另外,音频信号处理设备可以针对第一滤波器和第二滤波器中的每个的左侧滤波器和右侧滤波器中的每个执行内插。可以在时域中执行内插,或者可以经由傅立叶变换在频域中执行内插。公式15示出用于音频信号处理设备在频域中基于第一左侧滤波器和第二左侧滤波器生成左侧组合滤波器的方法。在公式15中,mag{x(k)}指示滤波器x的针对第k个频率区间的幅度分量,并且pha{x(k)}指示滤波器x的针对第k个频率区间的相位分量。另外,g_h和g_d分别表示应用于左侧第一滤波器和左侧第二滤波器的混合增益。
[公式15]
h_l_new(k)=mag{h_l_new(k)}·exp[pha{h_l_new(k)}],
其中,mag{h_l_new(k)}=g_h·mag{h_l(k)}+g_d·mag{d_l(k)},并且pha{h_l_new(k)}=g_h·pha{h_l(k)}+g_d·pha{d_l(k)
同时,根据本公开的实施例的音频信号处理设备可以通过仅内插多个滤波器中的每个的幅度响应来生成组合滤波器。音频信号处理设备可以使用作为第一滤波器的hrtf的相位响应作为组合滤波器的相位响应。因此,音频信号处理设备可以基于实时地确定的混合增益生成组合滤波器。音频信号处理设备可以省略对内插相位响应需要的操作,以减少实时操作中需要的总计算量。公式16示出用于音频信号处理设备以仅内插多个滤波器的幅度响应来生成组合滤波器的方法。
[公式16]
h_l_new'(k)=mag{h_l_new(k)}·exp[pha{h_l_new}],
其中,mag{h_l_new(k)}=g_h·mag{h_l(k)}+g_d·mag{d_l(k)}并且,pha{h_l_new(k)}=pha{h_l(k)}
在公式16中,mag{x(k)}指示滤波器x的针对第k个频率区间的幅度分量,并且pha{x(k)}指示滤波器x的针对第k个频率区间的相位分量。另外,g_h和g_d分别表示应用于左侧第一滤波器和左侧第二滤波器的混合增益。公式17和公式18示出用于音频信号处理设备通过使用经由公式16生成的组合滤波器来生成左侧输出音频信号y_l'(k)和右侧输出音频信号y_r'(k)的方法。在公式17和公式18中,mag{x(k)}指示滤波器x的针对第k个频率区间的幅度分量,并且pha{x(k)}指示滤波器x的针对第k个频率区间的相位分量。另外,g_h和g_d分别表示应用于第一滤波器和第二滤波器的混合增益。
[公式17]
y_l'(k)=g_h·h_l(k)·s(k)+g_d·d_l(k)·s(k)
={g_h·h_l(k)+g_d·d_l(k)}·s(k)
=[g_h·mag{h_l(k)}·exp[pha{h_l(k)}]+g_d·mag{d_l(k)}·exp[pha{h_l(k)}]]·s(k)
=[g_h+g_d·mag{d_l(k)}·mag{h_l_inv(k)}]·h_l(k)·s(k)
=g_new_l(k)·h_l(k)·s(k),
其中,g_new_l(k)=g_h+g_d·mag{d_l(k)}·mag{h_l_inv(k)},并且mag{h_l_inv(k)}=1/mag{h_l(k)}
[公式18]
y_r'(k)=g_h·h_r(k)·s(k)+g_d·d_r(k)·s(k)
=g_new_r(k)·h_r(k)·s(k),
其中,g_new_r(k)=g_h+g_d·mag{d_r(k)}·mag{h_r_inv(k)},并且mag{h_r_inv(k)}=1/mag{h_r(k)}
在公式17和18中,音频信号处理设备基于混合增益g_h、g_d、第二滤波器的幅度响应mag_d_r(k)和第一滤波器的反向幅度响应mag{h_r_inv(k)}来生成左和右组合滤波器。在这种情况下,第一滤波器的反向幅度响应mag{h_r_inv(k)}可以是先前在hrtf数据库中计算出的值。音频信号处理设备可以像在公式17和公式18的中间结果中那样通过使用第一滤波器的幅度响应而不是第一滤波器的反向幅度响应来生成所组合的滤波器g_new_l(k)、g_new_r(k)。
图26是图示通过在根据本公开的实施例的音频信号处理设备中在频域中内插多个滤波器而生成的组合滤波器的图。在图26中,实线表示第一滤波器,并且虚线表示第二滤波器。短划线表示所组合的滤波器的频率响应的幅度分量。
图27是根据本公开的实施例的空间滤波器的频率响应的图示。根据实施例,音频信号处理设备可以基于声源的大小调整双耳渲染的2声道音频信号之间的耳间交叉相关(iacc)。如果收听者收听具有低iacc的低声道音频信号,则能够使收听者体验到两个音频信号来自彼此远离。图27中所示的空间滤波器可以是减小左右双耳信号之间的iacc的滤波器。音频信号处理设备可以通过针对每个频率子频带跨越水平差来减小左右双耳信号之间的iacc。这里,子频带可以是信号的整个频域的一部分,并且每个子频带可以是连续的。每个子频带可以包括至少一个频率区间。当频域被划分成多个子频带时,多个子频带的频带大小可以相等。可替选地,相应的子频带的频带大小可以彼此不同。例如,音频信号处理设备可以根据诸如bark标度或octave频带的听觉标度来将相应的子频带的频带大小设定为不同的值。图27示出其中与较低频率相对应的子频带的频带大小小于较高频率的频带大小的情况。
图28是图示用于根据本公开的实施例的音频信号处理设备以基于上述的hrtf、平移滤波器、和空间滤波器生成最终输出音频信号的方法的图。根据实施例,音频信号处理设备可以获得具有线性相位响应的hrtf。此外,音频信号处理设备可以使用所获得的hrtf的相位响应作为平移滤波器和空间滤波器中的每个的相位响应。参考公式19,音频信号处理设备可以基于hrtf和平移滤波器生成输出音频信号y_bes(k)。参考公式20,音频信号处理设备可以基于hrtf和空间滤波器生成输出音频信号y_sprd(k)。
[公式19]
y_bes(k)=s(k)·h_lin(k)·g_h+s(k)·ip(k)·p_l,r·g_i
=(k)·mag{h_lin(k)}·pha{h_lin(k)}·g_h+s(k)·pha{h_lin(k)}·p_l,r·g_i
=s(k)·h_lin(k)·[g_h+g_i·p_l,r·mag{1/h_lin(k)})
[公式20]
y_sprd(k)=s(k)·h_lin(k)·g_h+s(k)·d_lin(k)·g_d
=s(k)[h_lin(k)·g_h+mag{d_lin(k)}·pha{h_lin(k)}·g_d]
=s(k)·h_lin(k)[g_h+mag{d_lin(k)}·mag{1/h_lin(k)}·g_d]
在公式19和公式20中,mag{x(k)}指示滤波器x的针对第k个频率区间的幅度分量,并且pha{x(k)}指示滤波器x的针对第k个频率区间的相位分量。另外,h_lin指示基于线性化相位响应而生成的hrtf,p_l,r指示左平移增益或右平移增益,并且d_lin指示基于hrtf的线性化相位响应而生成的空间滤波器。另外,g_h、g_i和g_d分别表示与hrtf、平移滤波器和空间滤波器相对应的混合增益。ip(k)表示具有与h_lin相同的相位的脉冲响应。
公式21表示最终输出音频信号y_bes+sprd(k)。这里,音频信号处理设备可以通过合成应用了bes的输出音频信号y_bes和应用了根据声源的距离和大小的特征的输出音频信号sprd(k)来生成最终输出音频信号。在公式21中,g_b是与应用了bes的输出音频信号相对应的混合增益。
[公式21]
y_bes+sprd(k)=y_bes(k)·g_b+s(k)·d_lin(k)·g_d
=s(k)·h_lin(k)·g_b(g_h+g_i·p·mag{1/h_lin(k)})+s(k)·mag{d_lin(k)}·h_lin(k)·mag{1/h_lin(k)}·g_d
=s(k)·h_lin(k)·(g_b·g_h+g_b·g_i·p·mag{1/h_lin(k)}+g_d·mag{d_lin(k)}·mag{1/h_lin(k)})
=s(k)·h_lin(k)·(g_b·g_h+(g_b·g_i·p+g_d·mag{d_lin(k)}·mag{1/h_lin(k)})
参见图28,音频信号处理设备可以基于hrtf双耳渲染输入音频信号,以生成第一音频信号。音频信号处理设备可以基于平移滤波器双耳渲染输入音频信号,以生成第二音频信号。音频信号处理设备可以基于空间滤波器双耳渲染输入音频信号,以生成第三音频信号。接下来,音频信号处理设备可以组合第一音频信号和第二音频信号,以生成应用了bes效果的第四音频信号。另外,音频信号处理设备可以合成第三音频信号和第四音频信号,并且对经合成的音频信号执行ifft以生成输出音频信号。图28和公式21,音频信号处理设备首先合成第一音频信号和第二音频信号,然后合成第三音频信号以生成输出音频信号。然而,本公开不限于此。例如,音频信号处理设备可以通过单个合成过程来组合基于相应的滤波器而生成的输出音频信号。在这种情况下,可以基于g_b和g_d修改上述的混合增益g_h和g_i。
同时,根据本公开的实施例,可以通过多个虚拟声源来模拟输入音频信号。例如,输入音频信号可以包括多个声道信号中的至少一个或多声道模拟立体声信号。在这种情况下,音频信号处理设备可以通过多个虚拟声源来模拟输入音频信号。例如,音频信号处理设备可以基于与多个虚拟声源中的每个相对应的多个hrtf双耳渲染指派给每个虚拟声源的音频信号,从而生成输出音频信号。在这种情况下,指派给相应的虚拟声源的音频信号可以是高度相关的。此外,与相应的虚拟声源相对应的多个hrtf的相位响应可以是彼此不同的。结果,可能在输出音频信号中发生由于上述梳状滤波效果而导致的声音质量劣化。根据本公开的实施例的用于处理音频信号的设备可以匹配与每个虚拟声源相对应的多个hrtf中的每个的相位响应。因此,音频信号处理设备可以减轻通过双耳渲染高度相关的多个声道信号或多声道模拟立体声信号引起的声音质量劣化。
具体地,音频信号处理设备可以通过使用与多个虚拟声源中的每个相对应的多个不同的hrtf对来生成输出音频信号。在此实施例中,虚拟声源可以是与声道信号相对应的声道或用于渲染多声道模拟立体声信号的虚拟声道。另外,音频信号处理设备可以将多声道模拟立体声信号转换成与相对于收听者的头部方向布置的多个虚拟声源中的每个相对应的虚拟声道信号。在这种情况下,可以根据声源布局来布置多个虚拟声源。例如,源布局可以是其整个顶点位于以收听者为中心的单位球体上的虚拟立方体。在这种情况下,多个虚拟声源分别可以位于虚拟立方体的顶点处。
在下文中,为了说明的方便,多个虚拟声源的位置被称为flu(前左上)、fru(前右上)、fld(前左下)、rlu(后左上)、rru(后右上)、rld(后左下)、和rrd(后右下)。在本公开的相关描述中,其中声源布局是立方体的顶点的情况作为示例被描述,但是本公开不限于此。例如,声源布局可以以八面体顶点的形式。
音频信号处理设备可以获得与多个虚拟声源中的每个相对应的多个不同的hrtf对。另外,音频信号处理设备可以在幅度响应和相位响应上分析多个hrtf中的每个。接下来,音频信号处理设备可以在上面参考图3至图9所描述的方法中修改多个hrtf中的每个的相位响应,以生成具有修改的相位响应的多个hrtf'。例如,音频信号处理设备可以通过将多个同侧hrtf中的每个的相位响应设定为相同的线性相位响应来生成多个同侧hrtf'。
另外,音频信号处理设备可以修改多个对侧hrtf中的每个的相位响应。例如,与多个虚拟声源中包括的第一虚拟声源相对应的第一hrtf对可以包括第一同侧hrtf和第一主hrtf。在这种情况下,音频信号处理设备可以相对于第一同侧hrtf'的相位响来获得其中第一同侧hrtf与第一对侧hrtf之间的相位响应的差异被维持的第一对侧hrtf'的相位响应。接下来,音频信号处理设备可以通过基于与多个虚拟声源的位置相对应的多个hrtf'对来渲染与多个虚拟声源中的每个相对应的虚拟声道信号,从而生成双声道输出音频信号。
根据本公开的实施例,音频信号处理设备可以基于声源布局生成左侧相位响应和右侧相位响应。如上所述,当声源布局是虚拟立方体的顶点时,从四个左侧顶点中的每个到收听者的左耳的距离相对于收听者是相同的。此外,从左侧顶点中的任何一个到收听者的左耳的距离与从四个右侧顶点中的任何一个到收听者的右耳的距离相同。如果从源到收听者的左耳或右耳的距离是相同的,则应用于音频信号的组延迟可以是相同的。也就是说,当声源布局相对于收听者左右对称时,音频信号处理设备可以生成针对相对于收听者的左侧和右侧中的每个具有公共相位响应的hrtf。
在下文中,为了说明的方便,与相对于收听者位于左侧的顶点相对应的四个hrtf对被称为左侧组。另外,与位于收听者的右侧的顶点相对应的四个hrtf对被称为右侧组。左侧组可以包括分别与flu、fld、rlu、和rld位置相对应的hrtf对。另外,右侧组可以包括分别与fru、frd、rru和rrd位置相对应的hrtf对。
音频信号处理设备可以基于右侧组和左侧组中的每个中包括的多个同侧hrtf中的每个的相位响应来确定右侧组和左侧组的相位响应。在这种情况下,左侧组的同侧表示收听者的左耳,而右侧组的同侧表示收听者的右耳。音频信号处理设备可以使用左侧组中包括的多个左侧hrtf的相位响应的均值、中值、或模式值中的任何一个作为左侧组相位响应。另外,音频信号处理设备可以使用右侧组中包括的多个右侧hrtf的相位响应的均值、中值、或模式值中的任何一个作为右侧组相位响应。此外,音频信号处理设备可以使所确定的组相位响应线性化。
此外,音频信号处理设备可以通过基于针对每个组获得的组相位响应修改每个组中包括的同侧hrtf中的每个的相位响应来生成同侧hrtf'。可以以与对侧hrtf相同或相对应的方式施加基于同侧hrtf描述的实施例。根据另一实施例,音频信号处理设备可以选择左侧组中包括的四个hrtf中的每个的相位响应中的任一个作为左侧组相位响应。另外,音频信号处理设备可以选择右侧组中包括的四个hrtf的相位响应中的任何一个作为右侧组相位响应。因此,音频信号处理设备可以在维持多声道模拟立体声信号和声道信号的双耳渲染中的像定位性能的同时减少音色失真。
在本实施例中,使用一阶多声道模拟立体声(foa)作为示例来描述音频信号处理设备的操作,但是本公开不限于此。例如,可以以相同或相对应的方式将上述方法应用于包括多个声源的高阶多声道模拟立体声(hoa)信号。这是因为即使多声道模拟立体声信号是更高阶多声道模拟立体声信号,也可以用与每个程度相对应的球体调和的线性和来模拟多声道模拟立体声信号。另外,在声道信号的情况下,可以在相同或相对应的方法中应用上述方法。
图29和图30是图示针对其中与多个虚拟声源相对应的多个hrtf中的每个的相位响应彼此不匹配或者匹配的情况中的每一种的输出音频信号的频率响应的幅度分量的示例的图。图29是当声源布局是虚拟立方体的顶点时的频率响应的示例。在图29中,当音频信号处理设备与对应于多个虚拟声源的多个hrtf的相位响应不匹配时,发生由于梳状滤波效果而导致的声音质量劣化(实线)。另一方面,当音频信号处理设备线性地匹配与多个虚拟声源相对应的多个hrtf的相位响应时,不会发生由于梳状滤波效果而导致的声音质量劣化(虚线)。
图30是当声源布局是虚拟八面体的顶点时的频率响应的示例。如图29中所示,当相对于声源布局中包括的八个虚拟声源的虚拟声源的数目增加时,由于梳状滤波而导致的声音质量劣化可能增加。如在图29中一样,当音频信号处理设备与对应于多个虚拟声源的多个hrtf的相位响应不匹配时,由于梳状滤波效果而发生声音质量劣化(实线)。另一方面,当音频信号处理设备线性地匹配与多个虚拟声音相对应的多个hrtf的相位响应时,不会发生由于梳状滤波效果而导致的声音质量劣化(虚线)。
还可以以记录介质的形式实现一些实施例,所述记录介质包括可由计算机执行的指令,诸如由计算机执行的程序模块。计算机可读介质能够是可由计算机访问的任何可用介质,并且能够包括易失性和非易失性介质、可移动和不可移动介质两者。计算机可读介质还可以包括计算机存储介质。计算机存储介质可以包括用任何方法或技术实现以便存储诸如计算机可读指令、数据结构、程序模块或其它数据的信息的易失性和非易失性、可移动和不可移动介质。
尽管已经使用具体实施例描述了本公开,然而本领域的技术人员能在不脱离本公开的精神和范围的情况下做出改变和修改。也就是说,尽管已经描述了用于音频信号的双耳渲染的实施例,然而本公开可被同样地应用并扩展到不仅包括音频信号而且包括视频信号的各种多媒体信号。因此,能由本领域的技术人员根据本公开的详细描述和实施例容易地推理的任何衍生物应当被解释为落入本公开的权利范围内。
- 还没有人留言评论。精彩留言会获得点赞!