一种自动过滤垃圾邮件的方法及其系统与流程
本发明涉及邮件过滤方法技术领域,更具体地说是指一种自动过滤垃圾邮件的方法及其系统。
背景技术:
互联网的普及和发展,使得人们几乎每天都会收到各种各样的邮件,各种邮件里面有人们需要日常交流工作所需要的邮件,同时也包含了大量的垃圾邮件,这些垃圾邮件无孔不入,给用户带来了很多的困扰,这些垃圾邮件大多有如下特点:1、未经接受者同意,都是在没有事先征得邮件接收者同意的情况下单方发布;2、用户的邮箱一般是有存储空间上限的,频繁的接收骚扰邮件会导致正常工作开展受到影响;3、邮件的内容可能存在违法性,邮件可能包含有反动,迷信封建内容,会对社会造成危害和不良影响;对于此类垃圾邮件,人们非常抵触和反感;因此,有必要设计一种方法,可以自动形成防护,进行拦截或举报。
技术实现要素:
本发明的目的在于克服现有技术的缺陷,提供一种自动过滤垃圾邮件的方法及其系统。
为实现上述目的,本发明采用于下技术方案:
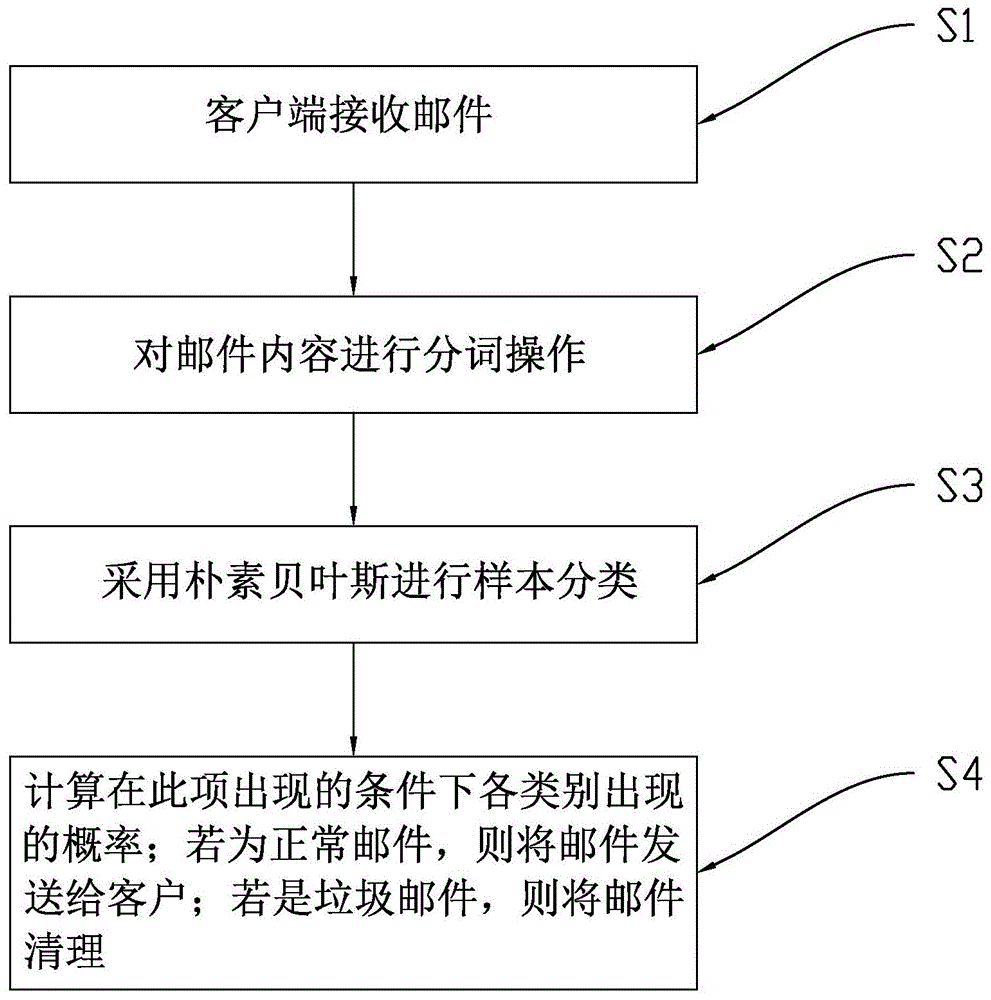
一种自动过滤垃圾邮件的方法,包括以下步骤:
s1,客户端接收邮件;
s2,对邮件内容进行分词操作;
s3,采用朴素贝叶斯进行样本分类;
s4,计算在此项出现的条件下各类别出现的概率;若为正常邮件,则将邮件发送给客户;若是垃圾邮件,则将邮件清理。
其进一步技术方案为:所述s3之前,还包括:对朴素贝叶斯进行样本训练。
其进一步技术方案为:所述朴素贝叶斯的公式为:
其进一步技术方案为:所述朴素贝叶斯进行样本训练通过分词去重提取出邮件中词集,作为训练内容,将邮件内容分割成由n个单词的组合,并计算包含各组合单词的邮件是垃圾邮件的概率。
其进一步技术方案为:当p是垃圾邮件,则:
其进一步技术方案为:独立事件发生的概率计算公式:p(a*b)=p(a)*p(b);两个事件互为独立事件,两个事件的发生没有相关性;因此,p(单词1、单词2...单词n同时出现|是垃圾邮件)转换为如下公式:
p(单词1、单词2...单词n同时出现|是垃圾邮件)
=p(单词1|是垃圾邮件)*
p(单词2|是垃圾邮件)*
…
p(单词n|是垃圾邮件)*|。
一种自动过滤垃圾邮件的系统,包括:接收单元,分词操作单元,分类单元,及计算单元;
所述接收单元,用于客户端接收邮件;
所述分词操作单元,用于对邮件内容进行分词操作;
所述分类单元,用于采用朴素贝叶斯进行样本分类;
所述计算单元,用于计算在此项出现的条件下各类别出现的概率。
其进一步技术方案为:还包括:训练单元,用于对朴素贝叶斯进行样本训练。
其进一步技术方案为:所述朴素贝叶斯的公式为:
其进一步技术方案为:所述朴素贝叶斯进行样本训练通过分词去重提取出邮件中词集,作为训练内容,将邮件内容分割成由n个单词的组合,并计算包含各组合单词的邮件是垃圾邮件的概率;当p是垃圾邮件,则:
本发明与现有技术相比的有益效果是:采用贝叶斯定理的概率探针判断,通过贝叶斯分类对邮件词集样本的学习,计算待分类项属于哪个类别,然后根据进行计算处理的结果分析,最终对垃圾邮件进行拦截,效果非常明显,从而大大降低了垃圾邮件的骚扰频率,给用户提供最佳用户体验,更好地满足需求。
下面结合附图和具体实施例对本发明作进一步描述。
附图说明
图1为本发明一种自动过滤垃圾邮件的方法流程图;
图2为本发明一种自动过滤垃圾邮件的系统方框图。
具体实施方式
为了更充分理解本发明的技术内容,下面结合具体实施例对本发明的技术方案进一步介绍和说明,但不局限于此。
如图1到图2所示的具体实施例,其中,如图1所示,本发明公开了一种自动过滤垃圾邮件的方法,包括以下步骤:
s1,客户端接收邮件;
s2,对邮件内容进行分词操作;
s3,采用朴素贝叶斯进行样本分类;
s4,计算在此项出现的条件下各类别出现的概率;若为正常邮件,则将邮件发送给客户;若是垃圾邮件,则将邮件清理。
其中,所述s3之前,还包括:对朴素贝叶斯进行样本训练。
其中,所述朴素贝叶斯的公式为:
其中,在充分了解贝叶斯定理后,再来看看,如何使用贝叶斯定理实现垃圾邮件的过滤,即基于概率统计的过滤方式。
其中,面对一封邮件,通常可以通过这个邮件的内容进行判断是否为垃圾邮件;对于计算机来说无法直接通过内容来判断,但是可以将邮件内容中的一些特征项提取出来,在本实施例中是通过分词去重的方法提取出邮件中词集,作为训练内容来供计算机判断的。
进一步地,所述朴素贝叶斯进行样本训练通过分词去重提取出邮件中词集,作为训练内容,将邮件内容分割成由n个单词的组合,并计算包含各组合单词的邮件是垃圾邮件的概率。
其中,p(是垃圾邮件|单词1、单词2...单词n同时出现)=?%,首先看一下理想状态该如何解这个概率,通过统计带有单词1、单词2、单词3同时出现的邮件数量y和短信样本总数x,即可得到概率y/x;这个计算方法的问题在于,即便邮件样本数量再大,也不会有太多是同时包含一系列单词的,极端情况可能根本没有;现在使用朴素贝叶斯定理,来将这个概率转换成其他三个概率来求解:
其中,当p是垃圾邮件,则:
p(是垃圾邮件)的值很容易计算,样本中垃圾邮件与样本总数之比即可得到;p(单词1、单词2...单词n同时出现|是垃圾邮件的值不太好求,需要进行转换,首先来看一个公式:独立事件发生的概率计算公式:p(a*b)=p(a)*p(b);两个事件互为独立事件指的是这两个事件的发生没有相关性;所以,p(单词1、单词2...单词n同时出现|是垃圾邮件)可以转换为如下公式:
p(单词1、单词2...单词n同时出现|是垃圾邮件)
=p(单词1|是垃圾邮件)*
p(单词2|是垃圾邮件)*
…
p(单词n|是垃圾邮件)*|。
为了确定每个类别下特性属性出现的概率,需要对朴素贝叶斯分类进行样本训练,即为了计算本例p(单词n|是垃圾邮件)的值,通过样本训练就可以得到在邮件是否是垃圾邮件的情况下单词n出现频率,其中,词集模式:只关注单词是否在这篇文档里出现,至于出现的次数以及相互之间的顺序,词集模式并不关心;在本实施例中,一封邮件有两种分类,分为垃圾邮件或者非垃圾邮件两种;获取训练所需要的邮件,并对每封邮件进行jieba分词->去掉停用词->去掉重复值的操作,这样获得训练所需词集;存储训练过程中所有邮件的词集,并且统计分别出现在垃圾邮件和非垃圾邮件的概率;分类统计的过程是有程序自动计算完成的,提供分类的样本即垃圾邮件和非垃圾邮件即可,理论上邮件数量越多,朴素贝叶斯分类进行样本训练所得到的结果将更为精准可靠;最后,发现p(单词1、单词2...单词n同时出现)的值也不太好求,前面说了由于样本数量有限,可能最终得到的值为0。
其中,其实没必要求分母,处理的方法可以同时求包含这些单词的这封邮件是垃圾邮件和不是垃圾邮件的概率,假设是垃圾邮件的概率是p1,不是垃圾邮件的概率是p2,这样一来,可以通过计算p1与p2的倍数关系来最终确定是否为垃圾邮件,例如若p1是p2的20倍,那么可以认为该邮件一定是垃圾邮件了;
如图2所示,本发明公开了一种自动过滤垃圾邮件的系统,包括:接收单元10,分词操作单元20,分类单元40,及计算单元50;
所述接收单元10,用于客户端接收邮件;
所述分词操作单元20,用于对邮件内容进行分词操作;
所述分类单元40,用于采用朴素贝叶斯进行样本分类;
所述计算单元50,用于计算在此项出现的条件下各类别出现的概率。
其中,还包括:训练单元30,用于对朴素贝叶斯进行样本训练。
其中,所述朴素贝叶斯的公式为:
进一步地,所述朴素贝叶斯进行样本训练通过分词去重提取出邮件中词集,作为训练内容,将邮件内容分割成由n个单词的组合,并计算包含各组合单词的邮件是垃圾邮件的概率;当p是垃圾邮件,则:
本发明采用贝叶斯定理的概率探针判断,通过贝叶斯分类对邮件词集样本的学习,计算待分类项属于哪个类别,然后根据进行计算处理的结果分析,最终对垃圾邮件进行拦截,根据目前的实验来看,成功率可以到达96%,效果非常明显,也就是说,对于100条骚扰短信,最多会有4条误判,从而大大降低了垃圾邮件的骚扰频率,给用户提供最佳用户体验,更好地满足需求。
上述仅以实施例来进一步说明本发明的技术内容,以便于读者更容易理解,但不代表本发明的实施方式仅限于此,任何依本发明所做的技术延伸或再创造,均受本发明的保护。本发明的保护范围以权利要求书为准。
- 还没有人留言评论。精彩留言会获得点赞!