一种基于图结构分析的IP别名解析方法与流程
本发明涉及互联网技术领域,具体涉及一种基于图结构分析的ip别名解析方法。
背景技术:
随着internet中节点的类型和节点之间的互联技术越来越多样化,骨干网络的拓扑日益复杂,网络拓扑在网络构建、网络安全、网络态势等很多方面有十分重要的作用,因此网络拓扑发现也显得越发重要,这对于保证网络系统运行和防范网络系统攻击都有重要意义。
现有的因特网拓扑测量多数都是基于traceroute机制而获取ip级拓扑,但ip级拓扑不能反映路由器之间的真实连接关系。因此网络拓扑测量的关键问题之一就是研究路由器间的连接情况,从而构建以路由器为节点粒度的拓扑图。采用别名解析可以根据ip级拓扑构建路由器级拓扑。
别名解析是识别出哪些ip地址属于同一个路由器,并将这些ip地址合并成一个节点的过程。目前别名解析技术主要分为基于探测的别名解析技术和基于分析的别名解析技术两大类。其中基于探测的别名解析技术是通过向目标地址发送探测报文,从返回的探测数据进行判断;基于分析的别名解析技术主要分析traceroute探测出的ip级拓扑结构,然后利用相关算法进行推理判断。
别名解析方法首先在iffinder项目中实现,该方法向目标地址发送一个udp报文,路由器收到这种类型的探测报文,可能采用另一个接口对应的ip向探测源回复icmp-端口不可达报文,由此可推断该响应报文的源ip地址和探测的目标ip地址必然属于相同路由器。该方法每次都需要联网发送探测包并等待响应报文,所以运行时间较长,但是其结果稳定可靠,一般路由器返回响应报文的端口ip地址不会变化,准确度比较高。基于分析的别名解析技术由spring提出,该方法认为在traceroute路径中具有相同后继ip的ip地址互为别名,如存在traceroute路径(…,a,b,…)和(…,c,b,…),则将a和c判定为一对别名,该方法判定规则比较简单,但误判率较高;shi提出一种基于traceroute路径交叉节点的别名解析方法,分别对交叉节点和非交叉节点处的拓扑进行分析判定,在一定程度上可以提升准确率,但依赖于探测traceroute数据中存在公共路径;基于分析和探测的别名解析方法apar(theanalyticandprobe-basedaliasresolver),首先对ip地址进行子网构建,根据得到的子网信息重新处理traceroute路径,从而推断出候选别名,该方法准确度比较高。
基于分析的别名解析方法主要基于traceroute路径数据,这种方式面临ip级拓扑数量巨大,不容易管理的问题,且现有的别名解析方法不能完整对所有的路由器进行别名解析。因此,亟需一种高效率和高正确率且能对所有路由器进行完整别名解析的方法。
技术实现要素:
为了克服现有技术的上述缺点,本发明提供了一种基于图结构分析的ip别名解析方法,本方法对现有别名解析进行了改进,利用iffinder方法对traceroute路径数据进行处理,提高别名解析的准确性,对traceroute路径进行图结构分析生成ip别名集合,提高别名解析的效率,最后随着探测数据的增加,对生成的路由器级拓扑数据进行合并分析,提高别名解析结果的完整性准确性。
本发明解决其技术问题所采用的技术方案是:
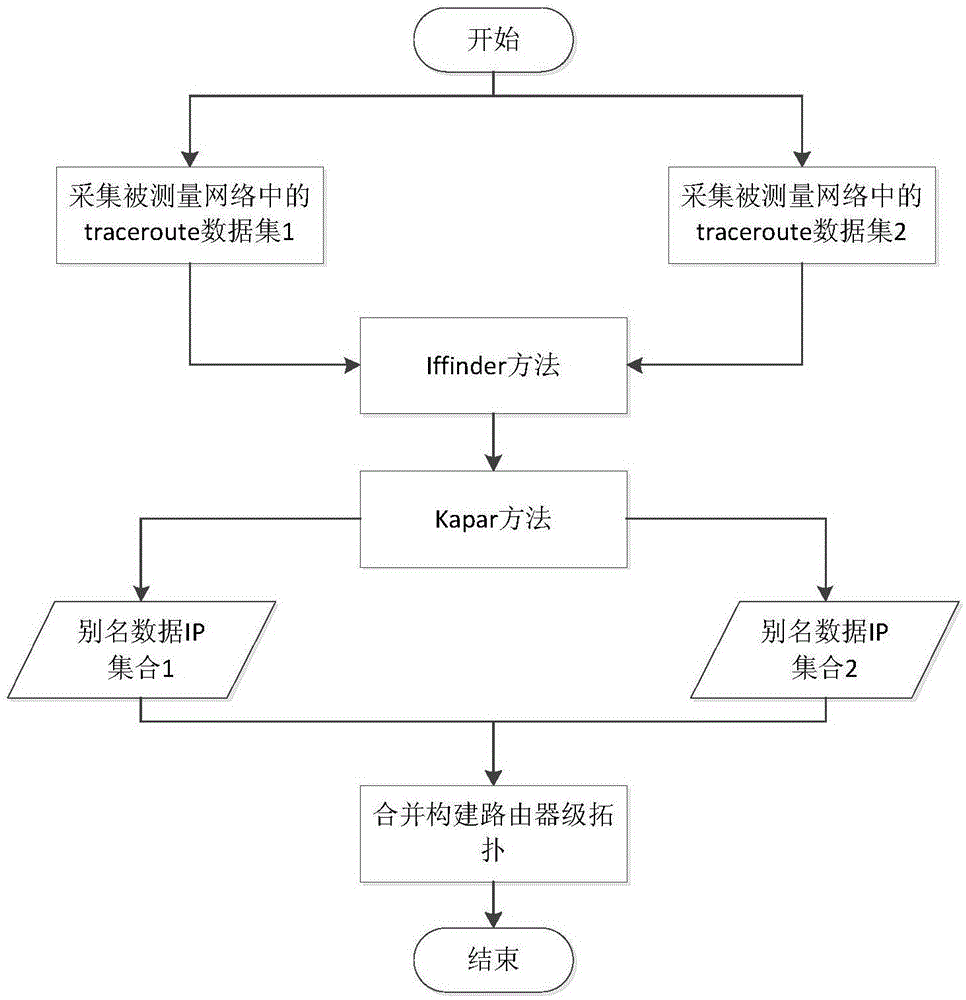
一种基于图结构分析的ip别名解析方法,包括如下步骤:
1)获取traceroute路径数据,并进行预处理以去除无效数据;
2)对预处理后的traceroute路径数据,利用iffinder工具进行处理,并存储处理结果;
3)对iffinder处理结果,利用kapar方法进行处理,得ip别名集合;
4)判断各ip别名集合是否合理,并对不合理的ip别名集合进行选择性合并;
5)利用ip别名集合构建路由器级拓扑。
本方法利用iffinder工具对traceroute路径数据进行处理,可以提高别名解析的准确性;利用图结构分析,优化数据结构和策略,提高别名解析的效率,克服了现有别名解析算法中时间复杂度高的问题;将多文件路由器级拓扑数据进行合并分析,既保证了别名解析的完整性,还有利于恢复全局拓扑结构。
进一步地,步骤4)判断各ip别名集合是否合理的方法如下:
判断各ip别名集合中任意两个ip地址是否处于同一条traceroute路径,若ip别名集合中所有ip地址均处于不同的traceroute路径,则该ip别名集合合理;若ip别名集合中至少有两个ip地址处于相同的traceroute路径,则该ip别名集合不合理。
通过分析发现,对于生成的部分路由器的ip别名集合存在环路现象,即:同一路由器的ip别名集合中有至少两个ip地址处于同一traceroute路径上,这样的ip别名集合被视为不合理的ip别名集合,例如别名集合s=(ip1,ip2,ip3,ip4),其中ip2和ip3处于一条traceroute路径上,这个时候就认为别名集合s不合理。对于不合理的ip别名集合,应当进一步处理,使其成为合理的ip别名集合。
进一步地,步骤4)对不合理的ip别名集合进行选择性合并的方法如下:
根据ip别名集合中各ip首部中的生存时间值之间的关系,将不合理的ip别名集合分解为多个ip别名集合,再将分解后的多个ip别名集合合并为多个新的合理的ip别名集合。
同一个路由器之间的ip地址的生存时间值(ttl)间的差不能超过2,利用这一规则可以将不合理的ip别名集合中的重复ip地址选择性分离出来,并合并为新的合理的ip别名集合,例如:若别名集合s=(ip1,ip2,ip3,ip4)对应的ttl为(25,26,28,24),则认为ip1、ip2、ip4为一个别名集合,ip3为一个别名集合。
通过对别名解析数据合理性进行分析和处理,可以提高别名解析结果的准确性。
进一步地,构建路由器级拓扑前,还应当对存在公共元素的别名集合进行合并,包括如下步骤:
s01.构建别名集合中路由器相交字典intersect_map,并将相交的别名集合之间存在相交的ip地址进行关联映射表示;
s02.根据步骤1构建的相交字典intersect_map,将存在相交的别名集合合并;
s03.将步骤s02合并后的别名集合进行比较,继续合并存在相交的别名集合,至所有ip别名集合之间均不存在相交为止。
进一步地,所述存在公共元素的ip别名集合是指:对不同时刻获得的部分或全部ip地址相同的多个ip别名集合。。
由于traceroute数据具有实时性,在别名解析过程中会生成多个路由器拓扑级数据,这些数据之间通常存在路由器ip相交的情况,因此需要对这些数据进行合并。其中,路由器ip相交的情况包含仅相交但不完全相交和完全相交两种情况。在对ip别名集合进行合并的过程中,应当保证ip别名集合的唯一性,相处重复的别名集合,同时,对于别名集合中不存在相交的别名,无需做其它处理。
进一步地,上述合并相交ip别名集合的方法还包括如下步骤:
判断合并后的各ip别名集合是否合理,并对不合理的ip别名集合进行选择性合并。选择性合并的方法与步骤4)选择性合并的方法相同。
进一步地,步骤5)中,根据traceroute探测得到的ip链路信息,推断各路由器之间的链路信息,再利用ip别名集合构建路由器级拓扑。
进一步地,步骤1)中所述预处理方法如下:
将traceroute路径数据中的不合理ip替换为匿名ip;和/或,
删除数据中合理ip个数少于两个的traceroute路径;和/或,
删除数据中存在重复ip地址的traceroute路径。
所述不合理ip是指:私有ip地址。
进一步地,判断各ip别名集合是否合理前,可对traceroute路径中的每个ip地址编号,并利用字典key-value存储,以提高别名解析效率。
通过采用上述技术方案,本发明的积极效果是:
本发明提供的ip别名解析方法,利用iffinder工具对traceroute路径数据进行处理,可以提高别名解析的准确性;利用图结构分析,优化数据结构和策略,提高别名解析的效率,克服了现有别名解析算法中时间复杂度高的问题;将多文件路由器级拓扑数据进行合并分析,既保证了别名解析的完整性,还有利于恢复全局拓扑结构。
附图说明
本发明将通过例子并参照附图的方式说明,其中:
图1为本发明基于图结构分析的ip别名解析方法流程图。
具体实施方式
针对现有ip别名解析方法耗时较长、误判率高且不能完整别名解析所有路由器的缺陷,本发明提供了一种基于图结构分析的ip别名解析方法,本方法对现有别名解析进行了改进,利用iffinder方法对traceroute路径数据进行处理,提高别名解析的准确性,利用图分析来生成别名解析ip集合,提高别名解析的效率,最后随着探测数据的增加,对生成的路由器级拓扑数据进行合并分析,提高别名解析结果的完整性和准确性。所述方法的方法流程图如图1所示。
本发明的基本方法包括如下步骤:
1)获取traceroute路径数据,并进行预处理以去除无效数据;
2)对预处理后的traceroute路径数据,利用iffinder工具进行处理,并存储处理结果;
3)对iffinder处理结果,利用kapar方法进行处理,得ip别名集合;
4)判断各ip别名集合是否合理,并对不合理的ip别名集合进行选择性合并;
5)利用ip别名集合构建路由器级拓扑。
本方法利用iffinder工具对traceroute路径数据进行处理,可以提高别名解析的准确性;利用图结构分析,优化数据结构和策略,提高别名解析的效率,克服了现有别名解析算法中时间复杂度高的问题;将多文件路由器级拓扑数据进行合并分析,既保证了别名解析的完整性,还有利于恢复全局拓扑结构。
步骤1)中,所述预处理方法如下:
将traceroute路径数据中的不合理ip替换为匿名ip;和/或,
删除数据中合理ip个数少于两个的traceroute路径;和/或,
删除数据中存在重复ip地址的traceroute路径。
步骤2)中所述iffinder工具的基本原理为:使用一个目的端口号未被使用的udp分组探测某个ip地址时,该ip所在的路由器可能采用另一个接口对应的ip向探测源回复icmp-端口不可达报文,因此可推断该响应报文的源ip地址和探测的目标ip地址必然属于相同路由器,在iffinder处理过程中,对每次联网ping操作得到的结果进行存储,并且按周期性更新数据。
步骤3)中所述的kapar方法是一种基于分析和探测的别名解析方法,该方法首先对经iffinder工具处理后的traceroute路径中的ip地址进行子网构建,然后根据得出的子网信息排列traceroute路径,推断出候选别名。该方法分为构建子网和别名解析两个阶段。在构建子网阶段要满足以下几个条件:(1)“无广播”条件:如果探测到子网中存在广播地址,则该前缀的子网并不存在;(2)“正确性”条件:在同一个探测到的traceroute路径中,来自于同一子网的两个或更多的ip地址不可能一非邻居的形式出现,用这个条件可以发现不正确的候选子网;(3)“完整性”条件:一个子网中的地址要按照一定的比例出现在traceroute探测路径中,如果没有达到该比例的子网即使是正确的子网也不采用,这个条件可以提高候选子网的正确性;(4)“处理顺序”条件:在输出子网信息是由很多个不同子网掩码的子网,在别名解析时先处理完整性比率高的子网,不同子网如果完整性比率相同则优先处理包含traceroute路径多的子网,当别名冲突时,选择先确定的忽略后确定的。别名解析阶段,要满足无循环、共同邻居和距离条件的限制,才能判断为别名:(1)无循环指的是如果因为推测两个ip地址为别名而在任何traceroute路径中出现路由循环,则别名被认为是错误的;(2)共同邻居是指满足以下三个条件中的一个就认为两个地址是别名:a.两个候选别名对有共同的邻居,b.存在一个已知的别名对与候选别名对互为前后继,c.traceroute路径排列时路径中某一段看起来像是两个子网在候选别名对的两侧;(3)距离条件限制主要是判断候选别名对到测量源点的ttl值是否相等来进一步排除不正确的候选别名对,这一限制条件是必需的,增加这一条件引入了额外的探测,但同时提高了方法准确性。kapar算法只遍历一遍traceroute数据集,在同一traceroute路径中标识出共同前缀长度来形成子网列表,并且为每条traceroute路径分配一个唯一的id,用压缩位图来存储每个ip地址所在的路径id编号。
步骤4)中,判断各ip别名集合是否合理的方法如下:
判断各ip别名集合中任意两个ip地址是否处于同一条traceroute路径,若ip别名集合中所有ip地址均处于不同的traceroute路径,则该ip别名集合合理;若ip别名集合中至少有两个ip地址处于相同的traceroute路径,则该ip别名集合不合理。
通过分析发现,对于生成的部分路由器的ip别名集合存在环路现象,即:同一路由器的ip别名集合中有至少两个ip地址处于同一traceroute路径上,这样的ip别名集合视为不合理的ip别名集合,例如别名集合s=(ip1,ip2,ip3,ip4),其中ip2和ip3处于一条traceroute路径上,这个时候就认为别名集合s不合理。对于不合理的ip别名集合,应当进一步处理,使其成为合理的ip别名集合。
步骤4)对不合理的ip别名集合进行选择性合并的方法如下:
根据ip别名集合中各ip首部中的生存时间值之间的关系,将不合理的ip别名集合分解为多个ip别名集合,再将分解后的多个ip别名集合合并为多个新的合理的ip别名集合。
判断各ip别名集合是否合理前,可对traceroute路径数据中的每个ip地址编号,并利用字典key-value存储,时间复杂度为o(1),以提高别名解析效率。
同一个路由器之间的ip地址的生存时间值(ttl)间的差不能超过2个,利用这一规则可以将不合理的ip别名集合中的重复ip地址选择性分离出来,并合并为新的合理的ip别名集合,例如:若别名集合s=(ip1,ip2,ip3,ip4)对应的ttl为(25,26,28,24),则认为ip1、ip2、ip4为一个别名集合,ip3为一个别名集合。
通过对别名解析数据合理性进行分析和处理,可以提高别名解析结果的准确性。
步骤5)中,构建路由器级拓扑前,还应当对存在公共元素的ip别名集合进行合并,包括如下步骤:
s01.构建别名集合中路由器相交字典intersect_map,并将相交的别名集合之间存在相交的ip地址进行关联映射表示;
s02.根据步骤1构建的相交字典intersect_map,将存在相交的别名集合合并;
s03.将步骤s02合并后的别名集合进行比较,继续合并存在相交的别名集合,至所有ip别名集合之间均不存在相交为止。
所述存在公共元素的ip别名集合是指:对不同时刻获得的部分或全部ip地址相同的多个ip别名集合。
由于traceroute数据具有实时性,在别名解析过程中会生成多个路由器拓扑级数据,这些数据之间通常存在路由器ip相交的情况,因此需要对这些数据进行合并。其中,路由器ip相交的情况包含仅相交但不完全相交和完全相交两种情况。在对ip别名集合进行合并的过程中,应当保证ip别名集合的唯一性,消除重复的别名集合,同时,对于别名集合中不存在相交的别名,无需做其它处理。
上述合并相交ip别名集合的方法还包括如下步骤:
判断合并后的各ip别名集合是否合理,并对不合理的ip别名集合进行选择性合并。选择性合并的方法与步骤4)选择性合并的方法相同。
步骤5)中,根据traceroute探测得到的ip链路信息,推断各路由器之间的链路信息,再利用ip别名集合构建路由器级拓扑。
- 还没有人留言评论。精彩留言会获得点赞!