针对超大规模片上网络容忍众故障的确定性路径路由方法与流程
本发明属于片上网络的架构设计和路由技术领域,涉及一种超大规模片上网络的路由方法,尤其是涉及一种针对超大规模片上网络容忍众故障的确定性路径路由方法。
背景技术:
凭借强大的并行通信能力,大规模片上网络已经成为超级计算机中最有前途的结构。而晶圆级noc(networkonchip,片上网络)可以将芯片之间的大量并行通信移动到芯片内部,这减少了传输延迟,从而显着提高了计算性能。同时,由于将单个芯片作为小型超级计算机,这种结构可以让超级计算机更加节省能量。因此,开发晶圆级noc成为进一步提高超级计算机性能的有效措施。
确保高产量是开发晶圆级noc的关键问题。大规模晶圆级noc将遇到许多故障问题,因为芯片上的故障概率与芯片的尺寸成比例。如果在noc中的任何地方出现故障时直接丢弃每个故障的晶片级noc,则产量将非常低,并且生产成本不切实际地高。保持晶圆级noc的高产量的可行解决方案是在晶圆上实现更多的处理路由器(即节点),只要芯片上可用节点的数量超过设计要求,就将故障芯片视为良好的芯片。幸运的是,noc通信结构支持此解决方案,因为它为节点间通信提供了自然的许多备用路径。我们需要的是一种路由算法,以容忍在晶圆级noc的制造和操作阶段可能发生的潜在的许多故障。
片上网络系统主要由以下部分组成:网络接口、处理单元、路由器和互连网络,由于其自身元器件的电气特性而极大地增加了产生故障的可能性。因此,片上网络需要具备有强大的容错能力,容错相关技术是片上网络的重要支撑技术之一。
由于在noc中,路由可能会产生循环依赖以致导致发生路由死锁,使路由的数据包处在无限等待下一跳缓存区处于空闲状态,这会导致路由的数据包无法到达目的地,因此,如何避免死锁也是容错路由算法一个很重要的研究内容。由于可以使用无故障的链路来替换故障连链路或者是绕过故障节点,因此,容错路由算法可以为noc提供一定的容错能力。
其次,在noc中,如果某一个节点同一时刻接收或者传递过多的数据包,就会导致缓存区一直处于忙碌状态,没有空闲的缓存区,这会导致需要路由到这一节点的数据包处于等待状态,会导致局部的路由拥塞,增加了路由的延迟从而使noc的性能降低。因此容错路由算法也需要很好地解决路由拥塞,才能使算法在容错的同时具备较高的性能。
在noc的容错路由算法领域,已经有很多的研究成果,但是大部分都没有考虑noc中可能存在的众多故障。
基于turnmodel理论提出了几种容错路由算法,这些路由算法不依赖于虚拟通道,并且可以又很有的避免死锁的效果,但是这些路由算法由于严格遵守了禁止转向的规则,从而导致严格禁用了指定的路由转向,这会导致有一些路由因为这些规则不能发生,会造成一定程度的丢包现象。
hamfa算法是一种简单可行的路由算法,它可以容忍链路故障。该算法为noc的每个节点分配hamfaid。然后,它根据这些hamfaid将网络划分为两个子通道:升序通道和降序通道。该算法还设置从当前节点到北邻居(或南邻居)节点的链路作为快速链路。路由器更倾向于通过快速链路发送数据包。当故障出现在快速链路上时,路由器使用上行路径(或下行路径)。因此,该算法通常容忍单个故障的影响。但是,当快速路径与下行(或上升)路径重合,并且故障刚好出现在相应的链路上时,该算法将无法容忍这样的故障。
zonedefense算法是一种能够容忍多故障的强大的路由算法,但是其只针对节点故障。该算法首先根据现有故障节点确定不安全节点。然后,它设置几个矩形区域以覆盖所有不安全的节点,这样的区域称为不安全区域。之后,该算法提出lchains(或fchains)来围绕这些区域。最后,即使出现多个故障节点,该算法也可以通过lchains(或fchains)发送数据包并绕过这些故障区域,从而实现容忍多个故障节点。但是,该算法牺牲了包含在不安全区域中的所有原始无故障节点。因此,该算法不适用于具有众多故障的noc,因为它几乎不能确保noc具有足够的可用节点以满足设计要求。
技术实现要素:
本发明的目的就是为了克服上述现有技术存在的缺陷而提供一种针对超大规模片上网络容忍众故障的确定性路径路由方法。
本发明的目的可以通过以下技术方案来实现:
一种针对超大规模片上网络容忍众故障的确定性路径路由方法,其特征在于,该方法在片上网络的每个交换机上维护一路由表,各交换机基于该路由表进行在线路由,
所述路由表离线生成,生成过程包括:基于tarjan算法计算片上网络的最大强连通分量,删除故障节点及故障链路,利用广度优先遍历策略遍历片上网络剩余节点及链路,生成路由表。
进一步地,将片上网络视为一个有向图生成路由表,每一个节点对应所述有向图中的一个节点,每一条链路对应所述有向图中的一个有向边,节点的标签按照从下到上、从左到右的顺序依次排序。
进一步地,在片上网络在线检测到故障时,路由表离线更新,实现路由表的动态重配置。
进一步地,利用所述广度优先遍历策略生成路由表时:
a)忽略已经遍历过的已经在路由树中的邻居节点;
b)选择邻居节点作为孩子节点时,优先选择标签值最小的节点。
进一步地,利用所述广度优先遍历策略生成路由表时,仅获取可达邻居节点。
进一步地,在发生故障时,基于turnmodel理论对片上网络的节点及链路进行预处理后,生成所述路由表。
进一步地,所述预处理包括:
p1)当片上网络的西或南边界出现故障链路时,将该故障链路相对反向链路设置为故障链路,并将故障链路称为弃用链路;
p2)当垂直或水平方向的弃用链路的东邻居或北邻居链路出现故障时,将故障链路设置为弃用链路;
p3)当节点的西向和南向链路均为非弃用链路,而西输出链路和南输出链路均为故障链路时,将该节点设置为已弃用节点;
在片上网络中删除弃用链路和已弃用节点后,利用广度优先遍历策略进行遍历,生成路由表。
进一步地,基于turnmodel理论生成路由表时,
r1)若当前节点的西链路和其西邻节点的北链路均为非弃用链路,而当前节点的西输出链路或其西邻节点的北输出链路有故障,则以当前节点及其正东侧所有节点的北输出链路均为故障链路为基础,计算当前节点的西侧区域内节点的路由方向;
r2)若当前节点的南链路和其南邻节点的东链路均为非弃用链路,而当前节点的南输出链路或其南邻节点的东输出链路有故障,则以当前节点正东侧所有节点的南输出链路均为故障链路为基础,计算当前节点的南侧区域内节点的路由方向。
与现有技术相比,本发明具有以如下有益效果:
1、本发明方法利用广度优先遍历策略生成路由表,不仅可以容忍许多故障,还可以能尽量选择最短的路由路径,确保交换机在一个周期内具有较小的单跳延迟;
2、本发明使用tarjan算法进行动态重新配置,在重新配置后最大化noc上的可用节点;
3、本发明基于turnmodel理论设置了弃用链路/节点,可以在不适用虚拟信道的情况下实现noc的无死锁通信;
4、本发明在平均延迟,吞吐量和能量消耗方面的性能也优于现有解决方案。
附图说明
图1为本发明的总体设计示意图;
图2为本发明路由表的结构示意图;
图3为动态重配置实例示意图;
图4为无故障时noc中可能产生的路由转向,其中,(4a)为所有可能转向,(4b)为顺时针环,(4c)为逆时针环;
图5为有故障时noc中可能产生的死锁,其中,(5a)为故障导致不存在的转向,(5b)为故障导致可能产生路由环;
图6为dpra采用的禁止转向,其中,(6a)为顺时针方向,(6b)为逆时针方向;
图7为预处理实例;
图8为避免死锁的故障链路设置示意图;
图9为死锁证明示意图,其中,(9a)为c1证明示意图,(9b)为c2证明示意图;
图10为16*16noc中zonedefense与dpra可用节点实验结果;
图11为16*16noc中hamfa与dpra可靠度实验结果;
图12为xy路由算法和dpra的平均延迟对比;
图13为hamfa和dpra的平均延迟对比;
图14为zonedefense和dpra的平均延迟对比;
图15为xy路由算法和dpra的吞吐量对比;
图16为hamfa和dpra的吞吐量对比;
图17为zonedefense和dpra的吞吐量对比;
图18为xy路由算法和dpra的能耗对比;
图19为hamfa和dpra的能耗对比;
图20为zonedefense和dpra的能耗对比;
图21为noc中能耗实验结果;
图22为不同尺寸下不同算法面积开销示意图。
具体实施方式
下面结合附图和具体实施例对本发明进行详细说明。本实施例以本发明技术方案为前提进行实施,给出了详细的实施方式和具体的操作过程,但本发明的保护范围不限于下述的实施例。
一、相关定义与相关指标
1.相关定义
片上网络(networkonchip,noc):片上网络是一种新的片上系统内各个ip核之间的通信方法。noc是多核技术的重要组成部分,为片上通信带来了一种新的思路,其明显优于传统的基于总线的系统。基于noc的系统更加适用于未来多核复杂的soc设计中的局部同步全局异步的时钟机制。noc解决了片上系统架构的可扩展性问题以及相关的片上互连问题,并提供了一种高效的片上通信的方法。伴随着单个芯片上集成的ip核数量地不断增加,片上互连架构的发展经历了从专用互连线,总线,交叉开关到片上网络。片上网络的提出借鉴了分布式计算系统的通信方式,采用分组交换技术和数据路由取代了传统的总线结构,解决了soc总线结构地址空间有限导致的可扩展性差,分时通信带来的通信效率问题,以及由全局时钟同步引起的面积和功耗问题。
容错路由算法:路由算法负责寻找数据包的路由路径,该路径负责准确地将数据包发送到目的地节点。由于noc是在单个芯片上实现的,具有面积和功耗的限制,在设计noc路由算法时必须满足以下要求:
1)路由算法必须能够正确地将分组发送到目的地节点,即要求路由算法无活锁和死锁;
2)路由信息的计算必须要简单,只有计算简单才能使相应的硬件设施速度更快、体积更小;
3)因为网络资源紧张,所以应该尽量选择最短路径,或者限制绕道次数的绕道路由算法;
4)路由算法应当公平对待noc中的所有节点,以防止饥饿。
死锁:死锁是指两个或两个以上的进程在执行过程中,由于竞争资源或者由于彼此通信而造成的一种阻塞的现象,若无外力作用,它们都将无法推进下去。此时称系统处于死锁状态或系统产生了死锁,这些永远在互相等待的进程称为死锁进程。在noc网络中,对于各自相邻的四个节点,如果每个节点都向其对角的节点发送数据包,则四个数据包都会等待下一跳的缓存区空闲才发送出去,由此四个数据包的路由便产生了死锁。
2.相关指标
本发明对路由算法的评估指标包括可靠性、可用节点数、延迟、吞吐量、能量、交换机单跳延迟和硬件面积开销等。
可用节点评估:当noc中发生众多故障时,不可避免地会牺牲掉某些健康的节点,因为有些健康节点会被故障环绕而导致其完全无法工作。在这种情况下,在相同的noc和故障配置时,路由算法拥有越多的可用节点就能一定程度表明该路由算法具有更好的性能。
可靠度评估:可靠度是noc容错路由算法的一个重要评估指标,指元件、产品、系统在一定时间内、在一定条件下无故障地执行指定功能的能力或可能性。可通过可靠度、失效率、平均无故障间隔等来评价产品的可靠性。
性能指标评估:本发明采取平均延迟、吞吐量和能量消耗作为实验中路由算法的性能指标。其中,数据包传输的平均延迟是度量路由算法性能的一个重要指标,平均延迟定义为从处理元件发出的消息的发起与数据包完全递送到目的地的时间之间的周期数的平均值。在片上网络中,吞吐量定义为在总仿真周期中接收到的分组的数量;吞吐量表明了noc对数据包的容纳和处理能力;能耗是指在总仿真周期中,noc所有元器件,包括路由器、处理器、链路等所消耗的总的能量。
二.本发明方法原理
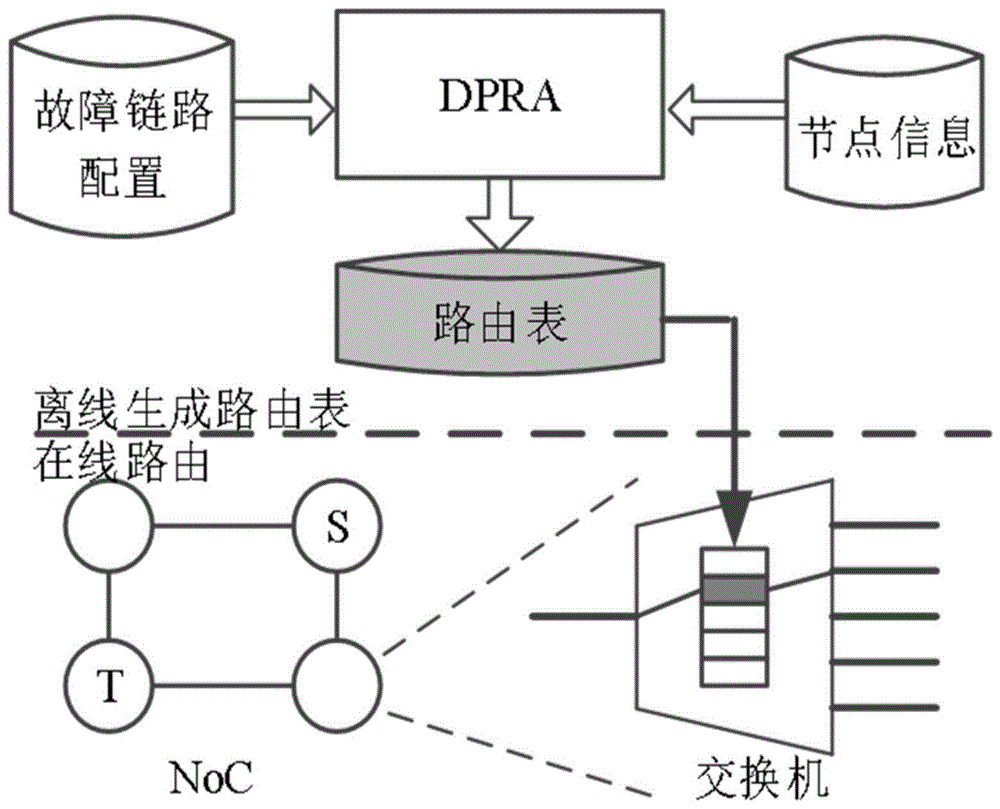
本发明提供一种针对超大规模片上网络容忍众故障的确定性路径路由方法(deterministic-pathroutingalgorithmfortoleratingmanyfaultsonwafer-levelnoc,dpra),可以容忍晶圆级noc上的众多故障,其核心思想是利用离线生成的路由表来进行在线传输数据包。如图1所示,该方法在片上网络的每个交换机上维护一路由表,如图2所示,各交换机基于该路由表进行在线路由,所述路由表离线生成,生成过程包括:基于tarjan算法计算片上网络的最大强连通分量,删除故障节点及故障链路,利用广度优先遍历策略遍历片上网络剩余节点及链路,生成路由表,实现可降级的noc动态重配置。在片上网络在线检测到故障时,路由表离线更新,实现路由表的动态重配置。进一步地,本发明在发生故障时,还基于turnmodel理论对片上网络的节点及链路进行预处理后,生成所述路由表,确保noc的无死锁通信。
1.基于广度优先遍历生成路由表
对于生成路由表的算法,本发明将noc网络整个视为一个有向图,每一个节点对应图中的节点,每一条链路对应有向图中的一个有向边,对于故障链路和故障节点,直接将其中有向图中删除对应的节点和边。然后以当前节点作为起始节点,对noc网络采用广度优先遍历,生成一棵路由树。在路由树中,根节点到达每个节点的路径就是noc中当前节点到达目的地节点的路由路径。
由于在路由器中存储一棵树会有很大的硬件开销,于是根据这棵树可以生成一张路由表,每个节点都需要配备这样一个路由表,路由表中记录了当前节点发往目的地节点的下一跳方向。这样能在noc中以更小的硬件开销实现dpra。
1.1.无故障时
在无故障时,本发明将noc视为一个强连通图,每两个相邻的节点之间有两个有向边连接。
在离线时,dpra首先遍历每一个节点,对每一个节点生成各自的路由表。dpra将当前节点视为根节点,然后对noc进行广度优先遍历,该算法会忽略掉已经遍历过的几点。对于具有多个邻居节点的节点,dpra会优先选择节点标签值较小的邻居节点进行遍历。这样通过广度优先遍历之后会生成一棵以当前节点为根节点的路由树。
对于路由树中的节点,其所在子树的根节点相较于路由树的根节点的方向就是当前节点发往目标节点的下一条路由方向。通过这个结论,可以根据生成的路由树生成一张路由表。
由于采用了广度优先遍历,所以在无故障时,dpra可保证数据包总是沿最短路径路由。
本发明将通过noc生成路由树和通过路由树生成路由表的两个过程整合在一起,称之为路由表生成算法,其伪代码如下:
无故障时计算邻居节点的核心思想是根据当前节点id与noc尺寸来获取邻居节点的id集合,伪代码如下:
计算下一跳方向的伪代码如下:
上述过程的核心思想是根据当前节点id和下一跳节点id来计算下一跳的方向。
1.2有故障时
当noc中存在故障时,借助于现有的故障检测机制,dpra可以离线获取所有的故障链路或节点的信息,其中节点故障可以等价成链路故障,然后在noc对应的有向图中,删除故障链路对应的有向边同,再对有向图执行路由表生成算法。
这里对获取邻居节点的算法进行一点改进:若是当前节点因为故障不可直达邻居节点,那么就不选取这个邻居节点。本发明称其为获取可达邻居节点的算法,主要是在考虑故障的情况下,根据当前节点id与noc尺寸来获取邻居节点的id集合,其伪代码如下:
2.基于tarjan算法实现可降级与动态重配置
tarjan算法是一种由roberttarjan提出的求解有向图强连通分量的线性时间的算法。tarjan算法是基于对图深度优先搜索的算法,每个强连通分量为搜索树中的一棵子树。搜索时,把当前搜索树中未处理的节点加入一个堆栈,回溯时可以判断栈顶到栈中的节点是否为一个强连通分量。tarjan算法的伪代码如下:
如果noc中产生了众多的故障,导致某些节点不能正常工作。在这种情况下需要对这些不能正常工作的节点进行舍弃,具体是不允许弃用节点发送和接收数据包,并且与其直接相连的链路全部是为故障链路,虽然这样会降低noc的性能,但是可以使noc依旧可以正常工作。
本发明将noc视为一个有向图,然后使用tarjan算法计算noc的最大强连通分量,并且将不在最大强连通分量中的节点弃用,具体表现为不允许弃用节点发送和接收数据包,并且与其直接相连的链路全部为故障链路。应用tarjan算法计算noc的最大强连通分量的伪代码如下:
由于降级的noc是原始noc的最大强连通分量,因此该算法最大化新noc中的可用节点数。
通过使用现有的检测动态故障的方法,该算法可以支持动态重配置。当检测故障方法在noc中检测到动态故障时,算法首先执行tarjan算法以确定noc是否仍然是强连通图。如果是,则算法重新计算遍历树并更新每个路由表;否则,算法执行所述的降解操作,并更新路由表。
如图3所示,如果链路n11=>n15在线时产生了一个动态故障,则dpra执行tarjan算法可以确定节点n15不再连接到noc。然后dpra在当前noc拓扑中禁用n15,并重新生成noc的最大强连通分量。降级的noc包含13个节点,dpra再重新为每个节点更新其路由表。最后,dpra通过其他信道(例如测试信道)将路由表更新到每个节点。
3.基于turnmodel和弃用链路避免死锁
避免死锁是路由算法设计中的一个严峻的挑战,虽然已经有很多避免死锁的方案,但是都有各自的缺陷。比如使用虚拟信道的方案会造成较大的面积开销和能耗开销;使用turnmodel的方案会造成禁用了某些唯一的路径,导致原本可达的路由不可使用等等。而路由死锁会严重影响路由算法的性能,因此容错路由算法必须支持避免路由死锁。
为了规避turnmodel中禁止转向可能会导致某些路由无法到达目的地的局限性,本发明提出了基于turnmodel的预处理方式来避免死锁,同时,可以允许某些禁止转向发生而不产生死锁。本实施例结合dpra的特性,在无故障和有故障的情况下分别探讨dpra的避免死锁的特性,在无故障时,dpra不会产生死锁,在有故障时,可以避免死锁,并出了无死锁证明。
所述预处理包括:
p1)当片上网络的西或南边界出现故障链路时,将该故障链路相对反向链路设置为故障链路,并将故障链路称为弃用链路;
p2)当垂直或水平方向的弃用链路的东邻居或北邻居链路出现故障时,将故障链路设置为弃用链路;
p3)当节点的西向和南向链路均为非弃用链路,而西输出链路和南输出链路均为故障链路时,将该节点设置为已弃用节点;
在片上网络中删除弃用链路和已弃用节点后,利用广度优先遍历策略进行遍历,生成路由表。
基于turnmodel理论生成路由表时,还依据以下设置:
r1)若当前节点的西链路和其西邻节点的北链路均为非弃用链路,而当前节点的西输出链路或其西邻节点的北输出链路有故障,则以当前节点及其正东侧所有节点的北输出链路均为故障链路为基础,计算当前节点的西侧区域内节点的路由方向;
r2)若当前节点的南链路和其南邻节点的东链路均为非弃用链路,而当前节点的南输出链路或其南邻节点的东输出链路有故障,则以当前节点正东侧所有节点的南输出链路均为故障链路为基础,计算当前节点的南侧区域内节点的路由方向。
3.1.无故障时
当noc中无故障时,由于路由表生成算法中的优先选择较小邻居节点与节点编号的共同作用,导致dpra算法中路由的可能转向如图(4a)所示。
于是分别如图(4b)和(4c)所示,在顺时针和逆时针方向都不可能会产生路由环。根据turnmodel可得,dpra算法在无故障的noc中不会导致死锁地产生。
3.2有故障时
当noc中存在故障时,如图5所示,故障可能会导致原本不存在的转向发生,于是noc中就有产生路由环的可能,也就是说在有故障时,noc中有产生死锁的可能。
在这种情况下,就需要使用一些方法来禁止死锁的产生。
本发明基于turnmodel来实现无死锁。如图6所示,分禁用顺时针和逆时针方向上右上角的一个转向来避免路由环的产生,也就可以避免死锁的产生。
3.3.故障预处理
如前所述,dpra可以轻松地离线执行这些预处理操作。例如,图7中n0和n1之间的两个相对链路根据p1被视为弃链路;根据p2,n9和n5之间的两个相对链接也被视为弃用链接;根据p3,节点n7被视为弃用节点,从而禁止可能的nw转弯。
因为有些禁止转向即使发生了也不会在noc中产生路由环,这些预处理步骤的主要作用是找出允许的禁止转向,并且在后续操作中不对这些转向进行禁止操作。从而尽可能减少规避掉turnmodel的局限性。
3.4.避免死锁处理
图8给出了避免死锁的两个例子。假设当前节点是n10,如果链路上出现故障n10=>n9,则符合r1。当计算由节点n0,n1,n4,n5,n8,n9,n23和n13组成的w框内的节点的路由方向时,本实施例链路n10=>n14和n11=>n15都是故障的。然后更新当前节点路由表中以这些w框内节点为下标的位置上的值,同时更新当前节点正南方向节点n6和n2的路由表。由于r1,nw转弯不会出现。若是链路10=>9或9=>13中存在一条启用链路,则r1也不会被使用。
假设当前节点是n9,如果链路上出现故障n9=>n5,则符合r2。当计算由节点n0,n1,n2,n3,n4,n5,n6和n7组成的s框内的节点的路由方向时,设置链路n10=>n6和n11=>n7都是故障的。然后,更新当前节点路由表中以这些s框内节点为下标的位置上的值,同时更新当前节点正西方向节点n8的路由表。由于r2,es转弯不会出现。若是链路9=>5或5=>6中存在一条启用链路,则r2也不会被使用。
3.5.无死锁证明
本实施例使用反证法对提出的避免死锁处理方式进行证明。如图9所示,首先假设即使noc采用了预处理操作和避免死锁处理后,也会出现逆时针环,这意味着路由至少发生一次nw转弯。因此,无故障noc中的正常传输wn转向被故障链路破坏,所以分组被迫沿nw转弯行进。在这种情况下,将出现这两个条件中的至少一个:
c1:在该环的区域中出现至少一对水平弃用链接或垂直弃用链接。
c2:在该环的区域中存在错误的西输出链路或错误的北输出链路。
对于c1,如图(9a),一旦存在一对水平弃用链路(或垂直弃用链路),由于p1和p2,故障链路南侧(或西侧)的所有链路都是弃用链路。即这个逆时针环不可能产生,于是违反了存在逆时针环的原假设。
对于c1,如图(9b)所示,如果在该环的区域中出现故障的西输出链路(或故障的北输出链路),则采用r1,在计算下一跳方向时,设置故障链路东侧的所有北输出链路都是故障链路。方向。因此nw转弯不会出现。因此,逆时针环不存在。也违反了存在逆时针环的原假设。
顺时针环也同理可证。于是,noc中不存在环,也就证明了提出的方法可以避免路由死锁。并且所提出的方法没有使用任何虚拟信道。
三.实验结果及分析
本实施例使用noxim仿真器在16*16noc中实现这些算法,并且使用随机流量模式,通过多组实验取平均值来计算性能指标。为了准确评估可靠性和可用节点数,本实施例为hamfa设置了不同数量的故障链路,为zonedefense设置了不同数量的故障节点。每种故障数量还包含多个故障配置,然后对实验结果计算它们的平均值。在评估延迟,吞吐量和能量时,本实施例只向noc注入一个或两个故障,并比较不同算法的性能指标,因为当发生众多故障时,hamfa和zonedefense并不能很好的容忍。本实施例将这些算法应用于使用xy算法的hermsnoc的交换机,并分别评估这些算法在6*6,10*10和16*16noc上的硬件实现成本。此外,本实施例只使用lchain和fchain的全局配置为zonedefense实现计算下一跳方向的函数,因为生成lchain和fchain全局配置的函数太复杂,无法使用硬件应用。最后本实施例使用90nm技术库合成这些交换机,获得它们的单跳延迟和面积开销。
1.可用节点评估
如图10所示,当向noc注入许多故障节点时,dpra的可用节点随着故障节点数量的增加而缓慢减少。这是因为dpra使用tarjan算法搜索强连接组件,并将故障noc重新配置为其最大强连接组件。zonedefense可以容忍多个故障的影响,但它会牺牲不安全区域中的所有无故障节点。在图10中,随着故障节点数量的增加,zonedefense的可用节点的减小十分明显。过度牺牲无故障节点使得zonedefense不适用于具有众多故障的noc,因为该算法可能会导致无法满足关于可用工作节点数量的设计要求。dpra不仅容忍许多故障的影响,而且可以最大化使用noc中的可用节点。
2.可靠度评估
本实施例在16*16noc中实现hamfa和dpra,并分别注入1,5,10,20,30,40个链路故障,分组进行多次实验,对实验结果进行取平均值。如图11所示,实验结果证明了dpra在容忍众多故障方面的强大能力。当向16*16noc注入许多故障链路时,无论故障链路的数量如何,dpra的可靠性始终保持在较高水平。这是因为只要两个节点之间存在路径,广度优先遍历总可以找到该路径并沿该路径发送数据包。死锁避免处理也成功避免了noc中的死锁,它们确保目的地节点可以准确地接收数据包。
作为比较,当故障链路数量增加时,hamfa的可靠性会迅速下降,如图11所示。这是因为hamfa不能容忍许多故障的影响。即使在升序路径(或降序路径)与快件链路重叠的链路上发生单个故障,通过该链路传输的分组也不能到达其目的地。
3.性能指标评估
3.1.平均延迟
图12展示了xy算法、无故障时的dpra和20个链路故障的dpra的平均延迟对比。从实验结果中可以看出,在无故障时dpra延迟会略高于xy路由算法。这是由于dpra采用了额外的硬件开销并且需要执行查表得出下一跳路由方向。而xy路由算法计算简单。
在注入20个故障的情况下,dpra的延迟又会略微升高,这是由于故障可能会导致数据包采取的路径并不是曼哈顿距离。
图13和图14展示了hamfa和dpra与zonedefense和dpra的平均延迟对比。从数据中可以看出,在无故障或有故障的情况下,dpra的平均延迟都要略低于其他两个算法。这是由于dpra的在线路由计算简单,而hamfa和zonedefense的路由计算都比较复杂。
3.2.吞吐量
图15-17展示了在吞吐量方面,dpra在无故障和有故障的情况下都要好于hamfa和zonedefense。在没有故障的情况下,hamfa和zonedefense的性能落后于dpra,当故障发生时,差距变得更加明显。在hamfa算法中,一些数据包通常必须通过较长的升序路径(或降序路径)传输,或者在出现某些故障链路时永远等待缓冲区。在zonedefense算法中,数据包会沿着lchain或fchain传输,这将增加传输路径的长度。所有这些条件都会降低noc的性能。
3.3.能耗
图18展示了在无故障时dpra相较于xy,能量消耗几乎一致,在注入20个故障的情况下。dpra吞吐量会略低于无故障的xy路由。这主要是因为在无故障时,dpra算法路由路径长度也是曼哈顿距离,较短的路由路径会差生比较小的能量开销。而在20个故障的情况下,dpra的路由路径可能会更长。
图19和20展示了能量消耗方面,dpra在无故障和有故障的情况下都要好于hamfa和zonedefense。这主要是因为dpra的简单的路由计算与较短的路由路径。
4.单跳延迟
dpra算法的硬件植入不会在在线操作阶段带来大的单跳延迟,因为唯一的在线操作只是读取路由表。如图21所示,其单跳延迟非常小,几乎与xy算法的单跳延迟一致。
hamfa的延迟高于dpra,因为它需要计算hamfaid,转换hamfaid和节点坐标,并确定下一跳方向。这些操作会有很大的单跳延迟。此外,hamfa在6*6和10*10noc会出现一些异常情况。当noc尺寸的值不等于2的幂时,hamfa的硬件实现需要特殊的除法器来计算hamfaid。
zonedefense的延迟远高于dpra的延迟,并且当noc的大小增加。即使zonedefense使用lchain和fchain的现有配置来计算下一跳方向,该算法也需要大量计算。因此,其硬件实现不可避免地复杂,并且会有很大的单跳延迟。上述两种方法的单跳延迟超过了单个时钟周期,因此noc必须为其分配多个时钟周期。总之,dpra的简单在线操作确保它永远不会危及在单个周期内执行路由操作的时序限制。
5.面积开销评估
如图22所示,dpra的面积开销对于容忍众多故障来说是合理的。dpra的大多数操作都是离线完成的,其路由器只需要一个简单的寄存器阵列即可为每个目标节点存储一个记录下一跳方向的路由表。
作为比较,在noc尺寸较大的情况下,hamfa具有比dpra更低的面积开销,因为它只使用故障链路的简单本地信息。由于缺乏故障链路的全局配置,hamfa几乎无法容忍许多故障,而随着noc尺寸的增大,dpra需要存储的路由表也会相应增大,这导致了在较大尺寸noc中,dpra面积开销会比较大。也正是由于hamfa的硬件实现需要特殊的除法器来计算hamfaid,所以hamfa的面积开销在16*16noc中会出现异常。
对于zonedefense,使用全局故障配置计算绕过所有故障链路的下一跳方向是计算密集型操作。zonedefense的硬件实现仅计算下一跳方向就已远远超过dpra。因此,在dpra中使用简单路由表的在线路由方法是减少区域开销的巧妙方法。
以上详细描述了本发明的较佳具体实施例。应当理解,本领域的普通技术人员无需创造性劳动就可以根据本发明的构思作出诸多修改和变化。因此,凡本技术领域中技术人员依本发明的构思在现有技术的基础上通过逻辑分析、推理或者有限的实验可以得到的技术方案,皆应在由权利要求书所确定的保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!