基于超分辨率重构的视频压缩方法与流程
本发明属于视频压缩技术领域,特别涉及一种视频压缩方法,可应用于视频存储、视频传输及视频通信场合。
背景技术:
随着视频产业链的不断发展和计算机技术的不断突破,以视频为载体的信息传播方式已经得到广泛使用。相较于普通的文字和图片,视频包含的数据量比较大,并且随着成像设备的快速发展,在一些使用超高清视频的场景中,超高清视频包含的数据量非常大,在对视频进行存储或者传输时,往往受到存储器容量和网络带宽的限制需要对视频进行压缩,而在压缩的过程中则会造成数据受损,给后续视频恢复带来困难。超分辨率技术因其技术优势能够有效缓解这一问题。近年来,随着网络直播、新一代多媒体视频通信、物联网等技术的快速发展,视频压缩由于具有较高的研究价值以及广阔的商业应用空间,无论是在科研领域还是在工业应用领域都受到了越来越广泛的关注。
当前,大部分传统的视频压缩方法都是利用视频数据在空间和时间上的相关性进行视频压缩,其中应用较为广泛的视频压缩方法是h.264视频压缩方法,该方法主要是通过帧内预测压缩、帧间预测压缩以及数据量化编码等技术来实现视频压缩,但该方法并没有充分应用视频大数据中的先验信息,在一些需要对数据进行低码率压缩的场景中会丢失较多信息,导致重构出的视频峰值信噪比低,给后续使用带来困难。
技术实现要素:
本发明目的在于针对上述现有技术的不足,提供一种基于超分辨率重构的视频压缩方法,以减少低码率压缩情况下的信息丢失,提高重构视频的峰值信噪比。
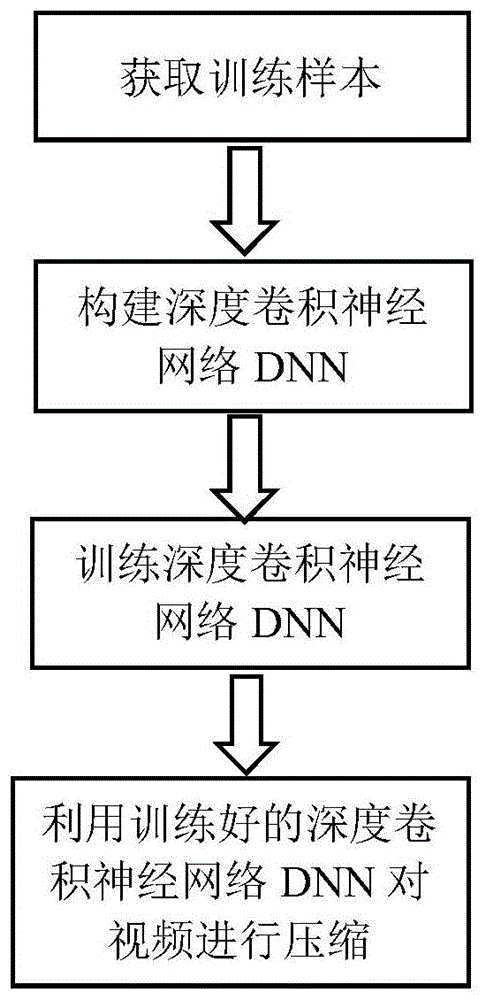
本发明的技术思路是:通过对需要压缩的视频进行下采样,将下采样后的视频输入h.264压缩方法中来减少数据量,通过设计一个压缩神经网络在原始视频大数据中学习先验信息,用学习到的先验信息帮助超分辨率重构,以此提升重构视频的峰值信噪比。其实现步骤包括如下:
(1)获取训练样本;
(1a)将包含n个高清视频的视频集备份存储2份,一份作为原始样本集x,一份作为标签视频集y,并对原始样本集依次进行下采样、编码及解码的预处理,得到压缩样本集x(c);
(1b)用压缩样本集和输入视频集共同作为训练样本集x(t);
(2)构建基于tensorflow架构的深度卷积神经网络dnn的网络模型:
(2a)设计依次由相邻帧融合子网络、编码子网络、量化子网络和解码子网络4部分组成的压缩神经网络模块,该量化子网络依次包含一个全连接层、tanh函数映射层、sign函数映射层和截断层;
(2b)设计依次由特征提取子网络,特征融合子网络和重构子网络3部分组成构超分辨率重构模块;
(2c)将压缩神经网络模块中解码子网络的输出端与超分辨率重构模块中的特征融合子网络相连接,构成深度卷积神经网络dnn的网络模型;
(3)用(1)获得的训练样本集对(2)构建的网络模型进行训练:
(3a)将训练样本输入(2)中构建的dnn网络模型中,输出重构的视频图像;
(3b)计算深度卷积神经网络dnn的网络模型的损失值,利用损失值采用随机梯度下降算法对该dnn网络模型进行训练,得到训练好的dnn网络模型;
(4)将待压缩的视频进行预处理后,用训练好的网络模型对视频进行压缩与解码:
(4a)在编码端对视频图像进行压缩:
(4a1)将需要压缩的视频图像进行备份存储;
(4a2)将需要压缩的视频图像输入到训练好的dnn网络模型中,提取量化子网络中的截断层特征进行压缩,并每隔m个特征进行备份保留,得到压缩特征;
(4a3)将备份存储的视频图像按照预先设定的下采样方式进行下采样,再使用h.264方法进行压缩,得到视频图像的压缩码流;
(4a4)用压缩码流与压缩特征共同组成压缩文件;
(4b)在解码端对压缩文件进行解码:
(4b1)提取出压缩文件中的压缩码流,通过h.264方法对该压缩码流进行解码,得到初始恢复视频;
(4b2)先提取出压缩文件中的压缩特征,每m个视频帧共享一个压缩特征,再对压缩特征进行解压缩得到解压缩特征,并用该解压缩特征替换量化子网络中的截断层特征;
(4b3)将初始恢复视频和替换后的截断层特征一起输入训练好的dnn网络结构中,该dnn模型的输出即为恢复后的视频。
本发明与现有技术相比具有以下优点:
1.峰值信噪比高
本发明在现有h.264视频压缩方法的基础上,将超分辨率重构技术应用到视频压缩领域,并且通过神经网络对视频中的相邻帧进行信息提取和融合,利用神经网络强大的表征能力和学习能力来拟合输入视频和和输出视频之间的映射关系,恢复出的视频峰值信噪比较高。
2.低码率压缩时信息丢失较少
本发明除了设计一个超分辨率重构模块对初始视频进行超分辨率重构外,还设计了一个压缩神经网络对需要压缩的视频进行学习,由于在下采样以及对下采样后的视频进行压缩的过程中,会造成不可逆的信息损失,给视频恢复带来困难,本发明通过设计的压缩神经网络对需要压缩的视频进行学习,学习到的信息叫做边信息,边信息用来帮助超分辨率重构,并且在测试使用时,采用多帧共享的方式,可在不显著降低压缩程度的同时,减少低码率压缩情况下的信息丢失,进一步提高视频的峰值信噪比。
附图说明
图1是本发明的实现流程图;
图2是需要压缩的视频中的某一帧图像;
图3是使用h.264方法对图2中的图像进行压缩后,恢复出的图像;
图4是使用本发明方法对图2中的图像进行压缩后,恢复出的图像;
具体实施方式
下面结合附图对本发明的实施例和效果做进一步描述。
参照图1,对本实例的具体实施步骤如下:
步骤1,获取训练样本。
本实施例中的高清视频包含542个视频序列,每个视频序列由32个连续帧组成,主要是从高清纪录片中搜集的高清视频序列,比较真实,数据集中有森林、雪、沙漠、城市生活等各种场景,其中大部分视频帧的分辨率为1280*720,从这些视频序列中获得训练样本的步骤如下:
(1a)将上述542个视频序列备份存储2份,一份作为原始样本集x={x1,x2,…,xi,…,xn},其中,xi表示第i个视频,n表示视频总个数,xi={xi,1,xi,2,…,xi,j,…,xi,l},其中,xi,j表示第i个视频中的第j帧,l表示第i个视频中的总帧数;另一份作为标签视频集y={y1,y2,…,yi,…,yn},其中,yi表示第i个视频,n表示视频总个数,yi={yi,1,yi,2,…,yi,j,…,yi,l},其中,yi,j表示第i个视频中的第j帧,l表示第i个视频中的总帧数;
(1b)对原始视频集x进行下采样,本实例是在matlab语言中用以下命令实现对原始样本集x中的视频进行下采样:
frame_down=imresize(frame,rate,'bicubic');
其中,frame_down表示下采样后的视频帧,frame表示原始视频帧,rate表示采样倍数,'bicubic'表示采样方法,本实施例中,rate=4;
(1c)使用现有的h.264压缩方法对下采样后的视频进行编码;
(1d)使用现有的h.264压缩方法对编码视频进行解码,得到压缩样本集x(c),
步骤2,构建基于tensorflow架构的深度卷积神经网络dnn的网络模型。
(2a)设计用于学习边信息的压缩神经网络模块:
(2a1)搭建相邻帧融合子网络,该子网络依次由3层卷积层组成,其中:
第一卷积层的卷积核大小为3×3×3,卷积核数量为32,步长为1;
第二卷积层的卷积核大小为3×3×3,卷积核数量为32,步长为1;
第三卷积层的卷积核大小为1×1,卷积核数量为32,步长为1;
(2a2)搭建编码子网络,该子网络由9个卷积层和3个拼接层组成,其结构依次为:第一卷积层→第二卷积层→第三卷积层→第一拼接层→第四卷积层→第五卷积层→第六卷积层→第二拼接层→第七卷积层→第八卷积层→第九卷积层→第二拼接层,其各层参数如下:
第一卷积层的卷积核大小为3×3,卷积核数量为32,步长为2;
第二卷积层的卷积核大小为3×3,卷积核数量为32,步长为1;
第三卷积层的卷积核大小为3×3,卷积核数量为32,步长为1;
第一拼接层,用于将第一卷积层的输出与第三卷积层的输出进行拼接;
第四卷积层的卷积核大小为3×3,卷积核数量为48,步长为2;
第五卷积层的卷积核大小为3×3,卷积核数量为48,步长为1;
第六卷积层的卷积核大小为3×3,卷积核数量为48,步长为1;
第二拼接层,用于将第四卷积层的输出与第六卷积层的输出进行拼接;
第七卷积层的卷积核大小为3×3,卷积核数量为64,步长为1;
第八卷积层的卷积核大小为3×3,卷积核数量为64,步长为1;
第九卷积层的卷积核大小为3×3,卷积核数量为64,步长为1;
第三拼接层,用于将第七卷积层的输出与第九卷积层的输出进行拼接;
(2a3)搭建量化子网络,该子网络依次由卷积层、tanh函数映射层、sign函数映射层和截断层组成,其结构参数如下:
第一卷积层的卷积核大小为1×1,卷积核数量为8,步长为1;
tanh函数映射层用于将第一卷积层的输出结果进行映射输出;
sign函数映射层用于将tanh函数映射层的输出结果进行映射输出;
截断层用于帮助网络模型训练,在网络训练过程中,在tensorflow架构中采用以下命令实现:
out=out_1+tf.stop_gradient(out_2-out_1)
式中,out_1表示tanh函数映射层的输出,out_2表示sign函数映射层的输出,out表示截断层的输出;
(2a4)搭建解码子网络,该子网络由5个卷积层、1个反卷积层和2个拼接层组成,其结构依次为:第一卷积层→第二卷积层→第三卷积层→第一拼接层→第一反卷积层→第四卷积层→第五卷积层→第二拼接层,其各层参数如下:
第一卷积层的卷积核大小为1×1,卷积核数量为8,步长为1;
第二卷积层的卷积核大小为3×3,卷积核数量为64,步长为1;
第三卷积层的卷积核大小为3×3,卷积核数量为64,步长为1;
第一拼接层,用于将第一卷积层的输出与第三卷积层的输出进行拼接;
第一反卷积层的卷积核大小为3×3,卷积核数量为64,步长为2;
第四卷积层的卷积核大小为3×3,卷积核数量为48,步长为1;
第五卷积层的卷积核大小为3×3,卷积核数量为48,步长为1;
第二拼接层,用于将第一反卷积层的输出与第五卷积层的输出进行拼接。
(2a5)将上述相邻帧融合子网络、编码子网络、量化子网络和解码子网络4部分依次连接,完成压缩神经网络模块的设计;
(2b)设计超分辨率重构模块:
(2b1)搭建特征提取子网络,该子网络由12个卷积层和5个拼接层组成,其结构依次为:第一卷积层→第二卷积层→第三卷积层→第四卷积层→第一拼接层→第五卷积层→第六卷积层→第二拼接层→第七卷积层→第八卷积层→第三拼接层→第九卷积层→第十卷积层→第四拼接层→第十一卷积层→第十二卷积层→第五拼接层,其各层参数如下:
第一卷积层的卷积核大小为5×5,卷积核数量为64,步长为1;
第二卷积层的卷积核大小为3×3,卷积核数量为64,步长为1;
第三卷积层的卷积核大小为1×1,卷积核数量为64,步长为1;
第四卷积层的卷积核大小为3×3,卷积核数量为64,步长为1;
第一拼接层,用于将第二卷积层的输出与第四卷积层的输出进行拼接;
第五卷积层的卷积核大小为1×1,卷积核数量为64,步长为1;
第六卷积层的卷积核大小为3×3,卷积核数量为64,步长为1;
第二拼接层,用于将第二卷积层、第四卷积层、第六卷积层的输出进行拼接;
第七卷积层的卷积核大小为1×1,卷积核数量为64,步长为1;
第八卷积层的卷积核大小为3×3,卷积核数量为64,步长为1;
第三拼接层,用于将第二卷积层、第四卷积层、第六卷积层、第八卷积层的输出进行拼接;
第九卷积层的卷积核大小为1×1,卷积核数量为64,步长为1;
第十卷积层的卷积核大小为3×3,卷积核数量为64,步长为1;
第四拼接层,用于将第二卷积层、第四卷积层、第六卷积层、第八卷积层、第十卷积层的输出进行拼接;
第十一卷积层的卷积核大小为1×1,卷积核数量为64,步长为1;
第十二卷积层的卷积核大小为3×3,卷积核数量为64,步长为1;
第五拼接层,用于将第二卷积层、第四卷积层、第六卷积层、第八卷积层、第十卷积层、第十二卷积层的输出进行拼接;
(2b2)搭建特征融合子网络,该子网络依次由1个卷积层、1个拼接层、1个卷积层和3个conv-lstm层组成,其结构参数如下:
第一卷积层的卷积核大小为1×1,卷积核数量为64,步长为1;
第一拼接层,用于将特征融合子网络中第一卷积层的输出与解码子网络中第二拼接层的输出进行拼接;
第二卷积层的卷积核大小为1×1,卷积核数量为64,步长为1;
第一conv-lstm层的卷积核大小为3×3,卷积核数量为16,步长为1;
第二conv-lstm层的卷积核大小为3×3,卷积核数量为32,步长为1;
第三conv-lstm层的卷积核大小为3×3,卷积核数量为64,步长为1;
其中,conv-lstm层采用以下公式:
式中,xt表示t时刻输入,σ表示sigmoid函数,i、f、o和c分别表示输入门、遗忘门、输出门和细胞状态,而w和b则表示对应的权重和偏置,h表示隐层状态,t表示某一时刻,wxi、whi和wci表示输入门的权重,bi表示输入门偏置,tanh表示双曲正切函数,*表示卷积运算,°表示逐元素相乘。
(2b3)搭建重构子网络,该子网络由11个卷积层、5个拼接层、2个重构卷积层和2个亚像素层组成,其结构依次为:第一卷积层→第二卷积层→第三卷积层→第一拼接层→第四卷积层→第五卷积层→第二拼接层→第六卷积层→第七卷积层→第三拼接层→第八卷积层→第九卷积层→第四拼接层→第十卷积层→第十一卷积层→第五拼接层→第一重构卷积层→第一亚像素层→第二重构卷积层→第二亚像素层,其各层参数如下:
第一卷积层的卷积核大小为3×3,卷积核数量为64,步长为1;
第二卷积层的卷积核大小为1×1,卷积核数量为64,步长为1;
第三卷积层的卷积核大小为3×3,卷积核数量为64,步长为1;
第一拼接层,用于将第一卷积层的输出与第三卷积层的输出进行拼接;
第四卷积层的卷积核大小为1×1,卷积核数量为64,步长为1;
第五卷积层的卷积核大小为3×3,卷积核数量为64,步长为1;
第二拼接层,用于将第一卷积层、第三卷积层、第五卷积层的输出进行拼接;
第六卷积层的卷积核大小为1×1,卷积核数量为64,步长为1;
第七卷积层的卷积核大小为3×3,卷积核数量为64,步长为1;
第三拼接层,用于将第一卷积层、第三卷积层、第五卷积层、第七卷积层的输出进行拼接;
第八卷积层的卷积核大小为1×1,卷积核数量为64,步长为1;
第九卷积层的卷积核大小为3×3,卷积核数量为64,步长为1;
第四拼接层,用于将第一卷积层、第三卷积层、第五卷积层、第七卷积层、第九卷积层的输出进行拼接;
第十卷积层的卷积核大小为1×1,卷积核数量为64,步长为1;
第十一卷积层的卷积核大小为3×3,卷积核数量为64,步长为1;
第五拼接层,用于将第一卷积层、第三卷积层、第五卷积层、第七卷积层、第九卷积层、第十一卷积层的输出进行拼接;
第一重构卷积层的卷积核大小为1×1,卷积核数量为64,步长为1;
第一亚像素层参数设置为分别为:h=32,w=32,n0=64,n1=16,r=2;
第二重构卷积层的卷积核大小为1×1,卷积核数量为64,步长为1;
第二亚像素层参数设置为分别为:h=64,w=64,n0=4,n1=1,r=2;
其中,亚像素层采用以下公式:
dim(i)=h*w*n0
=h*w*r*r*n1
=h*r*w*r*n1
式中,dim(·)表示输入张量的维度,i表示输入的特征映射图,h和w表示特征映射图的高和宽,r表示放缩因子,n0和n1表示网络层数;
(2b4)将上述特征提取子网络,特征融合子网络和重构子网络3部分依次连接,完成超分辨率重构模块的设计;
(2c)将压缩神经网络模块中解码子网络的输出端与超分辨率重构模块中的特征融合子网络相连接,构成深度卷积神经网络dnn的网络模型;
步骤3,用(1)获得的训练样本集x(t)和标签样本集y对(2)构建的网络模型进行训练。
(3a)从训练样本中分离出压缩样本集x(c)和原始样本集x;
(3b)将压缩样本集x(c)中的每一个视频
(3c)训练dnn网络模型:
(3c1)计算dnn网络模型损失值:
其中,loss表示损失值,n表示视频总个数,l表示视频总帧数,yi,j表示标签视频集中第i个视频的第j帧,即yi,j,y′i,j表示输入
(3c2)利用损失值采用现有的随机梯度下降算法对该dnn网络模型进行训练,得到训练好的dnn网络模型。
步骤4,将待压缩的视频进行预处理后,用训练好的网络模型对视频图像进行压缩与解码。
(4a)在编码端对视频图像进行压缩:
(4a1)将需要压缩的视频图像进行备份存储;
(4a2)将需要压缩的视频图像输入到训练好的dnn网络模型中,提取量化子网络中的截断层输出值,保存该输出值得到截断层特征;
(4a3)依次用python语言的一个扩展程序库numpy中的打包函数numpy.packbits和压缩保存函数numpy.savez_compressed对截断层特征进行压缩,并每隔m个特征进行备份保留,得到压缩特征;
(4a4)将备份存储的视频图像按照预先设定的下采样方式进行下采样,即在matlab语言中用以下命令实现:
frame_down=imresize(frame,rate,'bicubic');
其中,frame_down表示下采样后的视频帧,frame表示原始视频帧,rate表示采样倍数,'bicubic'表示采样方法,本实施例中,rate=4;
(4a5)使用现有的h.264方法对(4a4)中下采样后的视频进行压缩,得到视频图像的压缩码流;
(4a6)用压缩码流与压缩特征共同组成压缩文件;
(4b)在解码端对压缩文件进行解码:
(4b1)提取出压缩文件中的压缩码流,通过现有的h.264方法对该压缩码流进行解码,得到初始恢复视频;
(4b2)将压缩文件中的压缩特征提取出来进行保存,且每m个视频帧共享一个压缩特征,再用python语言的一个扩展程序库numpy中的解包函数numpy.unpackbits对压缩特征进行解压缩得到解压缩特征,并用该解压缩特征替换量化子网络中的截断层特征;
(4b3)将初始恢复视频和替换后的截断层特征一起输入训练好的dnn网络结构中,该dnn模型的输出即为恢复后的视频。
以下通过仿真实验,对本发明的技术效果作具体说明:
1.仿真条件:
软件环境:ubuntu16.04操作系统,matlabr2015a编程平台、python3.0编程语言解释器、tensorflow-1.4.0-gpu深度学习框架、cuda8.0显卡驱动、visualstudio2013编程平台;
硬件环境:interi7-5930kcpu、ddr5-128gb内存、geforcegtx1080ti显卡。
2.评价指标:
仿真实验中,采用视频的平均峰值信噪比指标,即用同一个视频内所有视频帧的峰值信噪比psnr平均值,评价视频的恢复效果,其中峰值信噪比psnr的定义为:
式中,mse表示恢复出的视频帧的均方误差。
3.仿真内容:
仿真1,采用本发明方法对图2所示的视频中的某一帧图像进行压缩,恢复结果如图4。
仿真2,采用现有h.264方法对图2所示的视频中的某一帧图像进行压缩,恢复结果如图3。
对比图3和图4,可以看出,本发明得到的结果更加接近真实视频帧。
4.对两种方法的平均峰值信噪比psnr进行对比
计算现有h.264方法和本发明方法对视频进行压缩后恢复出的视频的平均峰值信噪比,结果如表1所示。
表1基于超分辨率重构的视频压缩实验结果1(psnr/db)
在表1中,test0表示第一个需要压缩的视频,test1表示第二个需要压缩的视频,帧尺寸表示视频帧的大小,原始视频大小指的是需要压缩的视频大小,压缩文件大小指的是对需要压缩的视频进行压缩后得到的压缩文件大小,压缩比指的是压缩文件大小与原始视频大小的比值,
从表1中可以看出,本发明提高了恢复视频的峰值信噪比。
- 还没有人留言评论。精彩留言会获得点赞!