基于memetic框架的多目标动态网络社区划分方法与流程
本发明涉及动态复杂网络社区分析技术领域,具体为一种基于memetic框架的多目标动态复杂网络社区分析算法。
背景技术:
很多复杂系统可以用复杂网络来表述,如互联网、电力系统、社交关系网、交通系统等等。用户之间通过通讯进行交流时,就形成了一张社交关系网络,这种网络是随着时间不断变动的,可建模为动态复杂网络。将一个复杂网络中的节点按照规则进行分区,每一个这样的分区被称为一个社区。同一个社区的节点具有较高的连接度,不同社区间的节点连接度则较低。社区内的节点具有许多相同的属性,因而复杂网络的社区结构检测对于研究网络特性非常重要。
网络社区主要有两类检测方法。
一类是启发式方法,通过某种启发规则或直观性假设来寻找社区,其中较为经典的girvan-newman(gn)算法,快速的标签传播算法(lpa)等。
另一类是优化方法,newman等人将标准模块度q作为一个衡量网络划分质量的指标,从而将社区检测转化为按照目标函数进行优化,典型算法有newman快速算法、fastmodularity算法以及在此基础上延伸出的多目标优化算法,如moga算法。但是模块度q存在分辨率限制的问题,为此,li等人提出了基于平均模块度概念来评论社区划分的优劣,该方法中的准则函数称为模块度密度(modularitydensity)或d值。chi提出谱聚类进化算法之后,动态社区检测转化为代价函数的优化问题,代价函数由快照代价和时间代价组成,其中快照代价是衡量当前时刻网络的聚类质量的指标,时间代价是衡量当前时刻和相邻前一时刻聚类结果相似程度的指标。
此后,提出了facetnet模型,通过分解非负矩阵的方法可以同时分析出社区结构及其演化过程,但事先需要知道网络中的社区数目,这大大限制了它的应用范围。为避免这一局限性,han等人提出了基于粒子和密度的进化聚类检测机制,采用用户自定义参数来调整代价函数的权重配比,可以使用在不同时间阈值和社区数量不固定的动态网络社区检测场景中。为了摆脱上述算法人为干涉权重配比的限制,引入多目标优化策略,避免单一的全局最优解,从而产生一系列互不支配的解,称为pareto解。
folino和pizzui将社区得分(cs)和归一化互信息(nmi)作为两个目标函数,把动态社会网络社区检测及其社区演化问题用多目标优化的遗传算法方法进行求解,在小规模的动态网络上取得了较好的成效。
在此之后出现了许多的多目标优化算法,例如,lung的基于博弈论和极值优化的动态社区发现算法、ma等人的基于分解的多目标进化算法、gong等人的基于非支配邻域免疫算法的动态社区检测算法和wang等人研究的加权检测算法等,这些算法也都通过实验证实具有一定的有效性。
技术实现要素:
发明目的:为了克服现有技术中存在的不足,本发明提供一种基于memetic框架的多目标动态网络社区划分方法,其种群多样性高,搜索空间少,能够实现社区结构的精细化划分,同时算法效率高,社区划分精度细。
技术方案:为实现上述目的,本发明采用的技术方案为:
一种基于memetic框架的多目标动态网络社区划分方法,包括以下步骤:
步骤100、建立memetic算法框架;
步骤200、在memetic框架下,将模块度密度函数d加权得到的优化型模块度密度函数dλ,同归一化互信息nmi,嵌入到代价目标函数中求取最小化优化目标函数;
步骤300、采用直接式整数编码的方式,结合基于标识符传递的初始化机制、双路交叉遗传算法和自爬山算法的搜索方式获取最优社区结构。
优选地,所述memetic算法框架包括:
输入:动态网络g={g1,g2,...,gt},g1,g2,...,gt表示每个时刻对应的网络,t表示动态网络的总时间步;
参数:种群的规模n;;交叉概率pc;变异概率pm;迭代次数t;最大迭代次数max_gen,时间步tl;
第一步、使用moga-net检测算法对初始时刻的网络g1进行社区划分,获得第一个时刻g1的社区划分结果
第二步、判断终止条件tl≥t满足,则输出结果c={c1,c2,...,ct},否则,转向第三步;
第三步、种群初始化:基于标识符传递机制的父代初始化操作,并分别计算所有个体的适应值f,此时,t=0;
第四步、子代个体产生:根据个体适应度是高低,进行正比选择策略生成交配池,在交配池中进行双路交叉和基于邻位基因值的变异操作,产生子代个体,其中交叉概率pc和变异概率pm使用自适应优化;
第五步、种群更新:进行爬山式局部搜索,从当前父代个体及子代个体中选出适应度值f最高的n个个体,更新之前的父代种群,生成新的父代种群;
第六步、t=t+1,如果t=max_gen,从非占有解中选择模块度大的最优解,输出当前时刻的社区划分结果,
第七步、tl=tl+1,转向第二步;
输出:动态网络g对应的每个时刻下的社区结构c={c1,c2,...,ct}。
优选地,所述最小化优化目标函数的求取方法包括:
假设v1和v2是网络g的节点集v的两个不相交的节点子集,定义
式中:
ra和rc是共同体现优质划分的两个互补特性,当ra越大时表示社区的平均内度越大,即社区内节点连接越紧密,社区数目越多,则社区规模较小;
当rc越小时表示社区平均外度越小,即社区间的节点连接越稀松;
因此,d值越大,社区划分越为准确;
对模块度密度函数d加入权重调节参数λ,将模块度密度函数d看做两个目标函数的组合,变成dλ:
利用归一化互信息nmi描述相邻时刻算法划分结果之间的相似程度,可以衡量动态社区相邻时刻的复杂网络结构;
假设网络g的两种划分分别为s1和s2,设h为混合矩阵,h中的元素hij表示在s1划分情况下社区i中的节点同时也出现在s2划分情况下社区j中的数量;s1和s2之间的定义nmi为:
其中,np1和np2分别是s1和s2划分中的社区个数,hi和hj分别为h中第i行和第j列的元素之和,n为网络中所有节点的数量;
如果s1=s2,则nmi(s1,s2)=1;
如果s1和s2完全不同,则nmi(s1,s2)=0;
nmi的值越大,表示s1和s2之间的相似度越高;
nmi值表示两个社区的接近程度,用来评估社区划分算法的结果优劣,高的nmi说明从一个时间步到下一个时间步的社区没有发生大的变化,是瞬时顺滑的。
采用优化模块度密度dλ和归一化互信息nmi分别作为代价函数中的快照代价sc和时间代价tc:
代价函数cost=α·sc+(1-α)·tc;
其中,sc衡量的是在某一时刻t下社区结构的质量;tc衡量的是当前t时刻下的社区结构st和t-1时刻下社区结构st-1之间的一致性;参数α是权重参数,可以改变相邻两社区之间的结构差。
得到最小化优化目标函数f=σ-αdλ-(1-α)nmi;
其中,σ是一常数。
优选地,所述步骤300直接式整数编码包括:
对网络g的一个社区划分s可以编码为一个整型字符串x={x1,x2,...,xn},其中x代表染色体,n代表网络g中的节点总数,xi(i=1,2,...,n)为节点vi的社区整型标识符,带有相同标识符的节点被视为处于相同社区。
优选地,所述基于标识符传递的初始化机制包括:
假设一个网络中节点数量为n,种群初始化前,所有染色体都为同样的整数编码{1,2,...,n};
首先随机选择个体中的一个节点i,假设节点i有k个邻居节点,邻居节点集为a(i),邻居节点标识符集合为s(i)={x1,x2,...,xk},网络中的每个节点标识符的初始化取决于其邻居集中的标识符;
若节点i的邻居集中所有节点的标识符都不同,则随机选择一个邻居标识符去覆盖原来的xi;
若节点i的邻居集中存在节点具有相同标识符的情况,则选择具有最大比例的那个标识符去覆盖原来的xi。
优选地,所述双路交叉遗传算法包括:
交叉步骤:
假设存在两个亲代染色体xa和xb,两个染色体上的节点顺序相互对应;
首先在染色体xa上随机选择一个节点vi,vi的标识符为
同时,找出染色体xb中同样位置的节点vi以及和节点vi的标识符
变异步骤:
采用基于邻位基因值的变异方式;在交叉后的染色体中随机挑选一个节点,然后将这个节点的标识符随机地变为其任意邻居节点的标识符,其中这些节点变异方向所能取到的标识符值被限定在其邻居节点的标识符值之中;
求取交叉概率pm和变异概率pc:
使用logistic函数中来构造自适应的pc和pm;
其中,β1和β2是两个常数,β1∈(0,+∞),β2∈(0,1);pc∈(0.4,0.9),pm∈(0,0.1)。
优选地,所述爬山算法包括:
将全局搜索中得到的pareto解集看作局部搜索对象,通过爬山算法局部搜索产生最优解;
局部优化的适应度函数为ra和rc的权重和;
f1=fmax+ω1ra-ω2rc+x;
其中,fmax为保证适应值为非负的常数,x为0.05;
ω1=i/n,i为种群中的个体序号,n为种群规模,ω2=1-ω1。
本发明相比现有技术,具有以下有益效果:
(1)本发明本文采用memetic算法框架,利用遗传算法进行全局搜索,采用基于标识符传递的初始化机制、双路交叉和自适应优化等策略,即能够提高种群多样性,又减少搜索空间,提高算法效率。
(2)将单目标寻优拓展为多目标寻优方式,使用最小化思想改进模块度密度,既可以避免传统q值带来的分辨率限制,也可以降低算法复杂度,从而降低时间消耗,再将多目标函数引入调节参数,通过调节参数的变化可以调节社区检测结构,可以实现社区结构的精细化发现,避免出现极大社区,能够检测出动态网络的社区结构关系。
(3)在全局搜索中加入局部搜索,局部搜索采用爬山式智能算法,利用启发式方法进行深度优先搜索更好解替代旧解,最终获得最优解,有效的加速算法收敛,避免传统遗传算法所导致的陷入局部最优问题,可以有效的提高算法速度和社区划分精度。
附图说明
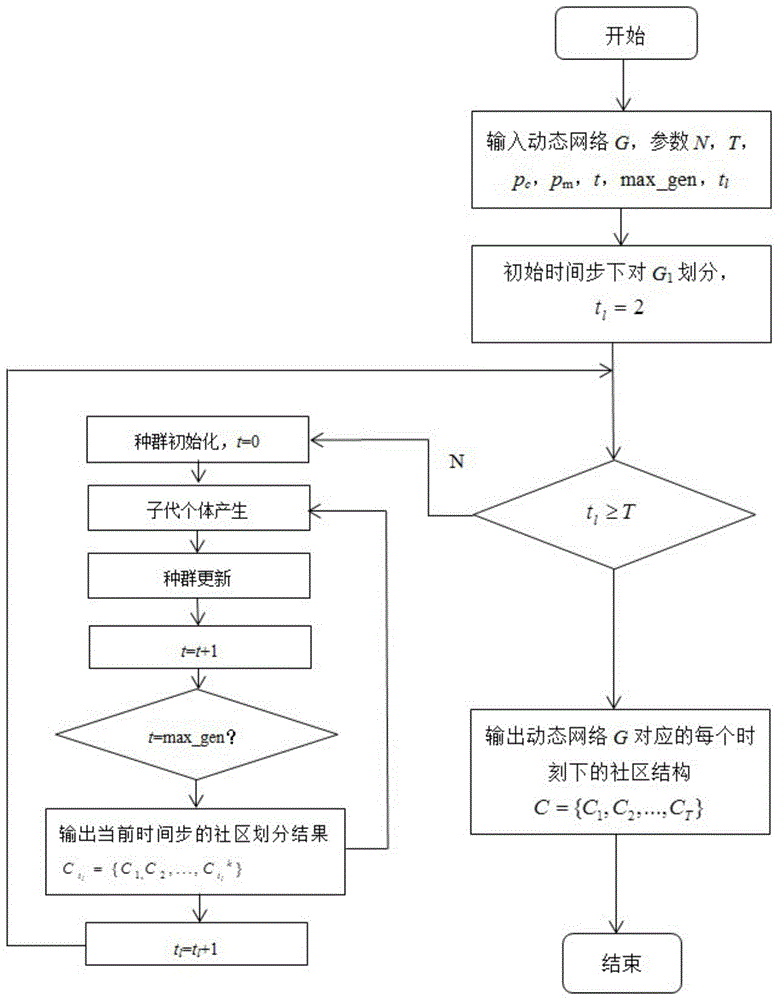
图1为本发明的流程图;
图2为本发明实施方式中4个不同算法在vast动态数据集上得到的结果值,其中图2(a)为nmi值,图2(b)为q值;
图3为本发明实施方式中dyn-smfmcd算法在vast数据集上社区划分图,其中图3(a)为时刻3的dyn-smfmcd算法在vast数据集上社区划分图,图3(b)为时刻9的dyn-smfmcd算法在vast数据集上社区划分图;
图4为本发明实施方式中dyn-smfmcd算法在学生接触数据集上的结构划分图,其中图4(a)为时刻2的dyn-smfmcd算法在学生接触数据集上的结构划分图,图4(b)为时刻3的dyn-smfmcd算法在学生接触数据集上的结构划分图。
具体实施方式
下面结合附图和具体实施例,进一步阐明本发明,应理解这些实例仅用于说明本发明而不用于限制本发明的范围,在阅读了本发明之后,本领域技术人员对本发明的各种等价形式的修改均落于本申请所附权利要求所限定的范围。
如图1所示,本发明提供了一种基于memetic框架的多目标动态网络社区划分方法,包括以下步骤:
步骤100、建立memetic算法框架;
步骤200、在memetic框架下,将模块度密度函数d加权得到的优化型模块度密度函数dλ,同归一化互信息nmi,嵌入到代价目标函数中求取最小化优化目标函数;
步骤300、采用直接式整数编码的方式,结合基于标识符传递的初始化机制、双路交叉遗传算法和自爬山算法的搜索方式获取最优社区结构。
在本实施方式中,社区的定义为:
动态复杂网络是随着时间不断演变的网络,采用时刻、节点和边进行描述,即g={g1,g2,...,gt}。
其中,gt=<vt,et>表示第t个时刻的网络,vt是指第t个时刻网络中的节点集合,et是指第t个时刻网络中的边集合。
网络中的社区是指所有节点通过划分而形成的子集,子集具有内部节点连接紧密,子集与子集之间的节点连接相对稀疏的特点。
定义节点i的度为ki=∑jaij,表示与i具有连接关系的节点之和,其中a=[aij]为图gt的邻接矩阵,j为gt中其它节点,若节点i与j存在连接关系则aij=1,否则取0。定义s是网络gt的一个社区,那么s中节点的度为其内度与外度之和,其中内度是节点i与s内其余节点连接的总数,外度是节点i与s以外节点连接的总数,表示为:
其中,当
动态网络的社区结构是由各个时刻下社区划分结果组成的集合,即当第t个时刻下网络gt由k个社区构成,得到划分结果为
为了研究动态社区的检测机制的需要,假设相邻时刻社区变化是相对平缓的。
在本实施方式中,memetic算法框架包括:
输入:动态网络g={g1,g2,...,gt},g1,g2,...,gt表示表示每个时刻对应的网络,t表示动态网络的总时间步;
参数:种群的规模n;交叉概率pc;变异概率pm;迭代次数t;最大迭代次数max_gen,时间步ti;
第一步、使用moga-net检测算法对初始时刻的网络g1进行社区划分,获得第一个时刻g1的社区划分结果
第二步、判断终止条件tl≥t满足,则输出结果c={c1,c2,...,ct},否则,转向第三步;
第三步、种群初始化:基于标识符传递机制的父代初始化操作,并分别计算所有个体的适应值f,此时,t=0;
第四步、子代个体产生:根据个体适应度是高低,进行正比选择策略生成交配池,在交配池中进行双路交叉和基于邻位基因值的变异操作,产生子代个体,其中交叉概率pc和变异概率pm使用自适应优化;
第五步、种群更新:进行爬山式局部搜索,从当前父代个体及子代个体中选出适应度值f最高的n个个体,更新之前的父代种群,生成新的父代种群;
第六步、t=t+1,如果t=max_gen,从非占有解中选择模块度大的最优解,输出当前时刻的社区划分结果,
第七步、tl=tl+1,转向第二步;
输出:动态网络g对应的每个时刻下的社区结构c={c1,c2,...,ct}。
在本实施方式中,最小化优化目标函数的求取方法如下:
假设v1和v2是网络g的节点集v的两个不相交的节点子集,,定义
式中:
ra和rc是共同体现优质划分的两个互补特性,当ra越大时表示社区的平均内度越大,即社区内节点连接越紧密,社区数目越多,则社区规模较小;
当rc越小时表示社区平均外度越小,即社区间的节点连接越稀松;
因此,d值越大,社区划分越为准确;
实验证明,基于模块度密度的优化算法在检测社区结构时,不管是网络被划分为很大规模的社区还是很小规模的社区,都不存在分辨率限制问题。
对模块度密度函数d加入权重调节参数λ,将模块度密度函数d看做两个目标函数的组合,变成dλ:
利用归一化互信息nmi描述相邻时刻算法划分结果之间的相似程度,可以衡量动态社区相邻时刻的复杂网络结构;
假设网络g的两种划分分别为s1和s2,设h为混合矩阵,h中的元素hij表示在s1划分情况下社区i中的节点同时也出现在s2划分情况下社区j中的数量;s1和s2之间的定义
nmi为:
其中,np1和np2分别是s1和s2划分中的社区个数,hi和hj分别为h中第i行和第j列的元素之和,n为网络中所有节点的数量;
如果s1=s2,则nmi(s1,s2)=1;
如果s1和s2完全不同,则nmi(s1,s2)=0;
nmi的值越大,表示s1和s2之间的相似度越高;
nmi值表示两个社区的接近程度,用来评估社区划分算法的结果优劣,高的nmi说明从一个时间步到下一个时间步的社区没有发生大的变化,是瞬时顺滑的。
采用优化模块度密度dλ和归一化互信息nmi分别作为代价函数中的快照代价sc和时间代价tc:
代价函数cost=α·sc+(1-α)·tc;
其中,sc衡量的是在某一时刻t下社区结构的质量;tc衡量的是当前t时刻下的社区结构st和t-1时刻下社区结构st-1之间的一致性;参数α是权重参数,可以改变相邻两社区之间的结构差。
得到最小化优化目标函数f=σ-αdλ-(1-α)nmi;
其中,σ是一常数。
在本实施方式中,采用动态网络社区检测中最常用的两种评价指标函数来评价社区划分的质量,分别是归一化互信息nmi和标准模块度q。
标准模块度q作为目标函数时会存在分辨率的问题,但在用做评价指标方面却有其不可取代的地位,特别是在网络的真实划分未知时,因此特别适合用于评价动态网络社区划分的优劣:
其中,ki和kj分别是节点i和j的度,m是网络的总边数,a是网络的邻接矩阵,kikj/2m表示节点i和j之间所有边数的期望值。
当节点i和j在同一个社区中时,δ(si,sj)=1,否则为0。
当q值大于0.3时,就可以认为该网络具有较为明显的社区结构,q值越高说明社区划分质量越好。
在本实施方式中,社区检测是在memetic算法框架下,利用遗传算法和爬山算法,对社区划分空间进行搜索。
编码模式:
采用直接式整数编码的方式,对网络g的一个社区划分s可以编码为一个整型字符串x={x1,x2,...,xn},其中x代表染色体,n代表网络g中的节点总数,xi(i=1,2,...,n)为节点vi的社区整型标识符,带有相同标识符的节点被视为处于相同社区;这种编码方式的优势在于无需提前知晓网络g中的社区数量,可以从网络划分的结果中获得。具有n个节点的单个网络图最大可以分成n个社区,此时每个社区只有一个节点存在,染色体表示为x={1,2,...,n}。
种群初始化:
采用基于标识符传递的初始化机制。
假设一个网络中节点数量为n,种群初始化前,所有染色体都为同样的整数编码{1,2,...,n};
首先随机选择个体中的一个节点i,假设节点i有k个邻居节点,邻居节点集为a(i),邻居节点标识符集合为s(i)={x1,x2,...,xk},网络中的每个节点标识符的初始化取决于其邻居集中的标识符;
若节点i的邻居集中所有节点的标识符都不同,则随机选择一个邻居标识符去覆盖原来的xi;
若节点i的邻居集中存在节点具有相同标识符的情况,则选择具有最大比例的那个标识符去覆盖原来的xi。
通过这种标识传递的初始化机制,既大大丰富了种群的多样性,连接紧密的节点也能够迅速被赋予共同的标识,具有较高的聚类精度。
遗传操作:
遗传算子由交叉和变异两方面的操作组成。交叉操作从染色体的整体出发,寻找适应值较高的染色体;适当地引入一些突变来增强遗传算法的局部搜索能力。
交叉步骤:
社区内部的节点采用小于等于节点总数的任意整数进行表示,具有较高的多样性,使用一种双路交叉的模式,定义如下:
假设存在两个亲代染色体xa和xb,两个染色体上的节点顺序相互对应;
首先在染色体xa上随机选择一个节点vi,vi的标识符为
同时,找出染色体xb中同样位置的节点vi以及和节点vi的标识符
这种交叉方式可以产生载有和双亲部分特征完全相同的子代,体现出交叉操作对于亲代资源充分利用的一面;另一方面,这种交叉过程十分具有探索性,它不像单切点交叉或双切点交叉,直接去切断染色体再简单地交换拼接,而是将双亲的特征进行有规律的结合。
表1所示例子里面子代染色体xc中,v1和v2成为了同一个社区中的节点。
表1双路交叉方式举例(当v2被选择时)
变异步骤:
采用基于邻位基因值的变异方式;在交叉后的染色体中随机挑选一个节点,然后将这个节点的标识符随机地变为其任意邻居节点的标识符,其中这些节点变异方向所能取到的标识符值被限定在其邻居节点的标识符值之中;
这种变异方式优势在于可以保证在变异过后的子代里面,染色体上的所有节点中,除了自身之外,有变化的节点只与其某个邻居有所关联,这可以大大缩小搜索空间,防止无效搜索,提高了算法的效率。
求取交叉概率pm和变异概率pc:
采用自适应的方法来模拟种群中个体本身在发育和遗传时,交配频率和范围、繁殖数量、变异程度会受到环境的变化而变化的情况,即在种群初期需要扩大搜索范围,避免早熟收敛,赋予算法较大的pc和pm;到了种群进化后期需要注重局部范围的搜索,以加快算法的收敛速度,则需要赋予算法较小的pc和pm。
使用logistic函数中来构造自适应的pc和pm;
其中,β1和β2是两个常数,β1∈(0,+∞),β2∈(0,1);pc∈(0.4,0.9),pm∈(0,0.1);这种构造方法比较合理。
局部搜索:
为了提高局部搜索算法的收敛速度和搜索精确度,且避免算法陷入局部最优过早,局部搜索采用爬山算法方式:
将全局搜索中得到的pareto解集看作局部搜索对象,通过爬山算法局部搜索产生最优解;
局部优化的适应度函数为ra和rc的权重和;
f1=fmax+ω1ra-ω2rc+x;
其中,fmax为保证适应值为非负的常数,x表示扰动参数,x为0.05;
ω1=i/n,i为种群中的个体序号,n为种群规模,ω2=1-ω1;
不同个体的ω1和ω2都不一样,致使在优化函数中进行自适应微调,从而扩大搜索范围。
具体的试验和分析:
利用两个真实动态通讯网络来验证dyn-smmcd算法的检测性能。
一是vast数据集(http://vast.cs.uml.edu/vast/repo/);
另一个是麻省理工学院学生接触网络(http://realitycommons.media.mit.edu/realitymining.html)。
(1)vast数据集来自2006年6月恐怖分子10天的电话记录,一共有400个不同的电话,9834条通讯记录。每个不同的电话可以看做是网络中的节点,两个电话之间的呼叫记录看做是网络中的边。将10天的通话记录按照每天为一组的方式构建一个由10个时刻组成的动态网络.
在图2中(a)、(b)中分别给出了dyn-smmcd算法、dyn-moga、dyn-nnia和escd在不同时刻的nmi值和q值。
由图1(a)可知,dyn-smmcd算法的nmi值明显高于dyn-moga和escd;在时刻7时略低于算法dyn-nnia,其余时刻点均高于算法dyn-nnia。
说明dyn-smmcd算法整体上在连续时刻中的瞬时顺滑度要优于其他算法,在时间代价方面消耗更低。
由图1(b)可知,dyn-smmcd算法的q值明显高于escd和dyn-nnia;在时刻3、4、9与dyn-moga算法值相近,其余时刻高于dyn-moga算法。
这说明dyn-smmcd算法整体上在全时刻内社区划分质量优于对比算法,划分的结构质量更好。
nmi值和q值宏观对比可知本算法在检验精度上具有明显的提高,具有较好的社区检测能力,而nmi值和q值在某些时刻低于对比算法,说明dyn-smmcd算法中仍然存在一些无效搜索,导致个别时刻点指标较低。
图3给出了dyn-smmcd算法在vast数据集上时刻3和时刻9的社区划分图。
从图2(a)中可以观察到网络中5个非常重要的人物erdinandocatalano、davidvidro、estabancatalano、jorgevidro和juanvidro(对应于节点201、2、6、3和4)联系较为频繁;
从图2(b)中能观察到节点301、310、307、398和361成为新的中心。
从图2(a)和(b)的对比中可以观察网络结构的变化,即从节点201、2、6、3和4改变到301、310、307、398和361。
在体现出运动趋势的同时,本算法还能够细分成其他小型联系频繁的社区,如图2(a)中节点16、21和55等所在的小社区,以及图2(b)中节点19、24、31和42等所在的小社区,体现出本算法在划分结构时具有更为细致和精确划分的能力,并体现出追踪到社团的演化特征的能力,这种能力可以让我们从节点的迁移变化中跟踪到犯罪分子,找出其现在所在的联系网络,有效地掌握到犯罪分子的通信网络的迁移情况,进行精准追捕布控,实现高效抓捕。
通过精细化划分之后获得的社区数量多,可以尽量多地发现犯罪参与者,真正实现“疏而不漏”,具有较大的现实意义。
(2)麻省理工学院学生接触的数据,包含有100名学生在九个月内的联系信息。由于它是包含百万个数据的较大数据集,我们无法全部进行分析,因此从中抽取了连续五个时刻作为代表,去验证我们的算法在日常往来中的分区识别、透过电话的联系了解关系亲疏的能力。
图4(a)和(b)显示了时刻2和3时,dyn-smmcd算法对学生接触数据集的结构划分,明显表现出了社区结构,分别有三个和五个社区。
这再一次验证了dyn-smmcd算法在通讯网络上划分的能力。也显示出了100名学生的社区结构随着时间变化的迁移情况,直观地展示了随着时间的变化动态网络会不断的产生新社团,消亡旧社团,大社团分裂和小社团结合等现象,本算法具有提取网络社区结构和追踪社区结构的演化能力。
综上,本发明dyn-smmcd算法采用memetic寻优框架,引入logistic函数模型,构造自适应遗传算子,可以提高收敛速度避免早熟收敛。通过框架内部的局部搜索机制,可以有效地减少搜索空间避免无效搜索,最终降低时间代价。
另外,dyn-smmcd算法还在遗传算法中使用多目标函数,即dλ和nmi,其中使用dλ解决了单纯使用模块度q可能存在的分辨率限制问题,可以同时优化平均内度和平均外度,降低复杂度的同时可以得到更精确和更细致的社区结构,最终提高快照代价,不同的pareto最优解还可以从不同层面分析网络划分。在真实的通讯联系网络上的试验结果表明,dyn-smmcd算法总体上能够提高社区检测的稳定性和准确度,能够有效地体现出动态联系网络的动态演变情况。
对于本领域技术人员而言,显然本发明不限于上述示范性实施例的细节,而且在不背离本发明的精神或基本特征的情况下,能够以其他的具体形式实现本发明。因此,无论从哪一点来看,均应将实施例看作是示范性的,而且是非限制性的,本发明的范围由所附权利要求而不是上述说明限定,因此旨在将落在权利要求的等同要件的含义和范围内的所有变化囊括在本发明内。不应将权利要求中的任何附图标记视为限制所涉及的权利要求。
- 还没有人留言评论。精彩留言会获得点赞!