一种基于聚类算法的联合频谱感知方法与流程
本发明涉及频谱感知领域,更具体地,涉及一种基于聚类算法的联合频谱感知方法。
背景技术:
随着无线通信需求的不断增长,当前固定的频谱分配政策已经不能满足人们的需求,于是人们提出了频谱感知技术,可以从时间和空间上充分利用那些空闲的频谱资源,从而有效的解决频谱资源的不足,提高频谱资源的利用率;频谱感知的基本出发点就是在不影响正常频段的正常通信的基础上,具有感知功能的无线通信设备可以按照某种机会方式接入授权的频段内,并且动态的利用频谱。
传统的频谱感知方法主要包括能量检测,匹配滤波器检测,循环平稳特征检测和基于机器学习的频谱感知方法;基于机器学习的频谱感知方法中K-means聚类方法是一种比较经典的频谱感知方法;该方法通过有主用户信号的采样信号矩阵和没有主用户信号的采样信号矩阵,分别得到两组协方差矩阵,由两组协方差矩阵分别可以得到特征值的集合,通过循环的方式可以分别得到两组最大与最小特征值之差的值的集合,随机组合两个值作为一个二维平面点的坐标,然后可以得到二维平面上点的坐标集合,通过k-means方法聚类训练分别得到两个点集合的中心点,将待测样本与中心点进行比较从而判定待测信号是否含有主用户信号。
基于普通K-means方法的频谱感知算法的不足有:算法通过对有主用户信号和无主用户信号的协方差矩阵得到的特征值集合进行聚类得到聚类中心,由于噪声的干扰,协方差矩阵的特征值无法明显体现有无主用户信号,从而影响聚类效果,降低检测性能;普通k-means算法聚类前的起始聚类中心点为随机选择,导致算法收敛速度较慢;普通k-means算法是对二维平面数据集进行聚类,数据样本维度较低,聚类性能不高;普通k-means算法是对单一的数据集进行训练,获取聚类中心,然后进行信号检测,受到单一数据集误差影响较大,导致单一特征检测时的准确率不高。
技术实现要素:
本发明为克服上述现有技术所述的单一特征检测时的准确率不高的缺陷,提供一种基于聚类算法的联合频谱感知方法。
所述的方法包括以下步骤:
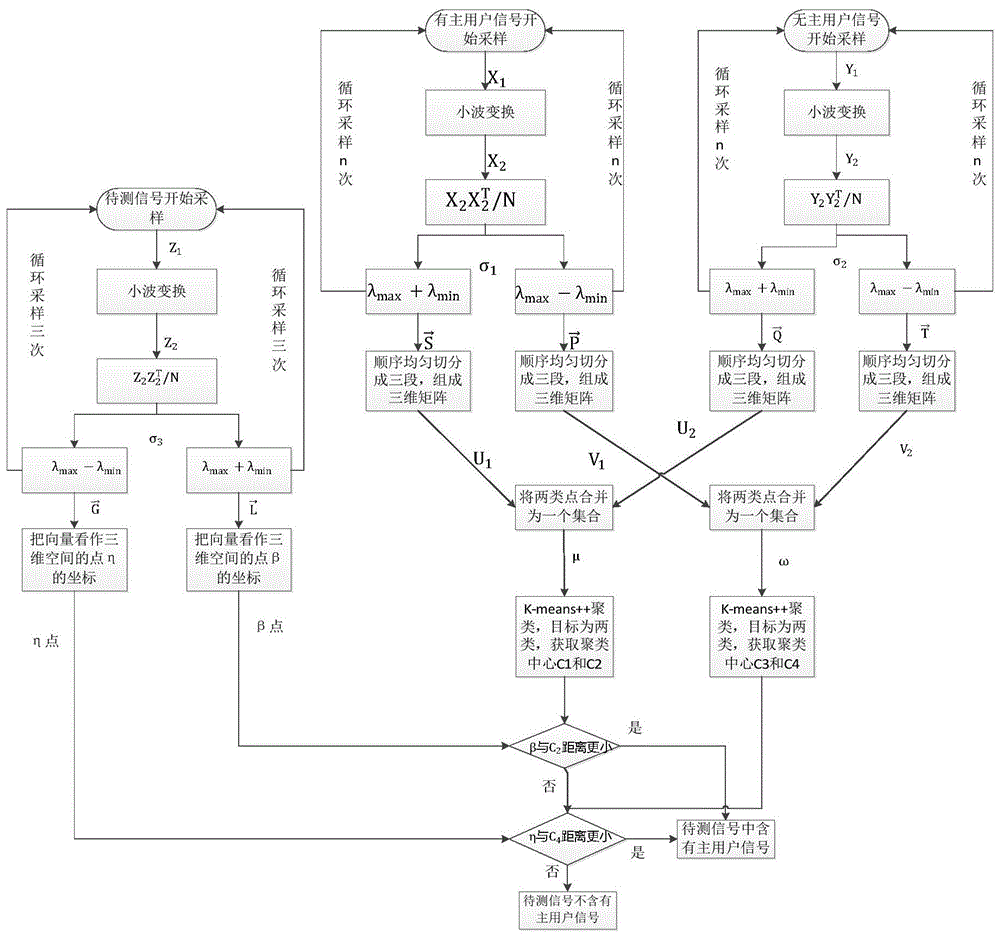
S1:输入采样矩阵;对采样矩阵进行小波变换降噪,得到降噪后的采样矩阵;
S2:将降噪后的采样矩阵进行处理,得到协方差矩阵;
S3:取S2所得协方差矩阵的最大特征值和最小特征值相加得到一个和值,取S2中所得协方差矩阵的最大特征值和最小特征值相减得到一个差值;
S4:输入待测信号的采样矩阵,循环S2-S4三次,分别得到三个和值L1、L2、L3和三个差值G1、G2、G3;将三个差值和三个和值分别组成向量和
输入有主用户信号存在情况下的采样矩阵,循环S2-S4,循环的次数为n次,且n为3的倍数,分别得到n个和值S1,S2…Sn和n个差值P1,P2…Pn;将n个和值和n个差值分别组成向量和
输入无主用户信号存在情况下的采样矩阵,循环S2-S4,循环的次数为n次,且n为3的倍数,分别得到n个和值Q1,Q2…Qn和n个差值T1,T2…Tn;将n个和值和n个差值分别组成向量和
S5:取三维坐标的中点为β,取的中点为η;
将顺序均匀切分成三段然后组成一个3×(n/3)的矩阵,以该矩阵的每一列为一个三维空间中点的坐标,于是可以得到n/3个三维空间中心的集合U1;
将顺序均匀切分成三段然后组成一个3×(n/3)的矩阵,以该矩阵的每一列为一个三维空间中点的坐标,于是可以得到n/3个三维空间中心的集合V1;
将顺序均匀切分成三段然后组成一个3×(n/3)的矩阵,以该矩阵的每一列为一个三维空间中点的坐标,于是可以得到n/3个三维空间中心的集合U2;
将顺序均匀切分成三段然后组成一个3×(n/3)的矩阵,以该矩阵的每一列为一个三维空间中点的坐标,于是可以得到n/3个三维空间中心的集合V2;
S6:将U1、U2的点混合得到点的集合μ,将V1、V2的点混合得到点的集合ω;通过k-means++聚类算法分别对μ和ω集合中的点进行聚类,分别得到聚类中心C1、C2和C3、C4;
S7:比较β点与C1、C2的距离,如果β点与C2点距离更小,则判断待测信号中含有主用户信号;否则进行S8;
S8:比较η点与C3、C4的距离,如果η点与C4点距离更小,则判断待测信号中含有主用户信号;否则判断待测信号中不含有主用户信号。
本发明在低信噪比情况下小波变换和k-means++联合方法比传统方法检测概率更高,性能更优。
优选地,步骤S1包括以下步骤:
S1.1:通过小波变换以获得小波系数;
S1.2:对小波系数进行阈值处理以获得估计系数;
S1.3:使用估计系数执行小波重构并获得去噪后信号。
S1.4:将去噪后信号按照顺序重新拆分,得到降噪后采样信号矩阵。
优选地,步骤S2的处理公式为:
δ=XXT/N
其中,δ为协方差矩阵,X为降噪后的采样矩阵,N为X列向量的个数。
优选地,步骤S6中k-means++聚类算法的聚类过程如下:
S6.1:从数据集中随机选择其中一类的一个样本作为初始中心点之一,然后计算该中心点与其他中心点的距离,选择与该中心点距离最大的点为另外一个初始中心点,并且该中心点所属另外一类;
S6.2:针对数据集中的每个样本,计算它到两个中心点的距离,并将其分到距离最小的聚类中心所对应的类中;
S6.3:设其中一类有m个点,该类任意一点坐标为(xi yi zi),则可得到该类新的中心点为:
同理可得到另外一个新的中心点;
S6.4:重复步骤S6.2-S6.3,直到无法产生新的中心点为止,最终的中心点即为所求聚类中心。
优选地,步骤S7中的比较判据为:
则预测β点属于有主用户信号类别,于是判断β来源的采样矩阵中含有主用户信号,否则进行步骤S8;
其中,C1的坐标为(a1,b1,c1),C2的坐标为(a2,b2,c2),β的坐标为(L1,L2,L3),β使用最大最小特征值之和作为坐标参数;
优选地,步骤S8中的比较判据为:
则预测η点属于有主用户信号类别,于是判断η来源的采样矩阵X中含有主用户信号,否则判断采样矩阵X中无主用户信号;
其中,C3的坐标为(a3,b3,c3),C4的坐标为(a4,b4,c4),η坐标为(G1,G2,G3),η使用最大最小特征值之差作为坐标参数。
与现有技术相比,本发明技术方案的有益效果是:本发明同时使用协方差矩阵的最大最小特征值之和和最大最小特征值之差作为训练特征,从而实现两种特征联合检测,提高单一特征检测时的准确率。
附图说明
图1为本发明所述方法流程图。
图2为SNR=-20时以最大最小特征值之和为坐标参数的点的最终聚类情况图。
图3为SNR=-20时以最大最小特征值之差为坐标参数的点的最终聚类情况图。
图4为本实施例虚警概率和检测概率对比图。
具体实施方式
附图仅用于示例性说明,不能理解为对本专利的限制;
为了更好说明本实施例,附图某些部件会有省略、放大或缩小,并不代表实际产品的尺寸;
对于本领域技术人员来说,附图中某些公知结构及其说明可能省略是可以理解的。
下面结合附图和实施例对本发明的技术方案做进一步的说明。
本实施例提供一种基于聚类算法的联合频谱感知方法;
如图1所示,所述的方法包括以下步骤:
S1:假设一个认知无线电系统,有一个主用户PU和M个认知用户SU,每个SU的采样点数为N。H0表示为主用户信号不存在,H1表示为主用户信号存在。因此在两种情形下接收信号的模型可由下式表示:
其中,Wi(n)表示均值为0,方差为δ2的高斯白噪声,Si(n)表示PU的信号。
实验过程中的信号发生器的输出端输出两种信号,一种输出H0情况下的信号,一种输出H1下的信号。
在H1情况下,输出信号包含主用户信号和噪声信号,假设第i个SU的采样信号向量可表示为:xi(n)=[xi(1),xi(2),...,xi(N)];初期采样信号矩阵X可以表示为如下式所示的M×N维的矩阵:
将该矩阵顺序合并为逻辑上为单一认知用户的矩阵:
X'=[x1(1)x1(2)···x1(N)x2(1)x2(2)···x2(N)···xM(1)xM(2)···xM(N)]
对认知用户矩阵X'进行小波变换,具体步骤如下:
S1.1:通过小波变换信号X以获得小波系数W。
S1.2:对小波系数W进行阈值处理以获得估计系数
S1.3:使用执行小波重构并获得去噪后信号X'。
将去噪信号Y'按照顺序重新拆分为M×N维的矩阵,得到降噪后采样信号矩阵Y。
S2:将降噪后的采样矩阵进行处理,得到协方差矩阵;
S3:在σ1的特征值之中可以得到最大特征值λmax和最小特征值λmin,于是得到:
P1=λmax-λmin
S1=λmax+λmin
同理,在H0情况下可以得到协方差矩阵σ2,在σ2的特征值之中可以得到最大特征值λ'max和最小特征值λ'min,于是得到:
T1=λ'max-λ'min
Q1=λ'max+λ'min
S4:通过n次循环,n为3的倍数,可以得到四个一维向量:
S5:将这些向量顺序拆分为三维矩阵:
把矩阵P′,S′和T′,Q′中每一列当作是三维空间中点的坐标,可以分别得到假想的三维空间点的集合V1,U1和V2,U2。将U1、U2的点混合得到点的集合μ,将V1、V2的点混合得到点的集合ω;通过k-means++聚类算法分别对μ和ω集合中的点进行聚类。
k-means++聚类算法(两个聚类中心)的训练流程如下:
S6.1:从数据集中首先随机选择其中一类的一个样本作为初始中心点之一,然后计算该中心点与其他点的距离,选择与该中心点距离最大的点为另外一个初始中心点,并且该中心点所属另外一类。
S6.2:针对数据集中的每个样本,计算它到两个中心点的距离,并将其分到距离最小的聚类中心所对应的类中。
S6.3:假设其中一类有m个点,该类任意一点坐标为(xi yi zi),则可得到该类新的中心点为:
同理可得到另外一个新的中心点;
S6.4:重复S6.2-S6.3两步,直到无法产生新的中心点为止,最终的中心点即为所求聚类中心。
对U1、U2的点混合得到点的集合μ进行k-means++算法聚类,可以得到无主用户信号类别的聚类中心C1和有主用户信号类别的聚类中心C2;
对V1、V2的点混合得到点的集合ω进行k-means++算法聚类,可以得到无主用户信号类别的聚类中心C3和有主用户信号类别的聚类中心C4;
S7:令C1坐标为(a1,b1,c1)C2坐标为(a2,b2,c2),令C3坐标为(a3,b3,c3)C4坐标为(a4,b4,c4),待检测点β坐标为(L1,L2,L3),待检测点η坐标为(G1,G2,G3),β使用最大最小特征值之和作为坐标参数,η使用最大最小特征值之差作为坐标参数,两个采样点都来源于同一个采样矩阵Z1。
如果:
则预测β点属于有主用户信号类别,于是判断β来源的采样矩阵Z1中含有主用户信号,否则继续进行S8判断。
S8:如果:
则预测η点属于有主用户信号类别,于是判断η来源的采样矩阵Z1中含有主用户信号,否则判断采样矩阵Z1中无主用户信号。
图2为SNR=-20时以最大最小特征值之和为坐标参数的点的最终聚类情况,C1为无主用户信号类别的聚类中心,C2为有主用户信号类别的聚类中心。
图3为SNR=-20时以最大最小特征值之差为坐标参数的点的最终聚类情况,C3为无主用户信号类别的聚类中心,C4为有主用户信号类别的聚类中心。
图4是在SNR=-20db情况下,比较了二维单一特征情况下非小波变换k-means算法与三维联合特征情况下小波变换和k-means++联合方法的虚警概率和检测概率对比图,从图中可以表明,在低信噪比情况下小波变换和k-means++联合方法比传统方法检测概率更高,性能更优。
相同或相似的标号对应相同或相似的部件;
附图中描述位置关系的用语仅用于示例性说明,不能理解为对本专利的限制;
显然,本发明的上述实施例仅仅是为清楚地说明本发明所作的举例,而并非是对本发明的实施方式的限定。对于所属领域的普通技术人员来说,在上述说明的基础上还可以做出其它不同形式的变化或变动。这里无需也无法对所有的实施方式予以穷举。凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明权利要求的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!